







| 论文名称 | 发表时间 | 发表期刊 | 期刊等级 | 研究单位 |
| CLAP: Learning Transferable Binary Code Representations with Natural Language Supervision | 2024年 | ISSTA | CCF A | 清华大学 |
1. 引言
研究背景:深度学习在许多二进制分析任务中都很有效,包括函数边界检测、二进制代码搜索、二进制代码相似性检测、函数类型推断、恶意软件分类、逆向工程,以及值集分析。 深度学习在二进制分析领域的成功可归因于其强大的表示学习能力,事实证明,这种能力可以有效捕获数据中的复杂模式和关系,以及学习有意义的汇编代码表示。
现存问题:尽管深度学习技术在二进制分析方面取得了进展,但现有方法仍存在一定的局限性。 首先,当前的方法在应用于新的数据集或任务时通常需要大量数据进行重新训练,导致在训练样本稀疏的场景中性能不佳。 这在少样本学习场景和零样本学习场景中尤其成问题,在少样本学习场景中,模型必须适应具有最少示例的新任务,在零样本学习场景中,模型遇到在训练期间从未见过的任务。 其次,现有的汇编代码编码方案通常会导致丢失关键信息,例如调用指令的参数、字符串和变量名称。 特别是,大多数方法倾向于使用特殊的词汇标记来标准化字符文本、常量数值和外部函数,这无意中导致了重要细节的遗漏。
研究动机:从多模态学习中汲取灵感,我们观察到诸如 CLIP 之类的模型可以通过将视觉模态概念与人类可理解的自然语言相结合来学习更好的图像表示(自然语言↔️图像)。 同样,我们可以将二进制代码概念化为一种类似的模态,并探索二进制代码和自然语言之间的一致性,以开发具有更好可移植性的语义上更深刻的汇编代码表示(自然语言↔️汇编代码)。 具体来说,我们可以使用自然语言(即代码语义的解释)作为监督信号,通过将二进制代码(即汇编代码)与预训练对齐来学习二进制代码的表示。 生成的模型很可能获得封装更多有关二进制代码的语义信息的表示。 为此,我们必须解决以下挑战:(1)以高效、低成本的方式获取对齐数据集;(2)在代码表示过程中保留代码的语义信息(例如控制流和数据流)。
研究内容:为了解决这些挑战,论文引入了一种名为 CLAP 的新方法,它利用自然语言监督来学习可转移的二进制代码表示。 具体来说,关于第一个挑战,论文提出了一个高效的数据集引擎,可以自动生成用于模型预训练的大型且多样化的汇编代码和自然语言解释数据集。 关于第二个挑战,论文引入了一种新颖的二进制代码表示学习主干网络,该网络结合了 WordPiece 标记化(例如 Llama 使用)和跳跃感知嵌入(例如 jTrans 使用)设计。 该网络能够捕获二进制代码中的数据流和控制流信息,同时保留关键信息,例如函数调用参数、反编译器处理的字符串和变量名称。
实验结果:论文生成了 1.95 亿对数据(汇编代码及其对应的自然语言),并预训练了 CLAP 原型模型。在多个下游任务上对 CLAP 进行了评估,包括二进制代码相似性检测 (BCSD)、加密相关函数识别和协议分类。 结果表明,即使没有任何进一步的特定任务训练或微调,CLAP 在这些任务上的表现也优于现有的最先进解决方案。 在 BCSD 任务中,当搜索 10,000 个函数之内的函数时,没有微调的 CLAP 以平均 Recall@1 率为 83.3% 获得最高排名。 相比之下,目前领先的监督解决方案仅达到 57.1%。 在与加密相关的功能识别方面,CLAP 在零样本设置中的表现略低于基线,但 CLAP 的微调版本大大超出了基线 17%。 在协议分类实验中,CLAP 的零样本和微调版本分别超过了最佳基线 6% 和 23%。 此外,论文还进行了一项案例研究,以评估真实样本上的 CLAP 的有效性。
论文主要探讨了一个关键的研究问题:即使面对极其有限或不存在的数据,是否可以在二元分析领域训练一个模型,以有效地将获得的知识转移到各种任务中? 论文所提的 CLAP 通过创新方法弥合了二进制代码和自然语言表示之间的差距,对该问题做出了肯定的回应。论文的的主要贡献如下:
- 论文了 CLAP,它创新性地使用自然语言作为监督信号来学习二进制代码表示。 这种方法将汇编代码与自然语言结合起来,并增强了迁移学习能力,特别是在少样本和零样本学习场景中。
- 论文开发了一个高效且可扩展的数据集引擎,能够生成汇编代码和相应自然语言解释的综合数据集。 该数据集有助于训练模型来表示具有自然语言监督的汇编代码,从而弥补了现有二进制分析方法中的重大差距。
- 论文进行了大量的实验来证明我们提出的 CLAP 方法的有效性,该方法优于最佳基线,并在各种任务上显示出卓越的迁移学习能力。 这展示了该模型在二元分析应用中的多功能性和有效性,在该领域树立了新的基准。
2. 研究背景
本节概述与 CLAP 相关的关键概念和技术,重点关注二进制代码表示和大型语言模型。
2.1 二进制代码表示
在编译过程中,高级语言被转化为更接近机器硬件的汇编代码(即二进制代码)。 与源代码相比,汇编代码更难解释。下图显示了汇编代码的示例,它实现了冒泡排序算法。 在二进制程序分析中,通常严重缺乏对源代码的访问。汇编代码表示需求

二进制代码表示对于二进制代码相似性检测 (BCSD)、函数原型推断、恶意软件分类以及逆向工程等各种任务至关重要。多年来,研究人员设计了多种技术将二进制代码表示为向量空间中的连续向量,使其适合下游任务。这些获得函数向量表示的方法可以大致分为三组:原始字节的直接建模,采用图模型建立控制流关系,将函数指令表示为指令序列。
2.1.1 原始字节
MalConv、DeepVSA 以及 𝛼-Diff 等多项研究采用 CNN 和 LSTM 等神经网络来分析原始字节的二进制代码,旨在改进恶意软件检测和识别代码相似之处。 这些方法专注于捕获数据依赖性和特征提取,并未不深入研究指令级语义或控制流图结构。这类方法具有计算效率上的优势,但无法实现深入的语义理解。原始字节方法专注于数据依赖性捕获和特征提取,其优点是计算效率高,其缺点是无法实现语义特征提取。
2.1.2 图建模
汇编代码本质上是由一系列基本块连接而成的控制流图 (CFG) ,这促使人们研究以图形方式对 CFG 进行建模。 Gemini 利用 GNN 从 CFG 中导出函数嵌入,尽管它受到手动选择可能丢失复杂语义的特征的限制。 GMN 通过基于注意力的图匹配网络创新地计算图相似度。 GraphEmb 和 OrderMatters 都注入了 DNN 来学习基本的块属性,然后应用图模型将这些块的相互关系封装在 CFG 框架内,从而更有效地捕获流程和结构。图建模方法通过 GNN 实现汇编代码 CFG 的嵌入,其优点是可以有效提取代码的控制流语义特征。
2.1.3 序列建模
序列建模方法将汇编代码视为指令序列,通过捕获指令顺序对指令序列建模。 Asm2Vec 和 SAFE 使用受语言启发的模型来生成指令和函数的嵌入,将指令类似于单词。基于 Transformers 的 Trex 和基于跳转感知模型的 jTrans 分别增强了微跟踪和控制流表示。VulHawk 集成了 RoBERTa 和 GCN 以实现多方面嵌入。 尽管它们在捕获语义细节方面很有效,但大多数序列模型缺乏全面的控制流图表示。序列建模方法通过 NLP 实现汇编代码指令序列的嵌入,其优点是可以有效提取代码的数据流语义特征。
2.2 大语言模型(LLM)
最近,大型语言模型尤其是 GPT 系列模型,已经表现出了非凡的源代码理解能力。例如,论文提示 ChatGPT 输出如下图 a 所示的代码片段的解释,ChatGPT 不仅通过实际使用,而且还通过其阐明代码功能的能力来展示其对源代码的强大理解力,即“此代码的目的是创建一个表示文件或目录模式的字符串,例如 -rw-r–r–”。

3. 研究内容

数据集引擎:论文首先对 Ubuntu 存储库进行广泛的编译活动开始(源码→汇编代码),之后为 GPT-3.5 设计提示词以生成解释数据集(源码→自然语言描述,通用、在线),最后论文使用这个解释数据集对 LLaMA 模型进行了微调(源码→自然语言描述,定制、离线)。
CLAP 模型:论文首先通过汇编代码数据集预训练一个跳跃感知 Transformer(Assembly 编码器生成),之后采用具有大量负样本的对比学习策略实现 Assembly 编码器与 Language 编码器的对齐(对齐过程增强了语义表示)。
3.1 数据集引擎
在本节中,我们将讨论获取训练数据集的过程。 核心思想是利用LLM对源代码的理解,构建源代码和汇编代码之间的关系,以获得汇编代码的自然语言解释。 考虑到构建数据集的成本,除了使用 GPT 之外,我们还本地训练了一个能够生成足够好的自然语言解释的模型,以创建大型且多样化的数据集。源代码→(汇编代码,自然语言)
3.1.1 汇编代码生成
我们利用包管理器来实现大规模的自动化编译和源代码获取,具体是使用 Ubuntu 的包管理器。 Ubuntu 是最流行的发行版之一,包含许多 C/C++ 软件包,每个软件包都有一个将源代码编译成最终产品的脚本。 这使得它适合生成一组不同的二进制可执行文件及其源代码。Ubuntu 包管理工具实现源码获取和自动化编译
我们采用各种编译器和优化级别来增加汇编代码的数量,其中包含六个不同的编译器(GCC-{7,9,11} 和 Clang-{9,11,12})和五个优化级别(O{ 0-3}和Os)。 此外,我们保留剥离和非剥离函数,以方便后期的组装预训练和对比预训练。在不同编译设置下对源码进行编译,六个不同的编译器,五个不同的编译优化级别

我们利用 Clang 来解析预处理后的源代码,通过确定代码文件中每个函数的位置来提取源代码片段。 为了增强函数的语义价值并最小化数据集中的噪声,我们排除了少于三行的源代码段,并消除了包含少于三个基本块的汇编代码。通过 Clang 进行预处理
3.1.2 自然语言生成
我们使用 GPT-3.5 来生成源代码的自然语言解释,因为它缺乏对汇编代码的理解。 通过利用源代码和汇编代码之间的对应关系,我们的目标是创建足够详细的文本解释,可以同时解释源代码和汇编代码。
具体来说,论文手动设计 GPT-3.5 的指令来生成解释。 论文首先提示模型简洁地总结源代码,同时避免详细的程序叙述。 其次,承认代码编译过程中固有信息丢失,例如缺少变量名称,我们指示模型放弃这些不可恢复的细节。 最后,论文对模型进行编程以将标签分配给代码片段。通过 GPT-3.5 生成源代码的自然语言解释,建立汇编代码与自然语言解释之间的映射
3.1.3 Shadow Model
我们使用 GPT-3.5 中 260 万个函数解释中的一半对 Vicuna 13B 进行监督微调 (SFT)。 为了进行比较,我们使用 50,000 个源代码函数解释分别训练了两个 LLaMA 13B 和 LLaMA 30B 模型。获得影子模型(针对 GPT 的影子模型)后,我们利用它来促进生成更大的自然语言解释语料库。 该方法用作数据增强技术,使我们能够生成自然语言解释和汇编代码对的扩展数据集。 因此,丰富的数据集显着增加了可用数据数量,同时保持了可接受的质量。训练影子模型实现大规模数据集的构建
3.2 CLAP 模型
接下来,我们将介绍整个 CLAP 引擎的设计和训练方法,包括汇编编码(即 CLAP-ASM)的设计、CLAP 引擎的训练过程以及使用自然语言作为监督信号增强可转移性。
3.2.1 模型架构
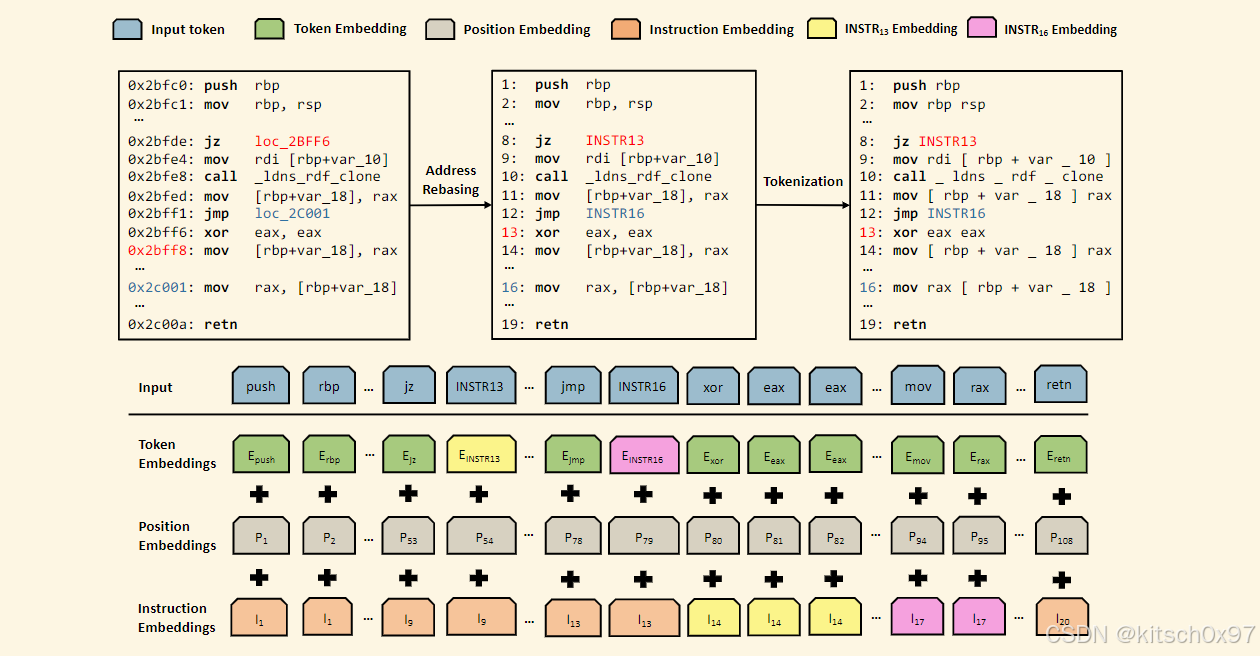
CLAP-ASM 基于 RoBERTa 基础架构,具有 110M 参数。 我们将最后一个 Transformer 层的输出平均作为程序集嵌入。CLAP-ASM 如上图所示,我们在设计编码器时采用了以下策略:
- 地址变基:首先对汇编代码的地址进行变基,并在处理跳转指令时保留相对地址关系。 这种方法不像以前的工作那样将不同的地址标准化为相同的令牌,而是保留了汇编代码中的控制流信息。 地址变基保持跳转指令与其目标之间的相对距离,使模型能够理解跳转指令引起的控制流变化。对指令地址进行标准化的同时保留相对地址关系
- Tokenization:我们将汇编代码标记化为单独的 Token。 我们首先采用 WordPiece 算法在整个汇编代码数据集上训练分词器,该数据集是专门为汇编代码量身定制的。该分词器可以对汇编代码进行无损编码,无需标准化,从而保留调用参数和外部函数名称等关键信息。 通过这种方式,我们使模型能够处理汇编语言的各种词汇,包括操作码、寄存器、常量和文字。采用基于 WordPiece 算法的分词器实现汇编代码的 Tokenization
- 跳跃关系:我们通过共享跳转符号的令牌嵌入参数及其相应的指令嵌入来增强 Transformer 对汇编代码中跳转关系的理解。例如,令牌嵌入 EINSTR16 与指令嵌入 I16 共享参数。 这种共享表示有助于模型捕获汇编代码的各个组件之间的复杂连接。 通过共享参数,模型学习将符号标记与其各自的目标标记相关联,从而使其能够更好地理解代码内的控制流。共享跳转符号的令牌嵌入参数及其相应的指令嵌入
3.2.2 编码器预训练
我们首先对汇编编码器进行预训练,通过选择性地屏蔽汇编上下文中的标记来理解汇编代码,这在之前的工作中已被证明非常有效。 我们遵循与之前工作 jTrans 相同的训练任务,包括掩码语言模型(MLM)任务和跳转目标预测(JTP)任务。 预训练阶段的集体损失函数 L𝑃 (𝜃 ) 是等式 1 中 MLM 和 JTP 目标函数的组合,其中 𝑥𝑖 是第 𝑖 个标记,mx 和 lx 表示正常标记和跳跃标记的掩蔽位置 。
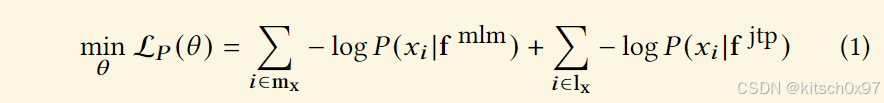
通过第一阶段的预训练,我们为第二阶段的对比预训练获得了一组初始化良好的权重,有利于对比预训练的加速收敛。借鉴 jTran 的训练方式,编码器进行预训练
3.2.3 对比预训练
预训练后,我们利用对比学习方法将汇编代码编码器与在大量文本对上预训练的文本编码器对齐。 通过对比学习实现自然语言监督的关键在于使用从预训练的自然语言模型获得的自然语言表示作为锚点。 训练任务是预测哪个解释对应哪个汇编代码。 我们应用 InfoNCE 损失来区分具有正文本解释和负文本解释的汇编代码。 给出正对汇编代码和文本解释 (𝑎𝑖, 𝑡𝑖 ) 和一组负对 (𝑎𝑖, 𝑡𝑗 ) 𝑗≠𝑖 。 我们分别通过汇编编码器 F𝐴 和文本编码器 F𝑇 获得汇编代码和解释的表示:
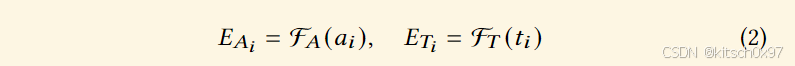
其中汇编代码 𝐴𝑖 的汇编嵌入表示 𝐸𝐴𝑖 ,用于解释的文本嵌入𝑇𝑗 表示 𝐸𝑇𝑖 ,𝑁 表示单个批次中的样本数量。 InfoNCE 损失定义如下所示:
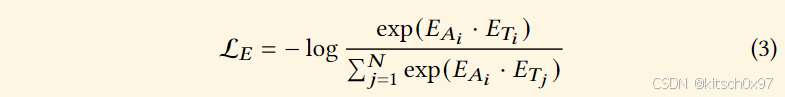
通过优化 InfoNCE 损失,我们增强了汇编代码和解释之间的相互信息,有效地对齐了它们的表示。 在实现中,我们采用了经过良好预训练的文本编码器 F𝑇 并利用了异常大的批量大小 𝑁 = 65, 536。这种方法使我们的模型能够从每个汇编代码的大量选项中准确识别最合适的解释。 它允许我们的模型利用自然语言解释的丰富语义来增强学习的汇编代码表示。通过优化 infoNCE 损失,增强汇编代码与自然语言之间的互信息,实现汇编代码与自然语言的对齐
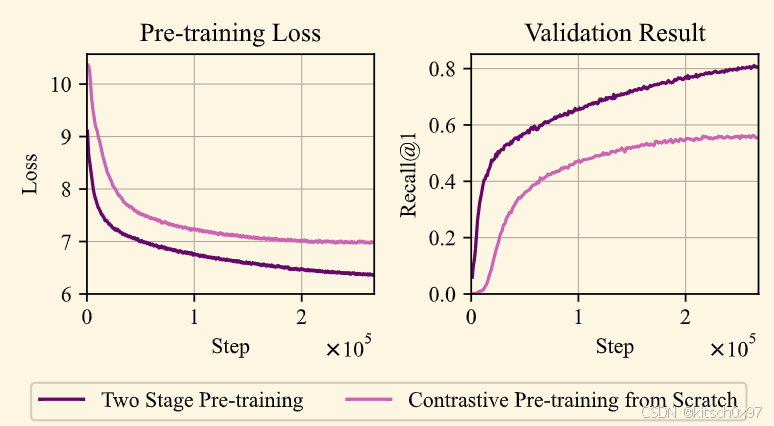
我们比较了直接预训练和两阶段预训练的损失和召回率。对比预训练损失和验证结果如上图所示。后者模型的损失在训练过程中下降得更快,并且获得了更高的验证结果。 与对比预训练相比,第一阶段预训练的成本不到10%,凸显了两阶段预训练的效率。两阶段预训练具有更好的性能
3.3 零样本推理
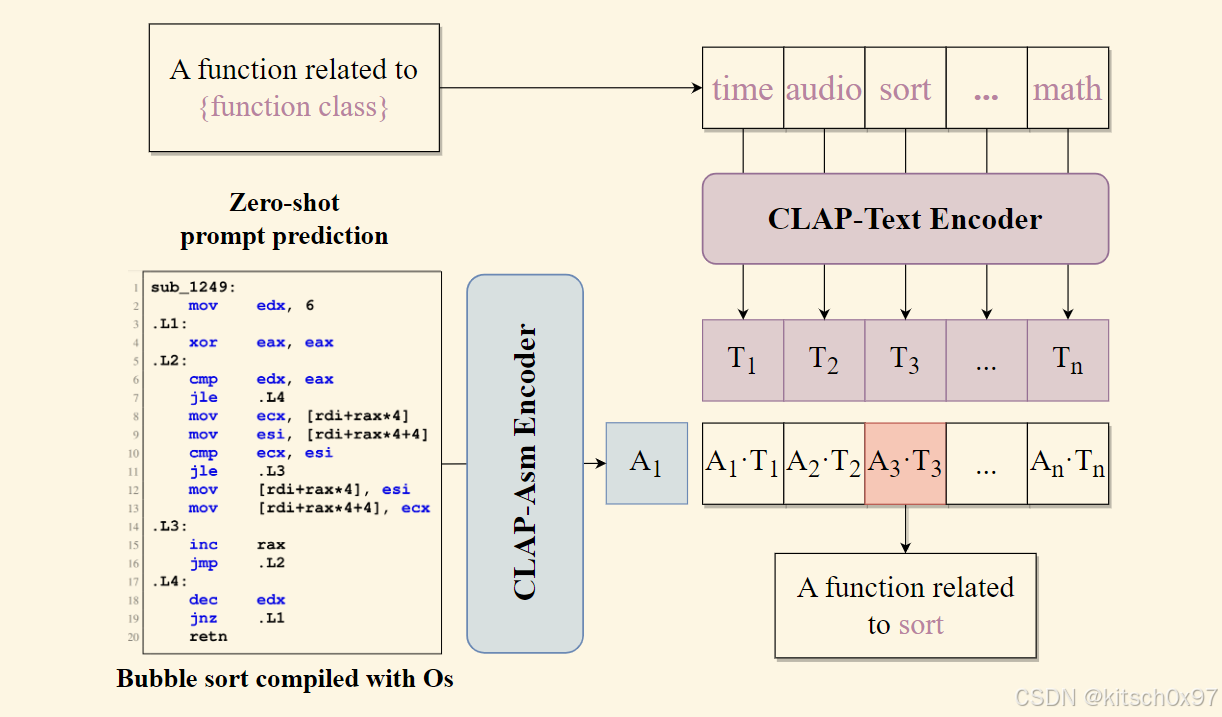
当我们通过对比学习将自然语言丰富的语义内容引入汇编代码的表示时,我们可以在下游汇编代码理解任务中实现令人印象深刻的零样本能力。 我们在下图中演示了如何使用零样本来执行汇编代码理解的下游任务。在多类分类任务中,首先使用 CLAP-ASM 将汇编代码编码为嵌入 𝐴1。 同时,构建 n 个提示来描述多类,随后由 CLAP-Text 处理以生成 n 个相应的文本嵌入 𝑇𝑖 。 为了得出零样本结果,我们计算 𝐴1 和每个 𝑇𝑖 的点积来计算相似度。 将相似度最高的提示标记为分类结果。 将每个相似度作为 logits,我们可以在 [𝐴1 · 𝑇1, 𝐴1 · 𝑇2, · · · , 𝐴1 · 𝑇𝑛] 上应用 SoftMax 函数来获得每个标签的概率。
4. 实验评估
我们使用 Pytorch 2.0 实现 CLAP。 我们在所有实验中都使用 IDA Pro 7.6 从二进制代码中反汇编和提取函数。 我们的训练和实验是在多台服务器上进行的,以加速训练。 每台服务器的 CPU 设置为 128 个核心,配备 2TB RAM。 GPU 总数为 32 个 NVIDIA Tesla A100。 我们进行了大量的实验来解决以下问题:
- RQ 1:CLAP 学习到的汇编代码表示的质量如何?
- RQ 2:即使面对极其有限或不存在的数据,CLAP 学习的表示是否表现出很强的可迁移性?
- RQ 3:自然语言解释可以支持二进制代码表示学习的根本理论原因是什么?
- RQ 4:数据集引擎获取的数据集质量如何
4.1 CLAP 表示的质量
在表示学习中,通常通过冻结预训练模型并仅训练用于下游任务评估的线性投影层(称为线性探针)来评估不同模型表示的效果。 在我们的评估中,我们仔细研究了一系列下游任务,特别是经过充分研究的 BCSD 任务,以及各种分类任务。 该方法旨在确认 CLAP 模型已有效地获得了更复杂的汇编代码表示。
4.1.1 二进制代码相似性检测
BCSD 代表了软件安全的重要方法。 它试图识别两个汇编代码之间的相似程度。 该方法是二进制分析不可或缺的一部分,大量研究致力于提高其准确性和效率,这对于漏洞识别、恶意软件检测和供应链分析等任务至关重要。 基于深度学习的方法现在已经成为BCSD事实上的SOTA,优于传统方法。 我们使用 BinaryCorp 数据集评估 CLAP 和几个基线 BCSD 模型。
为了评估预训练模型生成的嵌入的有效性,我们将线性探针合并到它们各自的输出中,使线性层能够将这些输出投影到适当的向量空间中。 更具体地说,我们在模型的顶层添加了一个线性分类器(没有非线性激活),并专门针对特定任务对其进行微调,以评估预训练模型生成的嵌入的质量。 此外,我们还提供 jTrans 的完整微调结果,因为它在线性探测期间表现最佳。 为了展示我们模型的可移植性,我们没有对 CLAP 进行微调。 相反,我们使用该模型而不进行任何进一步的训练来与基线进行比较。
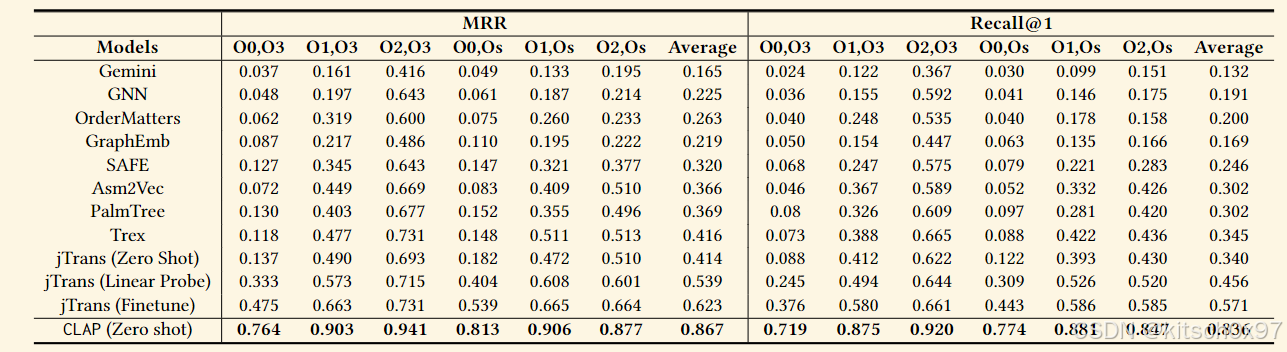
我们使用 Recall@1 和 MRR(平均倒数排名)作为指标,这些指标在之前的工作中使用过。 所有基线均以 10,000 的池大小进行评估,这意味着从整个数据集中随机采样的 10,000 个函数中只有一个正样本。我们的结果表明,在不同任务中,CLAP 的 MRR 指标平均优于最接近的基线竞争对手 0.244,recall@1 指标平均优于最接近的基线竞争对手 26.5%,这甚至是一个微调模型。
这些结果表明,即使在零样本格式中,CLAP 也可以显着优于 jTrans 和 Trex 等最先进的方法。我们还以零射击格式评估 jTrans,其中它使用 MLM 和 JTP 方法进行预训练,结果如表 1 中的 jTrans (Zero Shot) 所示。结果表明,CLAP 在零射击方面优于 jTrans。镜头格式的 MRR 指标提高了 0.453,recall@1 指标提高了 49.6% 以上。与仅采用自监督学习的汇编语言模型相比,自然语言监督的对比学习可以产生更好的汇编代码表示
4.1.2 加密算法识别
密码识别任务用于识别汇编代码属于哪种密码算法。在本实验中,我们首先从Ubuntu存储库中过滤出被识别为加密算法的包并提取函数。对于每个函数,我们根据其名称和相应包中包含的元信息将其分类为加密算法。值得注意的是,我们确保这些函数不会出现在对比学习的训练集中,以避免信息泄漏。我们过滤掉基本块数量小于 3 的函数,这意味着这些函数可能不包含有用的信息。最终,我们获得了包含 17 种加密算法和约 70K 个函数的数据集。为了进行比较,使用 jTrans、Trex 以及 PalmTree 作为预训练基线。
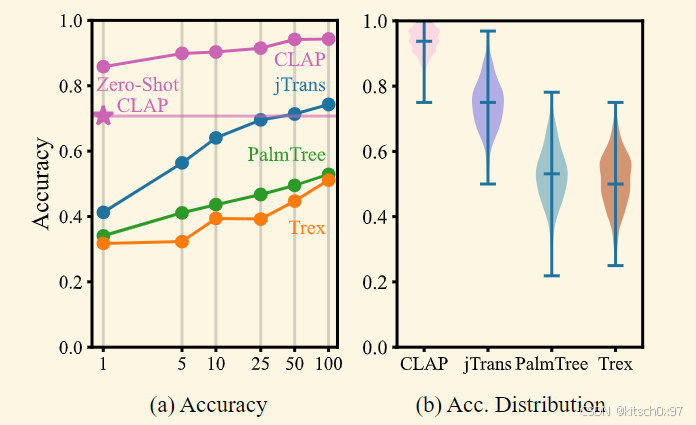
为了适应密码识别下游任务,我们使用线性探测方法评估模型。 我们分别使用 1%、5%、10%、25%、50% 和 100% 的训练数据对模型进行微调。 上图显示了 CLAP 和每个基线的性能,我们可以看到,CLAP 在具有 50% 训练集和所有训练数据的数据集上实现了 0.94 的高精度。 即使仅使用 1% 的数据进行训练,CLAP 的性能也超过了其他两个模型在所有训练数据上进行训练的结果。
4.1.3 协议类型识别
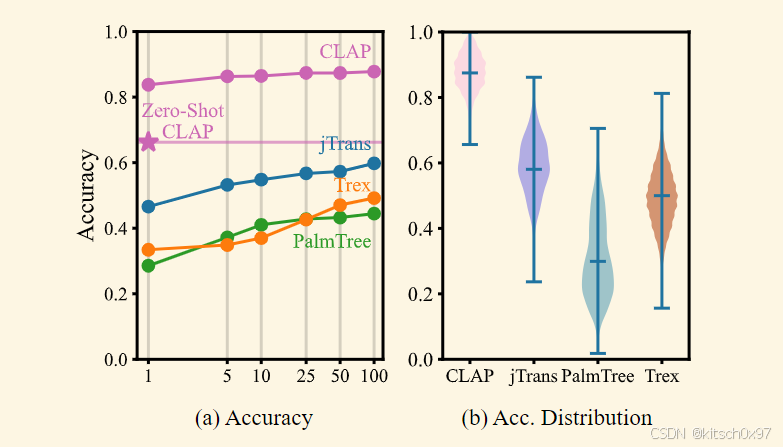
与上面的预处理和实验类似,我们使用标记为协议的包并获得736K函数的数据集,包含18种协议类型。上图显示了准确度结果,这表明我们的方法在密码识别任务中只需要 1% 的数据进行微调,使其超越在完整数据集上微调的其他基线的性能。此外,即使单独的零样本方法也优于或接近在完整数据集上微调的其他模型,这突显了我们的模型在获得出色的汇编代码表示方面的卓越能力。
基于上述实验可以得出结论,CLAP 模型可以获得了汇编代码的优越表示,并且其学习结果表现出更高的稳定性。
4.2 CLAP 可迁移能力
零样本学习允许模型在事先没有看到任务特定类别的任何示例的情况下进行预测或解决新任务,而少样本学习使模型能够仅通过少量示例快速适应新任务。 在本次评估中,我们努力评估模型的零样本和少样本能力,以验证其可迁移性能。
4.2.1 零样本学习
将汇编代码与自然语言解释结合起来的一个主要好处是能够使用自然语言与汇编代码无缝交互。 我们探索该模型的零样本功能以突出这一优势。
4.2.2 少样本学习
我们承认获取二进制任务数据的挑战,因为它们通常需要手动分析才能获取有限数量的样本。 为了模拟这一点,我们为每个模型提供一小组样本,并采用线性探针技术。 为了比较每个基线的少样本能力,我们使用线性探针方法和小数据集来训练模型,其中每个标签有 1、2、4、8 或 16 个样本。 由于样本数量有限,样本的选择可能会对最终结果产生较大影响,因此我们对每个样本量重复实验五次。
4.2.3 实验结果
上图中的结果表明了令人兴奋的结果。 当仅使用单个样本来训练每个标签时,与零样本学习相比,准确性通常会较低,这可能是由于过度拟合造成的。 这表明我们的模型即使没有样本也能取得满意的结果。 只有当每个类别都有足够多的样本时,少样本学习的结果才能超过零样本学习的结果。 我们将这种差异归因于每种方法与汇编代码特征交互的方式:虽然零样本学习允许自然语言直接与这些特征交互,但传统的少样本学习依赖于间接交互,导致在有限样本的情况下学习时遇到困难。 相比之下,其他基线甚至在学习任何东西上都遇到困难。 基线的准确度均低于 0.3。
上述结果显着证明了 CLAP 具有出色的零样本和少样本能力,从而即使在数据严重受限或缺失的情况下也表现出显着的可迁移性。
4.3 自然语言&代码表示
为了研究自然语言监督在汇编代码表示中的作用,我们进行了一些内在评估,以研究汇编代码表示在与自然语言表示对齐之前和之后如何变化。
4.3.1 表示可视化
我们首先利用 t-SNE 来可视化汇编表示,并增强我们对 CLAP 模型如何有效地从自然语言监督中学习的理解。 作为一种以将高维数据转换为更易于理解的二维或三维格式而闻名的工具,t-SNE 提供了清晰直观的数据关系视图,从而说明了我们的模型实现的细致入微的对齐。
在实验中,我们手动选择十个功能标签,包括时间、加密、身份验证、搜索、数学、文件管理、图形、网络、排序和音频。 我们从现实世界的程序中精心挑选了 50 个函数来举例说明每个功能,从而生成一个包含 500 个函数的数据集,称为“内在数据集”。 接下来,函数由五个模型进行编码:Trex、PalmTree、jTrans 和 CLAP-ASM 模型(有对齐和无对齐)。 然后,t-SNE 算法将这些表示形式简化为二维,如下图所示。

在可视化中,我们观察到 CLAP-ASM 生成的未经对齐的嵌入以及由 Trex、PalmTree 和 jTrans 生成的嵌入都显示出近乎无序的分布。 这种混乱模式在这些模型中是一致的,表明它们的嵌入缺乏高级程序语义。相反,在与文本嵌入对齐的自然语言监督之后,CLAP-ASM 模型的输出可以减少到相同的向量空间 根据功能,表现出相似的分布特征。 这一视觉证据强调了我们的模型和自然语言模型之间的对齐效应,这意味着在零样本场景中直接使用自然语言操作汇编语言模型的潜力。
4.3.2 自然语言监督
在实施由自然语言监督增强的对比学习训练后,我们观察到性能显着提高。 这种增强可以归因于通过经过复杂训练的文本编码器引入了本质上无限的标签。 与汇编代码的单独模式的对比学习不同,自然语言信号的结合在整个训练过程中提供了关键的锚点。 这种方法不仅丰富了训练环境,而且培养了具有卓越可迁移性的特征。
为了阐明我们的发现,请考虑具有两种加密算法的汇编代码实现的场景:RSA(一种非对称加密算法)和 MD5(一种哈希函数)。 对比学习仅依赖于汇编代码,通常使模型能够独立识别 RSA 和 MD5 实现中的相似性,但很难将两者联系起来。引入自然语言作为监督信号改变了这种动态。 例如,自然语言描述“RSA,密码学中的现代非对称加密算法”和“MD5,广泛使用的密码哈希函数”作为多方面的标签。 这些标签将 RSA 与术语“密码学、非对称加密、RSA”相关联,将 MD5 与“密码学、哈希算法、MD5”相关联,从而在密码学的广泛主题下在两者之间创建了一条连接线。 这凸显了自然语言在汇编代码表示中建立有意义的连接方面的关键作用。
在自然语言监督的过程中,经过复杂训练的文本编码器引入了本质上无限的标签,可以帮助模型实现更细致的代码表示。
4.4 数据集引擎评估
在本节中,我们评估 GPT 和 Shadow Mode 生成的解释的质量,即解释是否与源代码匹配以及匹配程度如何。
4.4.1 源码解释的质量
为了评估源代码解释的质量,我们聘请了五位领域专家对 GPT-3.5 和影子模型的解释进行独立审查和评分。 评估采用了明确的评分系统,具有四个不同的解释质量级别,从“典型”到“可接受”(有轻微遗漏),到“不合格”(遗漏了大多数关键点),最终为“差”(基本上没有准确解释) 代码功能。 专家将分别从 4(最好)到 1(最差)打分。
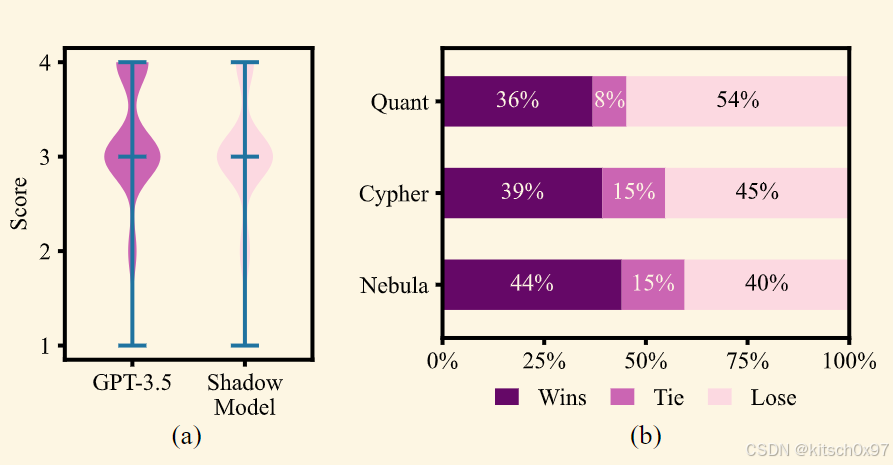
我们从每个模型中随机选择了 50 个解释供人类专家评估,但没有透露每个解释的来源。 如上图 (a) 所示,分数分布主要显示两个模型经常获得 3 分,表明处于可接受的水平。 值得注意的是,这两个模型都表现出相对较低的严重错误率。 然而,GPT-3.5 的表现略胜一筹,4 分分数的数量略多,正如平均分数所证明的那样。 GPT-3.5 的平均得分为 3.14,略高于影子模型的平均得分 3.00。 虽然这些结果并不突出,但它们被认为是可以接受的,这表明使用基于语言的监督作为对比学习的有效信号的可行性。通过 T 检验进行进一步定量分析,比较两个模型的平均分,得出 p 值为 0.0036,这表明 GPT-3.5 生成的解释的质量明显高于影子模型生成的解释。
4.4.2 影子模型的质量
为了比较影子模型和 GPT-3.5 的源代码解释质量,我们采用现有的 LLM 评估方法。 特别是,我们设计了一个在线网站,在该网站中,我们对同一源代码提供不同模型的不同解释,并让用户对它们进行排名。 这种方法使我们能够衡量模型与 GPT-3.5 相比的胜负和平局。 在人工评估过程中,我们的目标是防止模型信息泄漏(特别是模型大小和训练集大小),同时仍然获得用户反馈(允许用户评估各种模型的输出质量)。
如上图 (b) 所示的最终结果揭示了 GPT-3.5 与其他模型在人类感知方面的一些差异; 然而,GPT-3.5并没有表现出明显的优越性。每个模型都会经历胜利和失败。 值得注意的是,参数数量最多的 30B 模型优于两个 13B 模型,符合对更大模型的预期。 此外,在 1.3M 数据集上训练的模型遇到了更广泛的函数,使其能够处理更复杂的任务,而来自 50K 训练集的模型在人类评估中表现最差。 尽管如此,需要强调的是,后一种模型在代码理解和解释方面仍然与 GPT-3.5 竞争。 由于 GPU 内存需求增加以及与 30B 模型托管能力相关的批量大小减小,以及较大模型的推理速度较慢,我们选择 1.3M 数据集中的 13B LLaMA 模型进行广泛推理,以在性能和性能之间取得平衡。 推理开销。
5. 更广泛的影响
上面展示的实验结果凸显了 CLAP 的显着功能,但其潜力还进一步扩展。 通过弥合自然语言和汇编代码之间的差距,CLAP 通过使用开放词汇提示促进了对零样本学习的支持。 这一特性增强了CLAP在更多场景下的适用性,提供了更广泛的实用范围。
在二进制分析领域的许多潜在的现实世界语义分析任务中,数据集的构建非常具有挑战性,这极大地阻碍了汇编代码表示学习的应用。 由于数据集创建方面存在这些困难,本节通过各种案例研究分析 CLAP 的更广泛影响。 这些研究不仅证明了 CLAP 的实际有效性,而且凸显了其在零样本学习场景中的优势。 这种方法展示了我们的模型在处理传统数据驱动方法可能无法满足的复杂场景方面的强大潜力。
5.1 细粒度汇编语义
我们的第一个案例研究重点是检查模型对细粒度程序语义的潜在理解。 我们选择排序算法,以冒泡排序算法为例。 我们研究模型是否可以将给定的汇编代码识别为图 11 所示的冒泡排序算法。我们的输入提示包括十个标签:冒泡排序、选择排序、插入排序、合并排序、快速排序、堆排序、基数排序、桶排序 排序、希尔排序和计数排序,使用诸如“这是一个 XX 排序算法”(用各种排序算法替换 XX)之类的提示。 采用零样本推理方法,我们搜索与所提供的汇编代码最匹配的提示。 实验结果表明,我们的模型可以从十个选项中正确识别冒泡排序算法,展示了其理解细粒度程序语义的能力。
5.2 恶意行为分类
在第二个案例研究中,我们重点关注恶意代码分析,以展示模型在实际任务中的功能。 我们手动对恶意样本中的函数进行逆向工程,我们构建的提示涵盖了恶意软件中可能使用的常见功能,包括屏幕截图、自动启动、后门、下载、上传、rootkit、反检测、反调试、密码暴力破解和文件劫持。 我们使用 CLAP 将恶意汇编函数与上述类别进行零样本区分。 实验结果表明,我们的模型准确地识别了与屏幕截图相关的功能,凸显了我们的模型在现实世界恶意代码分析中的实用能力。
6. 研究不足
虽然我们的研究展示了 CLAP 的重大进展,但我们认识到某些局限性并提出了未来研究的方向。 首先,我们当前的方法没有充分利用源代码中可用的丰富信息。 未来的研究可以探索将自然语言与源代码相结合的方法。 这可能涉及开发更复杂的算法,深度集成源代码语义和结构,从而有可能产生更强大的模型。
其次,我们的数据集引擎依赖于从 Ubuntu 编译软件包并使用 GPT-3.5 进行源代码解释,可能会引入可能降低性能的偏差。 为了解决这个问题,未来的研究可以使数据源多样化,包括不同的编译环境或平台以及利用不同的语言模型进行源代码解释。
最后,当前讨论的语义分析任务的范围是有限的。 探索更广泛的应用场景还有很大的空间,例如使用自然语言进行汇编代码搜索。 这可能包括深入研究更复杂和多样化的语义分析任务,从而扩展模型的实用性并发现二进制代码分析的新途径。
7. 总结
总之,我们提出了 CLAP,一种通过自然语言监督学习汇编代码表示的新方法。 我们的方法成功地弥合了汇编代码和自然语言表示之间的差距。 CLAP 模型在二元分析中实现了卓越的可移植性,并在各种任务中优于最先进的解决方案。 这项研究强调了通过自然语言监督学习汇编代码表示的潜力,为汇编代码分析和表示学习开辟了新的可能性。 我们相信,我们的方法开辟了新的研究途径,并为未来的工作提供了一个有希望的起点。


















 3710
3710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









