







本博客系博主根据个人理解所写,非逐字逐句翻译,预知详情,请参阅论文原文。

发表地点:NIPS 2023;
论文下载链接:https://arxiv.org/abs/2305.14381
代码链接:https://c-mcr.github.io/C-MCR/;
摘要:
多模态对比表征学习MCR(Multi-modal Contrastive Representation)致力于将不同模态的数据编码到一个语义对齐的共享空间中。这种范式在下游的多种多模态任务上表现出了非常好的泛化性能。
但是MCR依赖于大量高质量的对齐数据(data pairs),这限制了MCR在更多模态上的发展。
本文提出了一个训练高效的方法,能够在没有paired data 的情况下训练MCR模型,称为Connecting Multi-modal Contrastive Representations (C-MCR).
具体而言,给定两个已经训练好的MCR,分别是在(A,B)和(B,C)模态下训练的。作者利用重复的B模态中的数据来对齐A,C两个模态,并把这些模态的数据映射到新的表征空间中。
同时,由于(A,B)和(B,C)已经是对齐好的数据,所以共同模态B的连接关系可以传递到(A,C)模态。
为了进一步增强本文C-MCR模型,作者还提出了一种语义增强的MCR内和MCR间的连接方法(semantic-enhanced inter- and intra-MCR connection method)。首先增强不同模态之间的语义一致性和完整性来实现更鲁邦的对齐。然后借助inter-MCR的对齐来建立连接关系,并且用intra-MCR对齐来更好地保持非重叠模态(A和C)的输入数据之间的关系。
为了展示C-MCR模型的性能,作者在audio-visual 和 3D-language两种跨模态任务上进行实验。具体而言,作者通过text将CLIP(一个text-image MCR模型)和CLAP(一个audio-text MCR模型)连接起来处理audio-visual 表征,通过image将CLIP和ULIP(一个3D-image MCR模型)连接起来处理3D-language表征问题。
实验表明,不借助任何paired数据,audio-visual C-MCR在audio-image retrieval, audio-visual source localization, and counterfactual audio-image recognition tasks任务上取得了SOTA结果。3D-language C-MCR在数据集ModelNet40上也达到了先进的zero-shot 3D点云分类准确率。
关键问题说明:
MCR多模态对比表征学习的目的是,给定一对text-image pair,分别学习一个text emb和image emb,这两个emb在下游各种多模态任务中可以随意使用,fusion或者各自分类。
需要注意,MCR不同于multimodal representation learning,后者是给定一个text-image pair,直接学习一个多模态的表征,这个表征同时包含text和image的信息,是fusion之后的结果。
本文动机及现有方法的问题:
本文的目标是,借助有大量paired data的两个MCR任务,学习缺少paired data的多模态MCR模型。比如,audio-image paired数据少,但是audio-text和text-image的paired数据非常多且高质量,于是本文就利用au-te MCR和te-im MCR,借助他们overlap的text模态,实现对audio和image多模态的MCR的学习。
这个想法很直接,很棒。
但是也存在一些挑战:
- 本文在现有MCR的基础上学习新的MCR,其实是没有直接处理原始paired data(现有MCR所利用的大量paired data存在的模态),而是直接使用了原始data经过MCR之后的表征进行后续的学习。而原始data在经过MCR的学习已经丢失了一些信息;
- 研究[1]表明,MCR实际上还是将两个模态的emb 映射到了一个shared space中的separate region,仍然存在modality gap。
本文主要贡献:
- 本文提出了C-MCR,一个novel的不需要paired数据、且训练高效的MCR学习方法。用简单的映射器(projector)将现有的MCR连接起来,本文可以挖掘现有MCR空间中的多模态对齐知识,然后将MCR扩展到更多的模态,那些缺少大规模高质量paired数据的模态。
- 本文提出了一个语义增强的MCR内和MCR间的连接方法。能够借助overlap的模态,在两个MCR之间建立可转移的连接,并将这种连接关系保持到non-overlap的模态中去。
- 为了证明本文模型的有效性,作者将CLIP和CLAP通过text连接起来,以处理audio-visual 表征问题。将CLIP和ULIP(一个3D的MCR模型)通过image连接起来,以处理3D-language表征问题。实验表明,audio-visual MCR模型在6个数据集,3中下游任务上表现出了SOTA性能。3D-language的C-MCR在zero-shot的3D点云分类任务上准确性也很高。
本文模型与方法:
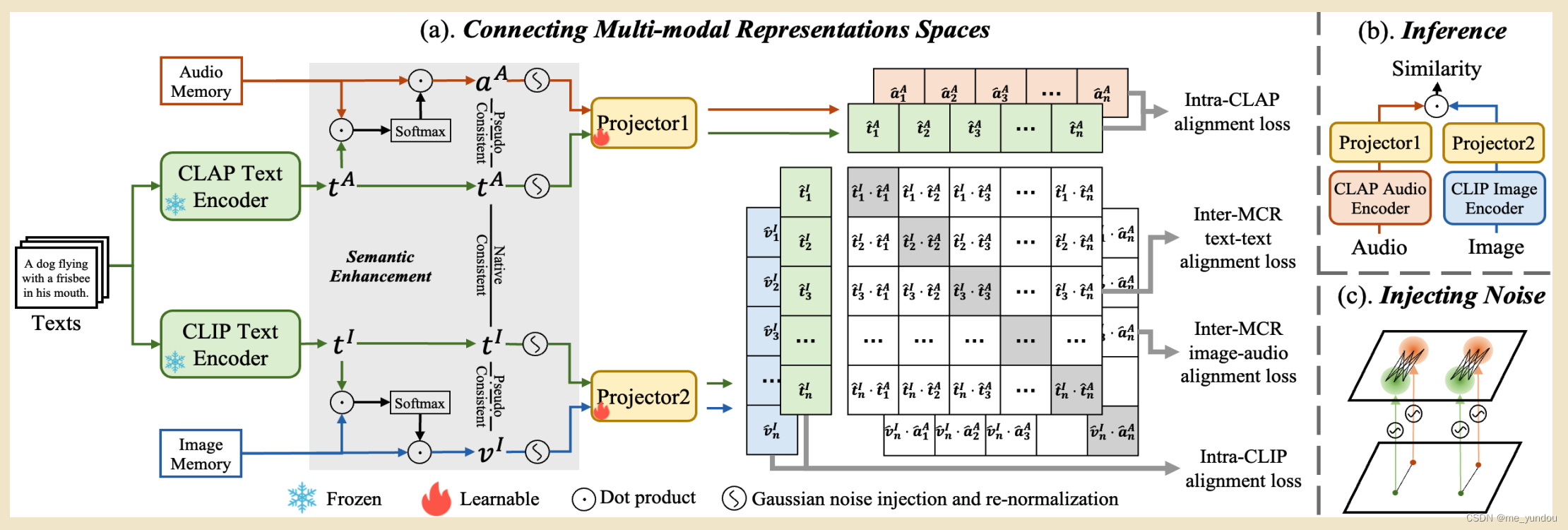
图1:本文C-MCR的pipeline
3.1 背景
问题定义:
以用text连接CLIP和CLAP构建audio-visual MCR为例子。
本文以text为输入数据,经过CLIP和CLAP的text encoder,分别得到和
,借助他俩的内在一致性对齐audio和visual模态。
多模态对比学习:
给定来自两个不同模态的N个text-image paired data,首先将N个text经过text encoder得到向量x,将N个image经过image encoder得到向量z。
那么多模态对比学习的目标是,最大化paired 的text embedding和image embedding的余弦相似性(cosine similarity),同时最小化不是来自一个pair的text emb和image emb的相似性。(在一般的MCR中,给定的数据都是paired的,意思是输入的一个text-image data是匹配的数据)
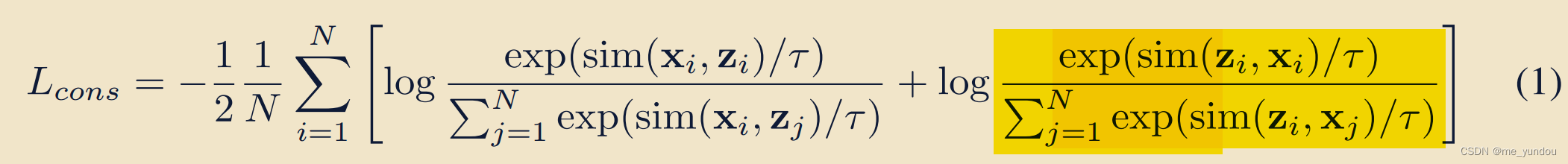
3.2 语义增强
inter-modality 语义一致性(Semantic Consistency):
先用大量的unpaired image和audio经过frozen的CLIP和CLAP模型,得到许多image emb和audio emb,放入image memory ![]() 和audio memory
和audio memory![]() 中。(从web上很容易爬取大量不配对的image和audio数据。现成的数据集中也有很多)
中。(从web上很容易爬取大量不配对的image和audio数据。现成的数据集中也有很多)
然后对每一个text input,经过frozen的CLIP和CLAP模型,得到和
;
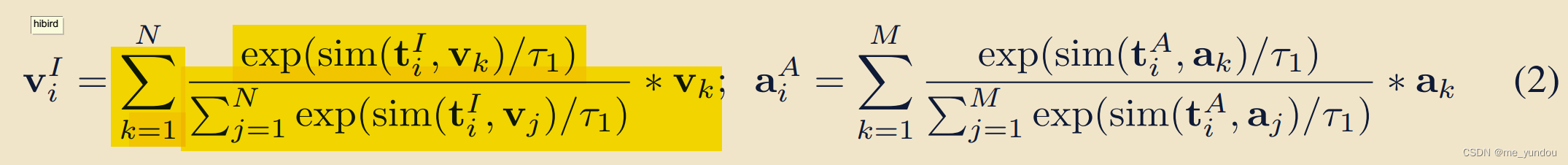
计算与image memory中所有image emb的sim值,根据sim权重对所有image emb加权求和,得到当前text伪匹配的image emb。同理,得到当前text伪匹配的audio emb。(我们可以这样理解:因为CLIP模型本身就是利用text emb和image emb的sim进行学习的。sim越大,说明这个text emb和image emb中语义相似点越多,将所有image emb中与当前text emb相似的部分都求和,就得到了比较语义丰富的image emb。类似一种语义增强了)
intra-modality 语义完整性(Semantic Completion):
另外,再对和
,以及上面公式2两个求和得到的image emb
和audio emb
,增加一个随机的高斯噪声,得到新的emb用于后面的计算。
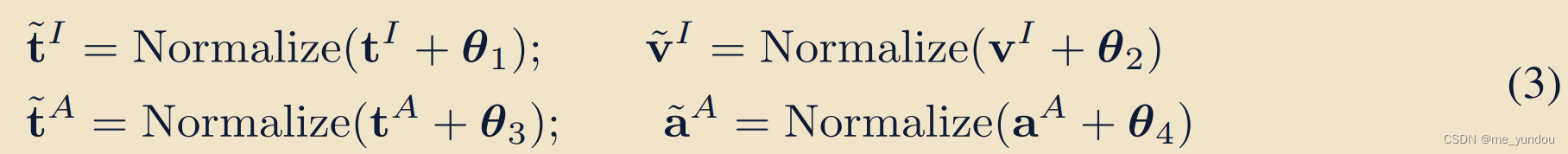
(通过加权求和和添加随机噪声两种方式,相当于是对image/audio信息做了一个semantic enhancement,解决了挑战1.)
3.3 inter-MCR 对齐
首先对上述学到的4个emb分别经过两个projector,来自同一个MCR的emb经过相同的projector,如下面的公式4。以把他们映射到同样的空间,方便对non-overlop的模态进行emb。
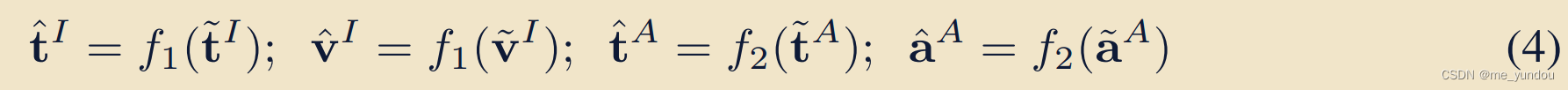
在新的映射后的空间,首先要保证相似语义的emb在空间中距离更近。
因此,由于 和
是同一个text得到的,所以他俩emb 的sim应该更相似,也就是比其他的 text对 高,这里就有一个对比loss了。
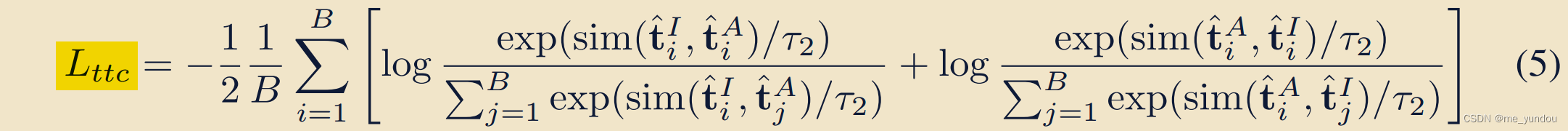
由于 和
是从同一个text伪配对得到的,因此我们传递pair关系,能够认为这个image emb和audio emb是伪配对的,就可以利用对比loss增强他俩的sim,又一个对比loss。
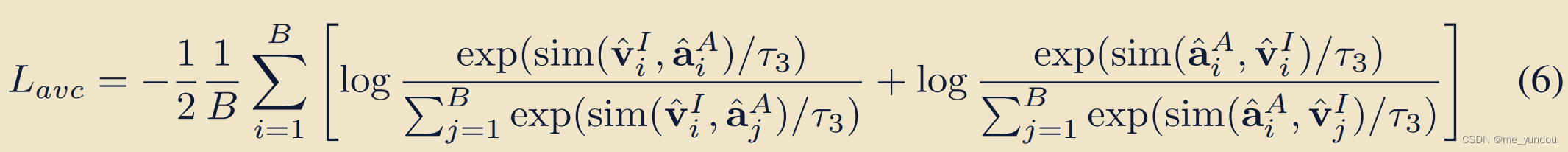
上述俩loss求和得到本文的L_inter.

3.4 intra-MCR 对齐
针对挑战2,研究[1]表明是由于对比loss中对负样本的约束造成的,一个典型的对比loss可以表示成如下公式8的形式,第一项就是正样本的约束,第二项是负样本的约束。所以本文的对比loss中去掉负样本的约束,只约束正样本的emb sim尽量大。
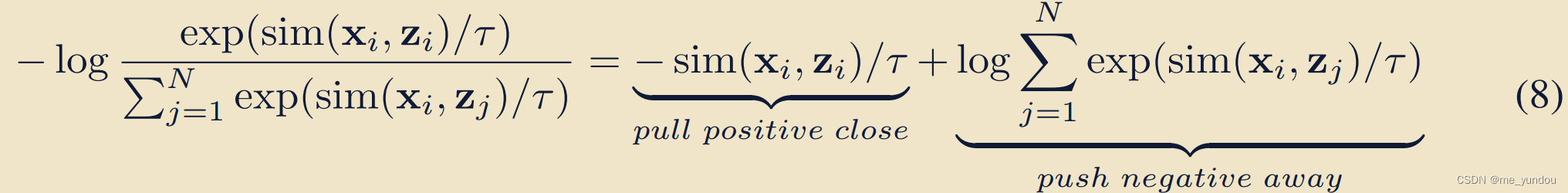
最后,分别增强text emb和image emb,text emb和audio emb的sim值,去掉对比loss中的负样本项之后,得到本文的L_intra。
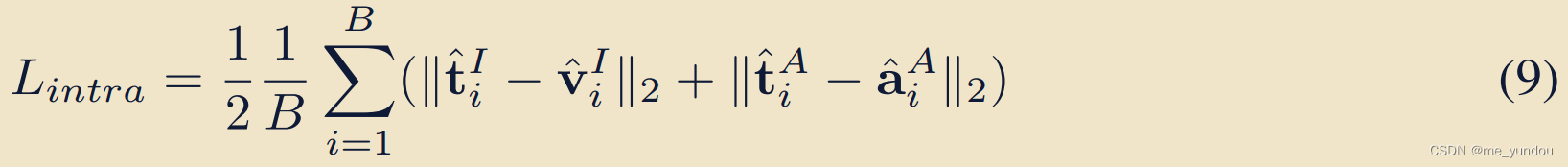
3.5 训练和推理
本文的training 目标:

本文在训练过程中,将所有的现有MCR的参数都frozen,比如CLIP,CLAP,ULIP,只更新C-MCR中两个projector的参数。
为了让训练更高效,本文提前使用现有的MCR模型得到text embeddings,并且计算得到语义增强之后的image emb 和audio emb
,把他们都保存在本地,方便后续使用。(因为这些操作都不含需要训练的模块)
推理过程:
如图1的右侧(b)所示,给定一个image和一个audio,分别输入CLIP和CLAP,然后再经过训练好的projectors,得到image emb和audio emb,计算他俩的余弦相似度作为他们的语义相似度。
实验结果及分析:
4.1 连接CLIP和CLAP的细节(连接ULIP和CLIP的见论文原文)
text数据集:image-text datasets (COCO and CC3M ), video-text datasets (MSRVTT, MAD), and audio-text datasets (AudioCap, Clotho)。这是为了保证这些text有足够的visual,action,audio信息。
audio/image memory:使用了AudioSet 和 ImageNet1K 数据集中的音频和图像数据(这些audio和image直接经过frozen 的CLIP和CLAP得到image emb和audio emb,构成memory),没有使用任何文本标注数据;
实现细节:frozen pre-trained CLIP ViT-B/32 model and CLAP model,projector是两层的多层感知机,其他超参数的设置见论文原文;
4.3 audio-visual 表征的评估
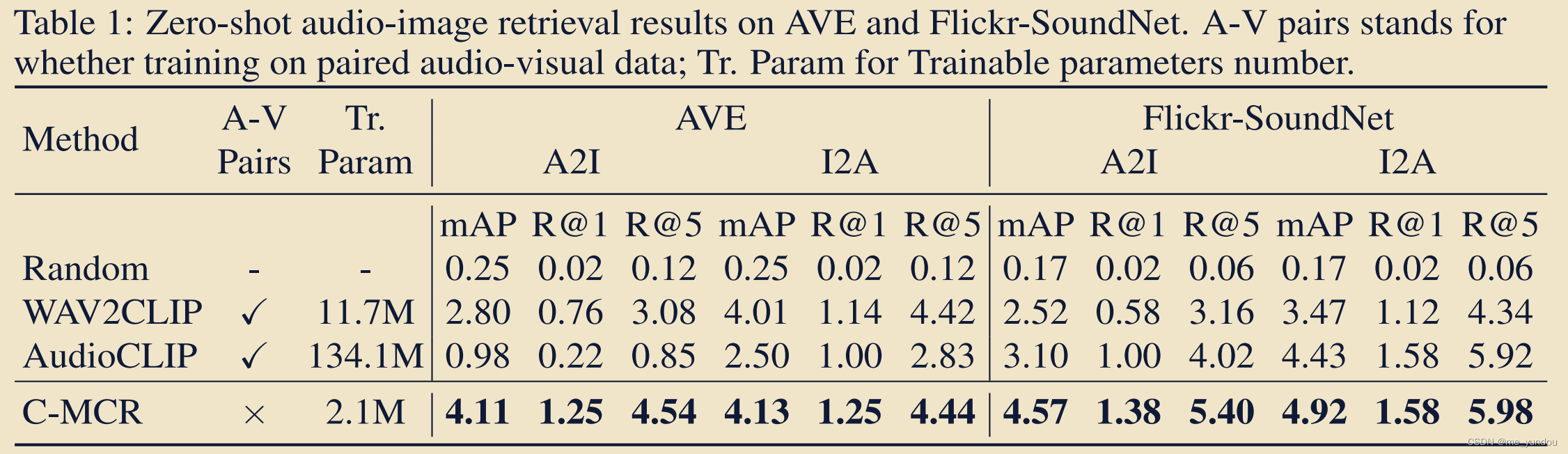
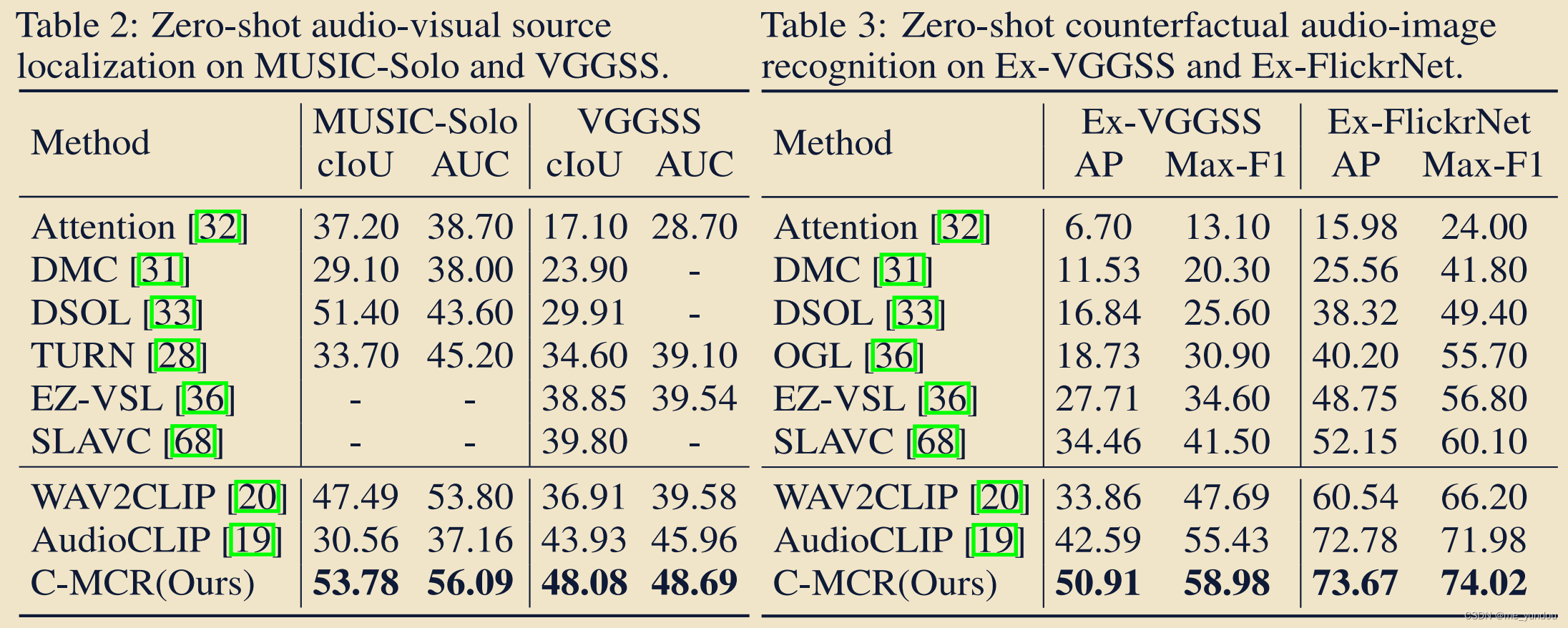
在下游三个任务上进行了测试(zero-shot的),表明本文模型的有效性。
任务:
- audio-image retrieval, 可以评估模型匹配粗粒度(coarse-grained)image和audio的能力;
- audio-visual source localization, 可以评估模型匹配细粒度(fine-grained)image objects和audio的能力;
- counterfactual audio-image recognition;可以评估模型对image和audio的理解和推理能力;
数据集:
- AVE and FlickrSoundNet(由于数据量太小,本文使用这些数据集中的所有train,eval,test数据进行测试),
- VGGSS and MUSIC;
- Extended VGGSS (Ex-VGGSS) and Extended Flickr-SoundNet (Ex-FlickrNet);
对比方法:AudioCLIP and WAV2CLIP;
结果:
本文的模型在各个数据集上都表现较好。而baseline在不同数据集上表现差异较大。而且本文的训练参数非常少。
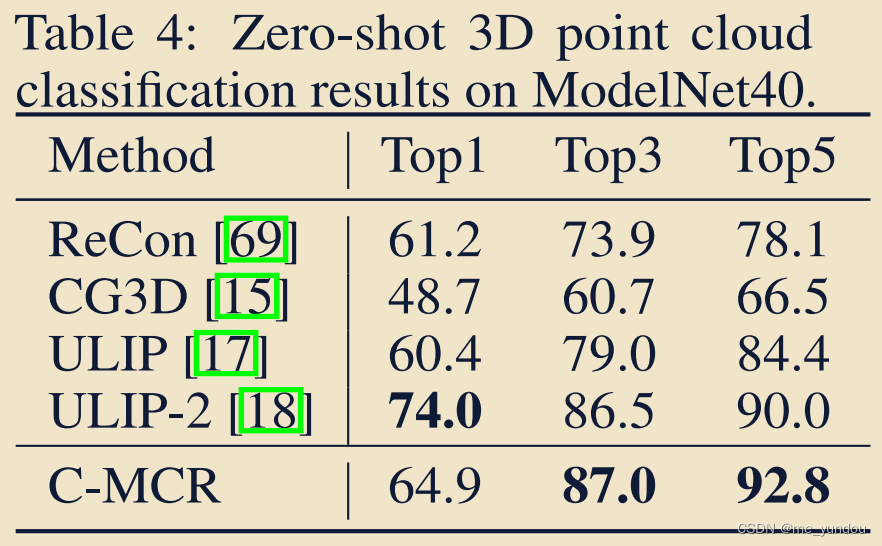
4.4 3D-language 表征的评估
任务:3D点云分类;
数据集:ModelNet40;
对比方法:见表4;
结果:
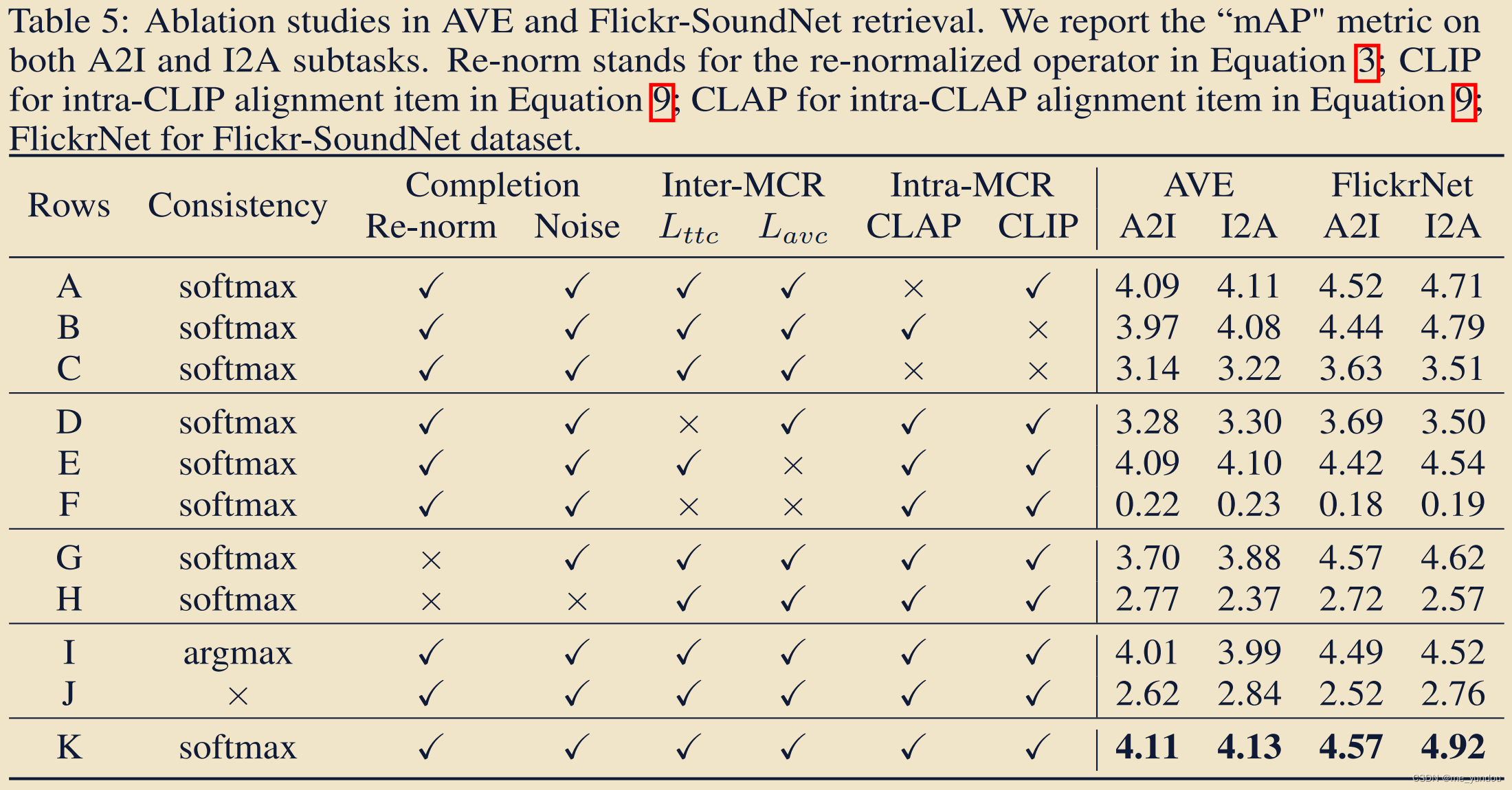
4.5 消融实验
本文对模型的下面几个部分进行了消融实验:
Semantic Consistency.,Semantic Completion.,Inter-MCR alignment.,Intra-MCR alignment.,
具体的消融实验实现方式见论文原文。
总结与展望:
本文提出了C-MCR,一个灵活的、训练高效的学习多模态对比表征的方法。C-MCR降低了对大规模高质量对齐数据的需求,通过对现有的MCR中多模态对齐知识的扩展实现MCR的学习。
通过借助overlap模态连接现有的MCR模型,作者能够在更多的模态中discover泛化性好的对比表征。
通过实验表明,本文模型学到了SOTA的audio-visual 对比表征,和3D-language表征。尽管没有使用任何paired data,C-MCR所学的表征在多个下游任务上都明显超过以前的从paired data中学习到的MCR的性能。
个人理解与问题:
(1)本文中CLIP,CLAP等其他MCR都是frozen参数的,只需要训练两个projector的参数,因此非常高效。而且输入数据都是unpaired 的image ,audio ,text,都很好获取。完美。
(2)本文需要理解的一个关键点是,在处理CLIP和CLAP的时候,模型的输入是text,对每一个text进行处理。而image和audio信息是提前输入到了frozen的CLIP和CLAP中得到memory了。在训练的时候,没有输入任何的image和audio,所以也没有输入pair信息。
(3)有一个疑问,为什么同一个MCR的两种模态数据要使用同样的projector呢?不能各自学习一个吗?或者两个MCR都学习一个共同的?这个projector的设置有什么物理含义吗?
参考文献:
[1] Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022.

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









