









简单说一下正则表达式中新加入的特性:
1)flags属性:
/abc/ig.flags//gi2)/u unicode标记,Chrome 48都还不支持这个标记
/\uD83D/.test('\uD83D\uDC2A')//true
/\uD83D/u.test('\uD83D\uDC2A')//false
/\uD83D/u.test('\uD83D \uD83D\uDC2A')//true
/\uD83D/u.test('\uD83D\uDC2A \uD83D')//true
/^[\uD83D\uDC2A]$/u.test('\uD83D\uDC2A')//true
/^[\uD83D\uDC2A]$/.test('\uD83D\uDC2A')//false
/^[\uD83D\uDC2A]$/u.test('\uD83D')//false
/^[\uD83D\uDC2A]$/.test('\uD83D')//true
'\uD83D\uDE80'.match(/./gu).length//1
'\uD83D\uDE80'.match(/./g).length//2
/\uD83D\uDE80{2}/u.test('\uD83D\uDE80\uD83D\uDE80')//true
/\uD83D\uDE80{2}/.test('\uD83D\uDE80\uD83D\uDE80')//false
/\uD83D\uDE80{2}/.test('\uD83D\uDE80\uDE80')//true
3)/y标记,看一下这个标记对一些函数的影响

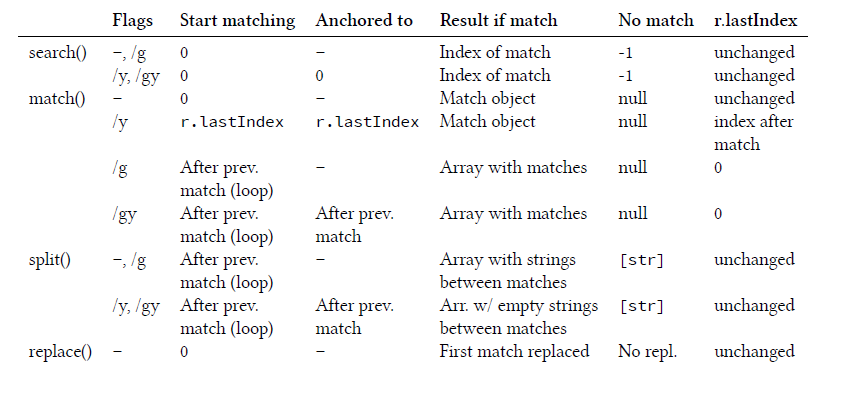

这个标记的一个用途就是用来分词:
function tokenize(TOKEN_REGEX, str) {
let result = [];
let match;
while (match = TOKEN_REGEX.exec(str)) {
result.push(match[1]);
}
return result;
}
const TOKEN_GY = /\s*(\+|[0-9]+)\s*/gy;
const TOKEN_G = /\s*(\+|[0-9]+)\s*/g;
tokenize(TOKEN_GY, '3 + 4')//[ '3', '+', '4' ]
tokenize(TOKEN_G, '3 + 4')//[ '3', '+', '4' ]
tokenize(TOKEN_GY, '3x + 4')//[ '3' ]
tokenize(TOKEN_G, '3x + 4')//[ '3', '+', '4' ]















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









