






pandas实战:
- 批量读取指定路径下文件并合并;
- merge函数的实际应用;
- groupby函数的实际应用;
- query函数的实际应用;
需求分析:
- 筛选客户.value包含244或4月,不同客户的不同网络类型的卡量分组计数;
- 不同客户的不同网络类型的key“本月池内用量(MB)”求和/1024;
- 不同客户不同出卡月份不同网络类型下,激活日期不为空的卡量计数;
- 不同客户不同出卡月份不同网络类型下,激活日期为2024-04的卡量计数;
- 激活日期为2024-04,每天的激活卡数量;
- 激活日期为2023-03,同期每天的激活卡数量;
- 4月不同的卡池不同区间用量的卡数量;
- 4月不同的卡池不同卡状态的卡数量;
00导入相应的包
import pandas as pd
import os
01批量读取指定路径下文件,将需要合并相同格式的csv文件放入一个文件夹内,直接调用即可。
def concat_csv(folder_name, save_path):
if os.path.exists(save_path):
df_all = pd.read_csv(save_path)
return df_all
listdir = os.listdir(folder_name)
df_list_1 = []
for f in listdir:
if not f.endswith("csv"):
continue
chunks = pd.read_csv(folder_name + os.sep + f, converters={'ICCID': str, 'MSISDN': str},
chunksize=100000) # 分块读取
for chunk in chunks: # 分块读取
df_list_1.append(chunk) # 建成列表
df_all = pd.concat(df_list_1, axis=0, ignore_index=True)
df_all.to_csv(save_path, index=False)
print('已合并,长度为{}, 文件路径{}'.format(len(df_all), save_path))
return df_all
02数据准备,使用merge内连接表格,匹配数据。
def total_match():
# 调用concat_csv()函数,参数1为文件夹所在路径,参数2为合并后的文件路径,包含卡号、激活日期字段
df_all = concat_csv('E:\qushu\lifes', 'E:\qushu\life\concat.csv')
# 读取指定路径下文件,包含卡号、用量、卡状态等字段
yl_dir = r"E:\qushu\usage"
for filename in os.listdir(yl_dir):
if not filename.endswith("csv"):
continue
file_path = os.path.join(yl_dir, filename)
usage_information = pd.read_csv(file_path)
# 两个文件分别命名为4G和5G,并增加新列[key:网络,value:4G,5G]
usage_information['网络'] = filename[:2]
usage_information.to_csv(file_path, index=None) # 合并写入
# 调用concat_csv函数,参数1为文件夹所在路径,参数2为合并后的文件路径
df_yl = concat_csv(yl_dir, 'E:\qushu\yl2.csv')
# 直接读取所需的第三个数据表,包含客户名称及出卡月份
total = pd.read_excel(r'C:\Users\Administrator\Desktop\MIFI数据总表.xlsx')
# 三个文件预处理,去除空字符串
three = [df_yl, df_all, total]
new_three = [i.replace('\s+', '', regex=True, inplace=True) for i in three]
# 表连接,根据ICCID列内连接客户、激活日期,并写入文件
client = df_yl.merge(total[["客户", "ICCID"]], on='ICCID', how='left')
general = client.merge(df_all[["激活日期", 'ICCID']], on='ICCID', how='left')
general.to_csv('E:\qushu\General_table.csv', index=False)
return general
# 由于前面对3个数据表去除了空字符串,包括0000-00-00 00:00:00中的空格
# 因此激活日期列切片,取年月日0000-00-00格式
def date_tiqu(date1):
return date1[:10]
03根据业务需求,筛选并分组计算数据
def remark():
# 数据写入Customer_Data表
with pd.ExcelWriter("E:\qushu\Customer_Data.xlsx", engine='xlsxwriter') as writer:
# 读取total_match()函数处理合并后的3个数据表
general = pd.read_csv(r'E:\qushu\General_table.csv')
# 不同网络类型卡量计数,并写入sheet1,命名为"备注"
client1 = general.groupby('网络')['ICCID'].count()
client1.to_excel(writer, sheet_name="备注", index=True) # 写入sheet1
# 剔除本月池内用量(MB)列的逗号并转化为浮点型
general['本月池内用量(MB)'] = general['本月池内用量(MB)'].replace(",", "", regex=True).astype(float)
# 不同客户的不同网络类型的用量合计
flow = general.groupby(['客户', '网络']).aggregate({'本月池内用量(MB)': "sum"})
# 筛选客户.value中包含244或4月的行
condition = ['4月', '244']
gen_filter = general[general['客户'].str.contains('|'.join(condition), na=True)]
# for i in range(0,len(gen_filter)):
# num = gen_filter.iloc[i]['本月池内用量(MB)']
# if str(num) !='0.000':
# print(num)
# 4月不同客户的不同网络类型的卡量计数
client2 = gen_filter.groupby(['客户', '网络'])['ICCID'].count()
# 激活日期列空值填充为空字符串,筛选日期不为空的行,不同客户不同出卡批次不同网络类型下的激活数
general_fillna = general.fillna({"激活日期": ""})
activation = general_fillna.query("激活日期 !='' ").groupby(['客户', '网络'])['ICCID'].count()
# 模糊筛选2024年4月激活卡数,按照不同客户不同出卡批次不同网络类型计数
data_filter = general_fillna.query("激活日期.str.startswith('2024-04')", engine='python')
activation4 = data_filter.groupby(['客户', '网络'])['ICCID'].count()
'''
将上面计算出来的flow,client2,activation,activation4根据客户、网络进行外连接,并写入sheet2
'''
# 将Series转化为Dataframe结构
df_client2 = client2.reset_index()
for series in [flow, activation, activation4]:
new_df = pd.DataFrame(series)
new_df.columns = ["count"]
new_df.reset_index(inplace=True)
df_client2 = df_client2.merge(new_df, on=['客户', '网络'], how='outer', suffixes=('', '_2'))
# 更改列名
df_client2.columns = ["客户", "网络", "卡量", "本月池内用量(MB)", "激活数", "4月激活卡数"]
# 写入sheet2,命名为'MIFI数据总汇(新)'
df_client2.to_excel(writer, sheet_name="MIFI数据总汇(新)", index=None) # 写入sheet2
# 模糊筛选激活日期为3月或4月的行
date_filter34 = general_fillna.query("激活日期.str.startswith('2024-04') or 激活日期.str.startswith('2024-03')",engine='python')
# 新增一列激活日期,格式为0000-00-00
date_filter34['激活日期'] = date_filter34['激活日期'].map(date_tiqu)
# 计算3月和4月每天的激活卡数量,并写入sheet3,命名为'激活卡情况'
df_date = date_filter34.groupby('激活日期')['ICCID'].count()
df_date.to_excel(writer, sheet_name="激活卡情况", index=True) # 写入sheet3
# 新增一列计算列,将MB转换为GB
general['本月池内用量GB'] = general['本月池内用量(MB)'].map(lambda x: x / 1024)
# 创建字典
net_dict = {
"4G": {
'大于20G': '本月池内用量GB >=20',
'10G-20G': '本月池内用量GB>=10 and 本月池内用量GB<20',
'0-10G': '本月池内用量GB>0 and 本月池内用量GB<10',
'0': '本月池内用量GB==0'
},
"5G": {
'大于50G': '本月池内用量GB >=50',
'25G-50G': '本月池内用量GB>=25 and 本月池内用量GB<50',
'0-25G': '本月池内用量GB>0 and 本月池内用量GB<25',
'0': '本月池内用量GB==0'
}
}
# 空列表每次追加一行,遍历字典,不同区间内计数
data_list = []
for net, inder_dict in net_dict.items():
for k, v in inder_dict.items():
value_counts1 = [f"{net}", k, len(general.query(f"{v} and 网络=='{net}'"))]
data_list.append(value_counts1)
# 更改列名
df_pools = pd.DataFrame(data_list, columns=['网络', '区间', '卡池数'])
df_pools.to_excel(writer, sheet_name="卡池分布", index=None) # 写入sheet4
# 当月激活卡数
df_activation1 = general_fillna.query("激活日期.str.startswith('2024-04') and 卡状态=='已激活'",
engine='python').groupby('网络')['ICCID'].count()
# 近3个月激活卡数
df_activation2 = general_fillna.query("激活日期 < '2024-03' and 激活日期 > '2024-01' and 卡状态=='已激活'",
engine='python').groupby('网络')['ICCID'].count()
# 3个月之前激活卡数
df_activation3 = general_fillna.query("激活日期 < '2024-01' and 卡状态=='已激活'",
engine='python').groupby('网络')['ICCID'].count()
# 不同网络不同卡状态激活卡数
df_activation4 = general.groupby(['网络', '卡状态'])['ICCID'].count()
# Series转化为Dataframe结构
df_activation = df_activation1.reset_index()
for series in [df_activation2, df_activation3, df_activation4]:
new_df = pd.DataFrame(series)
new_df.columns = ["count"]
new_df.reset_index(inplace=True)
df_activation = df_activation.merge(new_df, on=['网络'], how='outer', suffixes=('', '_2')) # 表外连接
df_activation.columns = ["网络", "本月激活", "近3个月激活", "3个月前激活", "卡状态", "卡数量"] # 更改列名
df_activation.to_excel(writer, sheet_name="卡状态分布", index=None) # 写入sheet5
if __name__ == '__main__':
total_match()
remark()
输出展示:
sheet1数据展示
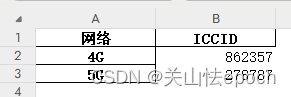
sheet2数据展示(客户名称已码)
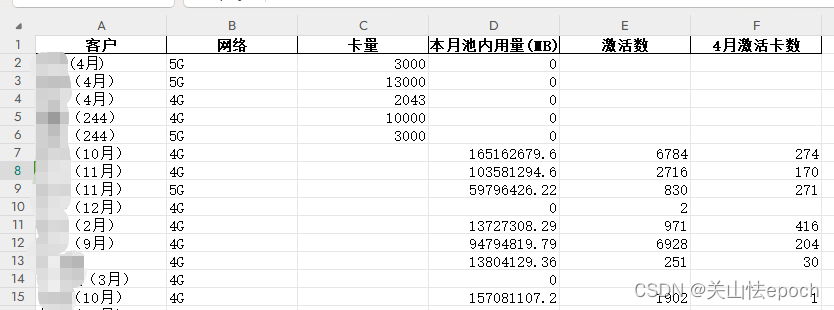
sheet3数据展示

sheet4数据展示
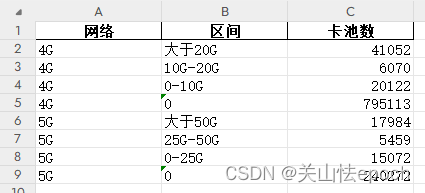
sheet5数据展示
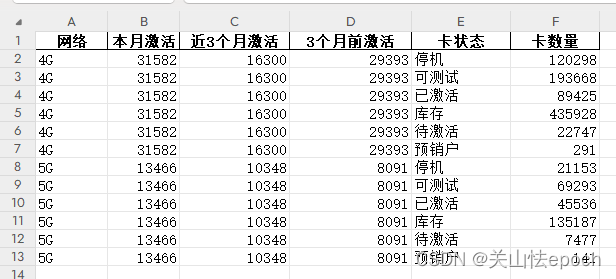
涉及企业内部数据,数据不公开,欢迎评论指正或私聊。转载请标明出处,谢谢。















 6960
6960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









