







如有需要,评论私发数据原表(本文利用R语言)
平稳序列的拟合与预测
1.1DF检验
类型一:无漂移项自回归结构
类型二:有漂移项自回归结构
类型三:带趋势回归结构
【例2-3续(2)】对1915-2004年澳大利亚自杀率序列(每10万人自杀人口数)进行DF检验,判断该序列的平稳性。
在例2-3中,我们通过图检验方法判断该序列为非平稳性,但这种判断带有很强的个人主观色彩和经验主义,现在借助DF统计量,进行序列的平稳性检验( α = 0.05 \alpha=0.05 α=0.05)
R语言中有多个函数可以进行平稳性检验,我们利用aTSA包中的adf.test函数,该函数的命令格式为:
adf.test(x,nlag=)
式中:
- x:进行平稳性检验的序列名
- nlag:最高延迟阶数。
- 若nlag=1,输出自回归0阶延迟平稳性检验结果;
- 若nlag=2,输出自回归0至1阶延迟平稳性检验结果;
- 若用户不特殊指定延迟阶数,系统会自动指定延迟阶数。
> #下载并调用aTSA包,使用adf.test函数进行DF检验
> library(readxl)
> A1_6 <- read_excel("C:/Users/86158/Desktop/A1_6.xlsx")
> View(A1_6)
> install.packages("aTSA")
> library(aTSA)
> Suicide<-ts(A1_6$Suicide,start=1915)
> adf.test(Suicide,nlag=2)
DF检验输出结果如下:
Augmented Dickey-Fuller Test
alternative: stationary
Type 1: no drift no trend
lag ADF p.value
[1,] 0 -1.39 0.179
[2,] 1 -1.32 0.204
Type 2: with drift no trend
lag ADF p.value
[1,] 0 -1.98 0.337
[2,] 1 -1.31 0.586
Type 3: with drift and trend
lag ADF p.value
[1,] 0 -2.29 0.449
[2,] 1 -1.65 0.719
----
Note: in fact, p.value = 0.01 means p.value <= 0.01
检验结果显示,如果序列的结构考虑如上三种类型(六种子类型)的话, τ \tau τ统计量的P值均显著大于显著性水平( α = 0.05 \alpha=0.05 α=0.05),因此可以判断,如果序列考虑如上6种结构之一提取确定性信息,则随机性部分 ξ t \xi_t ξt都不能实现平稳,也就是说1915-2004年澳大利亚自杀率序列是非平稳序列。
1.2ADF检验
【例2-5续(1)】对1900-1998年全球7.0级以上地震发生次数序列进行ADF检验,判断该序列的平稳性。
该序列我们在例2-5通过图检验,判断该序列平稳,现在基于ADF检验,对序列的平稳性进行统计检验。
> #读入序列,并使用adf.test函数进行ADF检验
> A1_7 <- read_excel("C:/Users/86158/Desktop/A1_7.xlsx")
> View(A1_7)
> number<-ts(A1_7$number,start=1900)
> library(aTSA)
> adf.test(number)
ADF检验结果输出:
Augmented Dickey-Fuller Test
alternative: stationary
Type 1: no drift no trend
lag ADF p.value
[1,] 0 -1.585 0.109
[2,] 1 -1.045 0.304
[3,] 2 -0.653 0.445
[4,] 3 -0.509 0.497
Type 2: with drift no trend
lag ADF p.value
[1,] 0 -5.35 0.0100
[2,] 1 -3.92 0.0100
[3,] 2 -3.18 0.0245
[4,] 3 -2.96 0.0450
Type 3: with drift and trend
lag ADF p.value
[1,] 0 -5.55 0.0100
[2,] 1 -4.14 0.0100
[3,] 2 -3.51 0.0448
[4,] 3 -3.37 0.0634
----
Note: in fact, p.value = 0.01 means p.value <= 0.01
检验结果显示,类型二和类型三各州模型的 τ \tau τ统计量的P值均小于显著性水平( α = 0.05 \alpha=0.05 α=0.05),所以可以认为该序列显著平稳。
1.3模型识别
【例4-1】选择合适的模型拟合1900-1998年全球7级以上地震发生次数序列(数据见表A1-7)
> #绘制该序列自相关图和偏自相关图
> acf(number)
> pacf(number)
从本例的自相关图可以看出,自相关系数是以一种有规律的方式,按指数函数轨迹衰减的,这说明自相关系数衰减到零不是一个突然截尾的过程,而是一个连续渐变的过程,这是自相关系数拖尾的典型特征,我们可以把拖尾特征形象地描述为“坐着滑梯落水”。
从本例的偏自相关图可以看出,除了1阶偏自相关系数在2倍标准差范围之外,其他阶数的偏自相关系数都在2倍标准差范围内,这是一个偏自相关系数1阶截尾的典型特征,我们可以把这种截尾特征形象地描述为“1阶之后高台跳水”。
本例中,根据自相关系数拖尾,偏自相关系数1阶截尾地属性,我们可以初步确定拟合模型为AR(1)模型。
【例4-2】选择合适的模型拟合美国科罗拉多州某个加油站连续57天的盈亏(overshort)序列(数据见表A1_8).
> #读入数据文件后,绘制时序图
> library(readxl)
> A1_8 <- read_excel("C:/Users/86158/Desktop/A1_8.xlsx")
> View(A1_8)
> overshort<-ts(A1_8$overshort)
> plot(overshort)
> #ADF检验
> adf.test(overshort)
点击查看加油站每日盈亏序列时序图
ADF检验结果输出:
Augmented Dickey-Fuller Test
alternative: stationary
Type 1: no drift no trend
lag ADF p.value
[1,] 0 -13.04 0.01
[2,] 1 -7.32 0.01
[3,] 2 -7.01 0.01
[4,] 3 -6.04 0.01
Type 2: with drift no trend
lag ADF p.value
[1,] 0 -13.10 0.01
[2,] 1 -7.46 0.01
[3,] 2 -7.38 0.01
[4,] 3 -6.61 0.01
Type 3: with drift and trend
lag ADF p.value
[1,] 0 -12.99 0.01
[2,] 1 -7.39 0.01
[3,] 2 -7.34 0.01
[4,] 3 -6.60 0.01
----
Note: in fact, p.value = 0.01 means p.value <= 0.01
纯随机性检验:
> for(k in 1:2)print(Box.test(overshort,lag=6*k))
纯随机性检验结果输出:
Box-Pierce test
data: overshort
X-squared = 19.002, df = 6, p-value = 0.00416
Box-Pierce test
data: overshort
X-squared = 28.204, df = 12, p-value = 0.005164
绘制自相关图和偏自相关图:
> acf(overshort)
> pacf(overshort)
时序图显示该序列没有明显的趋势或周期特征,说明该序列没有显著的非平稳特征。进一步进行ADF检验,判断该序列的平稳性。ADF检验结果显示,该序列所有ADF检验统计量的P值均小于显著性水平( α = 0.05 \alpha=0.05 α=0.05),所以可以确认该序列为平稳序列。再对平稳序列进行纯随机性检验,纯随机性检验结果显示,6阶和12阶延迟的LB统计量的P值都小于显著性水平( α = 0.05 \alpha=0.05 α=0.05),所以可以判断该序列为平稳非白噪声序列,可以使用ARMA模型拟合该序列。最后考察该序列的样本自相关图和偏自相关图的特征,给ARMA模型定阶。
自相关图显示除了延迟1阶的自相关系数在2倍标准差范围之外,其他阶数的自相关系数都在2倍标准差范围内波动,且自相关系数衰减没有显著的规律性。偏自相关图显示出有规律的衰减,这是偏自相关系数拖尾的特征。综合该序列自相关系数1阶截尾和偏自相关系数拖尾的特征,我们将该序列的拟合模型定阶为MA(1).
【例4-3】选择合适的模型拟合1880-1985年全球气表平均温度改变值差分序列(全球气表平均温度改变值序列见表A1_9)。
> library(readxl)
> A1_9 <- read_excel("C:/Users/86158/Desktop/A1_9.xlsx")
> View(A1_9)
> #读入数据文件后,对气表平均温度改变值序列进行差分运算,对差分后序列绘制时序图
> dif<-diff(A1_9$change)
> dif<-ts(dif,start=1880)
> plot(dif)
> #ADF检验
> adf.test(dif)
> #ADF检验结果输出
Augmented Dickey-Fuller Test
alternative: stationary
Type 1: no drift no trend
lag ADF p.value
[1,] 0 -13.13 0.01
[2,] 1 -9.60 0.01
[3,] 2 -8.97 0.01
[4,] 3 -7.62 0.01
[5,] 4 -7.68 0.01
Type 2: with drift no trend
lag ADF p.value
[1,] 0 -13.08 0.01
[2,] 1 -9.58 0.01
[3,] 2 -8.98 0.01
[4,] 3 -7.71 0.01
[5,] 4 -7.85 0.01
Type 3: with drift and trend
lag ADF p.value
[1,] 0 -13.01 0.01
[2,] 1 -9.53 0.01
[3,] 2 -8.94 0.01
[4,] 3 -7.67 0.01
[5,] 4 -7.82 0.01
----
Note: in fact, p.value = 0.01 means p.value <= 0.01
> #纯随机性检验
> for(k in 1:2)print(Box.test(dif,lag=6*k))
> #纯随机性检验结果输出
Box-Pierce test
data: dif
X-squared = 16.595, df = 6, p-value = 0.01089
Box-Pierce test
data: dif
X-squared = 24.597, df = 12, p-value = 0.01685
> #绘制自相关图和偏自相关图
> acf(dif)
> pacf(dif)
点击查看全球气表平均温度改变值差分序列时序图、自相关图和偏自相关图
时序图显示该序列没有明显的趋势或周期特征。进一步进行ADF检验,检验结果显示该序列显著平稳。接下来检验序列的纯随机性,LB检验结果显示该序列为非白噪声序列。所以全球气表平均温度改变值差分序列是平稳非白噪声序列,可以使用ARMA模型拟合该序列。接下来,序列的自相关图和偏自相关图均显示出不截尾的性质,因此可以尝试使用ARMA(1,1)模型拟合该序列。
1.4参数估计
R语言中,ARMA模型的参数估计可以通过调用arima函数完成,该函数的命令格式为:
arima(x,order=,include.mean=,method=)
式中:
- x:要进行模型拟合的序列名
- order=c(p,d,q):指定模型阶数
(1)p为自回归阶数
(2)d为差分阶数,本节不涉及差分问题,故d=0
(3)q为移动平均阶数 - include.mean:模型中要不要包含均值
(1)include.mean=T,模型中需要拟合均值,这也是系统默认设置
(2)include.mean=F,模型中不需要拟合均值 - method:指定参数估计方法
(1)method=“CSS-ML”,默认的是条件最小二乘与极大似然估计混合方法
(2)method=“ML”,极大似然估计方法
(3)method="CSS"条件最小二乘估计方法
【例4-1续(1)】使用极大似然估计方法确定1900-1998年全球7级以上地震发生次数序列拟合模型的口径。
根据该序列自相关图和偏自相关图,我们将该序列定阶为AR(1)模型,使用极大似然估计确定该模型的口径,相关命令和输出结果如下:
> #拟合AR(1)模型
> fit1<-arima(number,order=c(1,0,0),method="ML")
> fit1
> #模型拟合结果
Call:
arima(x = number, order = c(1, 0, 0), method = "ML")
Coefficients:
ar1 intercept
0.5432 19.8911
s.e. 0.0840 1.3179
sigma^2 estimated as 36.7: log likelihood = -318.98, aic = 643.97
输出结果分为三部分:
- 说明拟合变量和拟合模型;
- 输出参数估计结果,第一行输出的是参数估计值,第二行输出的是对应参数样本标准差;
- 输出残差序列方差估计值,对数似然函数值和AIC信息量。
根据输出结果,我们确定该模型口径为:
x
t
−
19.8911
=
ε
t
1
−
0.5432
B
,
V
a
r
(
ε
t
)
=
36.7
x_t-19.8911=\frac{\varepsilon_t}{1-0.5432B},Var(\varepsilon_t)=36.7
xt−19.8911=1−0.5432Bεt,Var(εt)=36.7
或者对输出参数进行适当变换
ϕ
0
=
μ
(
1
−
ϕ
1
)
=
19.8911
×
(
1
−
0.5432
)
=
9.0863
\phi_0=\mu(1-\phi_1)=19.8911\times(1-0.5432)=9.0863
ϕ0=μ(1−ϕ1)=19.8911×(1−0.5432)=9.0863
该AR(1)模型可以等价表达为:
x
t
=
9.0863
+
0.5432
x
t
−
1
+
ε
t
,
V
a
r
(
ε
t
)
=
36.7
x_t=9.0863+0.5432x_{t-1}+\varepsilon_t,Var(\varepsilon_t)=36.7
xt=9.0863+0.5432xt−1+εt,Var(εt)=36.7
【例4-2续(1)】确定美国科罗拉多州某个加油站连续57天的盈方序列拟合模型的口径。
在例4-2中,我们将该序列的拟合模型定价为MA(1)模型,使用条件最小二乘估计方法确定该模型的口径,相关命令和输出结果如下:
> #拟合MA(1)模型
> fit2<-arima(overshort,order=c(0,0,1),method="CSS")
> fit2
> #模型拟合结果
Call:
arima(x = overshort, order = c(0, 0, 1), method = "CSS")
Coefficients:
ma1 intercept
-0.8208 -4.4095
s.e. 0.0996 1.1655
sigma^2 estimated as 2105: part log likelihood = -298.96
根据输出结果,我们确定该模型口径为: x t = − 4.4095 + ε t − 0.8208 ε t − 1 , V a r ( ε t ) = 2105 x_t=-4.4095+\varepsilon_t-0.8208\varepsilon_{t-1},Var(\varepsilon_t)=2105 xt=−4.4095+εt−0.8208εt−1,Var(εt)=2105
【例4-3续(1)】确定1880-1985年全球气表平均温度改变值差分序列拟合模型的口径.
在例4-3中,我们将该序列的拟合模型定阶为ARMA(1,1)模型,使用条件最小二乘估计确定该模型的口径,相关命令和输出结果如下:
> #拟合ARMA(1,1)模型
> fit3<-arima(dif,order=c(1,0,1))
> fit3
> #模型拟合结果
Call:
arima(x = dif, order = c(1, 0, 1))
Coefficients:
ar1 ma1 intercept
0.3926 -0.8867 0.0053
s.e. 0.1180 0.0604 0.0024
sigma^2 estimated as 0.01541: log likelihood = 69.66, aic = -131.32
根据输出结果,我们确定该模型口径为:
x
t
−
0.0053
=
1
−
0.8867
B
1
−
0.3926
B
ε
t
,
V
a
r
(
ε
t
)
=
0.01541
x_t-0.0053=\frac{1-0.8867B}{1-0.3926B}\varepsilon_t,Var(\varepsilon_t)=0.01541
xt−0.0053=1−0.3926B1−0.8867Bεt,Var(εt)=0.01541
或者对输出参数进行适当变换
ϕ
0
=
μ
(
1
−
ϕ
1
)
=
0.0053
×
(
1
−
0.3926
)
=
0.0032
\phi_0=\mu(1-\phi_1)=0.0053\times(1-0.3926)=0.0032
ϕ0=μ(1−ϕ1)=0.0053×(1−0.3926)=0.0032
该ARMA(1,1)模型可以等价表达为:
x
t
=
0.0032
+
0.3926
x
t
−
1
+
ε
t
−
0.8867
ε
t
−
1
,
V
a
r
(
ε
t
)
=
0.01541
x_t=0.0032+0.3926x_{t-1}+\varepsilon_t-0.8867\varepsilon_{t-1},Var(\varepsilon_t)=0.01541
xt=0.0032+0.3926xt−1+εt−0.8867εt−1,Var(εt)=0.01541
1.5模型检验
1.5.1模型的显著性检验
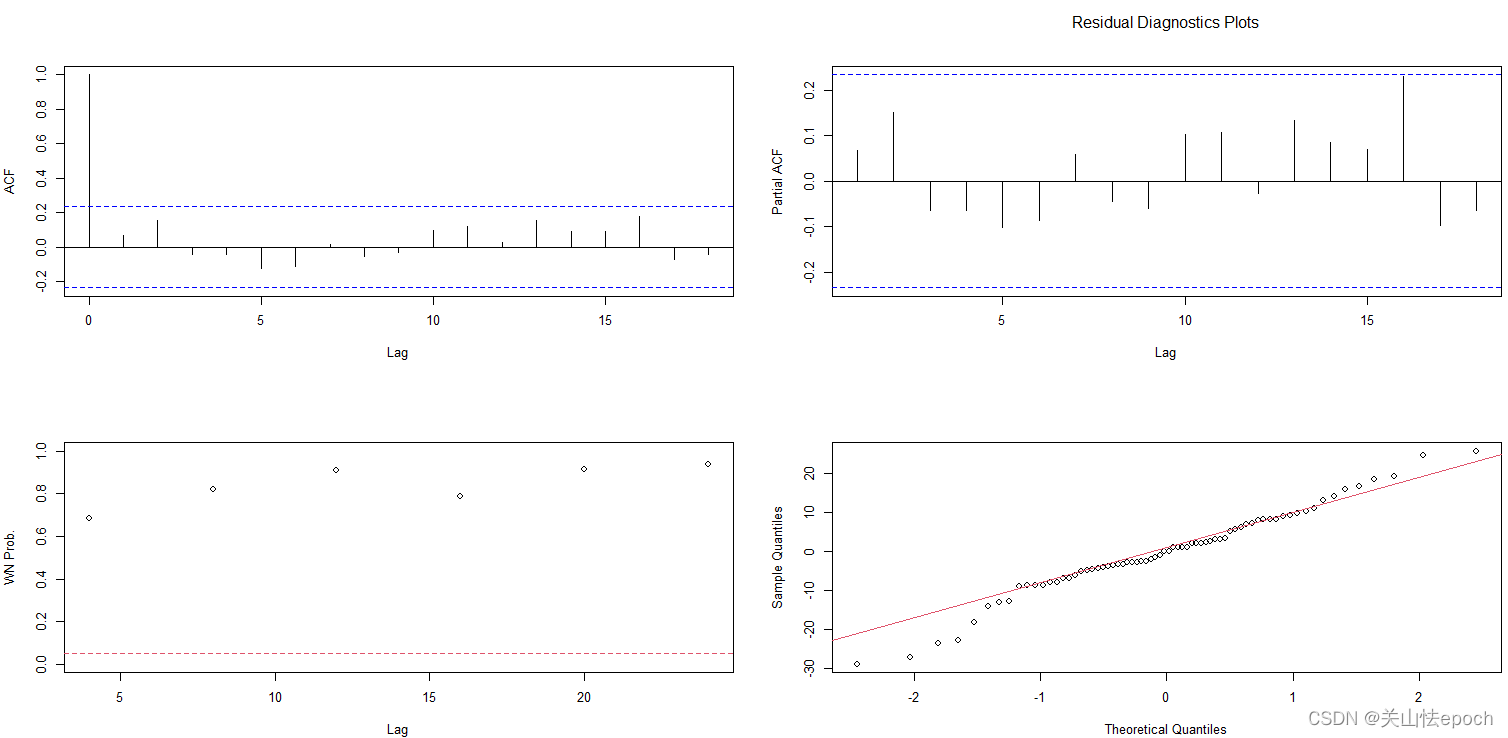
调用R语言aTSA包中的ts.diag函数,可以进行ARMA模型显著性检验,该函数的命令格式为:
ts.diag(object)
式中:
- object:指ARIMA函数拟合结果,调用ts.diag函数会输出四个图:
(1)左上:残差序列自相关图;
(2)右上:残差序列偏自相关图;
如果该拟合模型不能通过显著性检验,这两个相关图可以帮助用户重新定阶。
(3)左下:残差序列白噪声检验图。这个图的横轴是延迟阶数,纵轴是该延迟阶数纯随机性检验(Q统计量)的P值,这个图可以帮助我们直观判断拟合模型是否显著成立。
如果所有Q统计量的P值都在0.05显著性参考线之上,可以认为该模型显著成立。
(4)右下:残差序列正态性检验QQ图。我们可以利用QQ图来对序列进行正态分布假定的检验。QQ图横轴为正态分布的分位数,纵轴为样本分位数,如果这两者构成的点密集地分布在对角线左右,就认为该序列近似服从正态分布。
【例4-1续(2)】检验1900-1998年全球7级以上地震发生次数序列拟合模型的显著性( α = 0.05 \alpha=0.05 α=0.05).
我们对该序列拟合了AR(1)模型,拟合模型显著性检验的相关命令和输出结果如下:
> #拟合模型显著性检验
> library(aTSA)
> ts.diag(fit1)
考察残差序列的白噪声检验结果(左下),可以看出各阶延迟下白噪声检验统计量的P值都显著大于0.05(虚线为0.05参考线),我们可以认为这个拟合模型的残差序列属于白噪声序列,即该拟合模型显著成立。
1.5.3参数的显著性检验
使用arima函数为该序列拟合AR(1)模型,系统会输出各参数的估计值和系数估计值的样本标准差,但输出内容不包括各参数的t统计的值和检验P值。如果用户想获得参数检验统计量的P值,调用t统计量积累分布函数pt即可求得该统计量的P值,pt函数的命令格式为:
pt(t,df=,lower.tail=)
式中:
- t:t统计量的值.
- df:自由度.
- lower.tail:确定计算概率的方向.
(1)lower.tail=T,计算 P r ( X ⩽ x ) Pr(X \leqslant x) Pr(X⩽x).对于参数显著性检验,如果参数估计值为负,选择lower.tail=T.
(2)lower.tail=F,计算 P r ( X ⩾ x ) Pr(X \geqslant x) Pr(X⩾x).对于参数显著性检验,如果参数估计值为正,选择lower.tail=F.
【例4-1续(3)】检验1900-1998年全球七级以上地震发生次数序列拟合模型参数的显著性 ( α = 0.05 ) (\alpha=0.05) (α=0.05)
- 参数显著性检验方法一:因为该序列样本容量足够大(序列长度99),所以我们可以基于近似正态分布,非常便捷地得到参数显著性检验结果.
> #调用模型拟合结果
> fit1
> #输出结果
Call:
arima(x = number, order = c(1, 0, 0), method = "ML")
Coefficients:
ar1 intercept
0.5432 19.8911
s.e. 0.0840 1.3179
sigma^2 estimated as 36.7: log likelihood = -318.98, aic = 643.97
因为参数 ϕ 1 \phi_1 ϕ1的估计值大于它的两倍标准差 ( 0.5432 > 2 × 0.0840 ) (0.5432>2\times0.0840) (0.5432>2×0.0840),所以参数 ϕ 1 \phi_1 ϕ1显著非零.同理,因为 ( 19.8911 > 2 × 1.3179 ) (19.8911>2\times1.3179) (19.8911>2×1.3179),所以参数 μ \mu μ也显著非零.即我们为1900-1998年全球7级以上地震发生次数序列拟合的AR(1)模型两参数都显著非零.
- 参数显著性检验方法二:我们也可以构造参数显著性检验t统计量,调用pt函数求检验P值,相关命令和输出结果如下:
> #构造t统计量,调用pt函数求p值
> t=abs(fit1$coef)/sqrt(diag(fit1$var.coef))
> pt(t,length(number)-length(fit1$coef),lower.tail=F)
> #输出两参数显著性检验P值
ar1 intercept
2.002272e-09 1.687781e-27
因为两参数t统计量的P值都远远小于0.05,所以可以判断我们为1900-1998年全球7级以上地震发生次数序列拟合的AR(1)模型两参数都显著非零.
【例4-2续(2)】对盈亏序列的拟合模型进行检验.
> #模型显著性检验
> ts.diag(fit2)
模型显著性检验结果:
点击查看盈亏序列拟合模型显著性检验图
> #参数显著性检验(近似方法)
> fit2
> #输出结果
Call:
arima(x = overshort, order = c(0, 0, 1), method = "CSS")
Coefficients:
ma1 intercept
-0.8208 -4.4095
s.e. 0.0996 1.1655
sigma^2 estimated as 2105: part log likelihood = -298.96
> #参数显著性检验(精确方法)
> t=abs(fit2$coef)/sqrt(diag(fit2$var.coef))
> pt(t,length(overshort)-length(fit2$coef),lower.tail=F)
> #输出t统计量p值
ma1 intercept
1.775795e-11 1.919653e-04
模型的显著性检验结果显示残差序列可以视为白噪声序列,所以拟合模型显著成立.
参数的显著性检验结果显示,无论使用近似方法还是精确方法,都能得出两参数显著非零的结论.
【例4-3续(2)】对1880-1985年全球气表平均温度改变值差分序列拟合模型进行检验.
> #模型显著性检验
> ts.diag(fit3)
模型显著性检验结果:
点击查看dif序列拟合模型显著性检验图
> #参数显著性检验(近似方法)
> fit3
> #输出结果
Call:
arima(x = dif, order = c(1, 0, 1))
Coefficients:
ar1 ma1 intercept
0.3926 -0.8867 0.0053
s.e. 0.1180 0.0604 0.0024
sigma^2 estimated as 0.01541: log likelihood = 69.66, aic = -131.32
> #参数显著性检验(精确方法)
> t=abs(fit3$coef)/sqrt(diag(fit3$var.coef))
> pt(t,length(dif)-length(fit3$coef),lower.tail=F)
> #输出t统计量p值
ar1 ma1 intercept
6.112701e-04 3.323907e-27 1.555753e-02
模型的显著性检验结果显示残差序列可以视为白噪声序列,所以拟合模型显著成立.
参数的显著性检验结果显示,无论使用近似方法还是精确方法,都能得出三参数显著非零的结论.
1.6模型优化
【例4-7】等时间间隔连续读取70个某次化学反应的过程数据,构成一时间序列(数据见表A1_10),试对该序列进行拟合 ( α = 0.05 ) (\alpha=0.05) (α=0.05).
> library(readxl)
> A1_10 <- read_excel("C:/Users/86158/Desktop/A1_10.xlsx")
> View(A1_10)
> #绘制时序图
> x<-ts(A1_10$x)
> plot(x)
点击查看化学反应过程时序图
> #平稳性检验
> library(aTSA)
> adf.test(x)
Augmented Dickey-Fuller Test
alternative: stationary
Type 1: no drift no trend
lag ADF p.value
[1,] 0 -1.657 0.093
[2,] 1 -0.872 0.365
[3,] 2 -0.452 0.512
[4,] 3 -0.525 0.489
Type 2: with drift no trend
lag ADF p.value
[1,] 0 -12.25 0.01
[2,] 1 -5.38 0.01
[3,] 2 -4.36 0.01
[4,] 3 -3.91 0.01
Type 3: with drift and trend
lag ADF p.value
[1,] 0 -12.61 0.01
[2,] 1 -5.61 0.01
[3,] 2 -4.83 0.01
[4,] 3 -4.41 0.01
----
Note: in fact, p.value = 0.01 means p.value <= 0.01
> #纯随机性检验
> for(k in 1:2)print(Box.test(x,lag=6*k,type="Ljung-Box"))
Box-Ljung test
data: x
X-squared = 21.319, df = 6, p-value = 0.001608
Box-Ljung test
data: x
X-squared = 23.035, df = 12, p-value = 0.02743
平稳性检验和纯随机性检验显示该序列为平稳非白噪声序列,可以使用ARMA模型拟合该序列,下面考察该序列的自相关图和偏自相关图的特征,给ARMA模型定阶.
> #绘制自相关图和偏自相关图
> par(mfrow=c(1,2))
> acf(x)
> pacf(x)
根据自相关图的特征,可能有人会认为自相关系数2阶截尾,那么可以对序列拟合MA(2)模型.
根据偏自相关图的特征,可能有人认为偏自相关系数1阶截尾,那么可以对序列拟合AR(1)模型.
下面分别拟合MA(2)模型和AR(1)模型.
> #拟合MA(2)模型
> x.fit1<-arima(x,order=c(0,0,2))
> x.fit1
Call:
arima(x = x, order = c(0, 0, 2))
Coefficients:
ma1 ma2 intercept
-0.3194 0.3019 51.1695
s.e. 0.1160 0.1233 1.2516
sigma^2 estimated as 114.4: log likelihood = -265.35, aic = 538.71
> #拟合AR(1)模型
> x.fit2<-arima(x,order=c(1,0,0))
> x.fit2
Call:
arima(x = x, order = c(1, 0, 0))
Coefficients:
ar1 intercept
-0.4191 51.2658
s.e. 0.1129 0.9137
sigma^2 estimated as 116.6: log likelihood = -265.98, aic = 537.96
MA(2)模型的口径为:
x
t
=
51.1695
+
ε
t
−
0.3194
ε
t
−
1
+
0.3019
ε
t
−
2
,
V
a
r
(
ε
t
)
=
114.4
x_t=51.1695+\varepsilon_t-0.3194\varepsilon_{t-1}+0.3019\varepsilon_{t-2},Var(\varepsilon_t)=114.4
xt=51.1695+εt−0.3194εt−1+0.3019εt−2,Var(εt)=114.4
AR(1)模型的口径为:
x
t
−
51.2658
=
ε
t
1
+
0.4191
B
,
V
a
r
(
ε
t
)
=
116.6
x_t-51.2658=\frac{\varepsilon_t}{1+0.4191B},Var(\varepsilon_t)=116.6
xt−51.2658=1+0.4191Bεt,Var(εt)=116.6
对上述两个拟合模型分别进行模型显著性检验.
> #MA(2)模型显著性检验
> ts.diag(x.fit1)
点击查看MA(2)模型显著性检验图
> #AR(1)模型显著性检验
> ts.diag(x.fit2)
点击查看AR(1)模型显著性检验图
模型显著性检验结果显示,这两个拟合模型的残差序列都可以视为白噪声序列,所以这两个拟合模型均显著成立.
由于这个化学反应序列的序列长度为70,我们可以基于近似方法判断参数显著性,根据模型拟合输出结果,可以发现无论是MA(2)模型还是AR(1)模型,每个参数估计值的绝对值都大于该参数的2倍标准差,所以这两个模型的每个参数均显著非零.
上述分析说明MA(2)模型和AR(1)模型都是这个化学反应序列的有效拟合模型.
同一个序列可以构造两个甚至更多个拟合模型,多个模型都显著有效,那么到底该选哪个模型用于统计推断呢?为了解决这个问题,引进AIC和BIC信息准则的概念,进行模型优化.
【例4-7续(1)】用AIC准则和BIC准则评判例4-7中两个拟合模型的相对优劣.
> #将两个模型的AIC和BIC信息量合成一个数据框输出
> data.frame(AIC(x.fit1),AIC(x.fit2),BIC(x.fit2))
> #输出结果
AIC.x.fit1. AIC.x.fit2. BIC.x.fit2.
1 538.7055 537.9579 544.7033
最小信息量检验显示,无论是使用AIC准则还是使用BIC准则,AR(1)模型都要优于MA(2)模型,所以本例中AR(1)模型是相对最优模型.
AIC准则和BIC准则的提出可以有效弥补根据自相关图和偏自相关图定阶的主观性,在有限的阶数范围内帮助我们寻找相对最优拟合模型.
仔细考虑一下,模型定阶和模型优化其实是在做同一件事情——为序列选出最优拟合模型,R语言的forecast包提供了auto.arima函数,该函数基于信息量最小原则,可以帮助用户在一定的范围内自动识别最优模型的阶数,在模型定阶时,调用这个函数,可以尽量避免因个人经验不足导致的模型识别不准确的问题,也可以简化模型最优化比较的问题.
auto.arima函数的命令格式如下:
auto.arima(x,max.p=,max.q= ic=)
式中
- x:需要定阶的序列名
- max.p:自相关系数最高阶数,不特殊指定的话,系统默认值为5
- max.q:移动平均系数最高阶数,不特殊指定的话,系统默认值为5
- ic:指定信息量准则,有"aic",“bic”,"aicc"三个选项,系统默认AIC准则
有时选择不同的信息量准则会导致模型的识别阶数不同,另外auto.arima函数没有考虑系数不显著需要剔除的问题,有时它指定的最优模型阶数会高于真实阶数,因此,auto.arima函数是给用户作为定阶的参考信息,而不是最优模型的准确信息,用户需要自己结合自相关图、偏自相关图、参数显著性检验等多方面的信息综合分析,合理定阶.
【例4-7续(2)】使用auto.arima函数对化学反应序列进行定阶.
> #下载forecast包
> install.packages("forecast")
> #调用forecast包
> library("forecast")
> #调用auto.arima函数
> auto.arima(x)
> #输出结果
Series: x
ARIMA(2,0,0) with non-zero mean
Coefficients:
ar1 ar2 mean
-0.3407 0.1873 51.2263
s.e. 0.1218 0.1223 1.1007
sigma^2 = 117.8: log likelihood = -264.83
AIC=537.66 AICc=538.27 BIC=546.65
输出结果显示,基于AIC准则,系统推荐的最优模型为AR(2)模型,但是考虑到该序列偏自相关图1阶截尾,再看上面输出结果中显示的ar2的参数估计值为0.1873,它的样本标准差为0.1223,参数估计值小于2倍的样本标准差,所以ar2的参数不能认为显著非零,综上考虑,基于AIC准则,系统推荐的最优模型阶数偏高了,我们应该给该序列拟合AR(1)模型.
如果修改命令,指定使用BIC准则,则系统推荐的最优模型为AR(1)模型,相关命令和输出结果如下:
> #基于BIC准则,选择最优拟合模型
> auto.arima(x,ic="bic")
> #输出结果
Series: x
ARIMA(1,0,0) with non-zero mean
Coefficients:
ar1 mean
-0.4191 51.2658
s.e. 0.1129 0.9137
sigma^2 = 120: log likelihood = -265.98
AIC=537.96 AICc=538.32 BIC=544.7
1.7序列预测
R语言中有多个函数可以进行ARMA模型预测,我们介绍最常用的一个函数,forecast包中的forecast函数的命令格式如下:
forecast(object,h=,level=)
式中:
- object:拟合模型对象名.
- h:预测期数.
- level:置信区间的置信水平,不特殊指定的话,系统会自动给出置信水平分别为80%和95%的双层置信区间.
- 若aTSA包同时打开,需要使用forecast::forecast格式调用forecast包中的forecast函数.
【例4-1续(4)】根据1900-1998年全球7级以上地震发生次数的观察值,预测1999-2008年全球7级以上地震发生次数.
> #调用forecast函数,做10期预测
> library("forecast")
> fore1<-forecast::forecast(fit1,h=10)
> fore1
> #输出预测结果
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
1999 17.77725 10.013811 25.54069 5.904094 29.65041
2000 18.74274 9.907694 27.57778 5.230705 32.25477
2001 19.26723 10.139955 28.39451 5.308265 33.22620
2002 19.55217 10.340414 28.76392 5.464007 33.64032
2003 19.70695 10.470420 28.94349 5.580895 33.83301
2004 19.79104 10.547207 29.03487 5.653817 33.92826
2005 19.83672 10.590734 29.08271 5.696204 33.97724
2006 19.86154 10.614915 29.10816 5.720048 34.00303
2007 19.87502 10.628208 29.12183 5.733243 34.01679
2008 19.88234 10.635476 29.12921 5.740482 34.02420
> #输出预测图
> plot(fore1,lty=2)
> lines(fore1$fitted,col=4)
图中,虚线为观察值,实线为拟合值,深色阴影部分为置信水平为80%的预测值置信区间,浅色阴影部分为置信水平为95%的预测值置信区间.
如有需要,评论私发数据.















 3104
3104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}