






 本文概述了大模型发展的重要节点,特别是Transformer模型如何革新自然语言处理,解决RNN的限制。Transformer通过自注意力机制和位置编码改进了处理序列数据的能力,推动了LLM模型如BERT、T5和GPT系列的发展。报告还强调了大模型参数规模的扩大和多模态化的趋势。
本文概述了大模型发展的重要节点,特别是Transformer模型如何革新自然语言处理,解决RNN的限制。Transformer通过自注意力机制和位置编码改进了处理序列数据的能力,推动了LLM模型如BERT、T5和GPT系列的发展。报告还强调了大模型参数规模的扩大和多模态化的趋势。
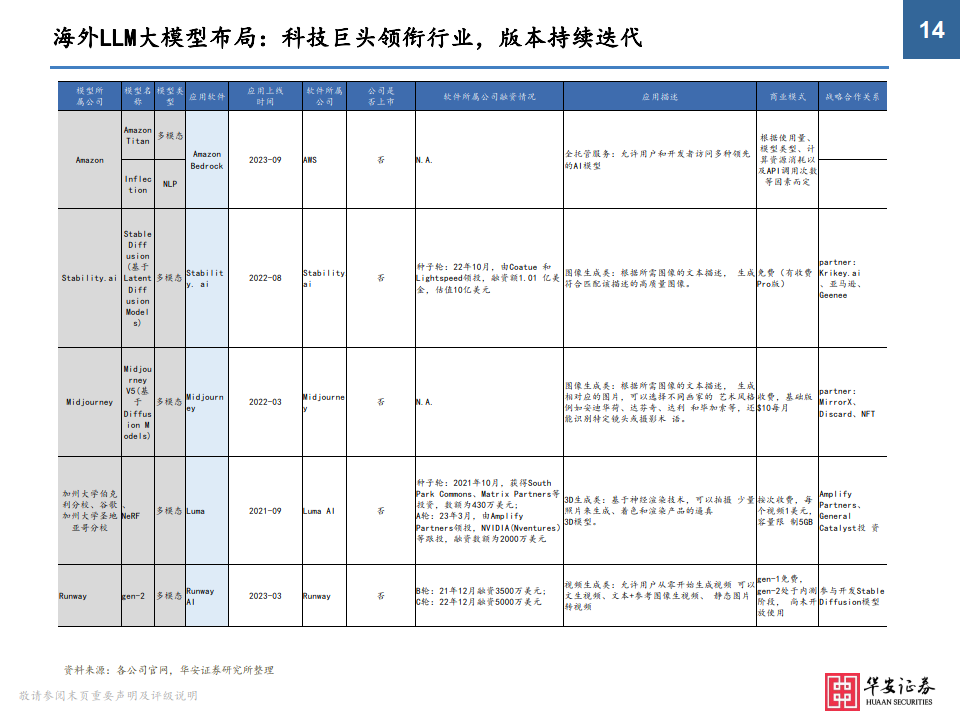
今天分享的是AIGC系列深度研究报告:《AIGC报告:大模型改变开发及交互环境,处于高速迭代创新周期》。
(报告出品方:华安证券)
报告共计:64页
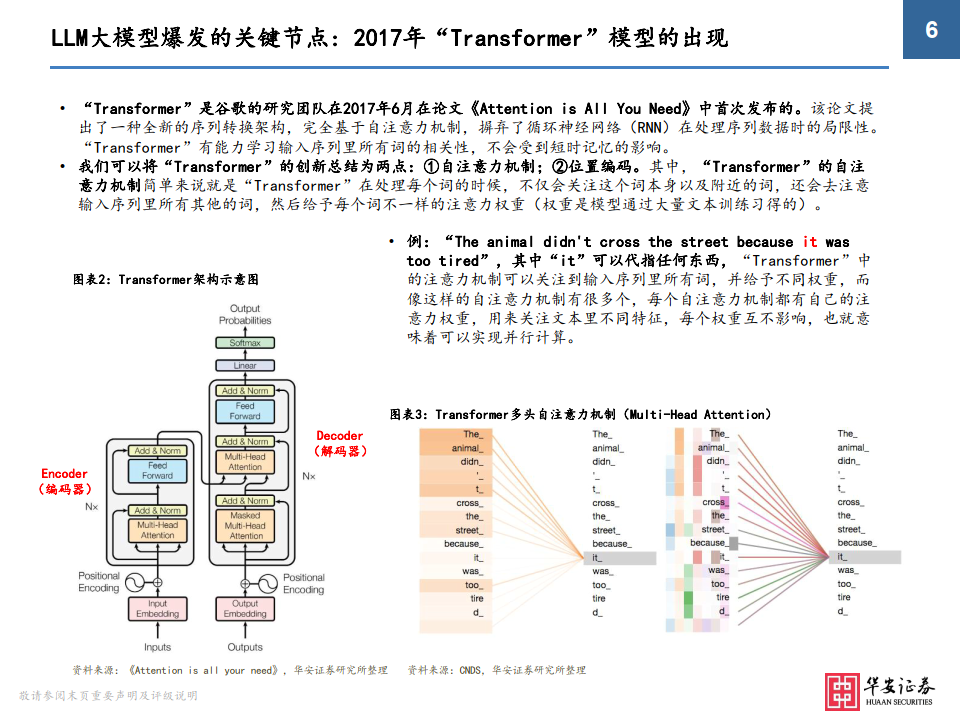
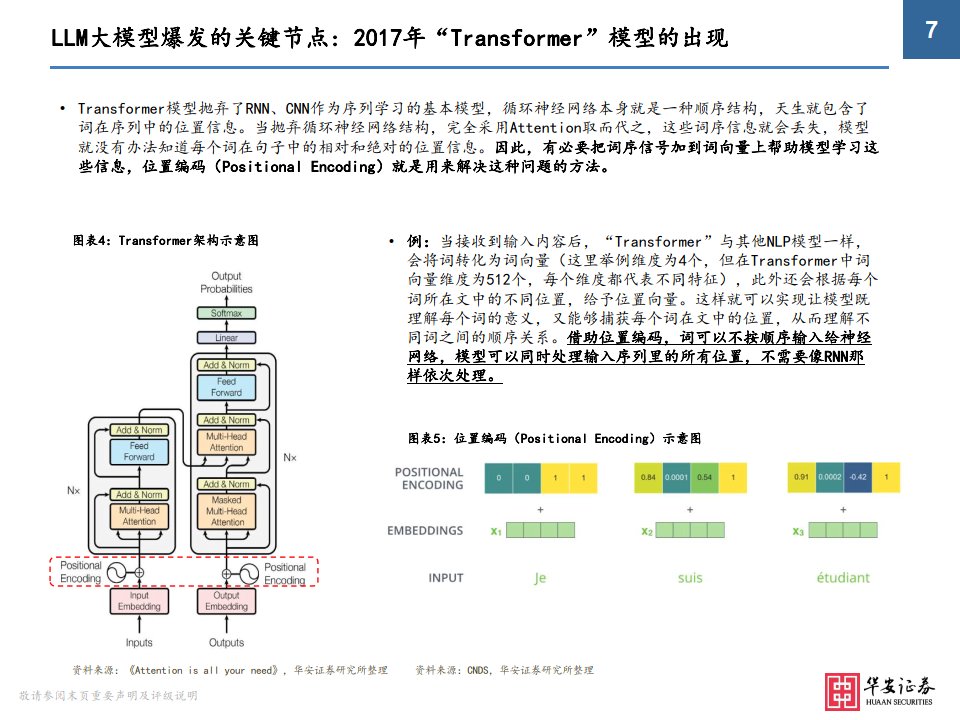
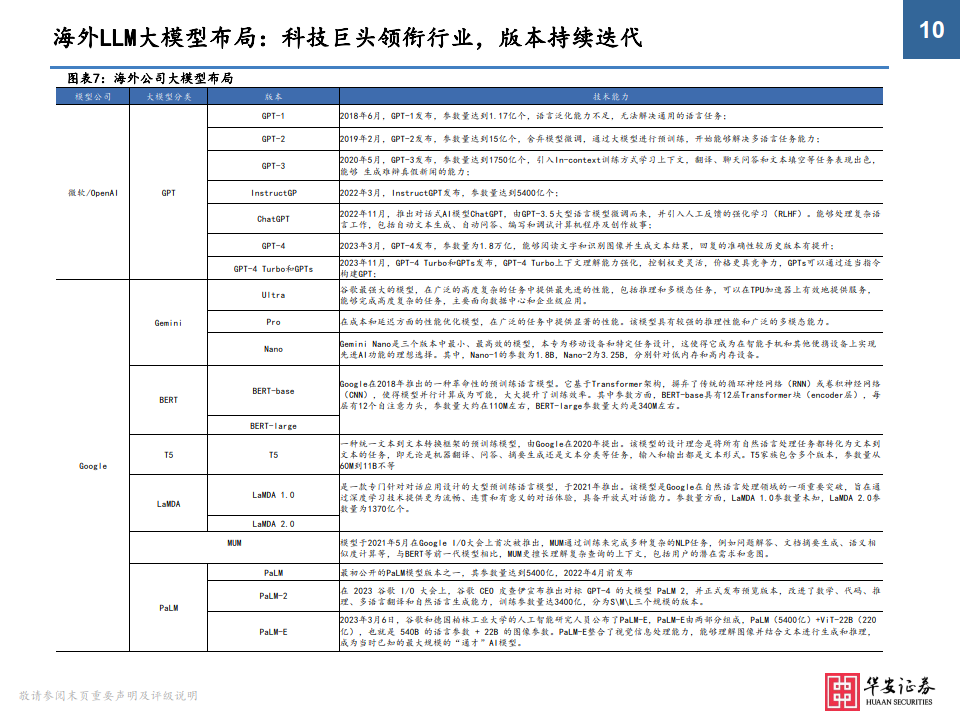
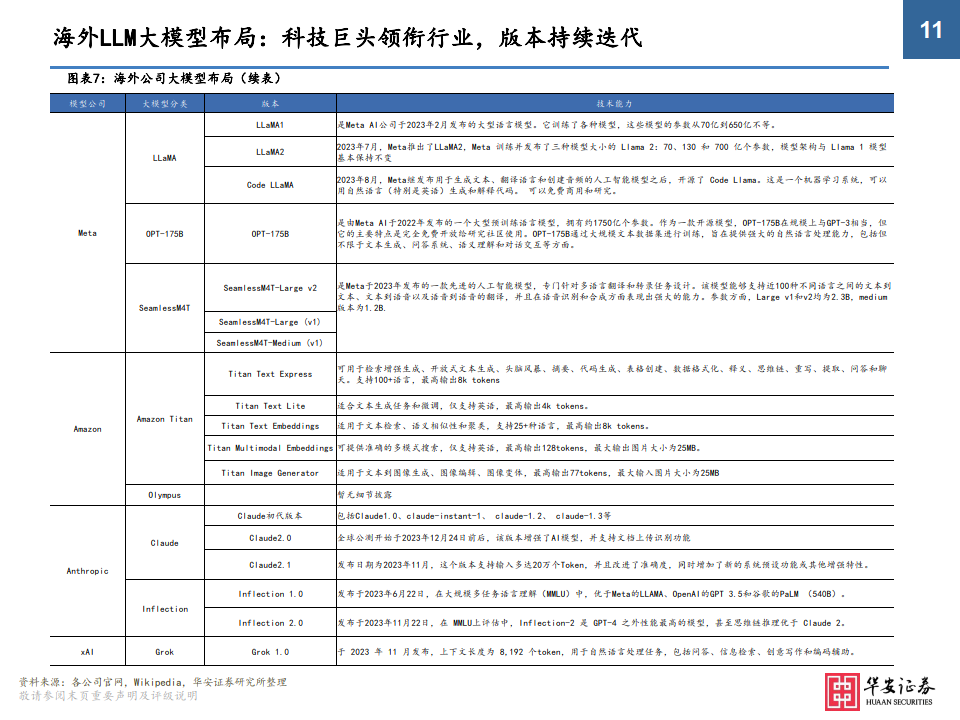
LLM大模型爆发的关键节点: 2017年“Transformer”模型的出现
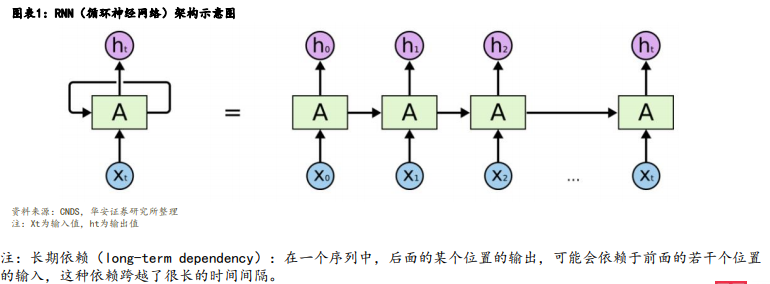
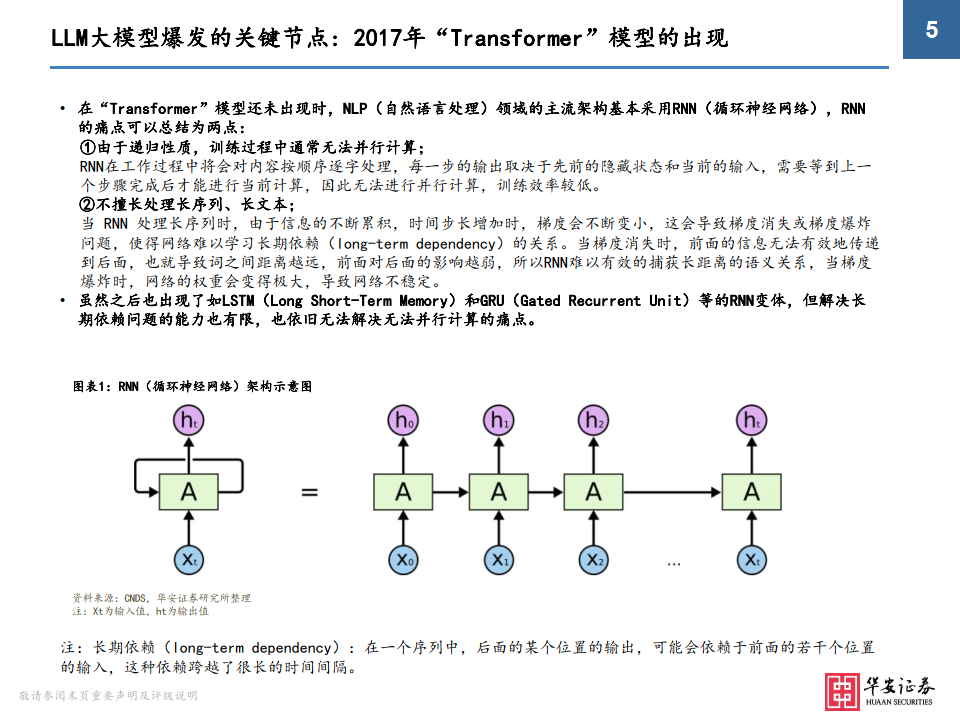
• 在“Transformer”模型还未出现时,NLP(自然语言处理)领域的主流架构基本采用RNN(循环神经网络),RNN 的痛点可以总结为两点: ①由于递归性质,训练过程中通常无法并行计算; RNN在工作过程中将会对内容按顺序逐字处理,每一步的输出取决于先前的隐藏状态和当前的输入,需要等到上一 个步骤完成后才能进行当前计算,因此无法进行并行计算,训练效率较低。 ②不擅长处理长序列、长文本; 当 RNN 处理长序列时,由于信息的不断累积,时间步长增加时,梯度会不断变小,这会导致梯度消失或梯度爆炸 问题,使得网络难以学习长期依赖(long-term dependency)的关系。当梯度消失时,前面的信息无法有效地传递 到后面,也就导致词之间距离越远,前面对后面的影响越弱,所以RNN难以有效的捕获长距离的语义关系,当梯度 爆炸时,网络的权重会变得极大,导致网络不稳定。
• 虽然之后也出现了如LSTM(Long Short-Term Memory)和GRU(Gated Recurrent Unit)等的RNN变体,但解决长 期依赖问题的能力也有限,也依旧无法解决无法并行计算的痛点。
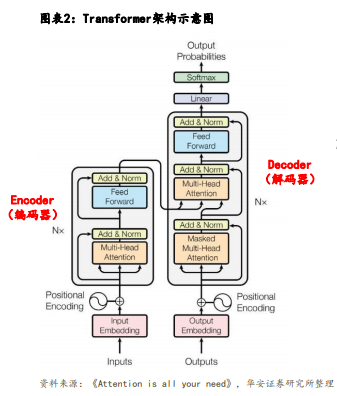
• “Transformer”是谷歌的研究团队在2017年6月在论文《Attention is All You Need》中首次发布的。该论文提 出了一种全新的序列转换架构,完全基于自注意力机制,摒弃了循环神经网络(RNN)在处理序列数据时的局限性。 “Transformer”有能力学习输入序列里所有词的相关性,不会受到短时记忆的影响。
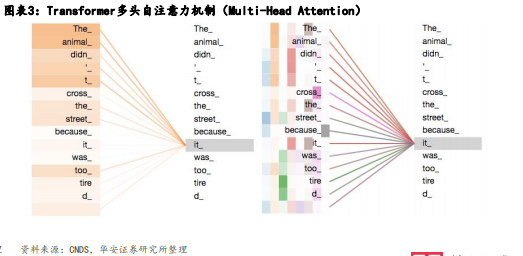
• 我们可以将“Transformer”的创新总结为两点:①自注意力机制;②位置编码。其中,“Transformer”的自注 意力机制简单来说就是“Transformer”在处理每个词的时候,不仅会关注这个词本身以及附近的词,还会去注意 输入序列里所有其他的词,然后给予每个词不一样的注意力权重(权重是模型通过大量文本训练习得的)。
• 例:“The animal didn't cross the street because it was too tired”,其中“it”可以代指任何东西,“Transformer”中 的注意力机制可以关注到输入序列里所有词,并给予不同权重,而像这样的自注意力机制有很多个,每个自注意力机制都有自己的注 意力权重,用来关注文本里不同特征,每个权重互不影响,也就意味着可以实现并行计算。
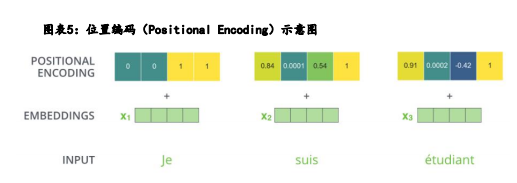
• Transformer模型抛弃了RNN、CNN作为序列学习的基本模型,循环神经网络本身就是一种顺序结构,天生就包含了 词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这 些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
• 例:当接收到输入内容后,“Transformer”与其他NLP模型一样, 会将词转化为词向量(这里举例维度为4个,但在Transformer中词 向量维度为512个,每个维度都代表不同特征),此外还会根据每个 词所在文中的不同位置,给予位置向量。这样就可以实现让模型既 理解每个词的意义,又能够捕获每个词在文中的位置,从而理解不 同词之间的顺序关系。借助位置编码,词可以不按顺序输入给神经 网络,模型可以同时处理输入序列里的所有位置,不需要像RNN那 样依次处理。
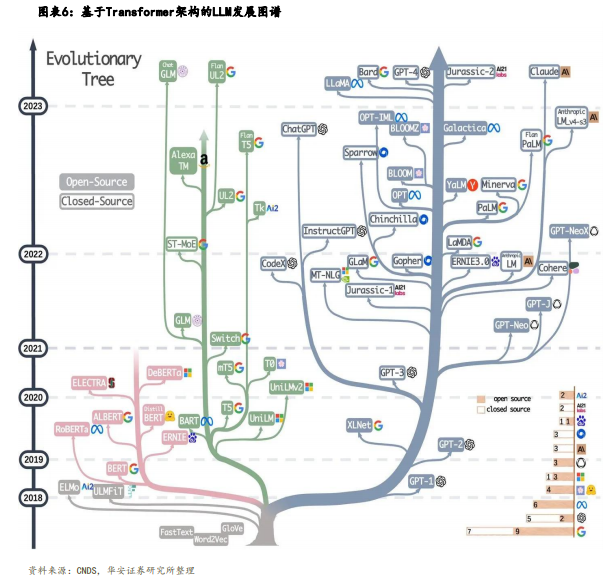
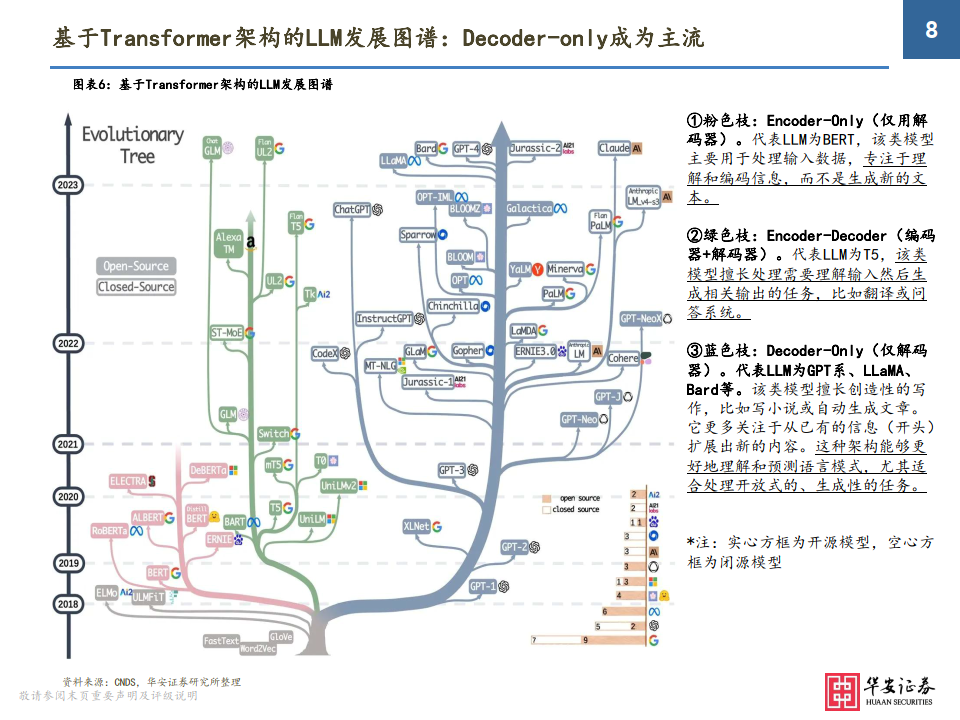
基于Transformer架构的LLM发展图谱:Decoder-only成为主流
①粉色枝:Encoder-Only(仅用解 码器)。代表LLM为BERT,该类模型 主要用于处理输入数据,专注于理 解和编码信息,而不是生成新的文本。
②绿色枝:Encoder-Decoder(编码器+解码器)。代表LLM为T5,该类 模型擅长处理需要理解输入然后生 成相关输出的任务,比如翻译或问答系统。
③蓝色枝:Decoder-Only(仅解码 器)。代表LLM为GPT系、LLaMA、 Bard等。该类模型擅长创造性的写作,比如写小说或自动生成文章。 它更多关注于从已有的信息(开头) 扩展出新的内容。这种架构能够更好地理解和预测语言模式,尤其适 合处理开放式的、生成性的任务。
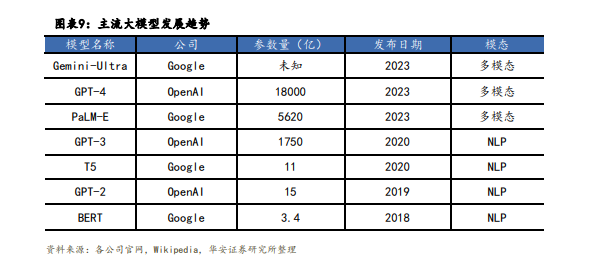
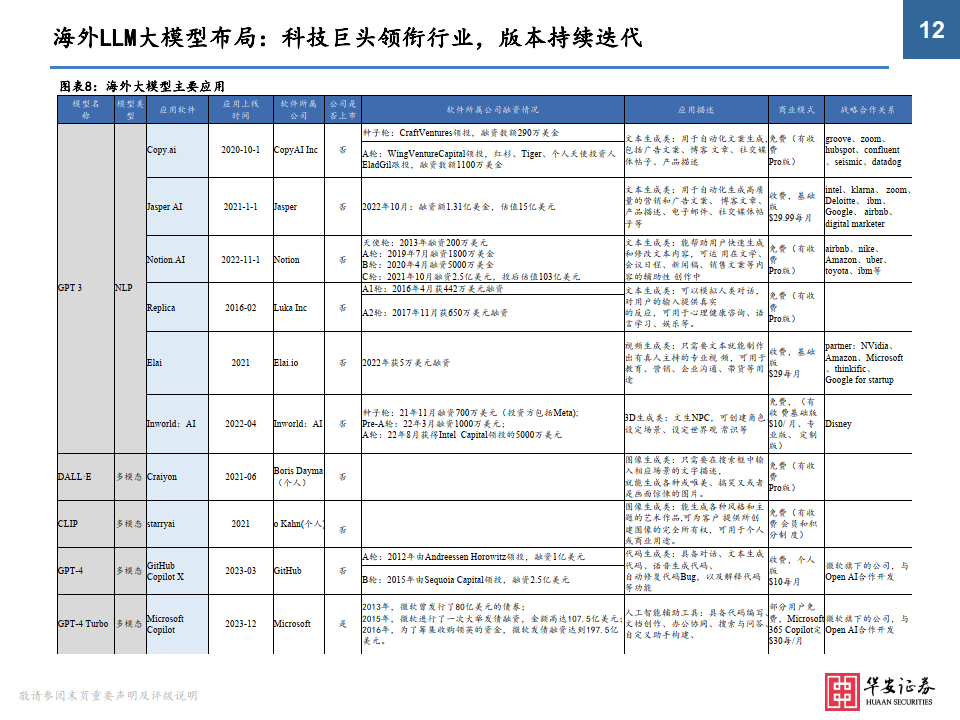
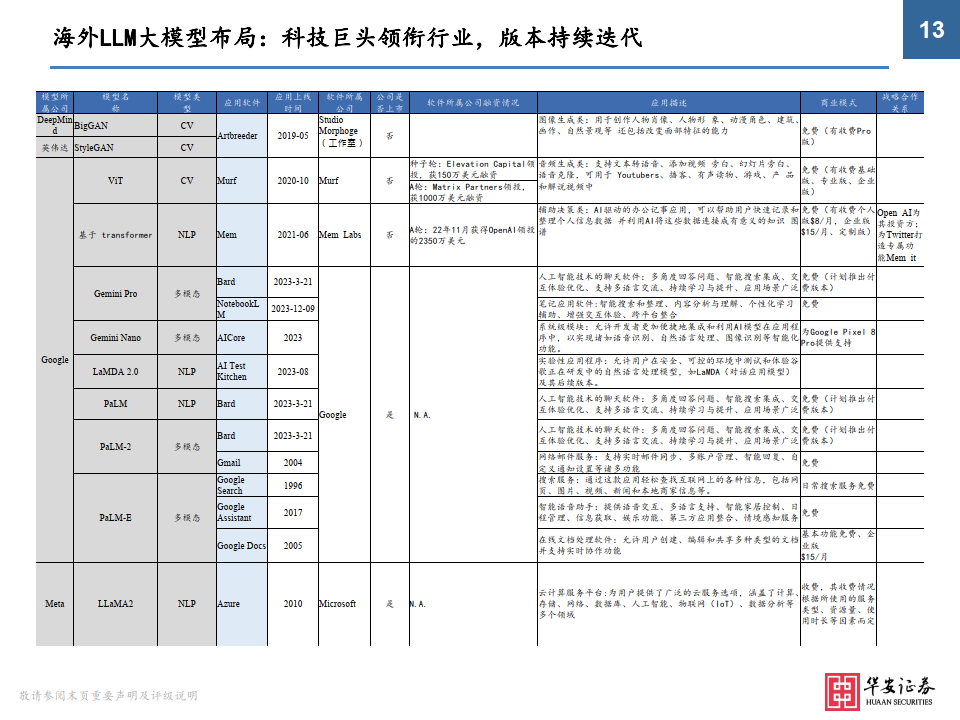
大模型发展趋势:参数规模扩大+向多模态演进
• 通过回溯主流模型迭代情况,我们可以将LLM大模型的发展趋势总结为两点:①模型参数量呈现增长趋势;②由单模态向多模态演变。其中,参数量规模的增长在很大程度上推动了大模型的学习能力(但不绝对,也取决于模型的算法和参数质量,过多的参数也会导致过拟合情况发生),而大模型由单模态向多模态的演变,也意味着模型能够 处理和理解来自不同数据模态的信息,这些模态可以包括但不限于图像、文本、音频、视频等,实现复杂生成任务。

报告共计:64页
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









