






文章已获作者授权转载,版权归原作者所有,如有侵权,与本账号无关,可联系删除。 原文作者:creative_mind
引入
当前我们已经学过一些排序方法,如冒泡排序,选择排序,还有链表(单双),qsort()等一系列进行排序的方法。那么,你真的了解排序的各种方法吗?今天,我将介绍一种新的巧解–堆排序,从时间复杂度和空间复杂度上看,堆排序并不比以上我们所说的那些方法复杂,甚至有时它更为常见!
也许你会感觉很陌生,不知道如何下手?其实我想说的是:堆排序也并非很难****。****
1 解读理解加复习
首先,堆排序的物理结构是数组,逻辑结构为二叉树。
对于物理结构,相信数组大家都不陌生,我们再学习栈的时候,就是通过数组来实现的,我们创建的结构体,数组指针,以及入栈(扩容),出栈(空间是否为1的分情况讨论)等操作其实在堆排序中也能遇到!
**那对于逻辑结构,**我们将要讲一下关于树以及二叉树的概念!
1.1 复习
1.是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合,树是递归定义的。
2.树的相关概念,如下:
节点的度:一个节点含有的子树的个数称为该节点的度;
叶节点或终端节点:度为0的节点称为叶节点;
非终端节点或分支节点:度不为0的节点;
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
树的度:一棵树中,最大的节点的度称为树的度;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次;
堂兄弟节点:双亲在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>0)棵互不相交的树的集合称为森林;
1.2 二叉树的概念
二叉树(binary tree)是指树中节点的度不大于2的有序树,它是一种最简单且最重要的树。二叉树的递归定义为:二叉树是一棵空树,或者是一棵由一个根节点和两棵互不相交的,分别称作根的左子树和右子树组成的非空树;左子树和右子树又同样都是二叉树。
1.3 二叉树分为满二叉树,完全二叉树
满二叉树:如果一棵二叉树只有度为0的节点和度为2的节点,并且度为0的节点在同一层上,则这棵二叉树为满二叉树。
完全二叉树:深度为k,有n个节点的二叉树当且仅当其每一个节点都与深度为k的满二叉树中编号从1到n的节点一一对应时,称为完全二叉树
1.4 二叉树的性质
- 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1) 个结点.
- 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 2^(k)-1.
- 对任何一棵二叉树, 如果度为0其叶结点个数为 , 度为2的分支结点个数为 ,则有 n0=n2+1.
- 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有:log2(n+1)
- 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
- 若2i+1<n,左孩子序号:2i+1,2i+1>=n否则无左孩子
- 若2i+2<n,右孩子序号:2i+2,2i+2>=n否则无右孩子
2 新解
堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值
- 堆总是一棵完全二叉树。
将根结点最大的堆叫做最大堆最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。画图如下:
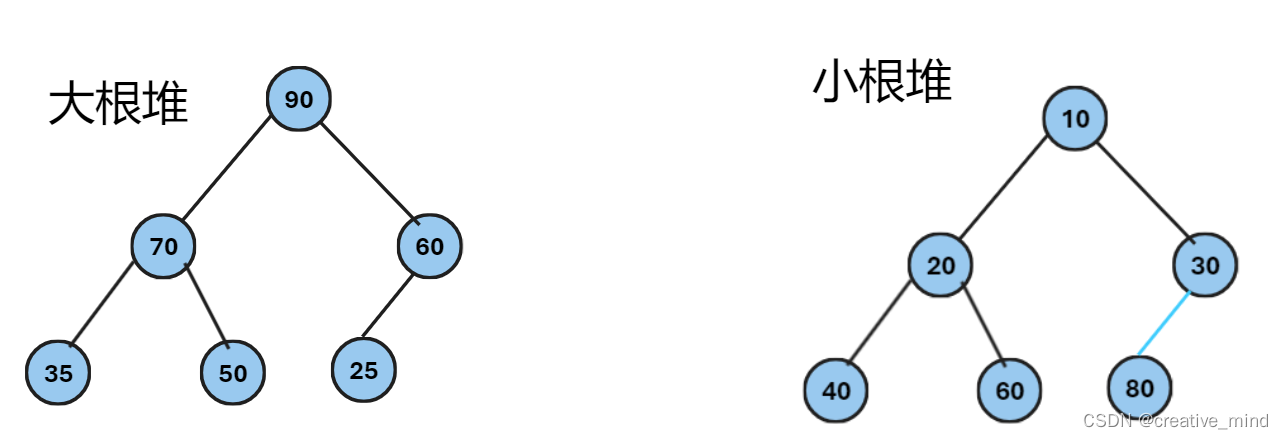
我们以小根堆为例子!
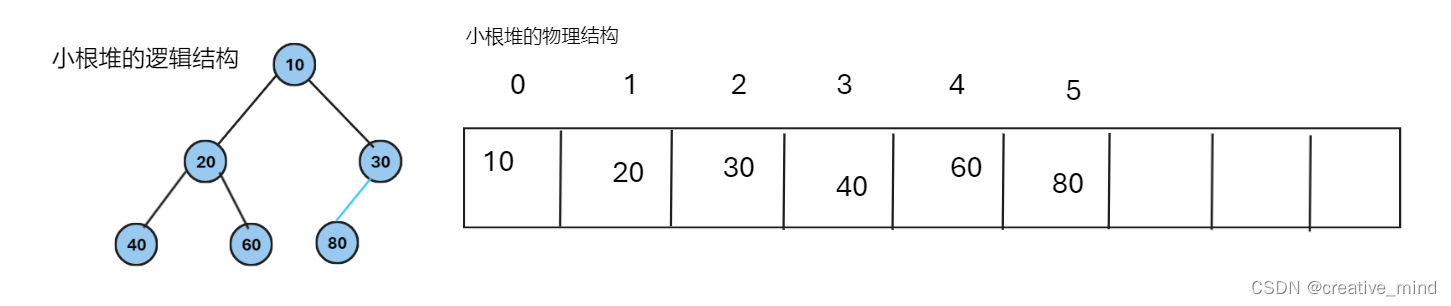
我们分析一下:首先我们定义parent和chlid节点!
我们不难得知:10为20和30的父亲节点,20为49与60的父亲节点 ,80为30的leftchlid节点!
总结一下:我们不难得知(以父亲与孩子的数组下标)推出以下关系:
leftchlid=parent*2+1;
rightchlid=parent*2+2;
parent=(chlid-1)/2;注意:“/”得出的结果为int 型!
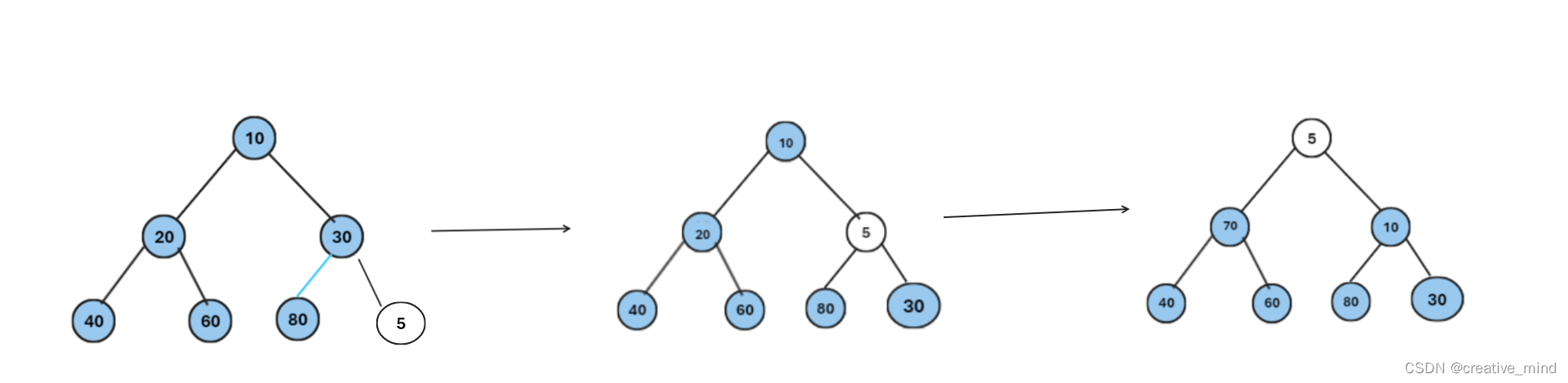
那我们该如何插入一个数据呢?我们画图解决!(以我们push(5)为例)
以下是堆排序演变过程!
以下是我挑选的一道题,有助于大家理解!(大家把答案打在评价区)
最小堆[0,3,2,5,7,4,6,8],在删除堆顶元素0之后,其结果是()
A[3,2,5,7,4,6,8]
B[2,3,5,7,4,6,8]
C[2,3,4,5,7,8,6]
D[2,3,4,5,6,7,8]
3 代码实现
我们主要实现一下一些基础接口!
`**typedef int HPDataType;
typedef struct Heap
{
HPDataType\* _a;//数组指针
int _size;
int _capacity;
}Heap;**`
**// 堆的初始化
void Heapinit(Heap\* hp);
// 堆的销毁
void HeapDestory(Heap\* hp);
// 堆的插入
void HeapPush(Heap\* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap\* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap\* hp);
// 堆的数据个数
int HeapSize(Heap\* hp);
// 堆的判空
int HeapEmpty(Heap\* hp);**
铁汁们,不要着急,我们一步一步来!
首先,我们从最简单的开始,不难的!
**// 堆的初始化
void Heapinit(Heap\* hp)
{
assert(hp);
hp->_a = NULL;
hp->_capacity = hp->_size = 0;
}
// 堆的销毁
void HeapDestory(Heap\* hp)
{
assert(hp);
free(hp->_a);
hp->_a = NULL;
hp->_capacity = hp->_size = 0;
}**
考虑到我们频繁进行交换操作,所以我们先定义一个函数!
void Swap(HPDataType* px, HPDataType* py)//注意要传实参!
{
HPDataType tmp = *px;
*px = *py;
*py = tmp;
}
好 ,接下来我们来写push;*重点为定义为向上调整法*
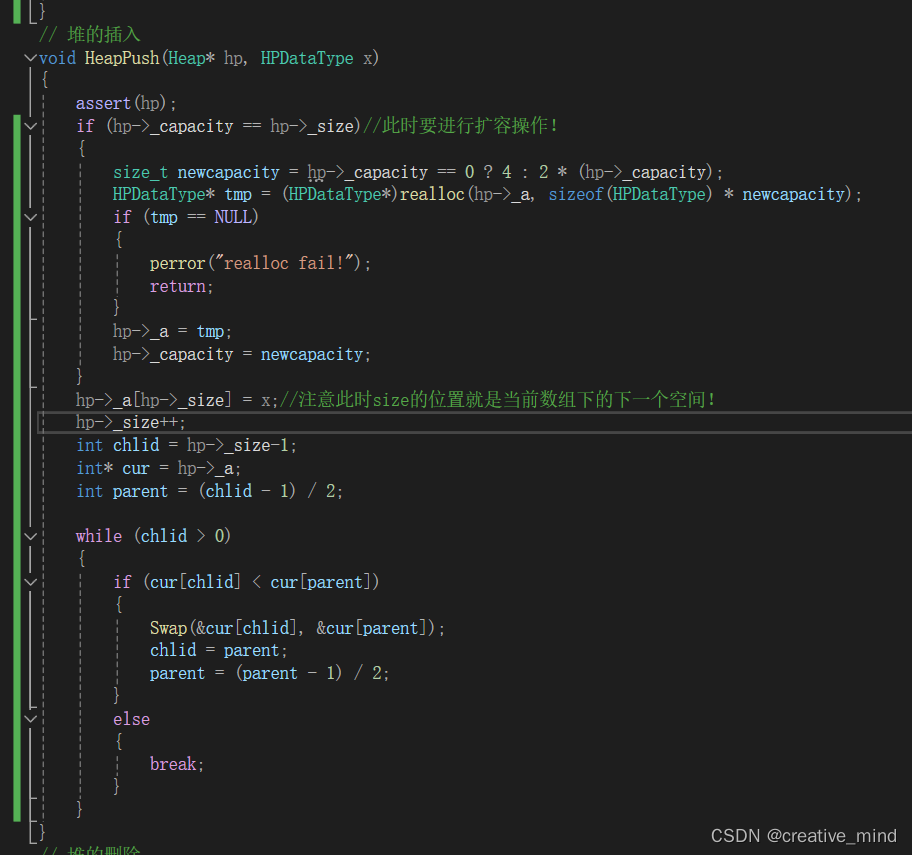
我们接着往下:void HeapPop(Heap* hp);重点是向下调整!
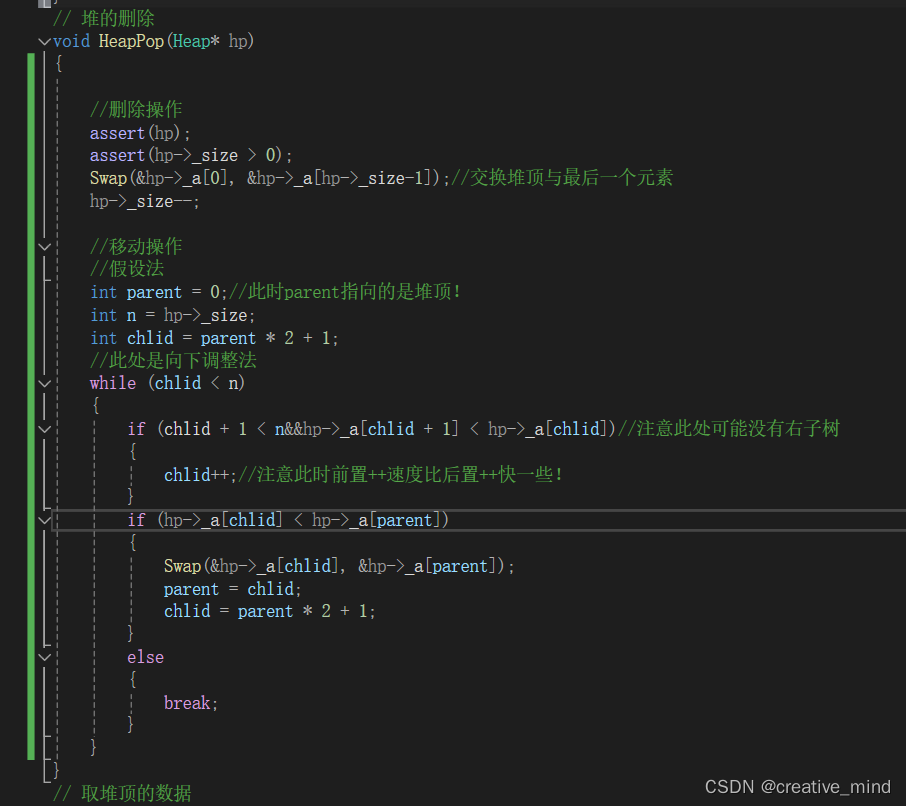
*这个要注意的是:(看注释,铁子们!)*
然后向下继续写!
**// 取堆顶的数据
HPDataType HeapTop(Heap\* hp)
{
assert(hp);
assert(hp->_size > 0);
return hp->_a[0];
}
// 堆的数据个数
int HeapSize(Heap\* hp)
{
assert(hp);
assert(hp->_size > 0);
return hp->_size;
}
// 堆的判空
bool HeapEmpty(Heap\* hp)
{
assert(hp);
return hp->_size == 0;
}**
我们要调试一下!

拿下,拿下,拿下,你看铁子们,不难的!
关注我,懂得更多!
原文链接:https://blog.csdn.net/creative_mind/article/details/136534278

















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









