






1实时数仓同步数据
实时数仓由Flink不断从Kafka中读数据计算,无需手动同步
2离线数仓同步数据
2.1用户行为数据同步
2.1.1数据通道
用户行为数据由Flume从Kafka直接同步到HDFS,由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期,具体数据流如图:

2.1.2日志消费Flume配置概述
按照之前规划,该Flume需要将Kafka中topic_log的数据发往HDFS,并且对每天产生的用户行为日志进行区分,将不同天的数据发往HDFS不同天的路径。
所以此处选择KafkaSource,FileChannel,HDFSSink
这些组件是 Apache Flume 中的核心组件,用于构建数据流管道以实现数据的采集、传输和存储。以下是它们的简要介绍:
-
KafkaSource:
KafkaSource 是 Flume 的源(Source)组件之一,用于从 Apache Kafka 中消费消息数据。它可以连接到 Kafka 集群,并订阅一个或多个 Kafka Topic,然后将从这些 Topic 中接收到的消息传递给 Flume 的其他组件,如 Channel 或 Sink,以进一步处理或传输。
-
FileChannel:
FileChannel 是 Flume 提供的一种通道(Channel)实现,用于在 Flume 的数据流管道中缓存数据。FileChannel 使用本地文件系统来存储数据,并且具有持久性和可靠性。它可以在数据生产者和消费者之间提供缓冲,以平衡数据传输的速度差异,从而提高系统的稳定性和性能。
-
HDFSSink:
HDFSSink 是 Flume 的目的地(Sink)组件之一,用于将数据写入到 Hadoop 分布式文件系统(HDFS)中进行持久化存储。它可以将 Flume 中的数据写入到 HDFS 中的指定目录或文件中,并具有高吞吐量和可靠性。HDFSSink 通常用于将 Flume 中采集到的数据持久化到 Hadoop 生态系统中,以供后续的数据处理和分析。
综合来看,这三个组件共同构成了一个完整的数据流管道,其中 KafkaSource 负责从 Kafka 中消费消息,FileChannel 提供数据的缓存和流量控制,而 HDFSSink 则将数据写入到 HDFS 中进行持久化存储,从而实现了数据的采集、传输和存储。
要使用 KafkaSource、FileChannel 和 HDFSSink 这些组件实现数据流传输,可以按照以下步骤进行设置和配置:
-
配置 KafkaSource: 首先,您需要配置 KafkaSource 来从 Kafka Topic 中消费消息。在配置文件中,指定 Kafka 的连接信息、要消费的 Topic 名称以及其他必要的参数。确保 KafkaSource 的配置正确,并且可以连接到 Kafka 集群并从指定的 Topic 中消费消息。
-
配置 FileChannel: 接下来,配置 FileChannel 作为 KafkaSource 和 HDFSSink 之间的通道。在 Flume 的配置文件中,指定 FileChannel 的类型为 file,并为其指定一个存储文件的路径。FileChannel 将 KafkaSource 获取的消息缓存到本地文件中,以便稍后传输给 HDFSSink。
-
配置 HDFSSink: 最后,配置 HDFSSink 将 FileChannel 中的数据写入到 HDFS 中。在配置文件中,指定 HDFSSink 的类型为 hdfs,并配置 HDFS 的连接信息、目标文件路径等参数。确保 HDFSSink 的配置正确,并且可以连接到 HDFS,并将数据写入到指定的目标文件中。
-
启动 Flume Agent: 在配置文件中定义完 KafkaSource、FileChannel 和 HDFSSink 后,通过命令行启动 Flume Agent。确保 Flume Agent 正常启动,并且可以连接到 Kafka、HDFS,并将数据从 Kafka Topic 中消费并写入到 HDFS 中。
-
监控和调试: 最后,确保监控 Flume Agent 的运行状态,并对可能出现的错误进行调试和排查。您可以使用 Flume 的日志文件来查看 Flume Agent 的输出和运行日志,以及使用相关监控工具来监控 Flume Agent 的运行状况。
通过按照以上步骤设置和配置 KafkaSource、FileChannel 和 HDFSSink,您可以实现从 Kafka Topic 中消费消息,并将消息数据传输到 HDFS 中进行持久化存储。
关键配置:
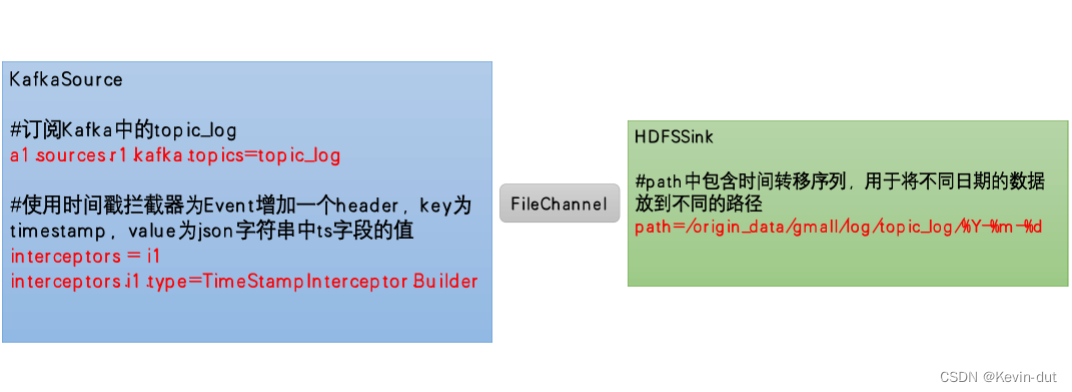
2.1.3日志消费Flume配置实操
1)创建Flume配置文件
在hadoop104节点的Flume家目录下创建job目录,在job下创建kafka_to_hdfs_log.conf
配置文件内容如下:
#定义组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder
#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c13)FileChannel优化
通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。
官方说明如下:
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据
4)HDFS Sink优化
(1)问题分析:HDFS存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。
(2)HDFS小文件处理
官方默认的这三个参数配置写入HDFS后会产生小文件,hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount
基于以上hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0几个参数综合作用,效果如下:
- 文件在达到128M时会滚动生成新文件
- 文件创建超3600秒时会滚动生成新文件
5)编写Flume拦截器
(1)零点漂移问题(8号23:59:59秒数据文件在经过文件—Kafka—Flume采集的过程消耗的3s后在Flume中的KafkaSource event中的header部分的timestamp漂移为9号00:00:02导致HDFSSink将文件落盘于9号分区中)(所以编写拦截器解决此问题)

(2)在idea里创建名为gmall的项目
(3)在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.10.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>(4)在com.atguigu.gmall.flume.interceptor包下创建TimestampInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class TimestampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1、获取header和body的数据
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
try {
//2、将body的数据类型转成jsonObject类型(方便获取数据)
JSONObject jsonObject = JSONObject.parseObject(log);
//3、header中timestamp时间字段替换成日志生成的时间戳(解决数据漂移问题)
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()) {
Event event = iterator.next();
if (intercept(event) == null) {
iterator.remove();
}
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}(5)打包

(6)需要先将打好的包放入到hadoop104的/opt/module/flume/lib文件夹下面。
2.1.4 日志消费Flume测试
1)启动Zookeeper、Kafka、HDFS
2)启动日志采集Flume
[atguigu@hadoop102 ~]$ f1.sh start3)启动hadoop104的日志消费Flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf4)生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh 5)观察HDFS是否出现数据
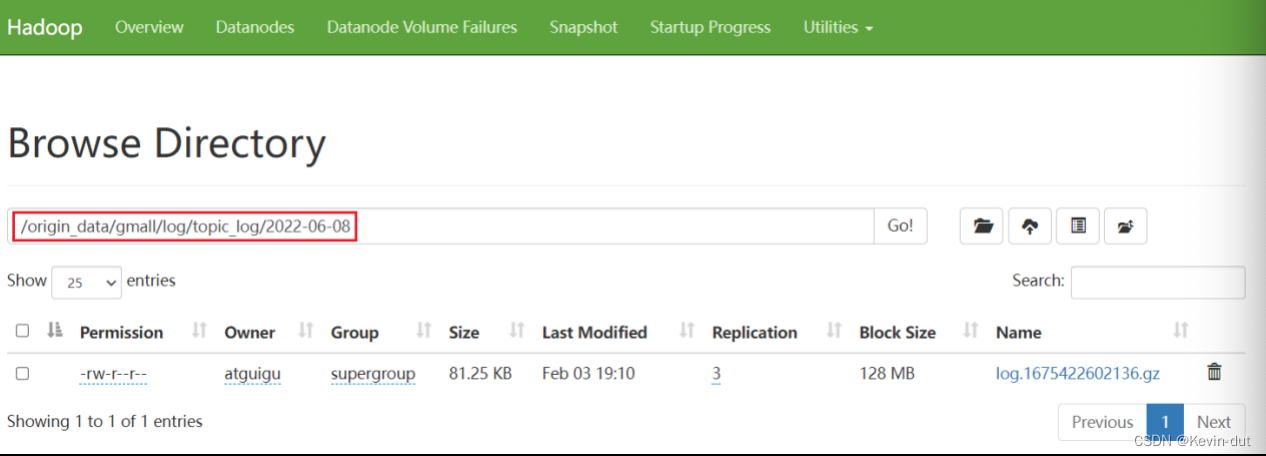
2.1.5 日志消费Flume启停脚本
若测试通过,为方便创建一个日志消费Flume启停脚本,过程同日志采集Flume,内容:
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 日志数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 日志数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac2.2 业务数据同步
2.2.1数据同步策略概述
业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后再对数据进行分析统计。
为保证统计结果的正确性,需要保证数据仓库中的数据与业务数据库是同步的,离线数仓的计算周期通常为天,所以数据同步周期也通常为天,即每天同步一次即可。
数据的同步策略有全量同步和增量同步。
全量同步:即每天将业务数据库中的全部数据同步一份到数据仓库,是保证两侧数据同步的最简单的方式。
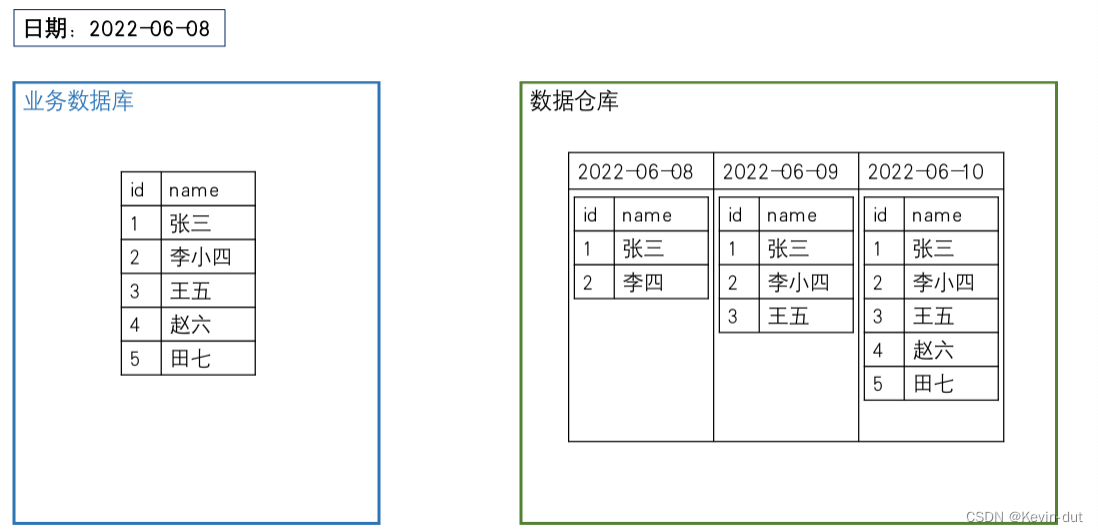
增量同步:即每天只将业务数据中的新增及变化数据同步到数据仓库,采用每日增量同步的表通常要在首日进行一次全量同步。

2.2.2策略选择
| 同步策略 | 优点 | 缺点 |
| 全量同步 | 逻辑简单 | 在某些情况下效率较低。例如某张表数据量较大,但是每天数据的变化比例很低,若对其采用每日全量同步,则会重复同步和存储大量相同的数据。 |
| 增量同步 | 效率高,无需同步和存储重复数据 | 逻辑复杂,需要将每日的新增及变化数据同原来的数据进行整合,才能使用 |
通常情况,业务表数据量比较大,优先考虑增量,数据量比较小,优先考虑全量;具体选择由数仓模型决定。
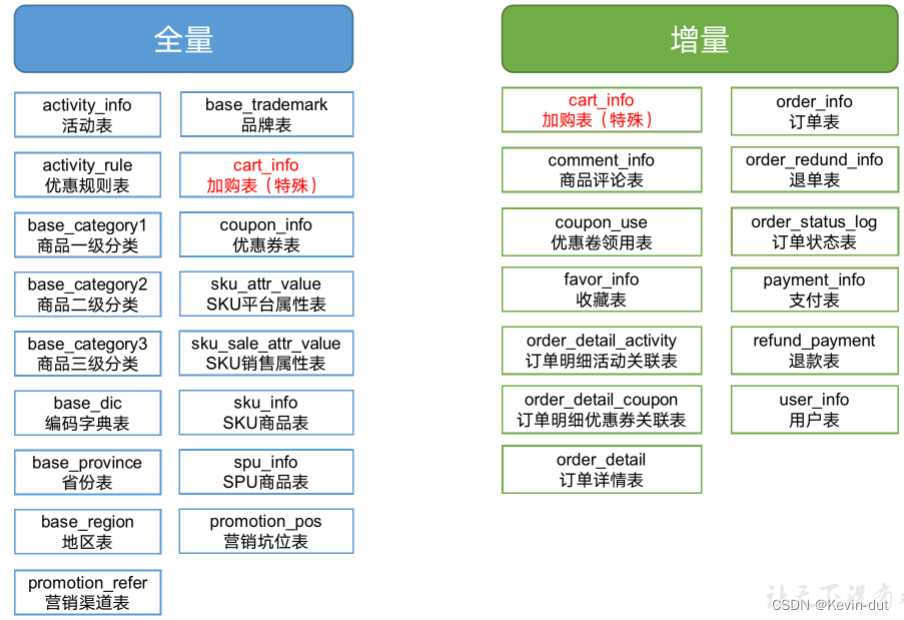
本项目各表同步策略
2.2.3数据同步工具概述
数据同步工具种类繁多,大致可分为两类,一类是以DataX、Sqoop为代表的基于Select查询的离线、批量同步工具,另一类是以Maxwell、Canal为代表的基于数据库数据变更日志(例如MySQL的binlog,其会实时记录所有的insert、update以及delete操作)的实时流式同步工具。
全量同步通常使用DataX、Sqoop等基于查询的离线同步工具。而增量同步既可以使用DataX、Sqoop等工具,也可使用Maxwell、Canal等工具,下面对增量同步不同方案进行简要对比。
| 增量同步方案 | DataX/Sqoop | Maxwell/Canal |
| 对数据库的要求 | 原理是基于查询,故若想通过select查询获取新增及变化数据,就要求数据表中存在create_time、update_time等字段,然后根据这些字段获取变更数据。 | 要求数据库记录变更操作,例如MySQL需开启binlog。 |
| 数据的中间状态 | 由于是离线批量同步,故若一条数据在一天中变化多次,该方案只能获取最后一个状态,中间状态无法获取。 | 由于是实时获取所有的数据变更操作,所以可以获取变更数据的所有中间状态。 |
本项目全量采用DataX,增量采用Maxwell
2.2.4全量表数据同步
数据同步工具DataX部署
DataX 是一款开源的数据同步工具,由阿里巴巴集团开发和维护,旨在解决不同数据源之间的数据传输和同步问题。它支持多种数据源和数据目的地,并提供丰富的数据同步功能和灵活的配置选项。
以下是关于 DataX 的简要介绍和使用方法:
-
数据源和数据目的地支持: DataX 支持多种数据源和数据目的地,包括但不限于:
- 关系型数据库(如 MySQL、Oracle、SQL Server 等)
- NoSQL 数据库(如 MongoDB、Redis、HBase 等)
- 分布式存储系统(如 HDFS、OSS 等)
- 文本文件(如 CSV、JSON、Parquet 等)
- 各种消息队列(如 Kafka、RocketMQ 等)
-
任务配置和执行: 使用 DataX,您可以通过编写 JSON 格式的任务配置文件来定义数据同步任务。任务配置文件包括源数据源配置、目的数据源配置、字段映射关系、数据过滤条件等信息。一旦配置完成,您可以使用 DataX 提供的命令行工具来执行任务,并监控任务的执行情况和进度。
-
插件机制: DataX 使用插件机制来支持不同类型的数据源和数据目的地。每种数据源或目的地对应一个特定的插件,用户可以根据需要选择并配置相应的插件。DataX 提供了丰富的内置插件,同时也支持用户自定义插件来满足特定的需求。
-
可扩展性和灵活性: DataX 的架构设计具有良好的可扩展性和灵活性,可以满足不同规模和复杂度的数据同步需求。它支持多线程并发执行、分布式任务调度和任务流水线等特性,以提高数据同步的效率和性能。
-
社区支持和文档资源: DataX 拥有活跃的社区和完善的文档资源,用户可以在社区中获取技术支持、提交反馈和贡献代码。此外,DataX 的官方文档提供了详细的使用说明、示例代码和常见问题解答,帮助用户快速上手和解决问题。
数据通道:由DataX从MySQL业务数据库直接同步到HDFS
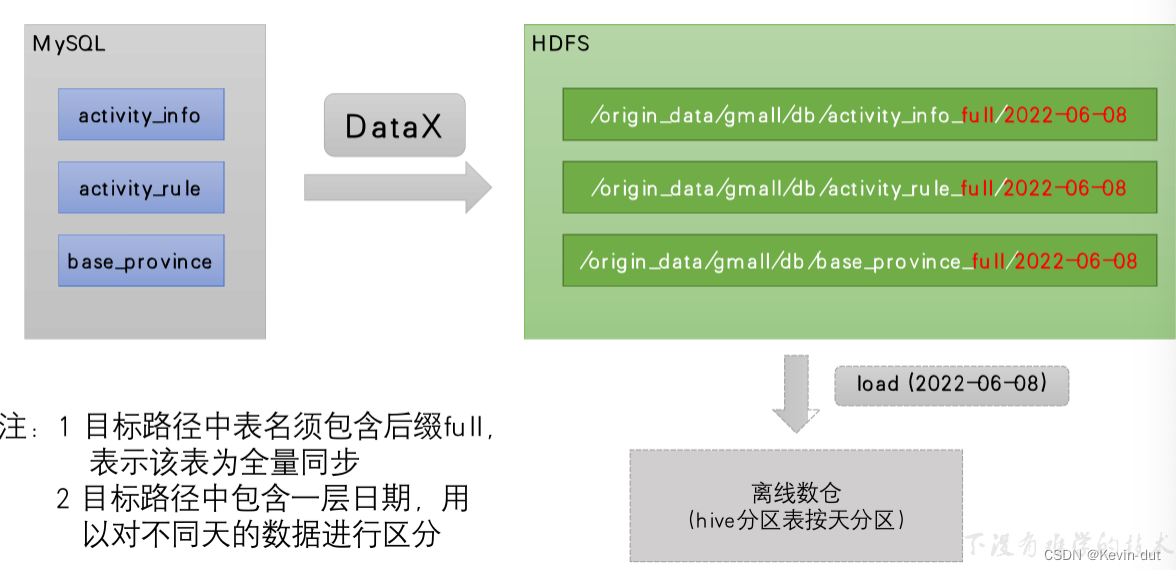
2.2.4.3 DataX配置文件
我们需要为每张全量表编写一个DataX的json配置文件,此处以activity_info为例,配置文件内容如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"activity_name",
"activity_type",
"activity_desc",
"start_time",
"end_time",
"create_time"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf-8"
],
"table": [
"activity_info"
]
}
],
"password": "000000",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "activity_name",
"type": "string"
},
{
"name": "activity_type",
"type": "string"
},
{
"name": "activity_desc",
"type": "string"
},
{
"name": "start_time",
"type": "string"
},
{
"name": "end_time",
"type": "string"
},
{
"name": "create_time",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "activity_info",
"fileType": "text",
"path": "${targetdir}",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}注:由于目标路径包含一层日期,用于对不同天的数据加以区分,故path参数并未写死,需在提交任务时通过参数动态传入,参数名称为targetdir。
2.2.4.4 DataX配置文件生成
1)DataX配置文件生成器使用
2)将生成器上传到服务器的/opt/module/gen_datax_config目录
3)上传生成器

4)修改configuration.properties配置
mysql.username=root
mysql.password=000000
mysql.host=hadoop102
mysql.port=3306
mysql.database.import=gmall
# mysql.database.export=gmall
mysql.tables.import=activity_info,activity_rule,base_trademark,cart_info,base_category1,base_category2,base_category3,coupon_info,sku_attr_value,sku_sale_attr_value,base_dic,sku_info,base_province,spu_info,base_region,promotion_pos,promotion_refer
# mysql.tables.export=
is.seperated.tables=0
hdfs.uri=hdfs://hadoop102:8020
import_out_dir=/opt/module/datax/job/import
# export_out_dir=5)执行
[atguigu@hadoop102 gen_datax_config]$ java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar6)观察结果
[atguigu@hadoop102 ~]$ ll /opt/module/datax/job/import
总用量 68
-rw-rw-r--. 1 atguigu atguigu 976 2月 3 21:56 activity_info.json
-rw-rw-r--. 1 atguigu atguigu 1116 2月 3 21:56 activity_rule.json
-rw-rw-r--. 1 atguigu atguigu 747 2月 3 21:56 base_category1.json
-rw-rw-r--. 1 atguigu atguigu 802 2月 3 21:56 base_category2.json
-rw-rw-r--. 1 atguigu atguigu 802 2月 3 21:56 base_category3.json
-rw-rw-r--. 1 atguigu atguigu 814 2月 3 21:56 base_dic.json
-rw-rw-r--. 1 atguigu atguigu 942 2月 3 21:56 base_province.json
-rw-rw-r--. 1 atguigu atguigu 758 2月 3 21:58 base_region.json
-rw-rw-r--. 1 atguigu atguigu 800 2月 3 21:56 base_trademark.json
-rw-rw-r--. 1 atguigu atguigu 1234 2月 3 21:56 cart_info.json
-rw-rw-r--. 1 atguigu atguigu 1461 2月 3 21:56 coupon_info.json
-rw-rw-r--. 1 atguigu atguigu 868 2月 3 21:56 promotion_pos.json
-rw-rw-r--. 1 atguigu atguigu 760 2月 3 21:56 promotion_refer.json
-rw-rw-r--. 1 atguigu atguigu 943 2月 3 21:56 sku_attr_value.json
-rw-rw-r--. 1 atguigu atguigu 1125 2月 3 21:56 sku_info.json
-rw-rw-r--. 1 atguigu atguigu 1051 2月 3 21:56 sku_sale_attr_value.json
-rw-rw-r--. 1 atguigu atguigu 898 2月 3 21:56 spu_info.json2.2.4.5 测试生成的DataX配置文件
以activity_info为例,测试用脚本生成的配置文件是否可用。
1)创建目标路径
由于DataX同步任务要求目标路径提前存在,故需手动创建路径,当前activity_info表的目标路径应为/origin_data/gmall/db/activity_info_full/2022-06-08。
[atguigu@hadoop102 bin]$ hadoop fs -mkdir -p /origin_data/gmall/db/activity_info_full/2022-06-082)执行DataX同步命令
[atguigu@hadoop102 bin]$ python /opt/module/datax/bin/datax.py -p"-Dtargetdir=/origin_data/gmall/db/activity_info_full/2022-06-08" /opt/module/datax/job/import/gmall.activity_info.json
3)观察同步结果
观察HFDS目标路径是否出现数据。
2.2.4.6 全量表数据同步脚本
为方便使用以及后续的任务调度,此处编写一个全量表数据同步脚本。
1)在~/bin目录创建mysql_to_hdfs_full.sh
脚本内容如下:
#!/bin/bash
DATAX_HOME=/opt/module/datax
# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
#处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行
handle_targetdir() {
hadoop fs -test -e $1
if [[ $? -eq 1 ]]; then
echo "路径$1不存在,正在创建......"
hadoop fs -mkdir -p $1
else
echo "路径$1已经存在"
fi
}
#数据同步
import_data() {
datax_config=$1
target_dir=$2
handle_targetdir $target_dir
python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config
}
case $1 in
"activity_info")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
;;
"activity_rule")
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
;;
"base_category1")
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
;;
"base_category2")
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
;;
"base_category3")
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
;;
"base_dic")
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
;;
"base_province")
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
;;
"base_region")
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
;;
"base_trademark")
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
;;
"cart_info")
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
;;
"coupon_info")
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
;;
"sku_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
;;
"sku_info")
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
;;
"sku_sale_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
;;
"spu_info")
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
;;
"promotion_pos")
import_data /opt/module/datax/job/import/gmall.promotion_pos.json /origin_data/gmall/db/promotion_pos_full/$do_date
;;
"promotion_refer")
import_data /opt/module/datax/job/import/gmall.promotion_refer.json /origin_data/gmall/db/promotion_refer_full/$do_date
;;
"all")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.promotion_pos.json /origin_data/gmall/db/promotion_pos_full/$do_date
import_data /opt/module/datax/job/import/gmall.promotion_refer.json /origin_data/gmall/db/promotion_refer_full/$do_date
;;
esac之后权限、测试、观察步骤同上
2.2.5 增量表数据同步
数据通道
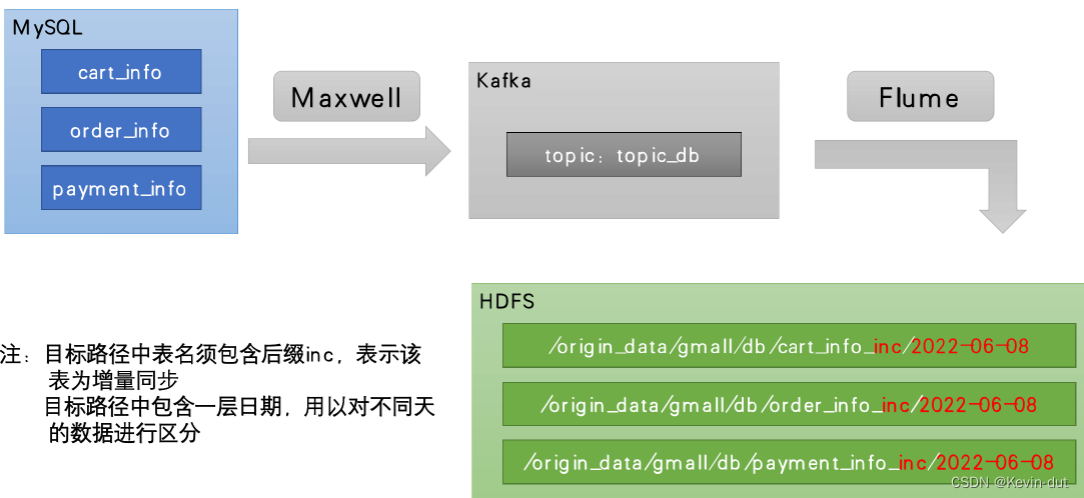
2.2.5.2 Flume配置
Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSink,Channel选用FileChannel。同前业务数据采集
需要注意的是, HDFSSink需要将不同MySQL业务表的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。关键配置如下:
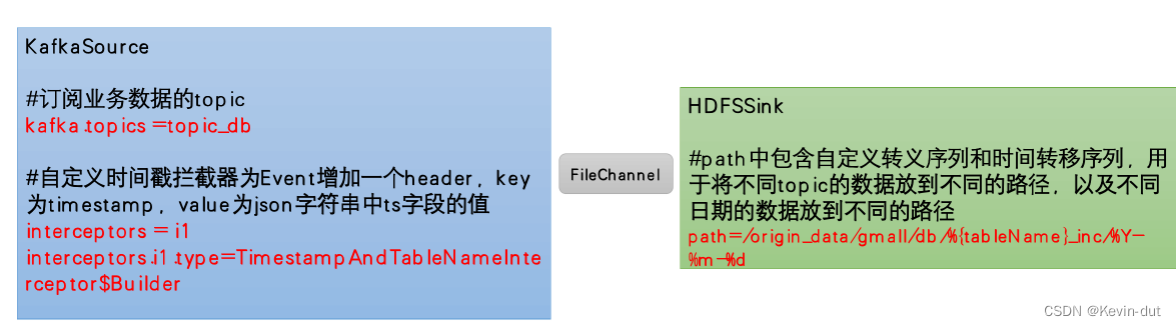
数据实例:

Flume配置实操
1)创建Flume配置文件
在hadoop104节点的Flume的job目录下创建kafka_to_hdfs_db.conf,配置文件内容如下
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampAndTableNameInterceptor$Builder
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c12)编写Flume拦截器
在com.atguigu.gmall.flume.interceptor包下创建TimestampAndTableNameInterceptor类。
package com.atguigu.gmall.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimestampAndTableNameInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
Long ts = jsonObject.getLong("ts");
//Maxwell输出的数据中的ts字段时间戳单位为秒,Flume HDFSSink要求单位为毫秒
String timeMills = String.valueOf(ts * 1000);
String tableName = jsonObject.getString("table");
headers.put("timestamp", timeMills);
headers.put("tableName", tableName);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampAndTableNameInterceptor ();
}
@Override
public void configure(Context context) {
}
}
}后打包
(3)删除hadoop104的/opt/module/flume/lib目录下的gmall-1.0-SNAPSHOT-jar-with-dependencies.jar文件
[atguigu@hadoop104 lib]$ cd /opt/module/flume/lib/
[atguigu@hadoop104 lib]$ rm gmall-1.0-SNAPSHOT-jar-with-dependencies.jar(4)将打好的包放入到hadoop104的/opt/module/flume/lib文件夹下
[atguigu@hadoop104 lib]$ ls | grep gmall
gmall-1.0-SNAPSHOT-jar-with-dependencies.jar最后进行通道测试
(1)启动Zookeeper、Kafka集群及Maxwell
(2)启动hadoop104的Flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_db.conf
(3)生成模拟数据
确保Maxwell正在运行,而后生成数据。
[atguigu@hadoop102 bin]$ lg.sh
(4)观察HDFS目标路径
(5)数据目标路径的日期说明
仔细观察,会发现目标路径中的日期,并非模拟数据的业务日期,而是当前日期。这是由于Maxwell输出的JSON字符串中的ts字段的值,是数据的变动日期。而真实场景下,数据的业务日期与变动日期应当是一致的。教学环境下需要修改时间戳日期。
4)编写Flume启停脚本
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 业务数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 业务数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac2.2.5.3 Maxwell配置
1)Maxwell时间戳问题

为了让Maxwell时间戳日期与模拟的业务日期保持一致,对Maxwell源码进行改动,增加了mock_date参数,在/opt/module/maxwell/config.properties文件中将该参数的值修改为业务日期即可。
2)补充mock.date参数
log_level=info
#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
# 目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=topic_db
# MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 过滤gmall中的z_log表数据,该表是日志数据的备份,无须采集
filter=exclude:gmall.z_log
# 指定数据按照主键分组进入Kafka不同分区,避免数据倾斜
producer_partition_by=primary_key
# 修改数据时间戳的日期部分
mock_date=2022-06-083)重新启动Maxwell
[atguigu@hadoop102 bin]$ mxw.sh restart4)重新生成模拟数据
[atguigu@hadoop102 bin]$ lg.sh
5)观察HDFS目标路径日期是否与业务日期保持一致
2.2.5.4 增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
1)在~/bin目录创建mysql_to_kafka_inc_init.sh
[atguigu@hadoop102 bin]$ vim mysql_to_kafka_inc_init.sh脚本内容:
#!/bin/bash
# 该脚本的作用是初始化所有的增量表,只需执行一次
MAXWELL_HOME=/opt/module/maxwell
import_data() {
$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}
case $1 in
"cart_info")
import_data cart_info
;;
"comment_info")
import_data comment_info
;;
"coupon_use")
import_data coupon_use
;;
"favor_info")
import_data favor_info
;;
"order_detail")
import_data order_detail
;;
"order_detail_activity")
import_data order_detail_activity
;;
"order_detail_coupon")
import_data order_detail_coupon
;;
"order_info")
import_data order_info
;;
"order_refund_info")
import_data order_refund_info
;;
"order_status_log")
import_data order_status_log
;;
"payment_info")
import_data payment_info
;;
"refund_payment")
import_data refund_payment
;;
"user_info")
import_data user_info
;;
"all")
import_data cart_info
import_data comment_info
import_data coupon_use
import_data favor_info
import_data order_detail
import_data order_detail_activity
import_data order_detail_coupon
import_data order_info
import_data order_refund_info
import_data order_status_log
import_data payment_info
import_data refund_payment
import_data user_info
;;
esac2)为mysql_to_kafka_inc_init.sh增加执行权限
3)测试同步脚本
(1)清理历史数据
为方便查看结果,现将HDFS上之前同步的增量表数据删除。
[atguigu@hadoop102 ~]$ hadoop fs -ls /origin_data/gmall/db | grep _inc | awk '{print $8}' | xargs hadoop fs -rm -r -f
(2)执行同步脚本
[atguigu@hadoop102 bin]$ mysql_to_kafka_inc_init.sh all
4)检查同步结果
观察HDFS上是否重新出现增量表数据。
2.3 采集通道启动/停止脚本
1)在/home/atguigu/bin目录下创建脚本cluster.sh
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
hdp.sh start
#启动 Kafka采集集群
kf.sh start
#启动采集 Flume
f1.sh start
#启动日志消费 Flume
f2.sh start
#启动业务消费 Flume
f3.sh start
#启动 maxwell
mxw.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Maxwell
mxw.sh stop
#停止 业务消费Flume
f3.sh stop
#停止 日志消费Flume
f2.sh stop
#停止 日志采集Flume
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
hdp.sh stop
#循环直至 Kafka 集群进程全部停止
kafka_count=$(xcall jps | grep Kafka | wc -l)
while [ $kafka_count -gt 0 ]
do
sleep 1
kafka_count=$(jpsall | grep Kafka | wc -l)
echo "当前未停止的 Kafka 进程数为 $kafka_count"
done
#停止 Zookeeper集群
zk.sh stop
};;
esac之后增加执行权限即可实现启停
3数仓环境准备
3.1 Hive安装部署
1)把hive-3.1.3.tar.gz上传到linux的/opt/software目录下
2)解压hive-3.1.3.tar.gz到/opt/module/目录下面
[atguigu@hadoop102 software]$ tar -zxvf /opt/software/hive-3.1.3.tar.gz -C /opt/module/3)修改hive-3.1.3-bin.tar.gz的名称为hive
[atguigu@hadoop102 software]$ mv /opt/module/apache-hive-3.1.3-bin/ /opt/module/hive4)修改/etc/profile.d/my_env.sh,添加环境变量
[atguigu@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin重启Xshell对话框或者source一下 /etc/profile.d/my_env.sh文件,使环境变量生效。
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh5)解决日志Jar包冲突,进入/opt/module/hive/lib目录
[atguigu@hadoop102 lib]$ mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak3.2 Hive元数据配置到MySQL
3.2.1 拷贝驱动
将MySQL的JDBC驱动拷贝到Hive的lib目录下。
[atguigu@hadoop102 lib]$ cp /opt/software/mysql/mysql-connector-j-8.0.31.jar /opt/module/hive/lib/3.2.2 配置Metastore到MySQL
在$HIVE_HOME/conf目录下新建hive-site.xml文件。添加如下内容。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--配置Hive保存元数据信息所需的 MySQL URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property>
<!--配置Hive连接MySQL的驱动全类名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--配置Hive连接MySQL的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置Hive连接MySQL的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>3.3 启动Hive
3.3.1 初始化元数据库
1)登陆MySQL
[atguigu@hadoop102 conf]$ mysql -uroot -p000000
2)新建Hive元数据库
mysql> create database metastore;
3)初始化Hive元数据库
[atguigu@hadoop102 conf]$ schematool -initSchema -dbType mysql -verbose
4)修改元数据库字符集
Hive元数据库的字符集默认为Latin1,由于其不支持中文字符,所以建表语句中如果包含中文注释,会出现乱码现象。如需解决乱码问题,须做以下修改。
修改Hive元数据库中存储注释的字段的字符集为utf-8。
(1)字段注释
mysql> use metastore;
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
(2)表注释
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
5)退出mysql
3.3.2 启动Hive客户端
1)启动Hive客户端
[atguigu@hadoop102 hive]$ hive
2)查看一下数据库
hive (default)> show databases;
OK
database_name
default
Time taken: 0.955 seconds, Fetched: 1 row(s)














 2903
2903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









