







第二章:线性表
定义、特点
一、定义
诸如此类由n(n>=0)个数据特性相同的元素构成的有限序列称为线性表,线性表中元素的个数n(n>=0)定义为线性表的长度以,n=0时称为空表。
二、特点
(1)存在唯一一个被称为“第一个”的数据元素;
(2)存在唯一一个被称为“最后一个”的数据元素;
(3)除第一个之外,结构中的每个数据元素均只有一个前驱;
(4)除最后一个之外,结构中的每个数据元素均只有一个后继。
顺序表
一、定义
线性表的顺序存储又称为顺序表。它是用一组地址连续的存储单元,依次存储线性表中的数据元素,从而使得逻辑上相邻的两个元素在物理位置上也相邻。
二、存储结构描述
#define MAXSIZE 100 //顺序表可能达到的最大长度
typedef struct
{
ElemType *elem; //存储空间的基地址
int length; //当前长度
}SqList; //顺序表的结构类型为SqList
(打包,课本例子:多项式
#define MAXSIZE 100 //多项式可能达到的最大长度
typedef struct //多项式非零项的定义
{
float coef; //系数
int expn; //指数
}Polynomial;
typedef struct
{
Polynomial *elem; //存储空间的基地址
int length; //多项式中当前项的个数
}SqList; //多项式的顺序存储结构类型为SqList
三、基本操作的实现
-
初始化
Status InitList(SqList &L) { L.elem = new ElemType[MAXSIZE]; //分配空间 if (!L.elem) exit(OVERFLOW); //分配失败退出 L.length = 0; //空表长度为0 return OK; } -
取值(时间复杂度:O(1))
Status GetElem(SqList &L, ElemType &e) { if (i<1||i>L.length) return ERROR; //判断i值是否合理,不合理返回ERROR e = L.elem[i-1]; //elem[i-1]单元存储第i个数据元素 return OK; } -
查找(时间复杂度:O(n))
int LocateElem(SqList L, ElemType e) { for (int i=0;i<L.length;i++) { if (L.elem[i]==e) return i+1; //查找成功,返回序号i+1 } return 0; //查找失败,返回0 } -
插入(时间复杂度:O(n))
Status ListInsert(SqList &L, int i, ElemType e) { if ((i<1)||(i>L.length+1)) return ERROR; //i值不合法 if (L.length == MAXSIZE) return ERROR; //当前存储空间已满 for (int j=L.length-1;j>=i-1;j--) { L.elem[j+1] = L.elem[j]; //插入位置及之后的元素后移 } L.elem[i-1] = e; //将新元素e放入第i个位置 ++L.length; //表长加1 return OK: } -
删除(时间复杂度:O(n))
Status ListDelete(SqList &L, int i) { if ((i<1)||(i>L.length+1)) return ERROR; //i值不合法 for (int j=i;j<=L.length-1;j++) { L.elem[j-1] = L.elem[j]; //被删除元素之后的元素前移 } --L.length; //表长减1 return OK; }
四、算法分析
时间复杂度:O(n)
缺点:在做插入或删除
链表
一、存储结构描述
typedef struct LNode
{
ElemType data;//数据域
struct LNode *next;//指针域
}LNode,*LinkList; //LinkList为指向结构体LNode的指针类型
二、基本操作的实现
-
初始化
Status InitList(LinkList &L) { L = new LNode;//生成头结点 这样删除等操作就不必分第一个结点和其他了 L->next = NULL; return 1; } -
取值(时间复杂度:O(n))
Status *GetElem(LinkList &L,int i, ElemType &e) { int j = 1; LNode *p = L->next; while(p&&j<i) { p=p->next; j++; } if (!p||j>i) return ERROR; e = p->data; return 1; } -
查找(时间复杂度:O(n))
LNode *LocateElem(LinkList &L ,ElemType e) { LNode *p = L->next; while(p!=NULL&&p->data!=e) p = p->next; return p; } -
插入(时间复杂度:O(n))
Status ListInsert(LinkList &L,int i,ElemType e) { LNode* s;LinkList p=L;int j=0; while(p&&(j<i-1))//j指到i-1位置或者p已经到最后时跳出 { p=p->next; ++j; } if(!p||j>i-1) return 0; s=new LNode; s->data=e; s->next=p->next; p->next=s; return 1; } -
删除(时间复杂度:O(n))
Status ListDelete(LinkList &L,int i) { LNode* s;LinkList p=L;int j=0; LinkList q; while(p&&(j<i-1))//j指到i-1位置 { p=p->next; ++j; } if(!(p->next)||j>i-1) return 0; q=p->next; p->next=q->next; free(q);//释放空间 return true; } -
创建单链表(时间复杂度:O(n))
//头插法 void CreateList(LinkList *&L, int n) { LNode *L = new LNode; //创建一个带头结点的空链表 L->next = NULL; for (int i=0;i<n;i++) { LNode *p = new LNode; cin >> p->data; p->next=L->next; //将新结点*p插入到头结点之后 L->next=p; }//尾插法 void CreatList_R(LinkList &L, int n) { LinkList r;//定义一个尾指针 L=new LNode; //L为头结点 L->next=NULL; r=L; //尾指针r指向头结点 for(int i=0;i<n;++i) { LinkList p = new LNode; cin>>p->data; p->next=NULL; //将新结点*p插入尾结点*r之后 r->next=p; r=p; //r指向新的尾结点*p } }
线性表应用
一、线性表的合并
void Merge(SqList &LA,SqList &LB)
{
int n = Length(LA),m = Length(LB);
int i,x;
for (i=1;i<=n;i++)
{
GetElem(LB,i,x); //取LB中第i个元素赋值给x
if (!LocateElem(LA, x)) //LA中不存在和x相同的元素
ListInsert(LA,m++,x); //将x插在LA的最后
}
}
二、有序表的合并
//顺序有序表
void MergeList_Sq(SqList LA, SqList LB, SqList &LC)
{
LC.length = LA.length + LB.length;
LC.elem = new ElemType[LC.length];
LNode *pa, *pb, *pc;
LNode *pa_last, *pb_last;
pc = LC.elem;
pa = LA.elem;
pb = LB.elem;
pa_last = LA.elem + LA.length - 1;
pb_last = LB.elem + LB.length - 1;
//逻辑上好理解 LA LB 一起找 小的就塞到LC 如果都其中一个空了 另一个就全塞进去
while (pa <= pa_last && pb <= pb_last) //均为达到表尾
{
if (*pa <= *pb) *pc++ = *pa++; //取两表中较小的值插入到LC的最后
else *pc++ = *pb++;
}
while (pa <= pa_last) *pc++ = *pa++; //LB以达到表尾,依次将LA的剩余元素插入到LC的最后
while (pb <= pb_last) *pc++ = *pb++; //同理
}
//链式有序表
void MergeList_L(LinkList &LA, LinkList &LB, LinkList &LC)
{
LinkList pa,pb,pc;
pa=LA->next;pb=LB->next; //pa和pb的初值分别指向两个表的第一个结点
LC=LA; //用LA的头结点作为LC的头结点
pc=LC; //pc指向LC的头结点
while(pa&&pb)
{//LA和LB均未达到表尾,则依次“摘取”两表中较小的结点插入到C的最后
if(pa->data <= pb->data)
{
pc->next=pa;
pc=pc->next;
pa=pa->next;
}
else
{
pc->next=pb;
pc=pc->next;
pb=pb->next;
}
} //while循环结束,有一表或两表为空
pc->next=pa? pa:pb; //将非空表的剩余段插入到pc所指结点之后
//相当于
/*if(pa)
{
pc-> next = pa;
else
pc-> next = pb;
}*/
delete LB;
}
作业练习题
一、选择填空
- For a sequentially stored linear list of length N, the time complexities for query and insertion are O(1) and O(N), respectively. (T)
(翻译:对于长度为N的顺序存储的线性列表,查询和插入的时间复杂度分别为O(1)和O(N))
查询相当于访问结点,只需要按照下标访问。
- If the most commonly used operations are to visit a random position and to insert and delete the last element in a linear list, then sequential storage works the fastest. (T)
(翻译:如果最常用的操作是访问随机位置并插入和删除线性列表中的最后一个元素,则顺序存储的工作速度最快。)
顺序存储结构可以实现随机访问并插入,删除最后一个元素不需要进行易懂,所以速度最快。
- In a singly linked list of N nodes, the time complexities for query and insertion are O(1) and O(N), respectively. (F)
(翻译:在N个节点的单链接列表中,查询和插入的时间复杂度分别为O(1)和O(N)。)
链表中操作时间复杂度都不为O(1),查询插入操作时间复杂度都为O(n)。
- 将N个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是O(logN)。 (F)
二分查找不可以用于链表
- 下列代码的功能是返回带头结点的单链表L的逆转链表。(代码填空)
List Reverse( List L ) { Position Old_head, New_head, Temp; New_head = NULL; Old_head = L->Next; while ( Old_head ) { Temp = Old_head->Next; *Old_head->Next = New_head;* New_head = Old_head; Old_head = Temp; } *L->Next = New_head;* return L; }
二、代码实战
-
在有序链表中插入数据 (20分)
给定一批严格递增排列的整型数据,给定一个x,若x不存在,则插入x,要求插入后保持有序。存在则无需任何操作。
输入格式:
输入有两行: 第一个数是n值,表示链表中有n个数据。后面有n个数,分别代表n个数据。 第二行是要插入的数。
输出格式:
输出插入后的链表数据,以空格分开。行末不能有多余的空格。
输入样例1:
在这里给出一组输入。例如:5 1 3 6 9 11 4输出样例1:
在这里给出相应的输出。例如:1 3 4 6 9 11输入样例2:
在这里给出一组输入。例如:5 1 3 6 9 11 3输出样例2:
在这里给出相应的输出。例如:1 3 6 9 11代码实现
#include <iostream> using namespace std; typedef int ElemType; typedef int status; typedef struct LNode { ElemType data; struct LNode *next; }LNode, *LinkList; status Initial (LinkList &L) { L = new LNode; L->next = NULL; return 1; } void CreateList(LinkList &L, ElemType n) {//输入第n个元素,尾插法建立带表头节点的单链表L LNode *p,*r; ElemType i; L = new LNode; L->next = NULL; r = L; for(i=0;i<n;i++) { p = new LNode; //生成新结点 cin >> p->data; //输入元素值 p -> next = NULL; r -> next = p; //将p加到表尾 r = p; //r指向新的尾结点 } } status ListInsert (LinkList &L, ElemType x) { LNode *p = L; if (p->next == NULL) { LNode *q = new LNode; q->data = x; q->next = NULL; p->next = q; p = q; return 0; } while (p->next != NULL) { LNode* temp = p; p = p->next; if (p->data == x) return 0; if (p->data > x) { LNode* q = new LNode; q->data = x; q->next = p; temp->next = q; return 0; } } LNode* q = new LNode; q->data = x; q->next = NULL; p->next = q; p = q; return 0; } void Output (LinkList &L) { LNode *p = L->next; while (p != NULL) { cout << p->data; if (p->next != NULL) cout << " "; p = p->next; } } int main() { ElemType n, x, i; LinkList L; cin >> n; CreateList (L, n); cin >> x; ListInsert (L, x); Output(L); return 0; } -
实现链表的删除、插入、遍历操作,并退出
代码实现
#include <iostream> using namespace std; typedef int Status; #define ElemType int typedef struct node { ElemType data; struct node *next; }LNode; typedef struct { LNode *head; LNode *tail; }List; void InitList (LNode &L, List &a) //建立链表 { a.head = new LNode; a.head->next = NULL; a.tail = a.head; } void DestroyList(LNode &L, List &a) { LNode *p = a.head , *q; while (p!=NULL) //当p指向结点不为空 { q = p->next; //q指向p的下一结点 delete p; //回收p指向的结点空间 p = q; //p指向q指向的结点 } } void A(LNode &L, List &a, ElemType &x) //增加操作 { LNode *p; p = new LNode; //生成新结点 p -> data = x; p -> next = NULL; a.tail-> next = p; //将p加到表尾 a.tail = p; //r指向新的尾结点 cout << "Insert " << x << " OK" << endl; } /* 该方法删除了头结点,直接将首元结点当成了头结点;不需要考虑删除 // 最后一个结点时会删掉尾指针的问题。 void D(List &L) { if (L.head->next == NULL) { cout << "Empty list" << endl; return; } LNode *p = L.head; L.head = L.head->next; cout << "Delete " << p->data << " OK" << endl; delete p; }*/ void D(LNode &L, List &a) //删除操作 { if (a.head->next==NULL) cout << "Empty list" << endl; //判断链表是否为空 else { LNode *q; q = a.head->next; //指向头结点 ElemType x; x = q->data; if (q==a.tail) //重置尾结点 { a.head->next = NULL; a.tail = a.head; } else a.head->next = q->next; delete q; //释放q空间 cout << "Delete " << x << " OK" << endl; } } void L(LNode &L, List &a) //遍历操作 { LNode *p = a.head->next; //指向头结点 if (a.head->next==NULL) cout << "Empty list" << endl; //判断链表是否为空 else { while (p!=NULL) { cout << p->data ; p = p->next; if (p!=a.tail->next) cout << " "; // 输出数据以空格分隔 } } } int main() { LNode a; List b; ElemType m; InitList(a, b); char t[2]; //存储输入的数据 while(1) { for(int i=0;i<1;i++) //分情况考虑输入字符个数 { cin >> t[i]; } if(t[0]=='A') { for(int i=1;i<2;i++) { cin >> t[i]; } m = t[1]-'0'; //字符型转化为整型 A(a, b, m); } else if (t[0]=='D') D(a,b); else if (t[0]=='L') L(a, b); else if (t[0]=='E') { cout << "88"; break; //退出程序 } } DestroyList(a, b); return 0; }运行结果
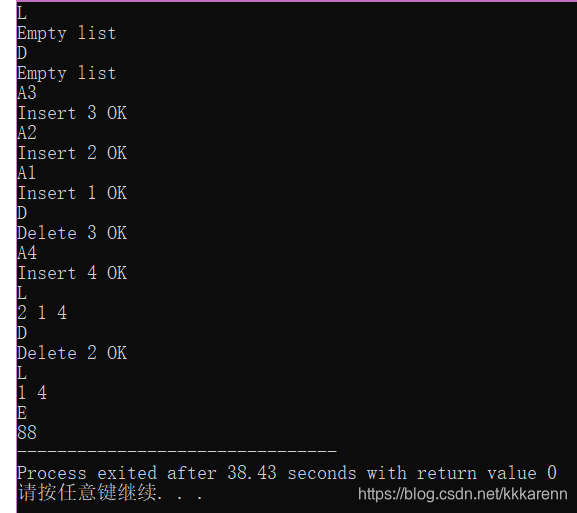
-
两个有序序列的中位数
已知有两个等长的非降序序列S1, S2, 设计函数求S1与S2并集的中位数。有序序列A0 ,A1 ,⋯,AN−1 的中位数指A(N−1)/2 的值,即⌊(N+1)/2⌋个数(A0 为第1个数)。输入格式:
输入分三行。第一行给出序列的公共长度N(0<N≤100000),随后每行输入一个序列的信息,即N个非降序排列的整数。数字用空格间隔。输出格式:
在一行中输出两个输入序列的并集序列的中位数。输入样例1:
5 1 3 5 7 9 2 3 4 5 6输出样例1:
4输入样例2:
6 -100 -10 1 1 1 1 -50 0 2 3 4 5输出样例2:
1代码实现
#include <iostream> using namespace std; typedef int Status; typedef int ElemType; #define MAXSIZE 100000 typedef struct { ElemType *elem; int length; } SqList; Status InitList(SqList &L) { L.elem = new ElemType[MAXSIZE]; L.length = 0; return 0; } void Input(SqList L, int N) { for (int i=0;i<N;i++) { cin >> L.elem[i]; } } Status GetElem(SqList L, int n, int &e) { if(n<1||n>L.length) return 0; e = L.elem[n-1]; return 1; } void MixList(SqList L1, SqList L2, SqList &L3, int N) { L3.length = N*2; int i, j, k; i = j = k = 0; for (;i<N,j<N;) { if (L1.elem[i]<=L2.elem[j]) { L3.elem[k] = L1.elem[i]; k++; i++; } else { L3.elem[k] = L2.elem[j]; k++; j++; } } } int main() { int N, e; cin >> N; SqList L1, L2, L3; InitList(L1); InitList(L2); InitList(L3); Input (L1,N); Input (L2,N); MixList(L1, L2, L3, N); if ((N*2)%2==0) { GetElem(L3, (L3.length)/2, e); } else { GetElem(L3, (L3.length+1)/2, e); } cout << e; return 0; } -
求两个一元多项式的和 (20分)
输入格式:
输入分2行,每行分别先给出多项式非零项的个数,再以指数递降方式输入一个多项式非零项系数和指数(绝对值均为不超过1000的整数)。数字间以空格分隔。输出格式:
输出分1行,分别以指数递降方式输出和多项式非零项的系数和指数。数字间以空格分隔,但结尾不能有多余空格。零多项式应输出0 0。输入样例1:
4 3 4 -5 2 6 1 -2 0 3 5 20 -7 4 3 1输出样例1:
5 20 -4 4 -5 2 9 1 -2 0代码实现
#include <iostream> using namespace std; typedef struct { int x;//系数 int y;//指数 }Node; typedef struct { Node data[1000]; int length; }SqList; void init(SqList &a) { a.length = 0; } void input(SqList &a) { cin >> a.length; for (int i=0;i<a.length ;i++) cin >> a.data[i].x >> a.data[i].y; } void output(SqList a) { int i; if (a.data[i].x==0) cout << 0 << " " << 0; else { for (i=0;i<a.length;i++) { if (i==0) cout << a.data[i].x << " " << a.data[i].y ; else cout << " " << a.data[i].x << " " << a.data[i].y ; } } } void add(SqList a, SqList b, SqList &c) { int i, j, k; i = j = k = 0; for (;i<a.length||j<b.length;) { if (a.data[i].y==b.data[j].y) { c.data[k].x = a.data[i].x + b.data[j].x ; if (c.data[k].x==0) { c.data[k].y==0; i++;j++; } else { c.data[k].y = a.data[i].y ; i++;j++;k++; } } else if (a.data[i].y>b.data[j].y) { c.data[k].x = a.data[i].x ; c.data[k].y = a.data[i].y ; i++;k++; } else if (a.data[i].y<b.data[j].y) { c.data[k].x = b.data[j].x ; c.data[k].y = b.data[j].y ; j++;k++; } c.length = k; } } int main() { SqList a, b, c; init(a); init(b); init(c); input(a); input(b); add(a, b, c); output(c); return 0; } -
两个有序链表序列的合并
已知两个非降序链表序列S1与S2,设计函数构造出S1与S2合并后的新的非降序链表S3。
输入格式:
输入分两行,分别在每行给出由若干个正整数构成的非降序序列,用−1表示序列的结尾(−1不属于这个序列)。数字用空格间隔。输出格式:
在一行中输出合并后新的非降序链表,数字间用空格分开,结尾不能有多余空格;若新链表为空,输出NULL。输入样例:
1 3 5 -1 2 4 6 8 10 -1输出样例:
1 2 3 4 5 6 8 10代码实现
#include <iostream> using namespace std; typedef int ElemType; typedef int Status; typedef struct LNode //存储结构定义 { ElemType data; //数据域 struct LNode *next;//指针域 int length; }LNode, *LinkList; void InitList(LinkList &L) //建立链表 { L = new LNode; L->next = NULL; } void CreateList(LinkList &L) { LNode *p,*r; ElemType temp; L = new LNode; L->next = NULL; r = L; cin >> temp; while((temp)!=-1) { p = new LNode; //生成新结点 p->data = temp; //输入元素值 p -> next = NULL; r -> next = p; //将p加到表尾 r = p; //r指向新的尾结点 cin >> temp; } } void Output (LinkList &L) { if (L->next==NULL) cout << "NULL"; else { LNode *p = L->next; while (p!=NULL) { cout << p->data ; p = p->next; if (p!=NULL) cout << " "; } } } void DestroyList(LinkList &L) { LNode *p = L, *q; while (p!=NULL) //当p指向结点不为空 { q = p->next; //q指向p的下一结点 delete p; //回收p指向的结点空间 p = q; //p指向q指向的结点 } } void MergeList(LinkList &a, LinkList &b, LinkList &c) { LNode *pa, *pb, *pc; pa = a->next ; pb = b->next ; pc = c; while (pa&&pb) { if (pa->data<=pb->data) { pc->next = pa; pc = pa; pa = pa->next; } else { pc->next = pb; pc = pb; pb = pb->next; } } if (pa!=NULL) { pc->next = pa; a->next=NULL; } if(pb!=NULL) { pc->next = pb; b->next=NULL; } } int main() { LinkList a, b, c; InitList(a); InitList(b); InitList(c); CreateList(a); CreateList(b); MergeList(a, b, c); Output(c); DestroyList(a); DestroyList(b); DestroyList(c); return 0; }
第三章:栈和队列
定义、特点
栈
顺序栈
链栈
栈与递归
队列
循环队列(顺序表示)
链队
作业练习题
判断选择填空
- 不论是入队列操作还是入栈操作,在顺序存储结构上都需要考虑"溢出"情况。 (T)
- 若一个栈的输入序列为1,2,3,…,N,输出序列的第一个元素是i,则第j个输出元素是j−i−1。 (F)
答案为不确定,输出序列的第一个元素是i,要分情况来看,当j<i时,答案为i-j+1;当j>i时,栈可以边进边出,这个时候第j个输出的元素就不一定是i-j+1了。
- (neuDS)下面( )问题求解过程中无须使用栈。 (D)
A.递归调用
B.数制转换
C.括号匹配
D.CPU资源管理 - 若栈采用顺序存储方式存储,现两栈共享空间V[m]:top[i]代表第i(i=1或2)个栈的栈顶;栈1的底在V[0],栈2的底在V[m-1],则栈满的条件是:(
top[1]+1==top[2]) - 若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一个结点。则采用哪种存储方式最节省运算时间?
带头结点的双循环链表 - 在解决计算机主机和打印机之间速度不匹配问题时通常设置一个打印数据缓冲区,主机将要输出的数据依次写入该缓冲区,而打印机将要输出的数据依次写入该缓冲区,而打印机则从该缓冲区中取走数据打印.该缓冲区应该是一个(
队列)结构。 - 设栈S和队列Q的初始状态均为空,元素a、b、c、d、e、f、g依次进入栈S。若每个元素出栈后立即进入队列Q,且7个元素出队的顺序是b、d、c、f、e、a、g,则栈S的容量至少是:
3 - 在单链表中,若p所指的结点不是最后结点,在p之后插入s所指结点,则执行:
s->next=p->next; p->next=s; - 如果循环队列用大小为m的数组表示,且用队头指针front和队列元素个数size代替一般循环队列中的front和rear指针来表示队列的范围,那么这样的循环队列可以容纳的元素个数最多为:
m
代码实战
-
括号匹配 (20分)
给定一串字符,不超过100个字符,可能包括括号、数字、字母、标点符号、空格,编程检查这一串字符中的( ) ,[ ],{ }是否匹配。输入格式:
输入在一行中给出一行字符串,不超过100个字符,可能包括括号、数字、字母、标点符号、空格。输出格式:
如果括号配对,输出yes,否则输出no。输入样例1:
sin(10+20)输出样例1:
yes输入样例2:
{[}]输出样例2:
no代码实现
#include <iostream> #include <string.h> using namespace std; #define MAXSIZE 101 typedef int SElemType; typedef int Status; typedef struct { SElemType *base; SElemType *top; int stacksize; }SqStack; Status InitStack(SqStack &S) { S.base = new SElemType[MAXSIZE]; if (!S.base) return 0; S.top = S.base; S.stacksize = MAXSIZE; return 1; } Status Push(SqStack &S, SElemType e) { if (S.top-S.base==S.stacksize) return 0; *S.top++ = e; return 1; } Status Pop(SqStack &S, SElemType e) { if (S.top-S.base==S.stacksize) return 0; e = *--S.top; return e; } SElemType GetTop(SqStack S) { if (S.top!=S.base) return *(S.top -1); } int main() { string a; int flag=1, x; SqStack S; InitStack(S); getline(cin,a); //可能会有空格,用getline可以读入空格; for(int i=0;a[i]!='\0';i++) { switch(a[i]) { case '{': Push(S,'{'); break; case '[': Push(S,'['); break; case '(': Push(S,'('); break; case '}': if(GetTop(S)=='{') Pop(S,x); else flag=0; break; case ']': if(GetTop(S)=='[') Pop(S,x); else flag=0; break; case ')': if(GetTop(S)=='(') Pop(S,x); else flag=0; break; default: break; } } if ((S.base==S.top)&&flag==1) cout << "yes"; else cout << "no"; return 0; } -
银行业务队列简单模拟 (20分)
设某银行有A、B两个业务窗口,且处理业务的速度不一样,其中A窗口处理速度是B窗口的2倍 —— 即当A窗口每处理完2个顾客时,B窗口处理完1个顾客。给定到达银行的顾客序列,请按业务完成的顺序输出顾客序列。假定不考虑顾客先后到达的时间间隔,并且当不同窗口同时处理完2个顾客时,A窗口顾客优先输出。输入格式:
输入为一行正整数,其中第1个数字N(≤1000)为顾客总数,后面跟着N位顾客的编号。编号为奇数的顾客需要到A窗口办理业务,为偶数的顾客则去B窗口。数字间以空格分隔。输出格式:
按业务处理完成的顺序输出顾客的编号。数字间以空格分隔,但最后一个编号后不能有多余的空格。输入样例:
8 2 1 3 9 4 11 13 15输出样例:
1 3 2 9 11 4 13 15代码实现
#include <iostream> #include <string.h> using namespace std; #define MAXSIZE 1001 typedef int QElemType; typedef int Status; typedef struct //队列定义 { QElemType *base; int front; int rear; }SqQueue; Status InitQueue (SqQueue &Q) { Q.base = new QElemType[MAXSIZE]; if (!Q.base) return 0; Q.front = Q.rear = 0; return 1; } Status EnQueue(SqQueue &Q, QElemType &e) { if ((Q.rear +1)%MAXSIZE==Q.front) return 0; Q.base[Q.rear] = e; Q.rear = (Q.rear+1)%MAXSIZE; return 1; } Status DeQueue(SqQueue &Q, QElemType &e) { if (Q.front == Q.rear) return 0; e = Q.base[Q.front]; Q.front = (Q.front+1)%MAXSIZE; return e; } int QueueLength(SqQueue Q) { return (Q.rear-Q.front+MAXSIZE)%MAXSIZE; } QElemType GetHead(SqQueue Q) { if (Q.front!=Q.rear) return Q.base[Q.front]; } bool EmptyQueue(SqQueue Q) { if (Q.front==Q.rear) return 0; //队列为空 else return 1; } void output (int a[], int n) { int i=1; cout << a[0]; for (;i<n;i++) cout << " " << a[i]; } int main() { int e, N, a[MAXSIZE], b[MAXSIZE]; int i=0, j=0; SqQueue A, B; InitQueue(B);//偶数B窗口,放B InitQueue(A);//奇数A窗口,放A cin >> N; for (;i<N;i++) { cin >> a[i]; if (a[i]%2==0) EnQueue(B, a[i]); else EnQueue(A, a[i]); } while ((A.front!=A.rear)&&(B.front!=B.rear)) { DeQueue(A, e); //A是B的两倍 b[j++] = e; DeQueue(A, e); b[j++] = e; DeQueue(B, e); b[j++] = e; } while (A.front!=A.rear) { DeQueue (A, e); b[j++] = e; } while (B.front!=B.rear) { DeQueue (B, e); b[j++] = e; } output(b, N); return 0; }
第四章:串、数组和广义表
串
数组
作业练习题
判断选择填空
- 二维数组A中,每个元素A的长度为3个字节,行下标i从0到7,列下标j从0到9,从首地址SA开始连续存放在存储器内,该数组按列存放时,元素A[4][7]的起始地址为()。提示:是按列存放。
SA+180 - 设主串 T = abaabaabcabaabc,模式串 S = abaabc,采用 KMP 算法进行模式匹配,到匹配成功时为止,在匹配过程中进行的单个字符间的比较次数是:
10
求next数组,next={-1,0,0,1,1,2};
开始匹配
abaabaabcabaabc
abaabc
当比较到s[5]时,不成功,比较6次;
abaabaabcabaabc
-----abaabc
根据next[5]=2,移动S到S[2]处,从S[2]处开始比较,比较4次,成功;
一共比较10次;
- 设有一个10阶的对称矩阵A,采用压缩存储方式,以行序为主进行存储,a11为第一元素,其存储地址为1,每个元素占一个地址空间,则a85的地址为:
33
代码实战
-
还是求集合交集
给定两个整数集合(每个集合中没有重复元素),集合元素个数<=100000,求两集合交集,并按非降序输出。输入格式:
第一行是n和m,表示两个集合的元素个数; 接下来是n个数和m个数。输出格式:
第一行输出交集元素个数; 第二行按非降序输出交集元素,元素之间以空格分隔,最后一个元素后面没有空格。输入样例:
在这里给出一组输入。例如:5 6 8 6 0 3 1 1 8 9 0 4 5输出样例:
在这里给出相应的输出。例如:3 0 1 8代码实现
#include <iostream> #include<algorithm> using namespace std; int main() { int a[100001], b[100001], c[200002]; int n, m, count=0; int i=0, j=0; cin >> n >> m; for (int i=0;i<n;++i) cin >> a[i]; for (int j=0;j<n;++j) cin >> b[j]; sort(a, a+n); sort(b, b+m); for (;i<n&&j<m;) { if (a[i]==b[j]) { c[count++] = a[i]; i++; j++; } else if(a[i]>b[j]) j++; else if(a[i]<b[j]) i++; } cout << count << endl; for (int i=0;i<count;i++) { cout << c[i]; if(i!=count-1) cout << " "; } return 0; }
第五章:数和二叉树
定义、性质、存储结构
遍历二叉树
树和森林
哈夫曼树
作业练习题
判断选择填空
- 任何最小堆的前序遍历结果是有序的(从小到大)(F)
- If the preorder and the postorder traversal sequences of a binary tree have exactly the opposite orders, then none of the nodes in the tree has two subtrees. (T)
(翻译:如果二叉树的前遍历和后遍历序列具有完全相反的顺序,则该树中的所有节点都没有两个子树。) - 某二叉树的后序和中序遍历序列正好一样,则该二叉树中的任何结点一定都无左孩子。 (F)
- 对N(≥2)个权值均不相同的字符构造哈夫曼树,则树中任一非叶结点的权值一定不小于下一层任一结点的权值。 (T)
- 将森林转换为对应的二叉树,若在二叉树中,结点u是结点v的父结点的父结点,则在原来的森林中,u和v可能具有的关系是:1.父子关系; 2. 兄弟关系; 3. u的父结点与v的父结点是兄弟关系 (1和2)
- 在一棵度为4的树T中,若有20个度为4的结点,10个度为3的结点,1个度为2的结点,10个度为1的结点,则树T的叶结点个数是:82
- 由分别带权为9、2、5、7的四个叶子结点构成一棵哈夫曼树,该树的带权路径长度为:44
- 任何一棵二叉树的叶结点在先序、中序和后序遍历序列中的相对次序:不发生改变
- 具有65个结点的完全二叉树其深度为(根的深度为1):7(完全二叉树的深度公式:⌊log2n⌋+1)
代码实战
-
求二叉树的叶子结点个数 (20分)
以二叉链表作为二叉树的存储结构,求二叉树的叶子结点个数。
输入格式:
输入二叉树的先序序列。
提示:一棵二叉树的先序序列是一个字符串,若字符是‘#’,表示该二叉树是空树,否则该字符是相应结点的数据元素。
输出格式:
输出有两行:
第一行是二叉树的中序遍历序列;
第二行是二叉树的叶子结点个数。
输入样例:ABC##DE#G##F###输出样例:
CBEGDFA 3代码实现
#include <iostream> using namespace std; typedef char TElemType; typedef struct BiTNode { TElemType data; struct BiTNode *lchild, *rchild; }BiTNode, *BiTree; void CreateBiTree(BiTree &T) { char ch; ch = getchar(); if (ch=='#') T = NULL; else { T = new BiTNode; T->data = ch; CreateBiTree(T->lchild); CreateBiTree(T->rchild); } } void InOrderTraverse(BiTree T) { if(T) { InOrderTraverse(T->lchild); cout << T->data; InOrderTraverse(T->rchild); } } int CountLeaves(BiTree T) {//统计T指向的二叉树的叶结点个数 if(T==NULL) return 0; if(T->lchild==NULL && T->rchild==NULL) return 1; return CountLeaves(T->lchild) + CountLeaves(T->rchild); } void Destroy(BiTree T) { if(T==NULL) return; Destroy(T->lchild); Destroy(T->rchild); delete T; } int main() { BiTree T = NULL; CreateBiTree(T); InOrderTraverse(T); cout << endl; cout << CountLeaves(T) << endl; Destroy(T); return 0; } -
List Leaves
给定一棵树,按照从上到下,从左到右的顺序列出所有叶子。
输入规格:
每个输入文件包含一个测试用例。
对于每种情况,第一行给出一个正整数N(≤10),它是树中节点的总数-因此,节点从0到N-1编号。
然后跟随N行,每行对应一个节点,并给出该节点左右子节点的索引。
如果孩子不存在,将在该位置放置一个“-”。
任何一对孩子都用空格隔开。
输出规格:
对于每个测试用例,按从上到下,从左到右的顺序在一行中打印所有叶子的索引。
相邻数字之间必须恰好有一个空格,行尾不得有多余的空格。
Sample Input:8 1 - - - 0 - 2 7 - - - - 5 - 4 6Sample Output:
4 1 5代码实现
#include <iostream> #include <queue> using namespace std; typedef struct { int lch; int rch; }Node; typedef struct { Node data[10]; int root; }Tree; void CreateTree(Tree &T) { int n, i; char a, b; bool check[10]={false}; cin >> n; for(i=0;i<n;i++) { cin >> a >> b; if(a=='-') { T.data[i].lch = -1; } else { T.data[i].lch = a-'0'; check[a-'0'] = true; } if(b=='-') { T.data[i].rch = -1; } else { T.data[i].rch = b-'0'; check[b-'0'] = true; } } for (i=0;i<n;i++) { if(check[i]==false) { T.root = i; break; } } } void LevelOrder(Tree T) { int k; bool flag = false; queue <int> Q; Q.push(T.root); while(!Q.empty()) { k = Q.front(); Q.pop(); if(T.data[k].lch==-1&&T.data[k].rch==-1) { if(flag==false) { cout << k; flag = true; } else cout << " " << k; } else { if(T.data[k].lch!=-1) Q.push(T.data[k].lch); if(T.data[k].rch!=-1) Q.push(T.data[k].rch); } } } int main() { Tree T; CreateTree(T); LevelOrder(T); return 0; } -
树的同构
给定两棵树T1和T2。如果T1可以通过若干次左右孩子互换就变成T2,则我们称两棵树是“同构”的。
现给定两棵树,请你判断它们是否是同构的。
输入格式:
输入给出2棵二叉树树的信息。对于每棵树,首先在一行中给出一个非负整数N (≤10),即该树的结点数(此时假设结点从0到N−1编号);随后N行,第i行对应编号第i个结点,给出该结点中存储的1个英文大写字母、其左孩子结点的编号、右孩子结点的编号。如果孩子结点为空,则在相应位置上给出“-”。给出的数据间用一个空格分隔。注意:题目保证每个结点中存储的字母是不同的。
输出格式:
如果两棵树是同构的,输出“Yes”,否则输出“No”。
输入样例1(对应图1):8 A 1 2 B 3 4 C 5 - D - - E 6 - G 7 - F - - H - - 8 G - 4 B 7 6 F - - A 5 1 H - - C 0 - D - - E 2 -输出样例1:
Yes输入样例2(对应图2):
8 B 5 7 F - - A 0 3 C 6 - H - - D - - G 4 - E 1 - 8 D 6 - B 5 - E - - H - - C 0 2 G - 3 F - - A 1 4输出样例2:
No代码实现
#include <iostream> using namespace std; #define MaxTree 10 #define Null -1 struct TreeNode { char Elem; int Left; int Right; }; TreeNode T1[MaxTree],T2[MaxTree]; int BuildTree(TreeNode T[]) { int N, k=-1; cin >> N; int check[10]; for (int i=0;i<N;i++) { check[i] = 0; } char value, lc, rc; if(N) { for(int i=0;i<N;i++) { cin >> T[i].Elem >> lc >> rc; if(lc!='-') { T[i].Left = lc-'0'; check[T[i].Left] = 1; } else T[i].Left = Null; if(rc!='-') { T[i].Right = rc-'0'; check[T[i].Right] = 1; } else T[i].Right = Null; } for(k=0;k<N;k++) { if (!check[k]) break; } } return k; } int Isomorphic(int R1, int R2) { if ((R1==Null)&&(R2==Null)) return 1; if (((R1==Null)&&(R2!=Null))||((R1!=Null)&&(R2==Null))) return 0; if (T1[R1].Elem!=T2[R2].Elem) return 0; if ((T1[R1].Left==Null)&&(T2[R2].Left==Null)) return Isomorphic(T1[R1].Right, T2[R2].Right); if (((T1[R1].Left!=Null)&&(T2[R2].Left!=Null))&&((T1[T1[R1].Left].Elem)==(T2[T2[R2].Left].Elem))) return ( Isomorphic(T1[R1].Left,T2[R2].Left)&&Isomorphic(T1[R1].Right,T2[R2].Right) ); else return ( Isomorphic(T1[R1].Left,T2[R2].Right)&&Isomorphic(T1[R1].Right,T2[R2].Left) ); } int main() { int R1, R2; R1 = BuildTree(T1); R2 = BuildTree(T2); if(Isomorphic(R1,R2)) cout << "Yes" << endl; else cout << "No" << endl; return 0; }
第六章:图
定义、术语
存储结构
邻接矩阵
邻接表
图的遍历
深度优先搜索(DFS)
广度优先搜索(BFS)
图的应用
最小生成树
最短路径
作业练习题
判断选择填空
- 如果图由邻接矩阵表示,则占用的空间仅取决于顶点数,而不取决于边数。(T)
- 在图G中,如果我们必须做两次BFS才能访问它的每个顶点,那么G中必须有两个相连的分量。(T)
- 用一维数组G[]存储有4个顶点的无向图如下:G[] = { 0, 1, 0, 1, 1, 0, 0, 0, 1, 0 },则顶点2和顶点0之间是有边的。(T)
从0开始计数,运用数组的公式i∗(i+1)/2+j
- Kruskal 算法是通过每步添加一条边及其相连的顶点到一棵树,从而逐步生成最小生成树。(F) (是prim算法)
- 若图G为连通图,则G必有唯一的一棵最小生成树。(F)不唯一
- 对于带权无向图 G = (V, E),M 是 G 的最小生成树,则 M 中任意两点 V1 到 V2 的路径一定是它们之间的最短路径。(F)
最小生成树的总权最小,不是其中的任意路径最小;
- P 是顶点 S 到 T 的最短路径,如果该图中的所有路径的权值都加 1,P 仍然是 S 到 T 的最短路径。(T)
假如说最短路径上一共有10条边,而另一条路径虽然比最短路径长,但它只有一条边,如果全加1,就会导致边少的路径成为新的最短路径。
- 我们用一个有向图来表示航空公司所有航班的航线。下列哪种算法最适合解决找给定两城市间最经济的飞行路线问题?(Dijkstra算法)
- 如果G是一个有15条边的非连通无向图,那么该图顶点个数最少为多少?(7)
无向图的边数:n(n-1)/2,非连通再加1。
- 具有6个顶点的无向图至少应有()条边才能确保是一个连通图。(5)
顶点为n,则最少需要n-1个才能连通该图
- 设有向图的顶点个数为n,则该图最多可以有()条弧。
每个顶点(共n个顶点)都有指向其余所有结点(n-1个)的边时,有向图具有最多边共有 n(n-1) 条边。
- 图的BFS生成树的树高比DFS生成树的树高(小或相等)
代码实战
-
列出连通集 (30分)
给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集。假设顶点从0到N−1编号。进行搜索时,假设我们总是从编号最小的顶点出发,按编号递增的顺序访问邻接点。
输入格式:
输入第1行给出2个整数N(0<N≤10)和E,分别是图的顶点数和边数。随后E行,每行给出一条边的两个端点。每行中的数字之间用1空格分隔。
输出格式:
按照"{ v1 v2 … vk }"的格式,每行输出一个连通集。先输出DFS的结果,再输出BFS的结果。
输入样例:8 6 0 7 0 1 2 0 4 1 2 4 3 5输出样例:
{ 0 1 4 2 7 } { 3 5 } { 6 } { 0 1 2 7 4 } { 3 5 } { 6 }代码实现
#include<iostream> #include<queue> using namespace std; #define MVNum 10 typedef struct { int vexnum,arcnum; int arcs[MVNum][MVNum]; int vexs[MVNum]; }AMGraph; int visited[MVNum]; int CreateUDN(AMGraph &G) { cin >> G.vexnum >> G.arcnum; for(int i=0;i<G.vexnum;i++) { for(int j=0;j<G.vexnum;j++) { G.arcs[i][j] = 0; } } int a, b; for (int i=0;i<G.arcnum;i++) { cin >> a >> b; G.arcs[a][b] = 1; G.arcs[b][a] = 1; } } void DFS(AMGraph &G, int v) { visited[v] = 1; cout << v << " "; for(int w=0;w<G.vexnum;w++) { if(G.arcs[v][w] && !visited[w]) { DFS(G, w); } } } void BFS(AMGraph &G, int v) { visited[v] = 1; queue<int> q; q.push(v); while(!q.empty()) { int m = q.front(); cout << m << " "; q.pop(); for(int i=0;i<G.vexnum;i++) { if(G.arcs[i][m] && !visited[i]) { visited[i] = 1; q.push(i); } } } } int main() { AMGraph G; CreateUDN(G); for(int i=0;i<G.vexnum;i++) { visited[i] = 0; } for(int i=0;i<G.vexnum;i++) { if (visited[i]==1) continue; cout << "{ "; DFS(G, i); cout << "}" << endl; } for(int i=0;i<G.vexnum;i++) { visited[i] = 0; } for(int i=0;i<G.vexnum;i++) { if (visited[i]==0) { cout << "{ " ; BFS(G, i); cout << "}" << endl; } } return 0; } -
拯救007 (30分)
在老电影“007之生死关头”(Live and Let Die)中有一个情节,007被毒贩抓到一个鳄鱼池中心的小岛上,他用了一种极为大胆的方法逃脱 —— 直接踩着池子里一系列鳄鱼的大脑袋跳上岸去!(据说当年替身演员被最后一条鳄鱼咬住了脚,幸好穿的是特别加厚的靴子才逃过一劫。)设鳄鱼池是长宽为100米的方形,中心坐标为 (0, 0),且东北角坐标为 (50, 50)。池心岛是以 (0, 0) 为圆心、直径15米的圆。给定池中分布的鳄鱼的坐标、以及007一次能跳跃的最大距离,你需要告诉他是否有可能逃出生天。
输入格式:
首先第一行给出两个正整数:鳄鱼数量 N(≤100)和007一次能跳跃的最大距离 D。随后 N 行,每行给出一条鳄鱼的 (x,y) 坐标。注意:不会有两条鳄鱼待在同一个点上。输出格式:
如果007有可能逃脱,就在一行中输出"Yes",否则输出"No"。输入样例 1:
14 20 25 -15 -25 28 8 49 29 15 -35 -2 5 28 27 -29 -8 -28 -20 -35 -25 -20 -13 29 -30 15 -35 40 12 12输出样例 1:
Yes输入样例 2:
4 13 -12 12 12 12 -12 -12 12 -12输出样例 2:
No代码实现
#include <iostream> using namespace std; struct Node {//点坐标 int x; int y; }s[101]; int visited[101]; int flag = 0; int jumpborder(int i, int D) //判断是否能跳到岸边 { if(50-s[i].x<=D || 50+s[i].x <=D || 50-s[i].y<=D || 50+s[i].y<=D) { return 1; } else return 0; } int jump(int i, int j, int D) //判断两点间距离是否可跳跃 { if( (s[i].x-s[j].x)*(s[i].x-s[j].x)+(s[i].y-s[j].y)*(s[i].y-s[j].y) <= D*D ) { return 1; } else return 0; } int FirstJump(int i, int D) //判断第一次可跳的点 { if(s[i].x*s[i].x+s[i].y*s[i].y <= (D+7.5)*(D+7.5)) { return 1; } else return 0; } int save007_dfs(int t, int D, int N) { visited[t] = 1; if (jumpborder(t, D)==1) flag = 1; //如果可以跳到岸边 for (int i=0;i<N;i++) { if(!visited[i]&&jump(t,i, D)) //点未被跳过且两点之间可跳跃 { flag = save007_dfs(i, D, N); //递归dfs算法 } } return flag; } int main() { int N, D; cin >> N >> D; for(int i=0;i<N;i++) { cin >> s[i].x >> s[i].y; } for(int i=0;i<N;i++) //重置visited数组 { visited[i] = 0; } if(D>=50-7.5) cout << "Yes" << endl; //跳跃距离大于等于岛到边界的距离 else { for(int i=0;i<N;i++) //循环每个点 { if(!visited[i]&&FirstJump(i,D)) //判断是否未被跳过且第一次可跳跃 { save007_dfs(i, D, N); } } if(flag==1) cout << "Yes" << endl; else cout << "No" << endl; } return 0; }
第七章:查找
线性表的查找
顺序查找
折半查找
分块查找
树表的查找
二叉排序树
散列表的查找
基本概念
构造方法
处理冲突的方法
查找
作业练习题
判断选择填空
- 即使把2个元素散列到有100个单元的表中,仍然有可能发生冲突。(T)若2个元素的相同散列函数值,则发生冲突
- 在散列表中,所谓同义词就是具有相同散列地址的两个元素。(T)
- 在机场安检处做爆炸物品检测时,召回率比准确率更重要。(T)
- 采用平方探测冲突解决策略(hi (k)=(H(k)+i^2)%11, 注意:不是±i^2 ),将一批散列值均等于2的对象连续插入一个大小为11的散列表中,那么第4个对象一定位于下标为0的位置。(T)
- 已知一个长度为16的顺序表L,其元素按关键字有序排列。若采用二分查找法查找一个L中不存在的元素,则关键字的比较次数最多是 :5
16个二叉排序树的深度为5,查找一个不存在的最多查到最后一层,即5
- 在下列查找的方法中,平均查找长度与结点个数无关的查找方法是:散列(哈希)查找
代码实战
-
Hashing
将一个不同的正整数序列插入到哈希表中,然后输出输入数字的位置。哈希函数定义为H(key)= key%TSize,其中TSize是哈希表的最大大小。二次探测(仅具有正增量)用于解决冲突。
请注意,表大小最好是素数。
如果用户给出的最大大小不是素数,则必须将表大小重新定义为最小的素数,该最小的素数大于用户给出的大小。
输入规格:
每个输入文件包含一个测试用例。
对于每种情况,第一行包含两个正数:MSize(≤104)和N(≤MSize)分别是用户定义的表大小和输入数字的数量。
然后在下一行中给出N个不同的正整数。一行中的所有数字都用空格分隔。
输出规格:
对于每个测试用例,在一行中打印输入数字的相应位置(索引从0开始)。
一行中的所有数字均以空格分隔,并且行尾不得有多余的空格。
如果无法插入数字,请打印“-”。
Sample Input:4 4 10 6 4 15Sample Output:
0 1 4 -代码实现
#include <iostream> using namespace std; bool IsPrime(int n) //判断素数 { if(n<=1) return 0; for(int i=2;i<n;i++) { if((n%i)==0) return 0; //能被任意n-1中的一个数整除 } return 1; } int main() { int MSize, N; cin >> MSize >> N; while((IsPrime(MSize)==0)) //若输入的表长不是素数 { MSize++; } int a[10007]={0};//表 int x; //要插入的数 for(int i=0;i<N;i++) { cin >> x; int j=0; int k = x%MSize; int temp = k; while(j<MSize) { if((a[k])==0) { a[k] = x; cout << k; break; } else { j++; k = (temp+j*j) % MSize; } } if(j==MSize) cout << "-"; if(i!=N-1) cout << " "; } return 0; } -
二分查找变形 (20分)
设a[0:n-1]是按非降序排列的数组,请改写二分查找算法,查找自左向右第一个大于等于x的值。若不存在这样的数,输出-1
输入格式:
输入有三行: 第一行是n值; 第二行是n个数; 第三行是x值。
输出格式:
输出自左向右第一个大于等于x的值的下标。若不存在这样的数,输出-1
输入样例:
在这里给出一组输入。例如:5 1 3 5 7 9 6输出样例:
在这里给出相应的输出。例如:3代码实现
#include <iostream> using namespace std; int Search_Bin(int a[], int n, int x) { int low = 0; int high = n-1; int mid; if (x>a[n-1]) return -1; else if(x<a[0]) return 0; else { while(low<=high) { mid = (low+high)/2; if(x<=a[mid]) high = mid-1; else low = mid+1; } return low; } } int main() { int n,i; cin >> n; int a[n]; for(i=0;i<n;i++) { cin >> a[i]; } int x; cin >> x; cout << Search_Bin(a, n, x); return 0; }
基本格式:
while (left <= right)
{//必须是等号
mid = (left + right) / 2;
if (key ? arr[mid]) right = mid - 1;
else left = mid + 1;
return ?;
}
根据要求的值的位置,先确定比较符号,再确定返回值
比较符号:小于,大于等于:>=;小于等于,大于:>
返回值:要比较的值在key左边,返回right;要比较的值在key右边,返回left;
先进行right=mid-1;和先进行left = mid + 1;在规律上有差别(体现在找与key相等的两种情况中)
第八章:排序
作业练习题
判断选择填空
- 要从50个键值中找出最大的3个值,选择排序比堆排序快。(T)
规模较小直接选择排序快;
- 对一组数据{ 2,12,16,88,5,10 }进行排序,若前三趟排序结果如下: 第一趟排序结果:2,12,16,5,10,88 第二趟排序结果:2,12,5,10,16,88 第三趟排序结果:2,5,10,12,16,88 则采用的排序方法可能是:冒泡排序
- 哪种算法可能出现:在最后一趟开始之前,所有的元素都不在其最终的位置上?(设待排元素个数N>2):插入排序
- 就排序算法所用的辅助空间而言,堆排序、快速排序、归并排序的关系是:堆排序 < 快速排序 < 归并排序
- 下列排序算法中,时间复杂度不受数据初始状态影响,恒为O(NlogN)的是:堆排序
- 排序方法中,从未排序序列中依次取出元素与已排序序列中的元素进行比较,将其放入已排序序列的正确位置的方法称为:插入排序
- 有组记录的排序码为{ 46,79,56,38,40,84 },则利用堆排序的方法建立的初始堆为:84,79,56,38,40,46
- 输入10^4个只有一位数字的整数,可以用O(N)复杂度将其排序的算法是:桶排序
- 对10TB的数据文件进行排序,应使用的方法是:归并排序
- 下列排序算法中,在每一趟都能选出一个元素放到其最终位置上,并且其时间性能受数据初始特性影响的是:快速排序
代码实战
-
统计工龄 (30分)
给定公司N名员工的工龄,要求按工龄增序输出每个工龄段有多少员工。
输入格式:
输入首先给出正整数N(≤10^5),即员工总人数;随后给出N个整数,即每个员工的工龄,范围在[0, 50]。
输出格式:
按工龄的递增顺序输出每个工龄的员工个数,格式为:“工龄:人数”。每项占一行。如果人数为0则不输出该项。
输入样例:8 10 2 0 5 7 2 5 2输出样例:
0:1 2:3 5:2 7:1 10:1代码实现
#include <iostream> //桶排序 using namespace std; int main() { int n,x; cin >> n; int count[51] = { 0 }; for (int i = 0; i < n; i++) { cin >> x; count[x]++; } for (int i = 0; i < 51; i++) if (count[i]) cout << i << ":" << count[i] << endl; return 0; } -
PAT排名汇总 (30分)
计算机程序设计能力考试(Programming Ability Test,简称PAT)旨在通过统一组织的在线考试及自动评测方法客观地评判考生的算法设计与程序设计实现能力,科学的评价计算机程序设计人才,为企业选拔人才提供参考标准(网址http://www.patest.cn)。
每次考试会在若干个不同的考点同时举行,每个考点用局域网,产生本考点的成绩。考试结束后,各个考点的成绩将即刻汇总成一张总的排名表。
现在就请你写一个程序自动归并各个考点的成绩并生成总排名表。
输入格式:
输入的第一行给出一个正整数N(≤100),代表考点总数。随后给出N个考点的成绩,格式为:首先一行给出正整数K(≤300),代表该考点的考生总数;随后K行,每行给出1个考生的信息,包括考号(由13位整数字组成)和得分(为[0,100]区间内的整数),中间用空格分隔。
输出格式:
首先在第一行里输出考生总数。随后输出汇总的排名表,每个考生的信息占一行,顺序为:考号、最终排名、考点编号、在该考点的排名。其中考点按输入给出的顺序从1到N编号。考生的输出须按最终排名的非递减顺序输出,获得相同分数的考生应有相同名次,并按考号的递增顺序输出。输入样例:
2 5 1234567890001 95 1234567890005 100 1234567890003 95 1234567890002 77 1234567890004 85 4 1234567890013 65 1234567890011 25 1234567890014 100 1234567890012 85输出样例:
9 1234567890005 1 1 1 1234567890014 1 2 1 1234567890001 3 1 2 1234567890003 3 1 2 1234567890004 5 1 4 1234567890012 5 2 2 1234567890002 7 1 5 1234567890013 8 2 3 1234567890011 9 2 4代码实现
#include <iostream> #include <cstring> #include <algorithm> using namespace std; struct student { string id; //考号 int score; //分数 int position; //考点 int rank; // 所在考点排名 int total_rank; //总排名 }stu[30010]; int compare(student a, student b) { if(a.score==b.score) { return a.id<b.id; } return a.score>b.score; } int main() { int N, K; int num=0; cin >> N; for(int i=0;i<N;i++) { cin >> K; for(int j=num;j<num+K;j++) { cin >> stu[j].id >> stu[j].score; stu[j].position = i+1; } sort(stu+num,stu+num+K,compare); //同一考场排序 int rank = 1; stu[num].rank = rank; //组中第一人排名为1 for(int t=num+1;t<K+num;t++) //确定组中排名 { rank++; if(stu[t].score==stu[t-1].score) //同分并列 { stu[t].rank = stu[t-1].rank; } else { stu[t].rank = rank; //排名+1 } } num = num+K; //更新stu长度 } sort(stu,stu+num,compare);//全部考生排序 int rank=1; stu[0].total_rank = rank; for(int i=1;i<num;i++) { rank++; if(stu[i].score ==stu[i-1].score) { stu[i].total_rank = stu[i-1].total_rank; } else { stu[i].total_rank = rank; } } cout << num << endl; for(int i=0;i<num;i++) { cout << stu[i].id << " " << stu[i].total_rank << " " << stu[i].position << " " << stu[i].rank << endl; } return 0; }
主观题练习
-
邻接表的应用场合 (20分)
问答题:使用邻接表存储无向图,为什么要足够稀疏才合算? -
邻接矩阵的边 (20分)
问答题:使用邻接矩阵存储无向图,如何查看i号顶点和j号顶点之间是否存在边? -
二叉树先序遍历 (40分)
若采用以下的图示方式存储二叉树,请写出相应的类型定义,并写出基于你的类型定义的二叉树先序遍历算法。
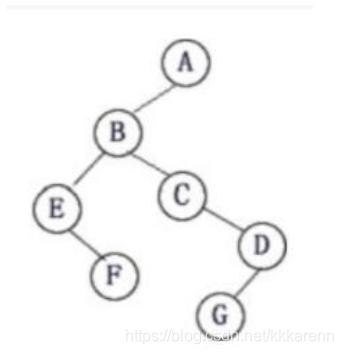
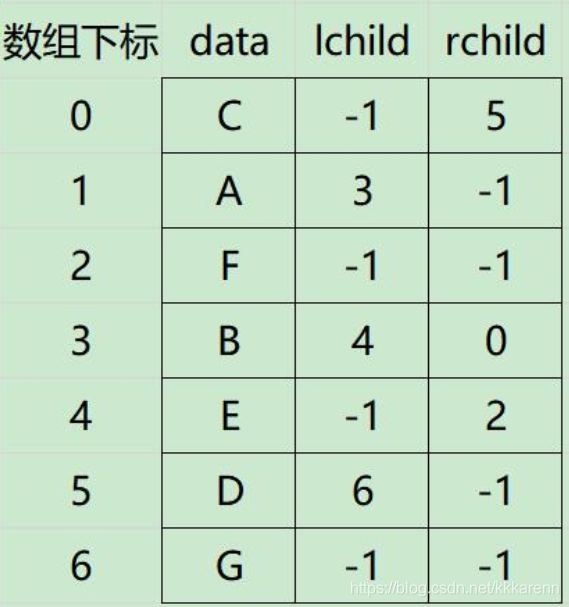
-
邻接表的度 (5分)
问答题:使用邻接表存储有向图,如何求指定顶点的度? -
邻接矩阵的边2 (5分)
问答题:使用邻接矩阵a存储无向网络,若i号顶点与j号顶点之间不存在边,则a[i][j]值为多少,你是怎么分析的? -
二叉树的中序遍历 (40分)(图片同第3题)
若采用以下的图示方式存储二叉树,请: (1)写出相应的类型定义。 (2)写出基于你的类型定义的二叉树中序遍历算法。 (3)写出调用函数的语句。 -
连通与非连通1 (20分)
-
对于连通图,其连通分量是什么?
-
如果从无向图的任一顶点出发进行一次深度优先搜索可访问所有顶点,则该图一定是
-
如果从无向图的任一顶点出发进行一次广度优先搜索可访问所有顶点,则该图一定是
- 设有以下算法定义:
void DFS_AM(AMGraph G, int v)
{ //图G为邻接矩阵类型
cout << v << " "; //访问第v个顶点
visited[v] = true;
for(w=0; w<G.vexnum; w++) //依次检查邻接矩阵v所在的行
if((G.arcs[v][w]!=0)&& (!visited[w]))
DFS_AM(G, w); //w是v的邻接点,如果w未访问,则递归调用DFS_AM
}
void DFSTraverse(Graph G)
{ // 对图 G 作深度优先遍历
for(v=0; v<G.vexnum; ++v)
visited[v] = FALSE; //访问标志数组初始化
for (v=G.vexnum-1; v>=0; --v)
if (!visited[v]) DFS(G, v); //对尚未访问的顶点调用DFS
}
假设图G中arcs数组内容如下:
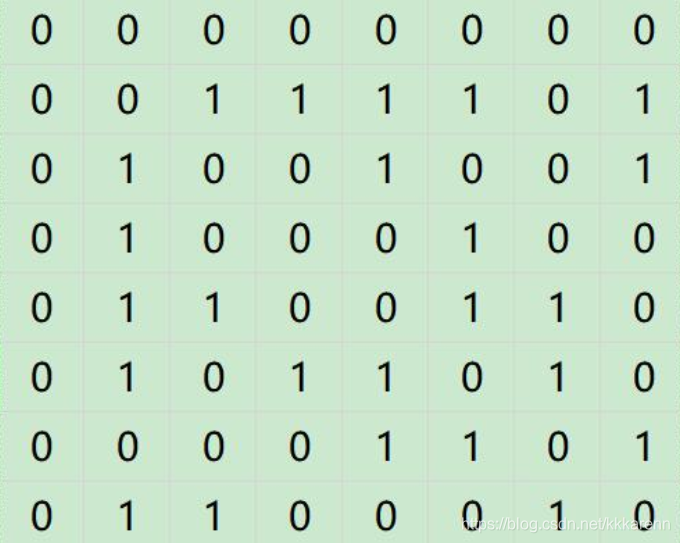
写出 DFSTraverse(G) 的运行过程和输出结果。
- 同上一题
代码为:
void DFS_AM(AMGraph G, int v)
{ //图G为邻接矩阵类型
cout << v << " "; //访问第v个顶点
visited[v] = true;
for(w=G.vexnum-1; w>0; w--) //依次检查邻接矩阵v所在的行
if((G.arcs[v][w]!=0)&& (!visited[w]))
DFS_AM(G, w); //w是v的邻接点,如果w未访问,则递归调用DFS_AM
}
void DFSTraverse(Graph G)
{ // 对图 G 作深度优先遍历
for(v=0; v<G.vexnum; ++v)
visited[v] = FALSE; //访问标志数组初始化
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) DFS(G, v); //对尚未访问的顶点调用DFS
}
-
两个顶点间是否有边 (20分)
写出算法,判别以邻接表方式存储的有向图G中是否存在由顶点vi到顶点vj的边(i!=j) -
哈希表的构造与查找 (25分)
设有一组关键字:(10,16,32,17,31,30,20),哈希函数为:H(key) =key MOD 11,表长为12,线性探测法处理冲突。试回答下列问题: 1、画出哈希表的示意图; 2、若查找关键字20,需要依次与哪些关键字进行比较? 3、若查找关键字27,需要依次与哪些关键字比较? 4、假定每个关键字的查找概率相等,求查找成功时的平均查找长度。 5、求装填因子。 -
普里姆-最小生成树 (10分)
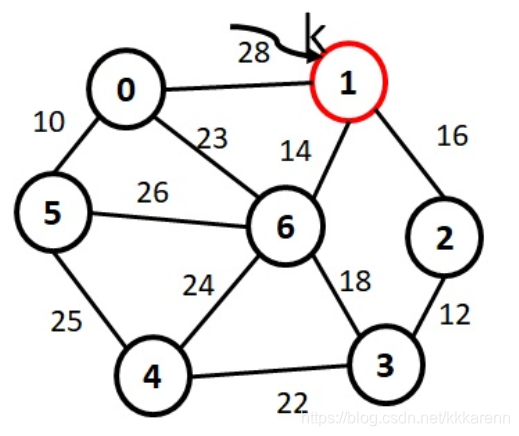
对下图,写出以普里姆算法,从顶点,1为起点,构建最小生成树的顶点序列和边的序列
-
根据邻接表写出图的广度优先遍历序列 (10分)
(1)写出下图的邻接表(边结点序号从小到大), (2)写出从顶点3出发的广度优先搜索序列和深度优先搜索序列,顶点之间用空格隔开。约定以结点小编号优先次序访问。

-
二叉排序树的构建 (5分)
在一个空的二叉排序树中依次插入关键字序列为12,7,17,11,16,2,13,9,21,4,请画出所得到的二叉排序树。 -
二分查找 (5分)
已知如下11个元素的有序表(8,16,19,23,39,52,63,77,81,88,90),画出其二分查找的判定树,给出查找元素88和17的折半查找过程。 -
堆排序的初始堆 (6分)
若一组记录的关键码为(46,79,56,38,40,84),请写出利用堆排序的方法建立的初始堆。请写详细过程(3分)和结果(3分) -
哈夫曼树的构建 (9分)
假设用于通信的电文仅由8个字母组成,字母在电文中出现的频率分别为0.09,0.16,0.02,0.06,0.32,0.03,0.21,0.11。(1)试为这8个字母设计哈夫曼编码,请写出哈夫曼树的构建详细过程和编码;
(2) 设计另一种由二进制表示的等长编码方案;
(3) 对于上述实例,分析两种方案的编码长度,分析两种方案的优缺点














 5180
5180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









