







一.实验目的
掌握JPEG编解码系统的基本原理。初步掌握复杂的数据压缩算法实现,并能根据理论分析需要实现所对应数据的输出。
二.实验原理和过程
JPEG编码框架解析

Level offset:零偏置电平下移,JPEG使用YUV方式,所以格式要先变成YUV,然后将灰度级是2^n的图像,通过减去2^(n-1),这样做就让无符号数变为有符号的了。对于256灰度级的来说,就从0~256变成-128~127了。这样做减少了像素的绝对值
同时。也要进行一定的采样,常见的有4:2:2;4:4:4;4:2:0。
8*8DCT:把图像变成8*8的块,进行DCT变换量化熵编码时,单位是每一个块,这样做的目的实现能量集中和去相关,便于去除空间冗余,提高编码效率。
通过DCT变换,8×8个灰度值被转换为8×8个频率谱值,分别对应不同频率。DCT变换系数值均为实数。低频谱值位于左上部分,高频谱值位于右下部分。通过下述公式可知,左上角F(0,0)对应频率为0,被称为DC系数,其他63个系数称为AC系数。
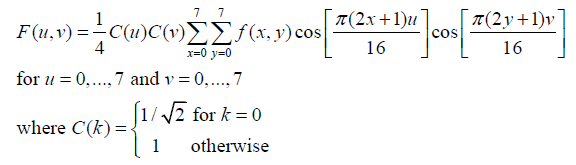
Uniform scalar quantization:均匀量化。量化是一个幅值离散的过程。人眼对亮度信号比对色差信号更敏感,因此使用了两种量化表:亮度量化值和色差量化值。大多数图像的高频分量较小,相应于图像高频分量的系数经常为零,加上人眼对高频成分的失真不太敏感,所以可用更粗的量化。对低频分量采取较细的量化。
熵编码:
1AC quantization indices(AC系数编码)
把8×8的系数矩阵转化为1×64的一维数据,而且采用的方式为Zig-Zag扫描法,采用Z字型的好处是可以把低频系数和高频系数分别集中在一起,而随着频率的增加,高频系数基本上都是0,方便采用0行程编码从而压缩数据。
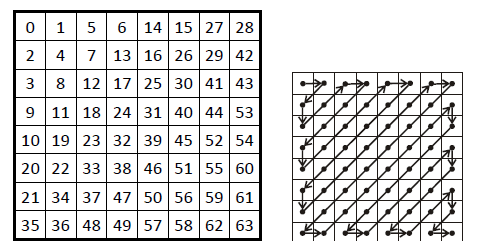
采用Zig-Zag扫描后,高频成分被量化为0,而且基本集中在一起,可以对AC系数采用游程编码,即记录此数值前的连续数值0的个数。下面是个对AC系数压缩的例子。

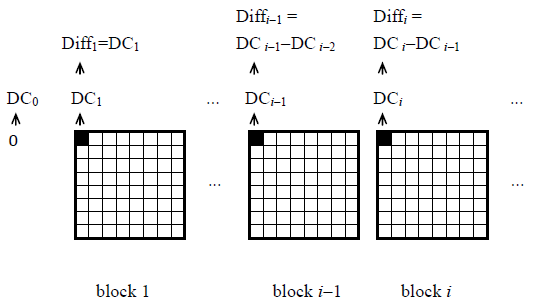
2.DC quantization indices(DC 系数编码)
由于DC系数是整个8×8块的均值,所以相邻块的DC系数有很大的相关性,同时DC系数通常比AC系数要大得多,JPEG标准对DC系数采用相邻DC差分(DPCM),通常Diff具有很小的数值,然后进行Huffman编码。如下图所示(第一个块的DC定义为0)。
JPEG文件格式分析
| 名称 | 标记固定值 | 具体字段 |
| SOI 图像开始 |
0xFFD8 | |
| APP0 应用程序保留标记0 |
0xFFE0 | 包含9个具体字段 ① 数据长度 2字节 ①~⑨9个字段的总长度即不包括标记代码,但包括本字段 字段⑦“缩略图水平像素数目”和字段⑧“缩略图垂直像素数目”的值均为0。 |
| APPn 应用程序保留标记n,其中n=1~15(任选) |
0xFFE1~0xFFF | 包含2个具体字段 ① 数据长度 2字节 ①~②2个字段的总长度 |
| DQT 定义量化表 |
0xFFDB | 包含9个具体字段 ① 数据长度 2字节 字段①和多个字段②的总长度,即不包括标记代码,但包括本字段 精度及量化表ID 1字节 高4位: 精度,只有两个可选值 0:8位;1:16位 表项 (64×(精度+1))字节 例如8位精度的量化表, 其表项长度为64×(0+1)=64字节 本标记段中,字段②可以重复出现,表示多个量化表,但最多只能出现4次。 |
| SOF0 帧图像开始 |
0xFFC0 | ① 数据长度 2字节 ①~⑥六个字段的总长度,即不包括标记代码,但包括本字段 a) 颜色分量ID 1字节 b) 水平/垂直采样因子 1字节 高4位:水平采样因子 c) 量化表 1字节 当前分量使用的量化表的ID 本标记段中,字段⑥应该重复出现,有多少个颜色分量(字段⑤),就出现多少次(一般为3次)。 |
| DHT 定义哈夫曼表 |
0xFFC4包含2个具体字段 | 包含2个具体字段 ①数据长度 2字节 字段①和多个字段②的总长度,即不包括标记代码,但包括本字段 a) 表ID和表类型 1字节 高4位:类型,只有两个值可选 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









