







 学习stanford的cs224d–deep learning for natural language processing, 顺便记录一下学习word2vec重要的知识点. word2vec 最先出现在谷歌工程师Mikolov在2013年的NIPS会议发表的一篇文章. 相比与传统的自然语言处理, 其优点是利用向量空间使词的表达更加方便, 并且在惯用词组的表达上更加powerful.
学习stanford的cs224d–deep learning for natural language processing, 顺便记录一下学习word2vec重要的知识点. word2vec 最先出现在谷歌工程师Mikolov在2013年的NIPS会议发表的一篇文章. 相比与传统的自然语言处理, 其优点是利用向量空间使词的表达更加方便, 并且在惯用词组的表达上更加powerful.
最近在学习stanford的cs224d–deep learning for natural language processing, 顺便记录一下学习word2vec重要的知识点. word2vec 最先出现在谷歌工程师Mikolov在2013年的NIPS会议发表的一篇文章. 相比与传统的自然语言处理, 其优点是利用向量空间使词的表达更加方便, 并且在惯用词组的表达上更加powerful.
词向量基础
首先看最简单的one-hot vector , 假设词库的容量是 V , 那么每一个词都是一个
首先考虑如何表达词, 采用矩阵的方法通常有两种, 一种是Word-Document Matrix, 另外一种是Window besed Co-occurrence Matrix, 我们只讨论第二种, 因为第一种的矩阵太大, 计算量太大.
Window based Co-occurrence Matrix
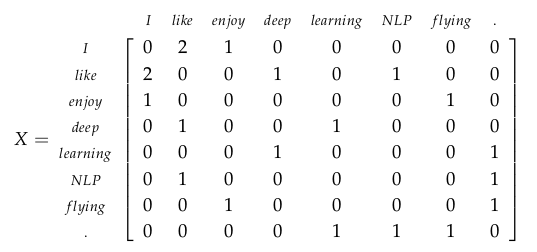
首先, 这种方法是基于语料库中的每个句子进行操作的, 然后设定一个窗的长度, 在中心词的左边右边都加窗, 计算窗中的词伴随中心词出现的频数, 构造一个矩阵. 以一个例子为例:窗为1, 句子个数为3- I enjoy flying
- I like NLP
- I like deep learning
因此, 这个矩阵表达为
可以发现, like 和 enjoy的相关性明显就高于I 和 like. 这样的矩阵还是太稀疏, 下面采用 SVD 的方法进行降维.
SVD(singular value decomposition)
根据线性代数的理论, 一个方阵可以做如下分解:
Amn=UmmSmnVTnn
其中, Umm , Vnn 分别是 AAT 和 ATA 的正交特征向量构成的正交矩阵, Smn 是一个对角元素是 U,V 矩阵的特征值平方根按从小到大排列的对标矩阵. 最终我们取U作为降维后的矩阵. 一个简单的可视化如图.
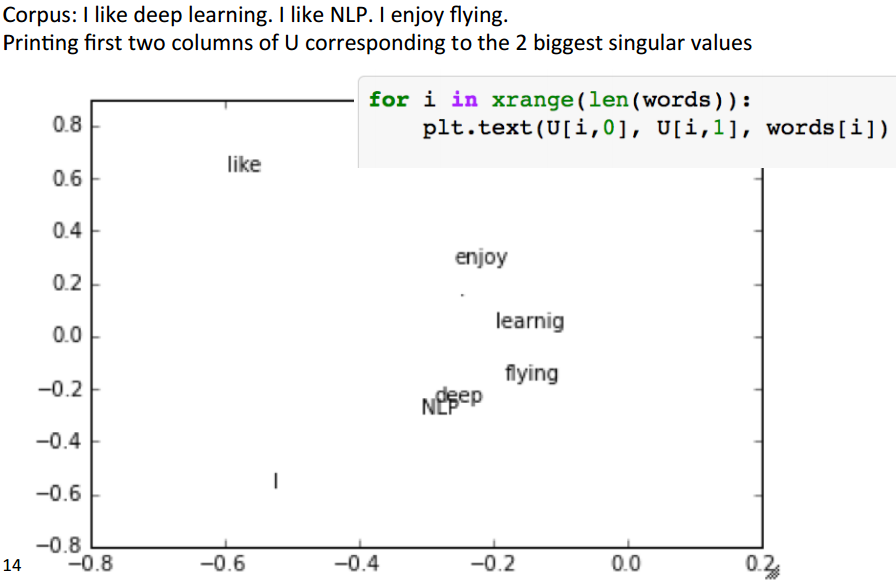
当然,语料库太小,这张图还不是很能够说明问题.
目前为止, 基于SVD的方法有如下的缺点:
1. 新词加入的时候矩阵的维度要改变
2. 矩阵过于稀疏, 因为大多数词是不相关的
3. 矩阵维度过大 (≈106×106)
4. 训练时间过长, o(n2)
5. 需要一些技巧来解决词频的不均衡性
下面,采用基于迭代(Iteration besed)的方法来解决以上问题.
Iteration Based Methods
- Language Models(Unigrams, Bigrams, etc.)
首先, 构造一个模型来衡量一个序列(句子)出现的概率. 如The cat jumped over the puddle. 显然,这个句子语法语义都是正确的. 数学上来说, 一个由 n 个词组成的序列的概率是P(w1,w2,...,wn) .
- 一元模型 Unigram model
P(w1,w2,...,wn)=∏i=1nP(wi)
显然, 它假设了所有词的出现概率都是彼此独立的,因此当我们把一些词频较高的词组合在一起构成一个愚蠢的句子的时候, 它出现的概率仍然很高. - 二元模型 Bigram model
P(w1,w2,...,wn)=∏i=1nP(wi|wi−1)
实际上, 词与词之间存在相关性, 下一时刻的词极有可能依赖于上一时刻的词. - 词向量 word2vec
二元模型只考虑了局部的相关性, 并且需要计算/存储一个大的数据库的全部信息. 于是word2vec出现了. word2vec的主要思想是不直接计算词与词之间的相关性, 而是通过计算每个词周围包围的词(surrounding words)来得到词向量.
P(o|c)=exp(uTovc)∑Ww=1exp(uTwvc)
其中, c是中心词, o 是输出词, u和v分别代表输出和输入向量.(注意:一个词作为中心词和非中心词表示的向量是不一样的.)
通过极大似然估计的方法来训练得到词向量, 目标函数
J(θ)=1T∑t=1T∑−m≤j≤m,j≠0logP(o|c) - Glove(#TODO: 待补充)
J(θ)=12∑i,j=1Wf(Pij)(uTivj−logPij)2
- 一元模型 Unigram model
下面讲两个word2vec的模型
Continuous Bag of Words Model(CBOW)
简而言之,就是已知通过周围的词来预测中心词.主要元素是输入矩阵和输出矩阵.计算过程如下- generate input context of size m: (xc−m,...,xc−1,xc+1,...,xc+m)
- get embedded word vectors: (vc−m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









