







Introduction
Convolution neural network has gain its popularity recently due to its power with computer vision. Although CNNs have been used as early as the nineties to solve character recognition tasks (Le Cun et al., 1997), their current widespread application is due to much more recent work, when a deep CNN was used to beat state-of-the-art in the ImageNet image classification challenge(Krizhevsky et al., 2012).
Difference from multi-layer conception
A convolutional layer’s output shape is affected by the shape of its input as well as the choice of kernel shape, zero padding and strides.
CNNs also usually feature a pooling stage
- transposed convolutional layers (also known as fractionally strided convolutional layers) have been employed in more and more work as of late
Discrete convolutions
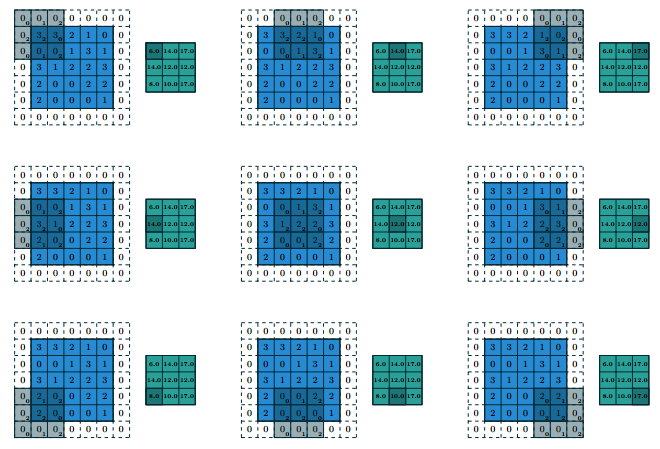
Features
stored as multi-dimensional arrays.
feature one or more axes for which ordering matters (e.g., width and height axes for an image, time axis for a sound clip).
One axis, called the channel axis, is used to access different views of the data.
sparse (only a few input units contribute to a given output unit) and reuses parameters (the same weights are applied to multiple locations in the input).
denotations
- ij : input size along axis j ,
kj : kernel size along axis j ,sj : stride (distance between two consecutive positions of the kernel) along axis j ,pj : zero padding (number of zeros concatenated at the beginning and at the end of an axis) along axis j .
Pooling
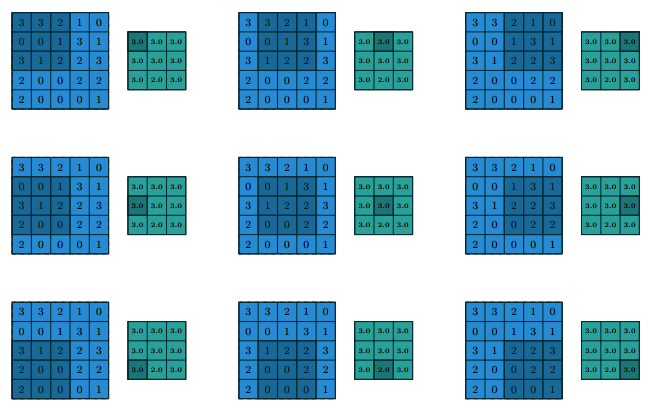
Pooling operations reduce the size of feature maps by using some function to summarize subregions, such as taking the average or the maximum value.
- difference from discrete convolution:
replaces the linear combination described by the
kernel with some other function.
denotations
ij : input size along axis j,- kj : pooling window size along axis j,
- sj : stride (distance between two consecutive positions of the pooling window) along axis j.
Convolution arithmetic
The discussion are based but not limited to the following c
onstraints:
- 2-D discrete convolutions ( N=2 ),
- square inputs ( i1=i2=i ),
- square kernel size ( k1=k2=k ),
- same strides along both axes ( s1=s2=s ),
- same zero padding along both axes ( p1=p2=p ).
No zero padding, unit strides

Relationship: o=(i−k)+1
Zero padding, unit strides
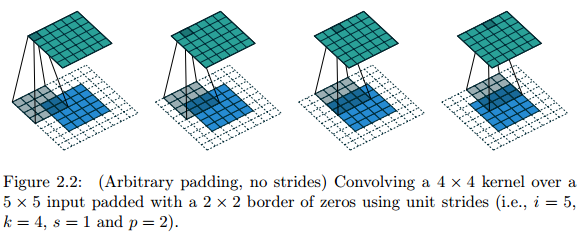
Relationship: o=(i−k)+2p+1
Half(same) padding
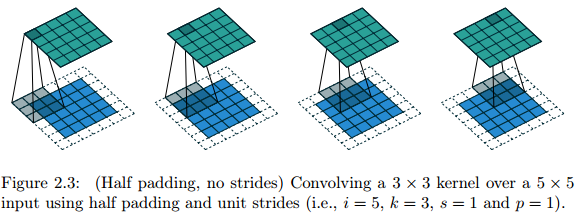
Sometimes, we just want the output size to be the same as the input size.
Relationship: For any
i
and for
Full padding
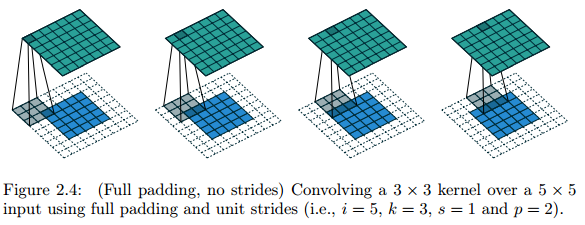
Sometimes, we just want to take every possible partial or complete superimposition of the kernel on the input feature map into consideration.
Relationship: For any
i
and
k
, and for
No zero padding, non-unit strides
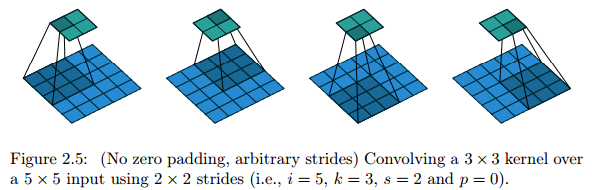
Move with strides.
Relationship: For any
i,k
and
s
, and for
Zero padding, non-unit strides
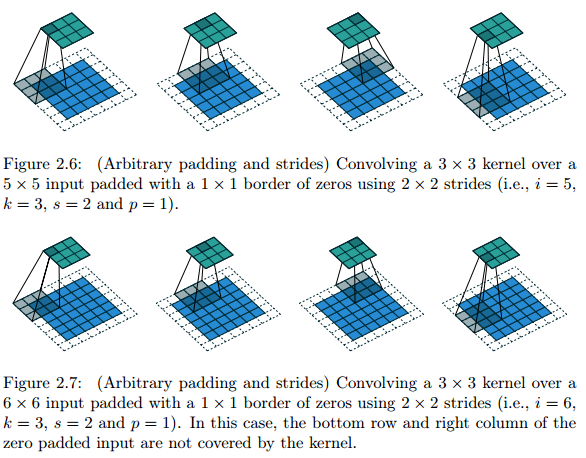
With strides, some regions may not be covered by the kernel.
Relationship:
Pooling arithmetic
Pooling does not consider padding, so its output size is simple and the relationship will hold for any type of pooling.
Relationship:
Transposed convolution arithmetic
Intuition: Arises form the desire of transformation from something that has the shape of the output of some convolution to something that has the shape of its input.
Usage: as decoding layer of a convolutional autoencoder or to project feature maps to a higher-dimensional space.
It has some similarities with direct convolution but some arithmetic changes!















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









