







对接第三方系统实操经验分享
前言
为使得指示性更强,有以下名词说明
- A系统:是指要发起对接的我方系统,可以理解成
Client - B系统:是要对接的第三方系统,可以理解成
Server
对接第三方的特殊性
- 请求方式不同。比较老的系统有可能使用
webservice接受参数,比较人性化的系统会使用http + json方式接受参数 - 登录方式不同。有些系统压根就不需要登录,有些系统通过 token登录,有些系统通过 cookie 登录
- 字段名不同。除非双方共同开发,否则字段名不一致的概率几乎为 100%
- 基础资料不同。就算是同一个供应商,在A系统的唯一id 为 333,在B系统的唯一id 为 supplier301,这才是棘手之处
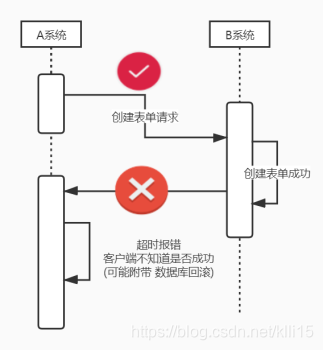
- 网络请求不可靠,数据一致性(事务)无法保证。对接过程中,你想实现分布式事务的可能性基本为0,因为你基本没有可能能使得对面的数据库按照你的意愿 回滚。示例如下图:
对接框架必备功能
- 字段名转换工具类
- 字段值转换机制
- 重试机制
- 系统数据一致性(幂等)机制
- 完整的日志机制
必备功能实现参考方案
字段名转换工具类
方案一:使用注解建立字段关联关系
- 例子:
@ErpDataField(name = "FSaler", dataType = ErpBaseInfoTypeEnum.Employee,keyName = "FSTAFFNUMBER")
private Integer fsaleAid;
@ErpDataField(name = "F_PAEZ_Text4")
private String fsoNumber;
- 解释
- 类似
fastjson的@JSONField注解一样,对字段进行重命名,根据目标系统的字段名进行关联 - 在重命名的同时,亦可以对字段值的类型进行标记,为字段值转换机制打上标记
- 可以按照对接框架的需要附上所需要的属性,比如说 字段是否需要强转成数字形式,单位是多少,保留多少位小数等属性,也是为了字段值转换机制打基础
- 优点:
- 注解写在字段上,清晰易懂,维护直接在代码中
- 反射也更好获取——工具类更好写
- 缺点:
- 由于字段之间的映射关系已经以 注解的形式 硬编码写在了代码里,想要 修改就必须重构代码,而重构往往对于 生产环境是不可容忍的
- 有可能污染了代码,尤其是 pojo(可以通过 新建一个vo类专门用于对接)
- 参考代码片段:一个详细的注解
方案二:使用数据库建立字段关联关系
其实也就是将注解的内容 放进数据库里进行维护,通过如前端填写注解表格进行 对接交互,可实时增删改,更为灵活
- 优点:
- 灵活,不使用硬编码
- 如果不涉及值转换机制的新增,基本可以实现 不用写任何代码,不用重构代码,即可新对接一张表单。
- 缺点
- 反射工具类书写难度加大:需要考虑到 字符串的拼写、合法性以及嵌套字段名解析等问题
- 参考代码:a2b对接脚手架项目
字段值转换方案
我们知道 A系统中供应商id 为 333 的供应商 = B系统中 供应商唯一主键 为 S303 的供应商,我们需要在值转换阶段,将其转换成 B系统能够接受的值
建议实现步骤
- 在字段名转换阶段,给字段打上 值转换类型属性(如上述注解中的
dataType属性) - 维护值转换 策略模式集合,各种转换策略实现同一个接口
public interface ErpBaseInfoHandler {
String handleField(ErpJsonField jsonField,String extInfo);
}
public enum ErpBaseInfoTypeEnumAdmin{
None(0,"不是基本信息", NotBaseInfoHandler.class),
Channel(1,"渠道客户", ChannelBaseInfoHandler.class),
XyCompany(2,"公司主体Id", XyCompanyBaseInfoHandler.class),
Employee(3,"员工faid", EmployeeBaseInfoHandler.class),
Currency(4,"币种", CurrencyBaseInfoHandler.class),
//....
}
- 在值转换阶段,根据值转换类型进入对应的转换策略中
转换策略推荐实现方案——以员工信息为例
- 输入的参数含有
需要转换的A系统的员工id值 : A23,要转换成 B系统的值 为B100567- 以下 值映射关系 是指 A系统的值 => B系统的值,如A系统员工id A23 => B系统 的 B100567
值映射关系不稳定
也就是说
A23 => B100567在某时刻是成立的,但是之后又不成立了
此种情况只能通过 B系统开发转换接口,然后A系统每次转换值时 调用接口 实时查询对应的值
值映射关系稳定
- 根据员工id查找数据库,如果可以找到映射关系则立即返回
- 根据B系统提供的查询接口(如果有),则根据一定的筛选条件获取对应的B系统的值(如根据员工工号 查询B系统的员工id),如果查询成功,则保存映射关系保存在数据库中(以便再次查询),然后立即返回
- 如果还不行,则根据B系统提供的新增表单接口(如果有),则以A系统的员工 在B系统创建 该员工的信息,一般创建成功 B系统 会返回能唯一确定这个员工的 B系统id,此时也将映射关系保存到数据库中,然后返回
- 否则,则报错,手动处理
public class EmployeeBaseInfoHandler implements ErpBaseInfoHandler{
@Override
public String handleField(ErpJsonField jsonField,String extInfo){
//在数据库中查询
String dbFnumber = this.searchInDb(jsonField);
if (!StringUtils.isEmpty(dbFnumber)) {
return dbFnumber;
}
String fname = this.getFname(jsonField);
//在第三方系统,如 erp 中查询
String fnumberByName = this.searchInErpByFname(jsonField, fname);
if (!StringUtils.isEmpty(fnumberByName)){
return fnumberByName;
}
//使用现有的员工信息,保存至第三方系统
String fnumber = saveToGetFnumber(jsonField, fname);
return fnumber;
}
}
重试机制
前文我们提到过 任何一个网络请求 都可能出现 失败情况,因此我们必须要考虑加入重试功能
建议实现方案
-
推送服务接收到 数据后,立即将能唯一确定数据的 信息保存在数据库,然后将 原始数据 临时缓存在 Redis等缓存容器
保存在数据库的信息,必须能保证足够可以用从 缓存容器 中重新取出 原始数据
-
最后再进行 值转换、发送网络请求等操作
-
所有操作成功后,将缓存删除;否则,延长 缓存时间
记得缓存时间 要大于 预期下一次定时任务处理时间,否则还没等到 定时任务来处理自己,缓存的数据就没了
触发机制
定时任务触发
设置原因
- 解决由于非数据错误导致的失败,如网络波动
- 减少人工处理的压力
注意事项
- 设置最大失败次数、缓存超时机制,以便淘汰由于数据错误导致的对接失败
- 设置每次最大处理量,保证不会使得 A系统的服务压力猛增 ,同时 B系统也不一定能够同时处理那么多内容
人工立即触发
设置原因
- 肯定有等不到定时任务,紧急需要重试 的需求
- 方便测试
注意事项
- 不需要跟定时任务一样处理多条任务,往往用户只需要 紧急处理 少量的单据
源头手动触发
设置原因
- 方便测试
- 缓存已经超时,需要重新提交数据
- 数据源有可能已经修改了——尤其在 由于数据错误导致失败时,更需要使用
注意事项
- 源头重新发起后,如果旧数据仍留在 缓存中,应该用新数据覆盖
- 源头重新发起后,旧数据对接产生的日志记录不应该被抹去,应该被保留下来,以便追踪问题
系统数据一致性(幂等)机制实现
但是如果重试,有可能就会出现以下情况
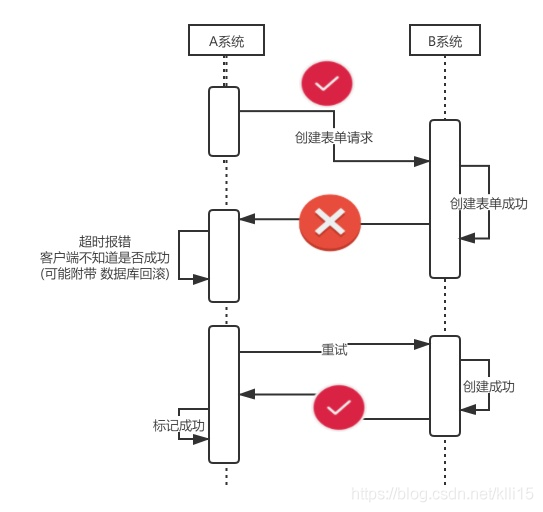
问题分析
为什么会出现上图的结果?关键在于 A系统在请求失败后无法判断请求是否成功了
想一下,如果你是B系统的设计者,你要怎样才能让 A系统 知道是否成功了呢?
幂等机制支持关键点
举例
幂等机制需要 B系统来支持,什么样的系统才能支持幂等机制?我以 金蝶K3Cloud ERP 中销售订单表单(下称 SO单)举例,以下是简介:
- so单中的订单号(字段名:
FbillNo) 是唯一的,支持创建的时候自定义订单号(关键1),如不自定义则自动生成 - 除此之外,每一张创建的单据有另外一个唯一的自增id,称为
FerpId吧 - erp提供了查询接口,可以根据 订单号 查询 表单信息,包括
FerpId(关键2)
关键点分析: 存在一个字段,可以在创建阶段指定值并且可以据此值查询到表单是否存在
如果提供以上的条件,就可以实现幂等机制:因为你可以根据上次请求预期结果,来查询上次预期结果是否成功。
可以在创建阶段指定值 的字段
问:这种字段非常多,能传值的字段都是可以指定值的字段,是否需要挑选值做了唯一索引的呢?
答:有更好,没有也可以。为什么呢?因为此值是 A系统自己控制的,A系统在传值时完全可以构造一个全局唯一的 值,比如加入时间戳、全局id生成器之类的。
再问:如果我选的 K 字段没有唯一索引,A系统传的值为 :k123-20200613,此时保存成功了但A系统没有收到结果,超时失败了;但是B系统的前端用户想搞事情,也创建了一张 K 字段为 k123-20200613,保存成功了。后来A系统重试时,查询时发现了两张单,不知道哪张单是它推送过去的了,这怎么办?
再答:这就是为啥说 有唯一索引更好 的原因。个人觉得程序无法解决,只能人工来处理,揪出这个”捣蛋鬼”了。
可以据指定值查询到单据是否存在 的字段
这个是幂等机制的基础!因为没有 这个字段或者查询接口不支持 ,则无法在重试前查询 上一次推送的结果是否成功了
实现示例
- A系统在每次重试so单推送erp前,需要根据 so单号 去查询此 so单是否存在于erp
- 如果存在,则将
FerpId存入数据库,并标记为已成功 - 如果没有查询成功(网络又失败了),则放弃重试
- 如果查询结果说明不存在,则重新推送
注意事项
- 不是所有第三方系统都符合实现幂等机制的条件,也不是所有的 A系统都有实现幂等机制的需求,如发送邮件、短信——多一条感觉也没什么关系(反正都是垃圾邮件/邮箱)
完整的日志机制
推送日志
推送日志是 事后定位bug 重要内容,最好不要只停留在日志文件中,数据库中应该也保留最近一次的错误原因等重要信息
日志基本元素
- 推送时间
- 错误原因
- 推送人(如果有)
- 推送数据(如果是json就得打印,webservice 就算了吧)
日志打印时间点
- 构造数据前:开始构造数据了
- 网络请求前:请求参数
- 网络请求后:请求结果,catch 超时异常
日志打印原则
- 重要操作
- 易错操作
- 反映程序执行链路,也就是可追踪
回调日志
如果B系统会在某个时间回调 A系统的某些接口,一定要打印接收到的原始数据,因为这是 追责的重要依据。















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









