







 本文介绍了马尔科夫决策过程(MDP)的基本概念,包括状态、动作、转移概率、折扣因子和奖励函数。通过值迭代和政策迭代两种方法解释了如何求解MDP,并探讨了在模型未知时如何学习MDP的模型。强化学习的目标是最大化全局回报,MDP是解决这类问题的重要工具。
本文介绍了马尔科夫决策过程(MDP)的基本概念,包括状态、动作、转移概率、折扣因子和奖励函数。通过值迭代和政策迭代两种方法解释了如何求解MDP,并探讨了在模型未知时如何学习MDP的模型。强化学习的目标是最大化全局回报,MDP是解决这类问题的重要工具。
在之前的教程中,我们首先学习了监督学习,如logistic方程、支持向量机的方法,又学习了无监督学习,如聚类等算法。从本讲开始,我们将进入强化学习课程的学习,我们首先将接触的是马尔科夫决策过程。
马尔科夫决策过程 Markov Decision Process MDP
一个马尔科夫决策过程常由一个五元组tuple描述,为(S,A,{Psa},γ,R),各元素意义如下:
·S为状态States的集合,如在直升机控制问题中,S可用来描述直升机的位置、方向等状态;
·A为动作Actions的集合,如用来描述直升机所有可行的运行方向;
·{Psa}为转移概率矩阵,表示在状态s的情况下,如果进行动作a,转移到下一状态的概率;
·γ是一个大于等于0,小于1的值,称为折扣因子Discount Factor;
·R是一个由状态和动作到实数的映射,称为奖励方程Reward Function。
一个典型的马尔科夫动态决策过程为:我们由状态集S中的一个状态s0初始,选择动作集A中的一个动作a0,此时,下一状态s1的概率分布服从转移概率矩阵Ps0a0,此时我们随机选择一个状态s1,然后选择一个动作a1,从而得到状态s2的概率分布,这一过程可通过下图描述
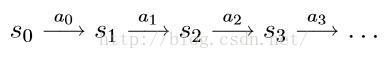
在上述过程的影响下,我们可定义回报函数Payoff Function为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1949
1949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









