






个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
Self-supervised Learning(自监督学习)
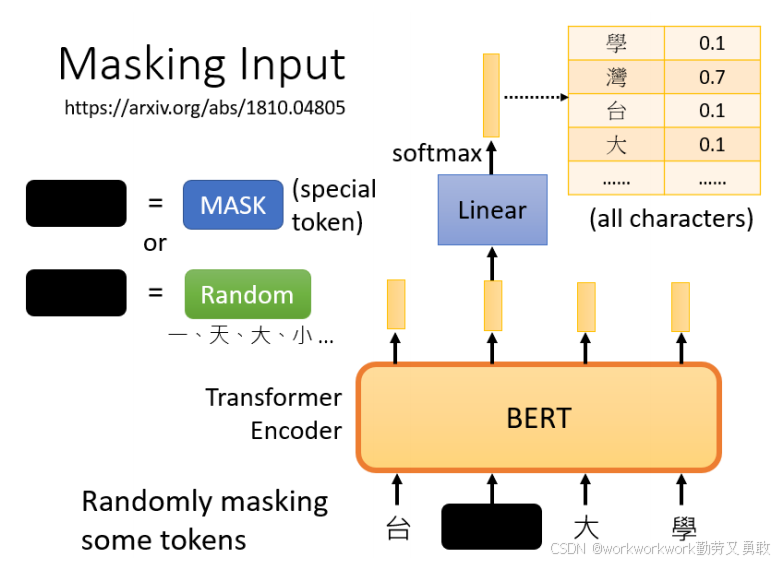
自监督学习无需人工标注,利用无标签的数据本身构造“输入-输出”对,实现类似有监督的训练。BERT 的预训练过程便是一种自监督学习:随机遮盖(mask)部分文本,然后让模型去预测被遮盖的内容,从而“自我监督”地学习语言知识。
BERT 是 Transformer 结构的 Encoder,它接收一个序列输入并输出相同长度的序列向量。BERT 主要通过两种预训练任务来学习语言表示:
Next Sentence Prediction(NSP):给模型两个句子,让其判断第二句是否是第一句的“后续句”。具体做法是在这两个句子之间添加一个特殊标记SEP,这样BERT就知道这两个句子是不同的句子,在句子开头也会有一个特殊标记CLS,传给BERT后让它回答是/不是。
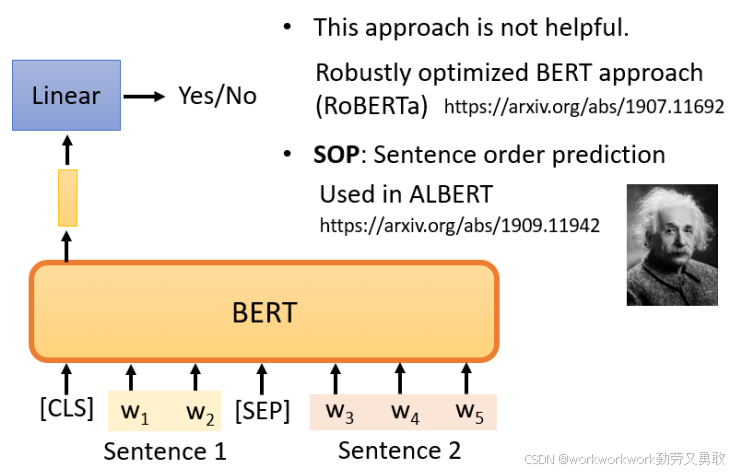
不过后续研究(如 RoBERTa 等)指出 NSP 在很多下游任务中帮助有限,一些改进模型(如 ALBERT)采用了更困难的 Sentence Order Prediction(SOP)来替代 NSP。
总的来说我们要求BERT学习两个任务:
-
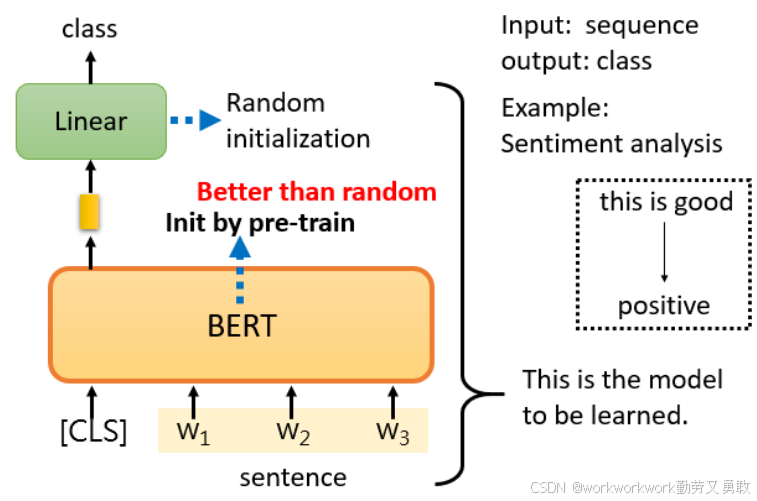
情感分析:在输入句子前加 CLS 标记,BERT 输出时只取 CLS 位置的向量,再接一个线性层做分类。在实践中,仍然需要提供标记数据,所以这其实是一种半监督式的学习,其中Linear transform的参数是随机初始化的,BERT的参数是学会填空的BERT初始化的。
-
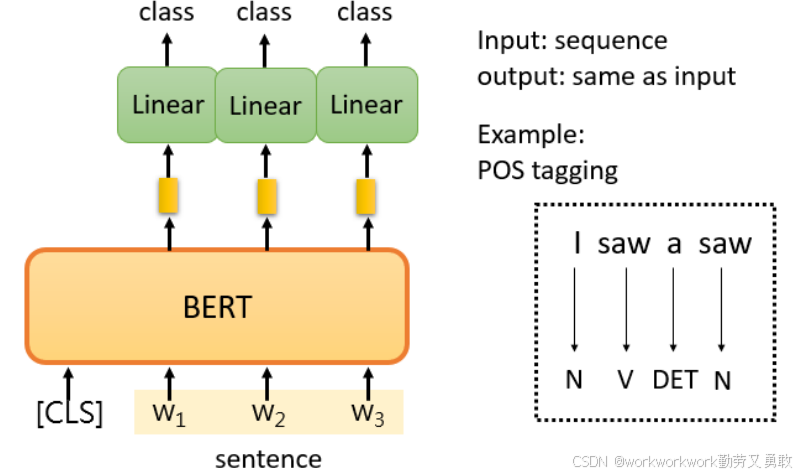
序列标注(例如词性标注 POS tagging):对 BERT 输出序列的每个向量分别做分类。比如做词性分类
-
自然语言推断(NLI):输入两个句子并用特殊标记 SEP 分隔,通过 CLS 位置向量判断两句是否矛盾/蕴涵/中立等。
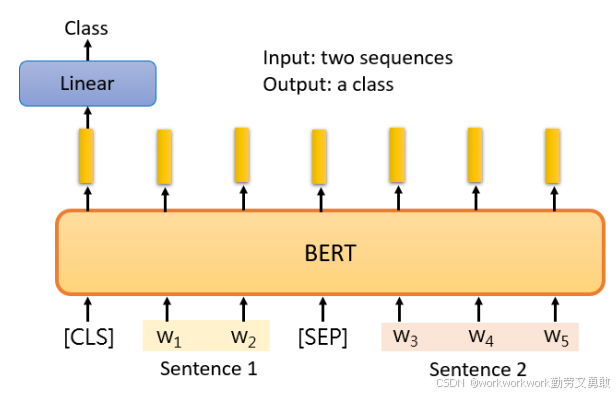
-
抽取式问答(QA):输入由“文章 + 问题 + 特殊标记”组成的序列,让 BERT 找出答案在文章中的起始和结束位置。
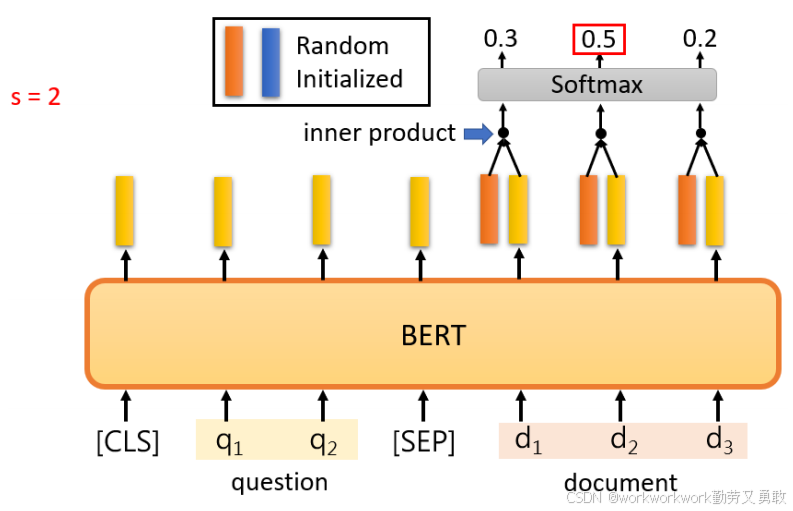
预训练Seq2Seq模型
前面提到,BERT 是 Transformer 结构的 Encoder,那么Decoder怎么训练呢?方法是这样的,transform的架构中,Decorder中的 Query(来自自身产生),Key 和 Value(来自 Encoder 的输出),通过故意在Encorder的输入中做一些干扰,而Decorder需要将句子恢复到干扰之前
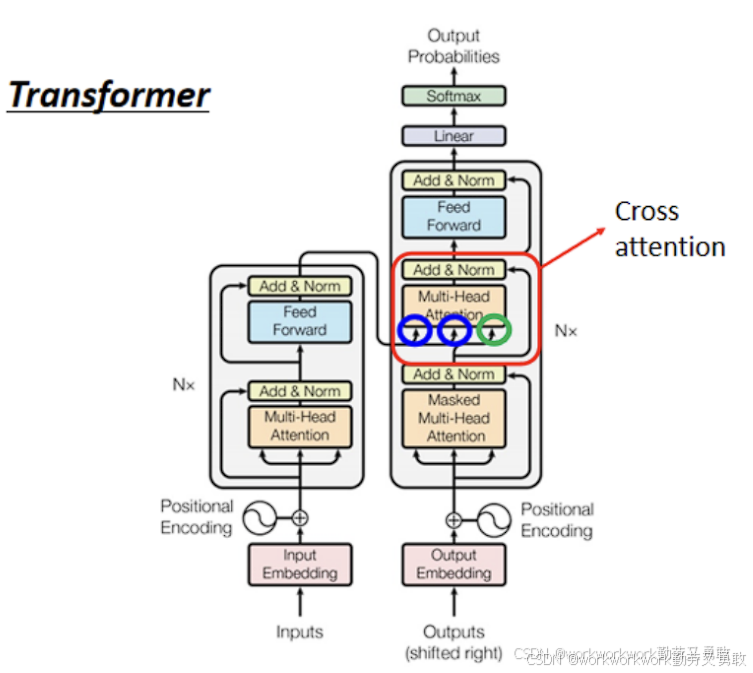
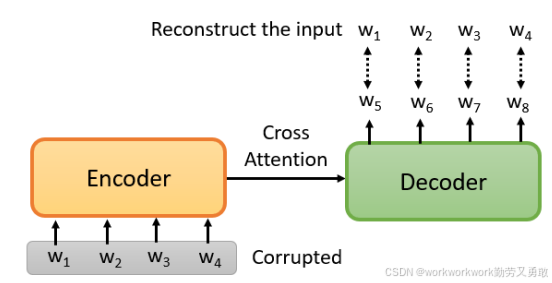
BART、T5、MASS 等“预训练 Seq2Seq”模型


BERT的工作原理
它为什么能成为一个“干细胞”?
有一种解释是这样的:每个词在不同上下文中会生成不同的向量(embedding),通过考虑上下文语境,BERT能够区分“苹果(水果)”和“苹果(公司)”。比如可食用的苹果更多的可能和产地、吃等词语相关;苹果公司则和手机、电脑等相关。

当我们训练BERT时,我们给它w1、w2、w3和w4,我们覆盖w2,并告诉它预测w2,而它就是从上下文中提取信息来预测w2。所以这个向量是其上下文信息的精华,可以用来预测w2是什么。
多语言BERT(Multilingual BERT)
Multilingual BERT是指训练时用很多种不同语言做填空
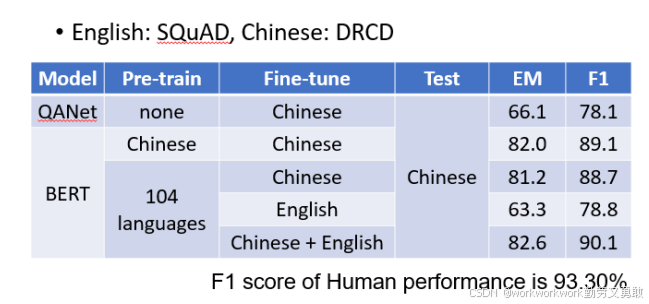
Zero-shot能力
-
用BERT做多语言预训练后,真正训练时使用英文Q&A数据,测试时用中文Q&A,BERT依然能取得不错表现(F1高达78%)。
-
说明其具有语言迁移能力,无需专门训练跨语言翻译。
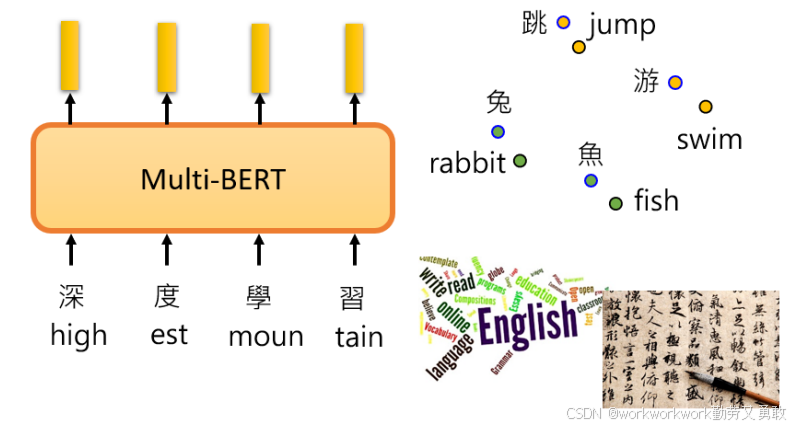
为什么能做到呢?可能是不同语言的同义词embedding在空间中位置接近。李老师提到,
-
自行训练多语言BERT时,如果数据量不足,无法对齐不同语言的embedding。
-
数据量对模型性能影响巨大,是多语言对齐成功的关键。
-
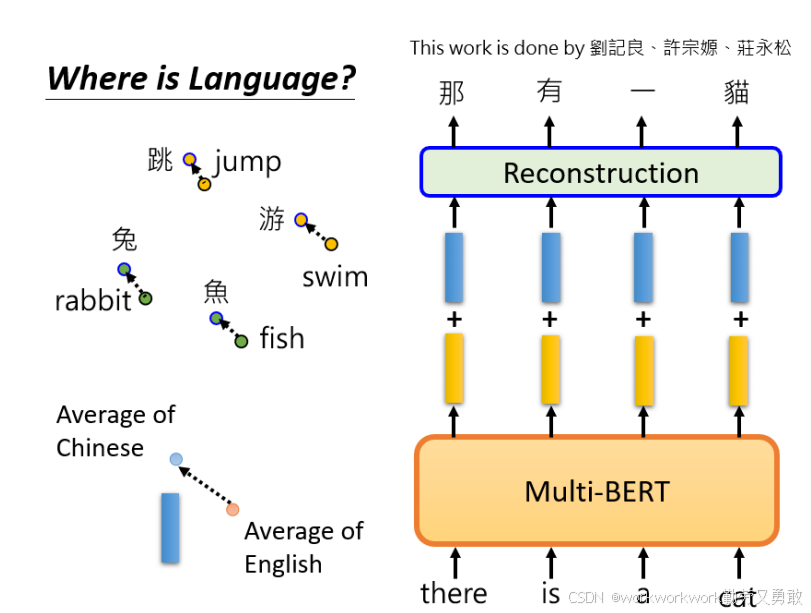
通过向embedding添加特定的“语言差异向量”,可以实现从一种语言向另一种语言的无监督转换。
对比学习与分类
分类的学习还是需要标签,对于一些语音识别,可以使用对比学习
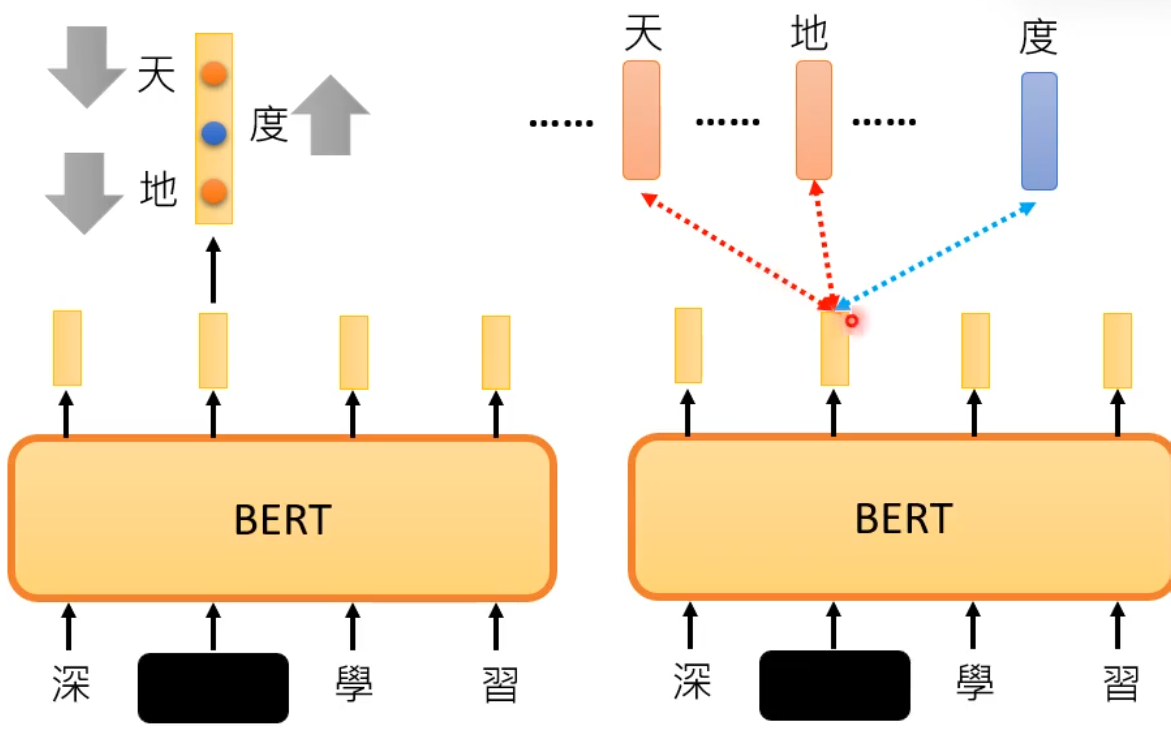
-
蓝色是 真实(正)样本 embedding;
-
橙色是 负样本 embedding(干扰项);
-
模型的目标是:
让输出向量与正样本越接近,和负样本越远。


















 2943
2943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









