






本文是对Skipnet: Learning Dynamic rounting in convolutional network的翻译。
Abstract
尽管需要更深的卷积网络才能在视觉感知任务中获得最大的准确性,但对于许多输入而言,较浅的网络就足够了。我们通过学习在每个输入的基础上跳过卷积层来利用这个观察到的结果。我们提出了SkipNet,这是一种经过改进的残差网络,它使用gating network根据前一层的激活有选择地跳过卷积层。我们在顺序决策(sequential decision)的背景下制定动态跳过(dynamic skipping)问题,并提出一种混合学习算法,将监督学习和强化学习相结合,以解决不可微分的跳过决策的问题。我们展示了SkipNet将计算量减少了30%至90%,同时在四个基准数据集上保留了原始模型的准确性,并且胜过了最新的动态网络和静态压缩方法。我们还定性评估gating策略,以揭示图像比例和显着性(saliency)与跳过的层数之间的关系。
1.Introduction
卷积网络设计中越来越多的研究揭示了一个明显的趋势:越深的网络越准确。因此,性能最佳的图像识别网络具有数百层和数千万个参数。这些非常深的网络以增加的预测成本和延迟为代价。但是,深度加倍的网络只能将预测准确性提高几个百分点。尽管这些小改进对实际应用至关重要,但它们的增量性质表明,大多数图像不需要网络深度加倍,并且最佳深度取决于输入图像。
在本文中,我们介绍了SkipNet(见图1),它是使用gating units的修改后的残差网络,可以动态选择在推理过程中应跳过卷积神经网络的哪些层。我们将动态跳过问题构造为一个顺序决策(sequential decision)问题,其中前一层的输出用于确定是否绕过后一层。然后,动态跳过问题的目标是在保留整个网络的准确性的同时,跳过尽可能多的层。跳过策略不仅可以大大降低模型推断的平均成本,而且还可以洞察各个层的收益递减和作用。
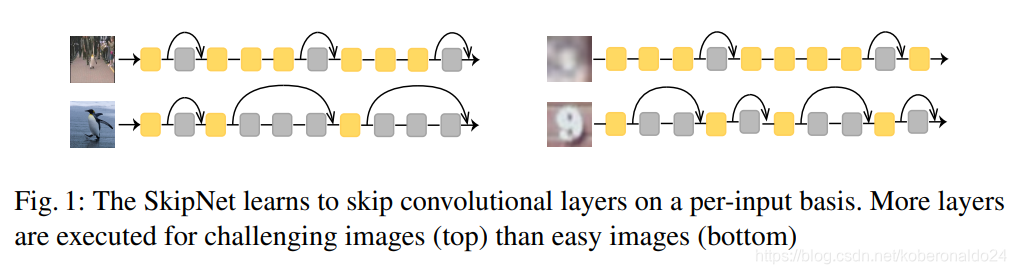
虽然从概念上讲很简单,但是学习有效的跳过策略是一项挑战。为了在保持准确性的同时减少计算量,我们需要正确绕过网络中不必要的层。这种内在的离散决定是不可微分的,因此无法应用基于梯度的优化。尽管一些文献提出了软逼近,但我们表明,为降低计算结果而需要的后续硬阈值处理导致精度较低。
最近的工作探索了强化学习(RL)在学习硬决策gate中的应用。尽管很有希望,但在我们的实验中,我们证明了这些基于RL的技术非常脆弱,经常陷于较差的局部最小值,并且所产生的网络无法与最新技术竞争。人们也可以应用重新参数化(reparametrization)技术,但是,这些方法通常部分地由于由松弛引起的逼近误差而发现次优策略(在后面的部分中有详细介绍)。
我们探索了几种SkipNet设计,并介绍了一种混合学习算法,该算法将监督学习与强化学习相结合,以解决不可微分的跳过决策的挑战。我们将gating module明确分配给每组卷积层(each group of layers)。gating模块将前一层的激活映射到二进制决策,以跳过或执行后一层。我们分两个阶段训练门控模块。首先,我们通过采用重新参数化(reparametrization)技巧对二进制skip决策使用soft-max松弛,并结合原始模型使用的标准交叉熵损失一起训练layers and gates。然后,我们将概率gate输出视为初始跳过策略,并在不使用relaxation的情况下使用REINFORCE来优化策略。在后期阶段,我们共同优化跳过策略和预测误差,以稳定探索过程。
我们使用ResNets作为基础模型,在CIFAR-10,CIFAR-100,SVHN和ImageNet数据集上评估SkipNets。我们显示,通过混合学习过程,SkipNets学习了可显着降低模型推理成本的跳过策略(在CIFAR-10数据集上为50%,在CIFAR-100数据集上为37%,在SVHN数据集上为86%,在ImageNet数据集上为30% ),同时保持准确性。我们将SkipNet与CIFAR-10和ImageNet数据集上的几种最新模型和技术进行了比较,发现SkipNet在两个基准测试中始终优于以前的方法。通过操纵计算成本超参数,我们展示了如何针对不同的计算约束条件调整SkipNets。最后,我们研究了学习的跳过策略的跳过行为,并揭示了图像比例和显着性与跳过层数之间的关系。我们的代码可从https://github.com/ucbdrive/skipnet获得。
2.Related Work
加速现有的卷积网络一直是实际部署中的中心问题,并且已经提出了几种补充方法。这项工作的大部分工作集中在通过权重稀疏化,滤波器修剪,矢量量化和蒸馏来将模型知识转移到较浅的网络上进行模型压缩。这些方法是在训练初始网络之后应用的,通常用作后处理。而且,这些优化的网络不会响应输入动态地调整模型的复杂性。虽然这些方法是互补的,但我们显示SkipNet优于现有的静态压缩技术。
几项相关的工作探索了通过提早终止来动态缩放计算。 Graves [8]探索了暂停循环网络以节省计算成本。 Figurnov等人和Teerapittayanon等人提出在卷积网络中使用尽早终止。与我们的工作最接近的是Figurnov等人研究了ResNets每组块中的提前终止。相比之下,SkipNet并不会提早退出,而是根据处理层的输出有条件地绕过各个层,我们显示出结果可以更好地权衡成本。
另一项工作探索级联模型的组成。这项工作建立在这样的观察基础上,即可以使用较小的模型准确地标记许多图像。 Bolukabasi等人为以增加成本的顺序排列的预训练模型的级联训练了一种终止策略。这种标准的级联方法无法跨分类器重用功能,并且需要大量的存储开销。类似于自适应时间计算的工作,Bolukabasi等人还探讨了网络内的早期终止。但是,在许多广泛使用的体系结构(例如ResNet)中,层被分为几组。有些层比其他层更关键(图10a)。 [1]的网络内级联工作无法在执行未来组中的后续层时绕过某些层。 SkipNets以组合方式探索选择网络中的各个层,从而形成级联超集的搜索空间。
SkipNets中的门控模块充当层组的调节gate。它们与循环神经网络(RNN)中的门控设计有关[3,14,27]。 Hochreiter等人提出给RNN添加门,以便网络可以将重要的内存保持在网络状态。 Srivastava等人[27]将类似的技术引入到卷积网络中,以学习深度图像表示。 [3]和[26]都将门应用于其他图像识别问题。在门输出是连续的意义上,这些建议的门是“软”的,而我们的门是“硬”二进制决策。我们在实验中表明,对于动态网络,“硬”选通比“软”选通更可取。
3.SkipNet Model Design
SkipNets是卷积网络,其中对于给定输入有选择地包括或排除了各个层。 使用插入在各层之间的小型门控网络可以完成各层的按输入选择。 gating网络将前一层或一组层的输出映射到一个二进制决策,以执行或绕过后一层或一组层,如图2所示。
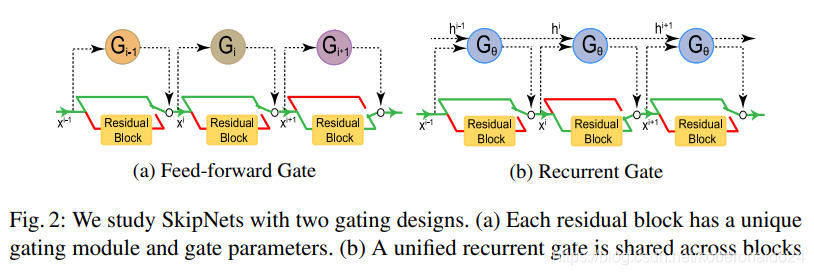
更准确地说,令xi为第i层或一组层的输入,而Fi(xi)为第i层或一组层的输出,然后将门控层(或一组层)的输出定义为:
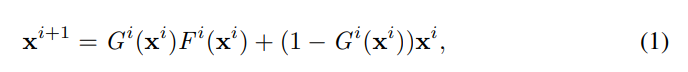
其中Gi(xi )∈ {0,1}是第i层的门控功能。 为了等式1定义明确,我们要求Fi (xi )和xi 具有相同的尺寸。 常用的残差网络体系结构可以满足此要求,其中:
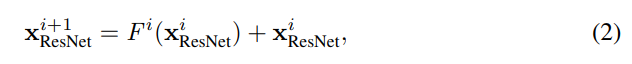
gating网络设计既要充分具备表达能力,以准确确定要跳过的层,又要节省计算量。 为了解决精度和计算成本之间的折衷问题,我们探索了一系列门控网络设计(第3.1节),涵盖前馈卷积架构到具有不同程度参数共享的递归网络。 无论哪种情况,确定门控网络参数都会因离散的门控决策以及使精度最大化和成本最小化的竞争目标而变得复杂。 为了学习门控网络,我们引入了一种两阶段训练算法,该算法结合了监督式预训练(第3.3节)和基于策略的优化(第3.2节),并使用了将预测精度与计算成本相结合的混合奖励函数。
3.1 Gating Network Design
在本文中,我们评估了两种前馈卷积gate设计(图2a)。 FFGate-I(图11a)设计由步幅分别为1和2的两个3×3卷积层组成,其后是全局平均池化层和全连接层,以输出单个维矢量。为了减少门运算,我们在第一个卷积层之前添加了2×2 max池化层。 FFGate-I的总体计算成本约为本文使用的剩余块的19%[10]。作为一种节省计算量的替代方案,我们还介绍了FFGate-II(图11b),它由一个3×3步幅2的卷积层组成,随后是与FFGate-I相同的全局平均池化和完全连接的层。 FFGate-II的计算成本为剩余块成本的12.5%。在我们的实验中,我们将FFGate-II用于具有100层以上的网络,将FFGate-I用于较浅的网络。
前馈门设计的计算成本仍然相对较高,并且无法利用先前门的决策。因此,我们引入了循环门(RNNGate)设计(图11c),该设计可实现参数共享并允许门跨阶段重用计算。我们首先在门的输入特征图上应用全局平均池,然后将特征线性投影到输入大小10。我们采用隐藏层大小为10的单层长短期记忆网络(LSTM)。对于每个门,我们将LSTM输出投影到一维向量以计算最终门决策。与计算残差块的成本相比,这种循环门设计的成本可以忽略不计(约占残差块计算的0.04%)。
在我们后面的实验中,我们发现递归门在预测精度和计算成本上都远超FFGate。我们还评估了没有卷积层的更简单的前馈门设计,尽管这些设计与递归门的计算成本相匹配,但预测精度受到了影响。我们推测循环门设计可以更好地捕获跨层依赖性。
3.2 Skipping Policy Learning with Hybrid RL
在推理期间,最有可能采取的行动是从每个门所编码的概率分布中决定的:该层被跳过或执行。这种固有的离散因而不可微的决策过程给我们如何训练SkipNets带来了独特的挑战。与公路网[27]中使用的方法类似,一种自然的近似方法是在训练过程中使用可微分的soft-max决策,然后在推理过程中恢复为硬决策。尽管此方法支持基于梯度的训练,但由于推理过程中网络参数未针对随后的硬门优化而无法实现,因此导致预测精度较差(第4.3节)。因此,我们探索了使用强化学习来学习不可微决策过程的模型参数。
由于SkipNets做出一系列离散决策,每个gate层决策一个,因此我们在通过强化学习进行策略优化的情况下,对估算门控功能的任务进行了框架设计。我们定义了跳过策略:
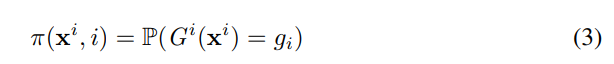
作为从输入xi到执行(gi= 1)或跳过(gi = 0)层i的门动作gi上的概率分布的函数。 我们将从输入x开始的跳过策略中得出的门控决策示例序列定义为:
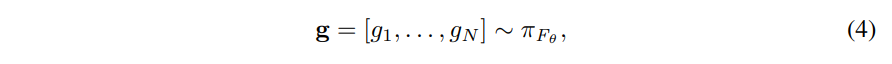

(这段翻译不来了。。。)
3.3 Supervised Pre-training
从随机参数开始优化方程式8还会始终产生预测精度较差的模型(第4.3节)。 我们推测学习能力下降是由于policy学习和图像表征学习之间的相互作用。 gating策略可能会过度适合早期特征,从而限制了将来的特征学习。
为了提供有效的监督初始化过程,我们引入了一种监督学习的预训练形式,该形式将正向传递期间hard-gating与反向传播期间的soft-gating相结合。 我们将等式1中的门输出G(x)放宽到连续值(即用S(x)2 [0,1]近似G(x))。 我们对正向传递中跳过模块的输出门控概率进行四舍五入。 在反向传播期间,我们使用soft-max近似值[16,21]并计算相对于soft-max输出的梯度。 松弛过程总结为:
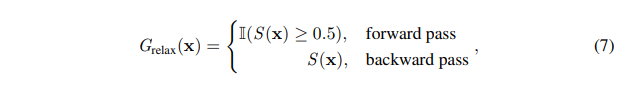
其中Ⅱ(·)是指标函数。 有监督的预训练的这种混合形式能够有效利用标记的数据来初始化基础网络和gating网络的模型参数。 经过监督的预训练后,我们然后应用REINFORCE算法来精炼模型和gate参数,从而提高预测精度并进一步降低预测成本。 我们的两阶段混合算法在Alg.1中给出。

4.Experiments
我们评估了一系列SkipNet架构以及我们在四个图像分类基准上建议的训练程序:CIFAR-10 / 100 [17],SVHN [24]和ImageNet 2012 [25]。 我们通过在残差块之间引入hard gates,从ResNet模型[10]构建SkipNet。 在第4.1节中,我们评估了两种门设计的SkipNets的性能,并将SkipNets与包括动态网络和静态压缩网络在内的最新模型进行了比较,这些模型也是我们方法的补充方法。 我们还将我们的方法与受[15]启发的基准进行比较,以证明学习的跳过策略的有效性。 在第4.2节中,我们通过广泛的定性研究和分析来解读SkipNets的动态本质,以揭示图像尺度与显着性和跳过层数之间的关系。 在第4.3节中,我们讨论了所提出的学习算法和门控设计的有效性。
Datasets
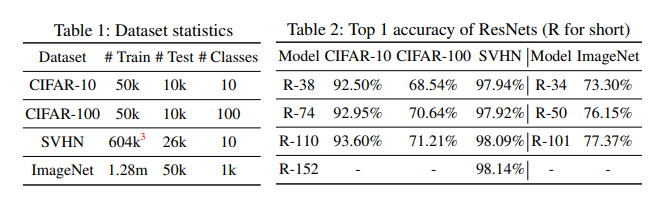
表1总结了本文使用的数据集的统计信息。 我们遵循为CIFAR和ImageNet数据集采用的通用数据增强方案(镜像/移位)[7,19,33]。 对于SVHN数据集,我们同时使用了训练并提供了额外的训练数据集,并且没有执行数据扩充[15]。 对于预处理,我们使用通道平均值和标准偏差对数据进行归一化。
Models
对于CIFAR和SVHN,我们对基本模型使用具有6n + 2堆叠加权层的ResNet [10]体系结构,并选择n = {6,12,18,25}来构建深度为{38,74,110 ,152}。 对于ImageNet,我们按[10]中所述评估ResNet-34,ResNet-50和ResNet-101。 我们用SkipNet-x表示深度为x的模型。 此外,我们添加+ SP和+ HRL来指示是否使用了监督预训练或混合强化学习。 如果未提供修饰符,则我们将执行完整的两阶段培训程序。 最后,我们还将使用+ FFGate和+ RNNGate指示正在使用的门控设计。 如果未指定,则使用RNNGate。 我们在表2中总结了基本模型的准确性。在后面的章节中,我们演示SkipNets可以保持相同的准确性(相差0.5%)。
Training
我们的两阶段培训程序将监督式预培训和政策改进与混合强化学习相结合。 在第一阶段,我们采用与[10]中的CIFAR和ImageNet和[15]中的SVHN相同的超参数。
在policy优化阶段,我们将训练后的模型用作初始化,并使用相同的优化器对其进行优化,所有数据集的学习率降低为0.0001。 我们训练了固定的迭代次数(CIFAR数据集为10k迭代,SVHN数据集为50 epoch,ImageNet数据集为40 epoch),并报告了终止时评估的测试准确性。 有监督的预训练阶段的训练时间与在不进行门控的情况下训练原始模型的时间大致相同。 我们的总体培训时间略长一些,增加了约30-40%。
4.1 SkipNet Performance Evaluation
在本小节中,我们首先在四个基准数据集上提供SkipNets的整体计算量减少量,以证明SkipNet实现了减少计算量的主要目标,同时又保留了完整的网络预测精度。 我们还表明,通过调整α,SkipNet可以满足不同的计算成本和准确性要求。 为了进行水平比较,我们显示了SkipNet在ImageNet和CIFAR-10上均优于一组最新的动态网络和静态压缩技术。
Computation reduction while preserving full network accuracy
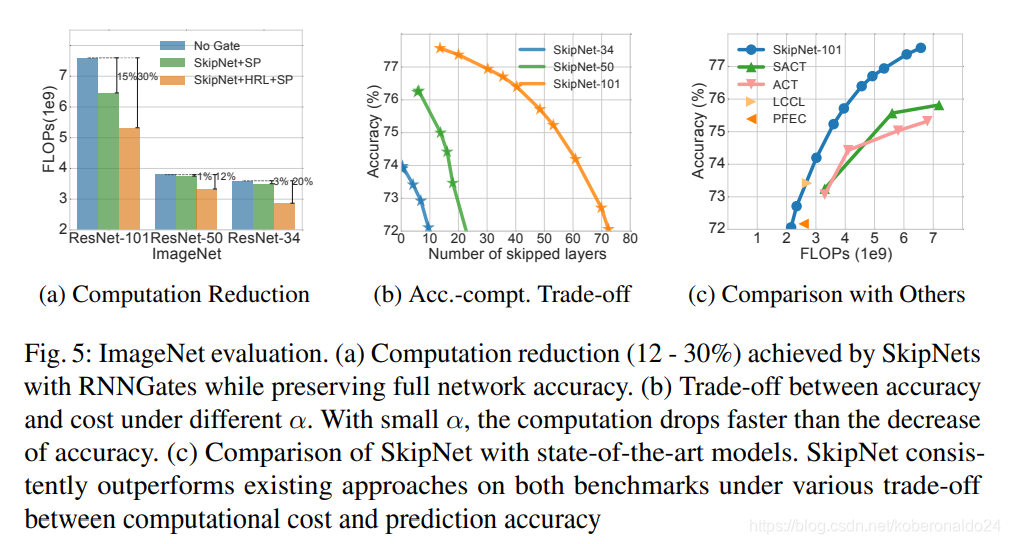
图4和图5a显示了FFGate和RNNGate设计的原始ResNet和SkipNet的浮点运算(FLOP)的计算成本(包括门网络的计算),其中α已调整为匹配相同的精度(方差小于0.5%)。精度和计算成本之间的权衡将在后面讨论。根据[10],我们仅考虑与卷积运算相关的乘积,因为其他运算对成本的影响可忽略不计。
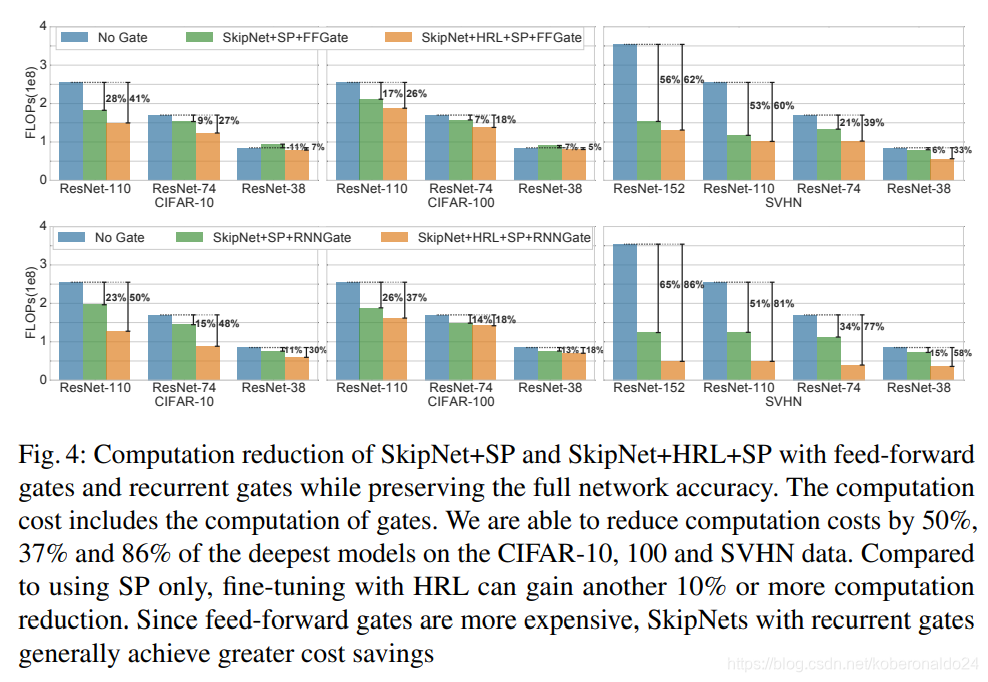
我们观察到带有监督预训练的混合强化学习(HRL)(SkipNet + HRL + SP)能够大大降低计算成本。总体而言,对于每个数据集上最深的模型,带有循环门的SkipNet-110 + HRL + SP分别将CIFAR-10和CIFAR-100数据集的计算量减少了50%和37%。最大的具有循环门的SkipNet-152 + HRL + SP模型将SVHN数据集的计算量减少了86%。在ImageNet数据上,使用循环门的SkipNet-101 + HRL + SP能够将计算量减少30%。有趣的是,如前所述,即使在目标中没有cost正规化的情况下,SkipNet体系结构的监督预训练也始终可以降低预测成本。一种解释的方法是,较浅的网络更容易训练,因此更有利。我们还观察到,更深层的网络倾向于降低更多的成本,这支持了我们的猜测,即只有一小部分投入需要极深的网络。
Trade-off computational cost and accuracy
公式8引入了超参数α,以平衡计算成本和分类精度。 在图5b中,我们针对ImageNet上从0.0到4.0的α的不同值,针对跳过层的平均数量绘制了精度。 我们在其他数据集上观察到类似的模式,并且可以在补充材料中找到详细信息。 通过调整α,可以折衷计算和精度来满足各种计算或精度要求。
Comparison with state-of-the-art models
我们将SkipNet与ImageNet(图5c)和CIFAR-10(图6c)上现有的最新模型进行比较。 [6]提出的SACT和ACT模型是自适应计算时间模型,试图在ResNets的每组块中尽早终止计算(第2节)。另外,我们将SkipNet与静态压缩技术进行了比较:PEFC [20]和LCCL [5],它们也是我们方法的补充方法。
如图5c所示,即使SkipNet-101使用最新的更准确的预激活[11] ResNet-101作为基本模型,但它们在ImageNet基准上的表现仍大大优于SACT和ACT模型。我们假设跳过模型公式化提供的增加的灵活性使SkipNet设计胜过SACT和ACT。在图6c.4的CIFAR-10上可以观察到类似的图案
为了与静态压缩技术进行比较,我们在图5中绘制了计算FLOP和压缩残差网络的精度(可能与本文中使用的深度有所不同)。尽管静态压缩技术是互补的方法,但SkipNet可以执行类似于或优于这些技术。请注意,尽管LCCL [5]使用更浅,更便宜的ResNet(在ImageNet上为34层,在CIFAR-10上为20、32、44层),但我们的方法仍可获得相当的性能。
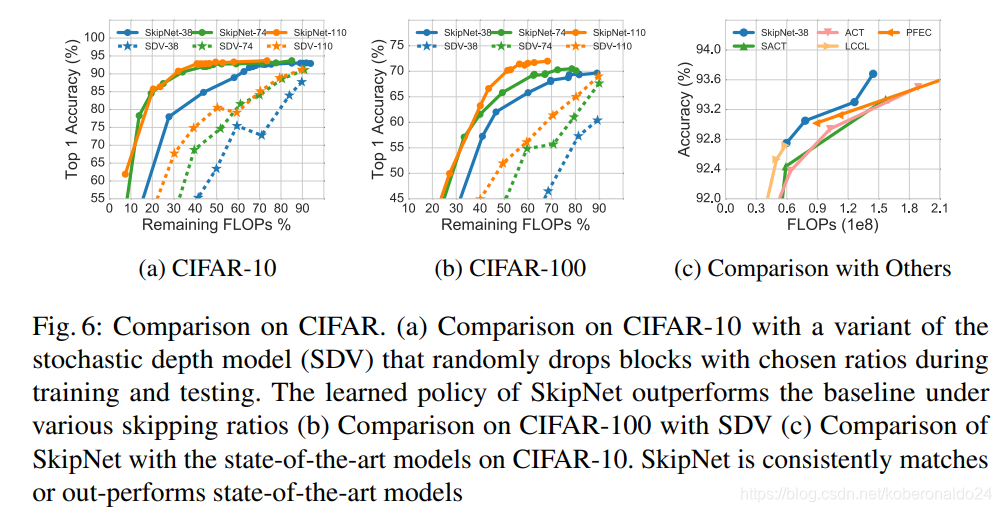
Comparison with stochastic depth network variant
Huang等人提出了一种随机深度网络,该网络可以随机丢弃每个训练小批量的图层,并恢复为使用完整网络进行推理。 随机深度模型的最初目标是避免梯度消失并加快训练速度。 为了减少推理计算成本,此模型的自然变体是在训练和推理阶段(称为SDV)中以选定的比率随机跳过块。 我们在图6a和6b所示的CIFAR-10和CIFAR-100数据集上将SkipNet与SDV进行了比较。 在不同深度的网络下,SkipNet大大优于SDV。
4.2 Skipping Behavior Analysis and Visualization
在本小节中,我们研究与动态跳过相关的关键因素,并定性地可视化其行为。 我们从以下几个方面研究块跳过和输入图像之间的相关性:(1)图像之间的质量差异(2)输入的比例和(3)每个类别的预测准确性。 我们发现,SkipNet在更小比例的输入和更明亮,更清晰的图像上更积极地跳过。 此外,对于高精度的类,将跳过更多的块。
Qualitative difference between inputs
为了更好地理解学习的跳过模式,我们将图7中的SkipNets跳过了许多层(视为简单示例)并针对CIFAR-10和SVHN保留了许多层(视为硬示例)。有趣的是,我们发现每个群集中的图像在显着性和清晰度方面都具有相似的特征。在这两个数据集上,我们观察到简单的示例更加突出(明亮,清晰且具有高对比度),而困难的示例则黑暗而模糊,甚至人类都难以识别。这些发现表明,SkipNet可以识别输入的视觉差异,并相应地跳过图层。

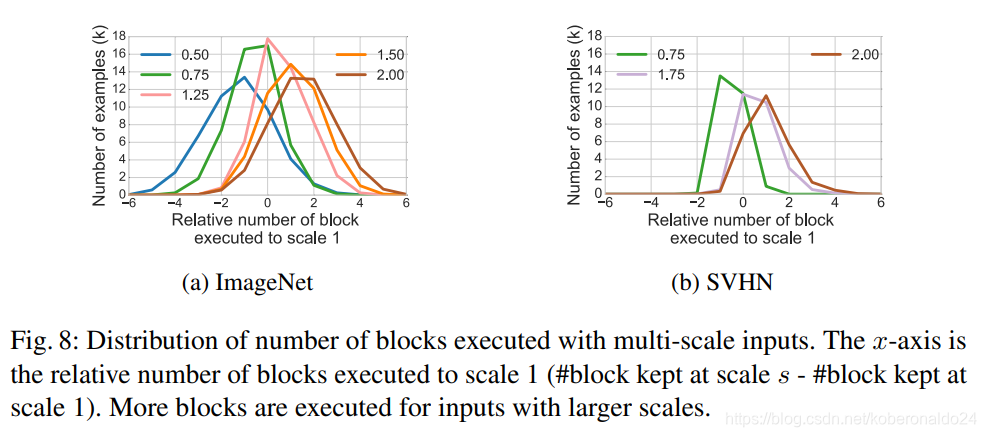
Input scales
我们推测输入尺寸会影响门的跳过决策。为了验证这一假设,我们在ImageNet和SVHN数据集上对经过训练的模型进行了多尺度测试。我们绘制了相对于其他实验中使用的原始比例1而言,不同输入比例执行的块数分布的图。我们在两个数据集上都观察到,较小比例的分布偏左(执行比输入比例为1的模型少的块),而较大比例的分布偏右(执行了更多的块)。这种观察符合直觉,即较大规模的输入需要较大的接收场,因此需要执行更多的块。另一种解释是,SkipNet为具有不同输入比例的给定输入动态选择具有适当接收场大小的图层。
Prediction accuracy per category
我们进一步研究了skipping行为与CIFAR-10上每个类别的预测准确性之间的相关性。可以预见的是,SkipNet在简单的类(例如卡车类的高精度类)上跳过更多,而在困难的类(例如猫狗类的低精度类)上跳过较少。我们在图9a中为SkipNet + SP和Skip-Net + HRL + SP在每个类别中绘制了跳过层数的中位数。它表明,尽管所有类在应用HRL后倾向于更积极地跳过,但SkipNets倾向于在简单类上跳过更多层。图9b表明,硬类(例如狗类)的分布向左偏斜,而较容易的类(例如卡车类)的偏向右偏,因为SkipNet倾向于在较容易的类上跳过更多层。
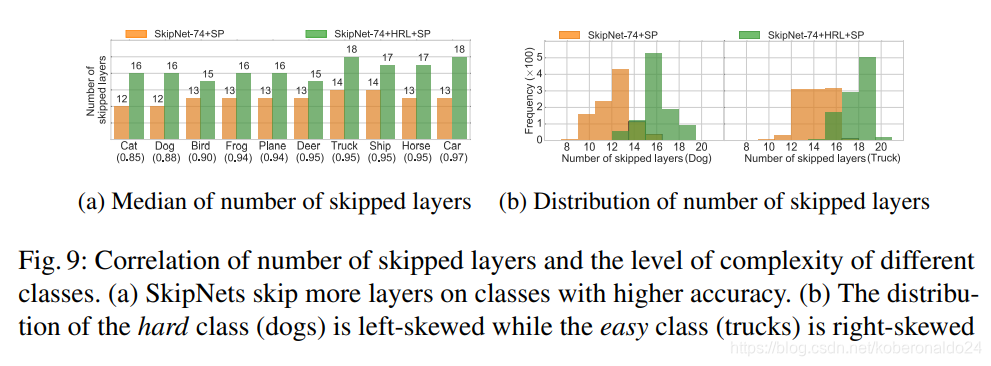
Skip ratio of different blocks
我们在图10a中的CIFAR-10上通过SkipNet可视化了不同块的跳过率。补充材料中可以找到SkipNet在其他数据集(例如ImageNet,CIFAR-100)上的可视化。 ResNet模型可以分为3组,其中同一组中的块具有相同的特征图大小,并且往往具有相似的功能。有趣的是,我们观察到第2组的跳跃比第1组和第3组少,这表明第2组对于特征提取可能更为关键。
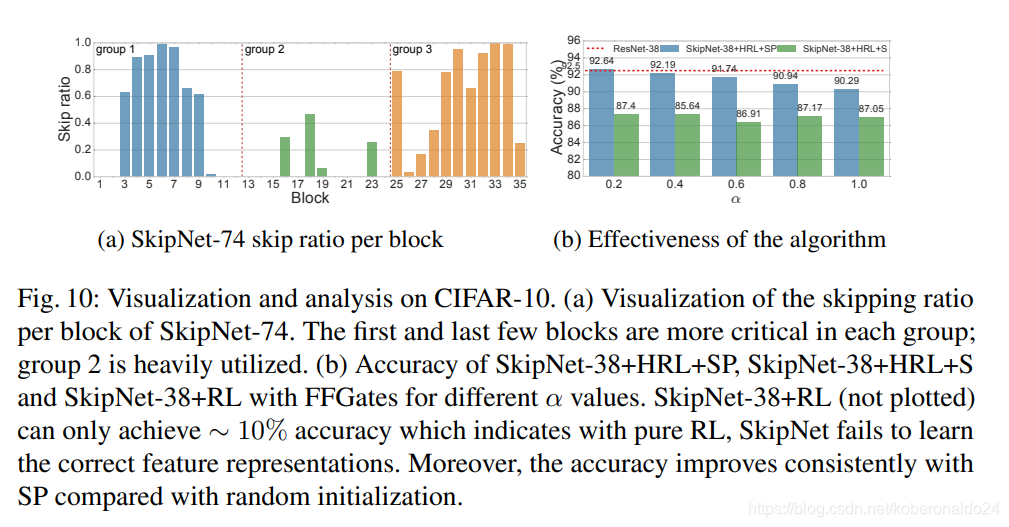
4.3 SkipNet Design and Algorithm Analysis
Effectiveness of hybrid learning algorithm
我们在图10b中比较了在CIFAR-10上使用基本RL,从头开始的混合RL(HRL + S)和混合RL加上监督的预训练(HRL + SP)训练的SkipNet-38的性能 。 对于SkipNet + HRL + S和SkipNet + RL,我们训练两个网络进行80k迭代,以匹配SkipNet + HRL + SP两阶段训练的总训练步骤。
首先,我们无法使用纯RL方法训练模型(SkipNet-38 + RL精度约为10%)。 这为在复杂视觉任务中进行监督的重要性提供了有力的证据。 其次,SkipNet-38 + HRL + SP始终比SkipNet-38 + HRL + S更高。 即使使用很小的↵,SkipNet-38 + HRL + S的精度也低于原始ResNet-38模型的精度。 这表明,有监督的预培训可以提供更有效的初始化,这有助于HRL阶段将更多的精力放在跳过策略学习上。
“Hard” gating and “Soft” gating design
在有监督的预训练中,我们可以将门输出视为“硬”(第3.3节)或“软”(第3.2节)。对于“软”门控,采用连续门控概率进行训练,但离散值用于 推断以实现所需的计算简化。 在表3中,我们显示了在类似的计算成本下,带有“硬”门(SkipNet-Hd)和“软”门(SkipNet-St)的SkipNet的分类精度。 SkipNet-Hd实现的准确性比SkipNet-St高得多,这可能是由于训练与软门控推理之间的不一致。
5.Conclusion
我们引入了SkipNet体系结构,该体系结构学会了在不牺牲预测准确性的情况下,在每个输入的基础上动态跳过冗余图层。我们将动态执行问题定为顺序决策问题。为了解决动态执行固有的不可微性,我们提出了一种新颖的混合学习算法,该算法结合了监督学习和强化学习的优势。
我们在四个基准数据集上评估了所提出的方法,表明Skip-Nets在保留原始精度的同时大大减少了计算量。与最新的动态模型和静态压缩技术相比,SkipNets可以以较低的计算量获得更高的准确性。此外,我们进行了一系列的消融研究,以进一步评估所提出的网络架构和算法。
动态架构通过专门化和重复使用单个组件,提供了更高的计算效率和提高准确性的潜力。我们认为,对该领域的进一步研究对于机器学习和计算机视觉的长期发展至关重要。















 2350
2350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









