









PyTorch深度学习实践-RNN
基础篇
RNNS
RNN适用于处理诸如天气、股票和自然语言等带有序列性质的数据结构;
①RNN Cell
RNN Cell就相当于是一个线性层,对输入的数据xt进行空间变换,生成输出数据ht。
p.s. RNN Cell也是基于权值共享的原则来进行的,也就是在同一层变换中所有的RNN Cell使用的是同一个线性变换。
②RNN 计算逻辑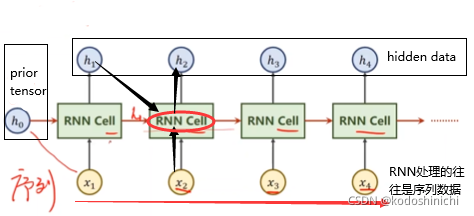
- 序列中每一个点的数据传入RNN Cell后和前一层得到的隐层数据一起生成下一层的数据;
- h0表示的是先验数据,比如需要根据图像生成文本时,可以将CNN+FC得到的特征向量作为先验传给RNN网络;如果没有可以利用的先验数据,则直接传入和隐层数据相同维度的全零向量;
- 所谓的【权值共享】指的就是在当前这一层所有的RNN Cell是相同的权值。
③RNN Cell计算过程
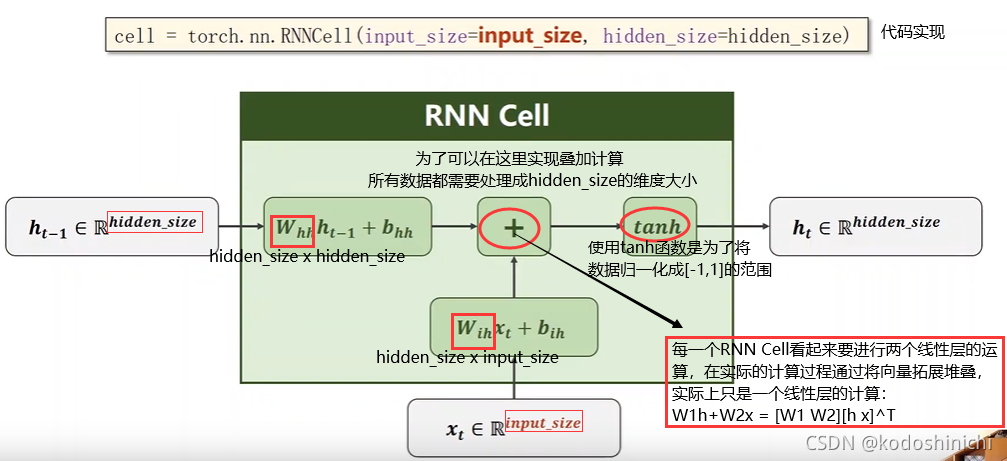
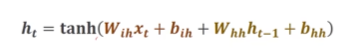
④RNN的计算实现
- 在PyTorch中RNN的实现有两种方式:
其一,就是自己对RNN Cell中的计算逻辑进行定义,然后写一个循环计算的主过程;
其二,就是对内部封装好的RNN模块进行调用
#方法一:自定义RNNCell的计算过程并计算
#定义一个RNNCell关键在于明确其输入出的尺度即可
# cell = torch.nn.RNNCell(input_size = input_size,hidden_size = hidden_size)
# hidden = cell(input,hidden) #实例化一个隐层
#使用自定义的RNNCell进行相关计算
batch_size = 1
seq_len = 3 #相较以前的DNN和CNN多了一个序列长度的维度
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size = input_size,hidden_size = hidden_size)
#将数据按照(seq,batch,features)的方式进行组装,这样的顺序便于之后取数据
dataset = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(batch_size,hidden_size) #按照指定维度全零初始化隐层大小
for idx,input in enumerate(dataset):
print('=' * 20, idx, '=' * 20)
print('Input_size: ',input.shape)
hidden = cell(input,hidden)#循环逻辑中重要的一环
print('hidden size:',hidden.shape)
print(hidden)
'''
运行结果:
==================== 0 ====================
Input_size: torch.Size([1, 4])
hidden size: torch.Size([1, 2])
tensor([[-0.0622, -0.7854]], grad_fn=<TanhBackward>)
==================== 1 ====================
Input_size: torch.Size([1, 4])
hidden size: torch.Size([1, 2])
tensor([[0.5771, 0.4987]], grad_fn=<TanhBackward>)
==================== 2 ====================
Input_size: torch.Size([1, 4])
hidden size: torch.Size([1, 2])
tensor([[-0.9632, 0.0138]], grad_fn=<TanhBackward>)
'''
# 方法二,直接使用封装好的RNN模块,需要传入输入尺寸、隐层尺寸和层数
#按照给定的维度大小实例化一个RNN网络即可
# cell = torch.nn.RNN(input_size = input_size,hidden_size = hidden_size,
# num_layers = num_layers)
# out,hidden = cell(inputs,hidden)
# 使用封装好的RNN模块进行相关计算
#定义维度及相关参数
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size = input_size,hidden_size = hidden_size,
num_layers = num_layers)
#同样按照(SeqLen,batchSize,inputSize)的顺序对数据进行组装
inputs = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(num_layers,batch_size,hidden_size)
out,hidden = cell(inputs,hidden)
print('output size:',out.shape)
print('output: ',out)
print('Hidden size:',hidden.shape)
print('Hidden:',hidden)
'''
运行结果:
output size: torch.Size([3, 1, 2])
output: tensor([[[-0.9672, 0.1342]],
[[ 0.0097, 0.7191]],
[[ 0.9787, 0.8844]]], grad_fn=<StackBackward>)
Hidden size: torch.Size([1, 1, 2])
Hidden: tensor([[[0.9787, 0.8844]]], grad_fn=<StackBackward>)
'''
实例:使用RNN进行Seq2Seq的训练
(一)使用RNNCell
步骤流程:
①定义好相关参数与数据
②定义模型、损失函数和优化器
③编写训练过程的代码
其中在RNN模型定义阶段:
①要将input_size,hidden_size和batch_size(只有初始化hidden数据的时候需要)这些重要的参数传入;
②根据维度实例化一个RNNCell隐层单元
③并在模型的前向计算函数(forward)中编写迭代计算的代码。
#实例:使用RNN进行seq2seq学习
#设置维度参数
input_size = 4
hidden_size = 4
batch_size = 1
#数据准备
idx2char = ['e','h','l','o'] #以列表的形式组织词典,方便索引
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]#独热编码词典,方便将数据组织成独热编码形式
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
labels = torch.LongTensor(y_data).view(-1,1)
#定义模型
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size):
super(Model,self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size = self.input_size,hidden_size = self.hidden_size)
def forward(self,input,hidden):
hidden = self.rnncell(input,hidden)#使用自定义的RNNCell书写RNN的循环计算过程
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size)
net = Model(input_size,hidden_size,batch_size)
#定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.1)
#定义训练过程
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('Prediceted string: ',end = '')
for input, label in zip(inputs,labels):
hidden = net(input,hidden)
loss += criterion(hidden,label)#这里要使用计算图进行运算
_,idx = hidden.max(dim = 1)
print(idx2char[idx.item()],end = '')
loss.backward()
optimizer.step()
print(',Epoch [%d/15] loss = %.4f'% (epoch+1,loss.item()))
'''
运行结果:
Prediceted string: ooeeo,Epoch [1/15] loss = 7.6255
Prediceted string: ooool,Epoch [2/15] loss = 6.0844
Prediceted string: ollol,Epoch [3/15] loss = 5.2406
Prediceted string: ollol,Epoch [4/15] loss = 4.7149
Prediceted string: ollll,Epoch [5/15] loss = 4.3591
Prediceted string: ohlll,Epoch [6/15] loss = 4.0733
Prediceted string: ohlll,Epoch [7/15] loss = 3.8144
Prediceted string: ohlol,Epoch [8/15] loss = 3.5744
Prediceted string: ohlol,Epoch [9/15] loss = 3.3530
Prediceted string: ohlol,Epoch [10/15] loss = 3.1521
Prediceted string: ohlol,Epoch [11/15] loss = 2.9789
Prediceted string: ohlol,Epoch [12/15] loss = 2.8339
Prediceted string: ohlol,Epoch [13/15] loss = 2.7003
Prediceted string: ohlol,Epoch [14/15] loss = 2.5856
Prediceted string: ohlol,Epoch [15/15] loss = 2.5081
'''
(二) 使用RNN
代码逻辑对比
#使用RNN进行Seq2Seq的学习
#设置维度参数
input_size = 4
hidden_size = 4
num_layers = 1 #使用RNN新增的参数
batch_size = 1
seq_len = 5 #使用RNN新增的参数
#数据准备
idx2char = ['e','h','l','o'] #以列表的形式组织词典,方便索引
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]#独热编码词典,方便将数据组织成独热编码形式
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)
labels = torch.LongTensor(y_data)#对输入出数据的维度进行调整
#定义模型
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size,num_layers = 1):
super(Model,self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size = self.input_size,hidden_size = self.hidden_size,
num_layers = num_layers)
def forward(self,input):#使用RNN不用再显示地对hidden的数据进行操作
hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
#定义RNN前向计算时先对要用到的hidden数据进行一下全零初始化
out,_ = self.rnn(input,hidden)#使用封装好的RNN直接进行计算
return out.view(-1,self.hidden_size)#输出的格式应该是[seqLen x num_layers,hidden_size]大小的矩阵
net = Model(input_size,hidden_size,batch_size,num_layers)
#定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.05)
#定义训练过程
for epoch in range(15):
#因为不需要对seqLen个RNNCell的loss逐一累加计算了
#所以可以直接调用torch中封装好的反向传播逻辑
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy() #使用封装好的RNN计算 得到的数据都是以张量的形式出现
print('Prediceted string: ',''.join([idx2char[x] for x in idx]),end = '')
print(',Epoch [%d/15] loss = %.4f' % (epoch + 1, loss.item()
'''
运行结果:
Prediceted string: ellll,Epoch [1/15] loss = 1.6451
Prediceted string: hhllh,Epoch [2/15] loss = 1.5567
Prediceted string: hhlll,Epoch [3/15] loss = 1.4618
Prediceted string: hhlll,Epoch [4/15] loss = 1.3571
Prediceted string: hhlll,Epoch [5/15] loss = 1.2495
Prediceted string: hhlll,Epoch [6/15] loss = 1.1544
Prediceted string: hhlll,Epoch [7/15] loss = 1.0838
Prediceted string: ohlll,Epoch [8/15] loss = 1.0309
Prediceted string: ohlll,Epoch [9/15] loss = 0.9789
Prediceted string: ohlll,Epoch [10/15] loss = 0.9235
Prediceted string: ohlll,Epoch [11/15] loss = 0.8714
Prediceted string: ohlll,Epoch [12/15] loss = 0.8284
Prediceted string: ohlll,Epoch [13/15] loss = 0.7944
Prediceted string: ohlll,Epoch [14/15] loss = 0.7664
Prediceted string: ohlll,Epoch [15/15] loss = 0.7413
'''
(三)独热编码
【特性】
①独热编码对应出来的向量都是很高维的
②独热向量在其编码空间是稀疏的
③独热向量是硬编码的
【希望可以创造出具有以下特点的词编码】
①低维的
②密集
③基于数据的学习
→一种好的方式被称作EBEDDING:也即把高维的稀疏的样本映射到稠密的低维的空间中去【数据降维】
高级篇——RNN classifier
问题描述

问题解决
数据构造
1. 数据流
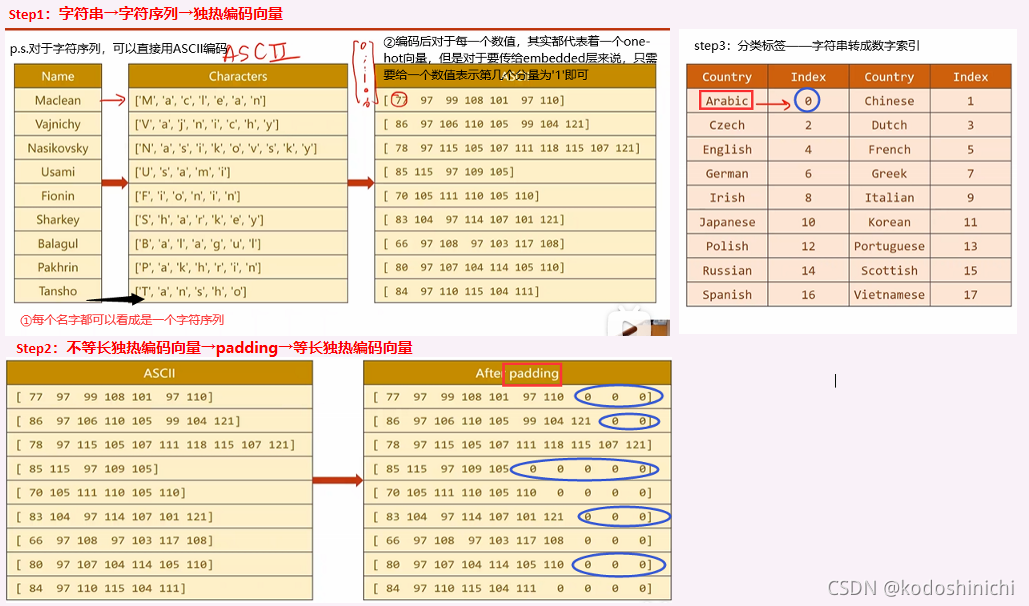
【GRU运行提速】
背景:为了能够将数据规整化,我们之前对不同长度的序列进行了padding操作;但其实在实际计算过程中,全零的padding部分可以不参与计算,以减少计算的开销。
操作:在传入输入数据前先利用函数对数据形式进行处理
gru_input = pack_padded_sequence(embedding,seq_lengths)
- 返回一个PackedSequence对象
- 传入的embedding对象的维度为(seqLen,batchSize,hiddenSize)
- 传入的seq_lengths是一个张量,返回的是每一个batch元素的序列长度
函数的内部处理流程:
- 将数据按照实际的SeqLen降序排序
- 按照batch维度将数据压缩成新的gru_input
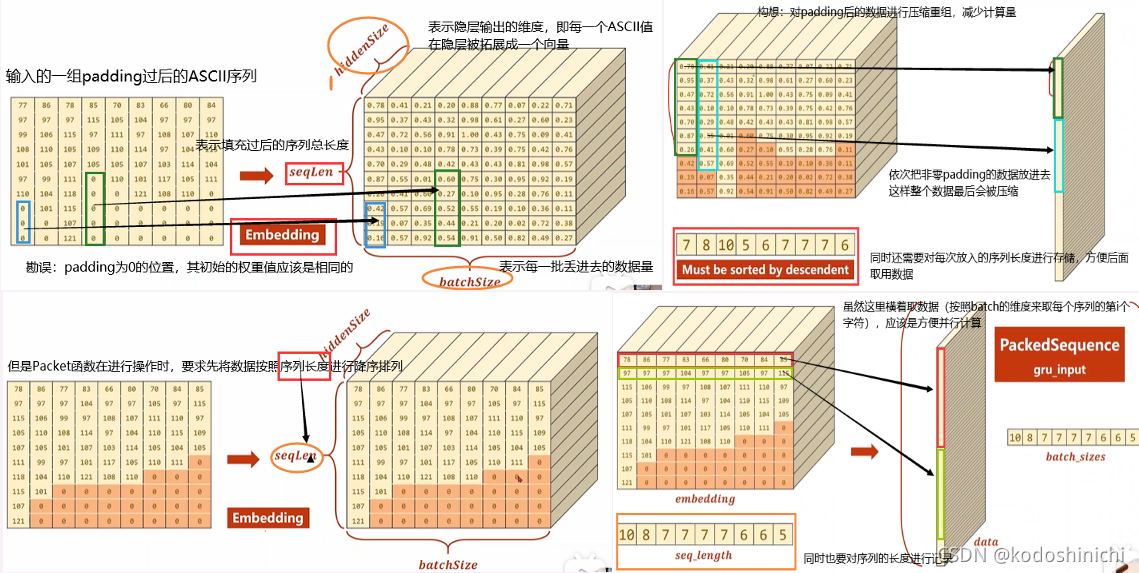
2. 数据维度
3. 代码实现
#定义数据集类
class NameDataset(Dateset):
def __init__(self,is_train_set = True):
filename = '' if is_train_set else ''
with gzip.open(filename,'rt') as f:
reader = csv.reader(f)
rows = list(reader)
self.names = [row[0] for row in rows]
self.len = len(self.names)
self.countries = [row[1] for row in rows]
self.country_list = list(sorted(set(self.countries)))
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list)
def __getitem__(self, index):
return self.names[index],self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict = dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name] = idx
return country_dict
def idx2country(self,index):#给定索引返回国家名
return self.country_list[index]
def getCountriesNum(self):#返回国家数量
return self.country_num
模型结构
1. 图示
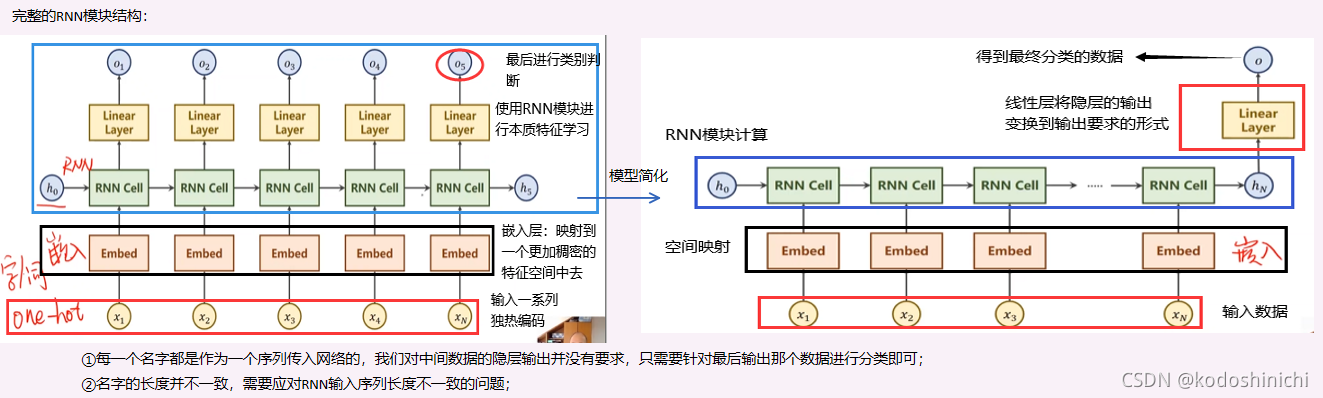
2. 双向时序单元

3. 代码实现
# 定义RNN分类器
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers = 1,bidirectional = True):
super(RNNClassifier,self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size,hidden_size)
self.gru = torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional = bidirectional)
self.fc = torch.nn.Linear = (hidden_size*self.n_directions,output_size)
def _init_hidden(self,batch_size):
hidden = torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
#前向传播过程
def forward(self,input,seq_lengths):
# 输入维度:BXS -> SXB
input = input.t()
batch_size = input.size(1)
hidden = self.init_hidden(batch_size)
embedding = self.embedding(input)
#pack up
gru_input = pack_padded_sequence(embedding,seq_lengths)
output,hidden = self.gru(gru_input,hidden)
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1],hidden[-2]],dim = 1)
else:
hidden_cat = hidden[-1]
fc_output= self.fc(hidden_cat)
return fc_output
def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
def name2list(name):
arr = [ord[c] for c in name]
return arr,len(arr)
def make_tensors(names,countries):#对数据集中的数据进行构造,转换成张量形式
sequences_and_lengths = [name2list(name) for name in names]
name_sequences = [s1[0] for s1 in sequences_and_lengths]
seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_lengths])
countries = countries.long()
#将name字段的数据组装成 BatchSize x SeqLen大小的张量
seq_tensor = torch.zeros(len(name_sequences),seq_lengths.max()).long()
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)#此处将所有字段都padding成最大长度
#先确定整个数据的维度,初始化为零,再逐一对有效数据位的数据进行填充
#使用pack_padded_sequence方法,按照序列长度进行降序排序
seq_lengths,perm_idx = seq_lengths.sort(dim = 0,descending = True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx] #将tensor按照长度排序后,利用返回的下标将名字和国家张量的顺序进行转换
return create_tensor(seq_tensor),\
create_tensor(seq_lengths),\
create_tensor(countries)
计算逻辑
1. 模型训练
【模型训练的常规逻辑】
- forward——compute output of model
- forward——compute loss
- zero grad
- backward
- update
# 模型训练
def trainModel():
total_loss = 0
for i,(names,countries) in enumerate(trainloader,1):
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs,seq_lengths)
loss = criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch}', end='')
print(f'[{i * len(inputs)}]/{len(trainset)}',end = '')
print(f'loss = {total_loss / (i * len(inputs))}')
return total_loss
2. 模型测试
#模型测试
def testModel():
correct = 0
total = len(testset)
print("evaluating train model .....")
with torch.no_grad():
for i,(names,countries) in enumerate(testloader,1):
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim = 1,keepdim = True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%,2f'% (100 * correct / total)
print(f'Test set: Accuracy {correct} / {total} {percent}%')
return correct / total
3. 主过程
# 主过程
if __name__ == '__main':
classifier = RNNClassifier(N_CHARS,HIDDE_SIZE,N_COUNTRY,N_LAYER)
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(),lr = 0.001)
start = time.time()
print("Training for %d epochs..."% N_EPOCHS)
acc_list = []
for epoch in range(1,N_EPOCHS+1):
trainModel()
acc = testModel()
acc_list.append(acc)
EX:Sentiment Analysis on Movie Reviews
问题要求
问题解决
先把代码实现欠在这儿,过段时间补上















 2344
2344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









