






背景:
hadoop集群服务崩溃,无法集群模式执行Mapreduce任务。
目标:
迅速修复业务服务,(立刻!!!)让任务重新执行起来。
临时方案:
目录
背景:Mapreduce集群服务崩溃
目标:紧急恢复服务
临时方案:采用Local模式
问题1:MapTask并行度,默认为1
优化1:增加Local模式下,MapTask并行度
问题2:ReduceTask拉取数据线程数,默认为1
问题3:ReduceTask并行度,默认为1
优化3:增加Local模式下,ReduceTask并行度
由于处理的数据量不大,采用Local或者伪分布式(单机器)执行Mapreduce任务。(这里我选择Local模式)
问题1
潜在问题1:Local模式下,默认所有MapTask交给含有一个线程的线程池执行,无法真正并行,效率低下。
源码解析:org.apache.hadoop.mapred.LocalJobRunner
protected synchronized ExecutorService createMapExecutor() {
// Determine the size of the thread pool to use
// 这里就是获取配置的Local能同时处理的最大map数
int maxMapThreads = job.getInt(LOCAL_MAX_MAPS, 1);
if (maxMapThreads < 1) {
throw new IllegalArgumentException(
"Configured " + LOCAL_MAX_MAPS + " must be >= 1");
}
maxMapThreads = Math.min(maxMapThreads, this.numMapTasks);
maxMapThreads = Math.max(maxMapThreads, 1); // In case of no tasks.
LOG.debug("Starting mapper thread pool executor.");
LOG.debug("Max local threads: " + maxMapThreads);
LOG.debug("Map tasks to process: " + this.numMapTasks);
// Create a new executor service to drain the work queue.
ThreadFactory tf = new ThreadFactoryBuilder()
.setNameFormat("LocalJobRunner Map Task Executor #%d")
.build();
// 创建线程池
ExecutorService executor = HadoopExecutors.newFixedThreadPool(
maxMapThreads, tf);
return executor;
}优化1
修改conf.set("mapreduce.local.map.tasks.maximum", "cpu核数"),增加线程池的线程数。
准备了两个txt文件(只有几KB)进行wordcount测试,默认使用TextInputFormat进行数据读取与切片,两个文件会产生两个MapTask。
测试代码:WordCount.java(包含了job提交、Mapper、Reduce)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
// Mapper 类
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// 打印线程id
System.out.println(Thread.currentThread()+" 线程id:"+Thread.currentThread().getId());
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one); // 输出键值对 (单词, 1)
}
}
}
// Reducer 类
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// 打印线程id
System.out.println(Thread.currentThread()+" 线程id:"+Thread.currentThread().getId());
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); // 输出键值对 (单词, 总次数)
}
}
// 主函数
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 本地模式关键配置
conf.set("fs.defaultFS", "file:///"); // 使用本地文件系统
conf.set("mapreduce.framework.name", "local"); // 本地模式
// conf.set("mapreduce.local.map.tasks.maximum", "2");
Job job = Job.getInstance(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class); // 可选:Combiner优化
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 输入输出路径(使用绝对路径)
FileInputFormat.addInputPath(job, new Path("E:\\study\\projects\\mapreduce\\src\\main\\resources\\input")); // 输入目录
FileOutputFormat.setOutputPath(job, new Path("E:\\study\\projects\\mapreduce\\src\\main\\resources\\output")); // 输出目录
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
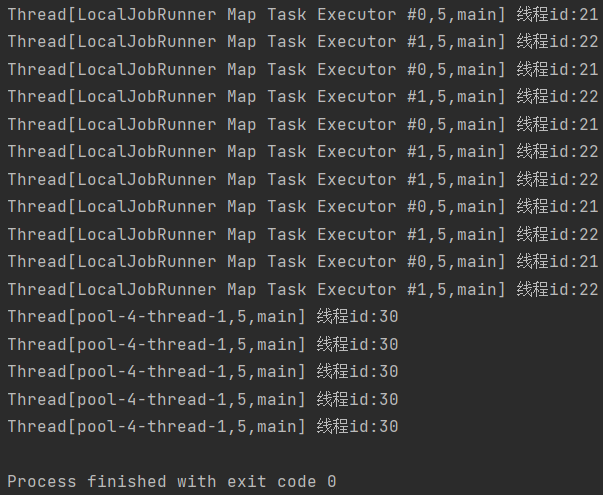
}设置conf.set("mapreduce.local.map.tasks.maximum", "2")前

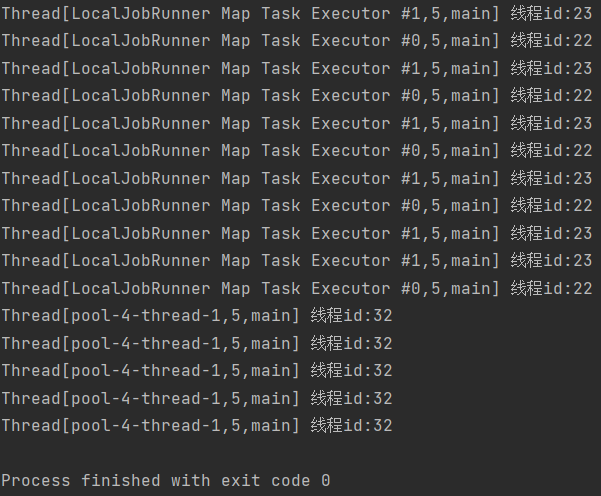
设置conf.set("mapreduce.local.map.tasks.maximum", "2")后
问题2
潜在问题2:Local模式下,shuffle过程中,reduce拉取数据时,只使用一个线程。
源码解析:org.apache.hadoop.mapreduce.task.reduce.Shuffle
// Start the map-output fetcher threads
boolean isLocal = localMapFiles != null;
// Local模式只是用一个Fetcher
final int numFetchers = isLocal ? 1 :
jobConf.getInt(MRJobConfig.SHUFFLE_PARALLEL_COPIES, 5);
Fetcher<K, V>[] fetchers = new Fetcher[numFetchers];
if (isLocal) {
fetchers[0] = new LocalFetcher<K, V>(jobConf, reduceId, scheduler,
merger, reporter, metrics, this, reduceTask.getShuffleSecret(),
localMapFiles);
fetchers[0].start();
} else {
for (int i=0; i < numFetchers; ++i) {
fetchers[i] = new Fetcher<K, V>(jobConf, reduceId, scheduler, merger,
reporter, metrics, this,
reduceTask.getShuffleSecret());
fetchers[i].start();
}
}问题3
潜在问题3:Local模式下,所有ReduceTask交给一个线程处理,效率低下。
源码解析:org.apache.hadoop.mapred.LocalJobRunner
protected synchronized ExecutorService createReduceExecutor() {
// Determine the size of the thread pool to use
// 获取Local模式下Reduce最大并行度参数
int maxReduceThreads = job.getInt(LOCAL_MAX_REDUCES, 1);
if (maxReduceThreads < 1) {
throw new IllegalArgumentException(
"Configured " + LOCAL_MAX_REDUCES + " must be >= 1");
}
maxReduceThreads = Math.min(maxReduceThreads, this.numReduceTasks);
maxReduceThreads = Math.max(maxReduceThreads, 1); // In case of no tasks.
LOG.debug("Starting reduce thread pool executor.");
LOG.debug("Max local threads: " + maxReduceThreads);
LOG.debug("Reduce tasks to process: " + this.numReduceTasks);
// Create a new executor service to drain the work queue.
// 创建处理ReduceTask的线程池
ExecutorService executor = HadoopExecutors.newFixedThreadPool(
maxReduceThreads);
return executor;
}优化3
针对问题3,修改conf.set("mapreduce.local.reduce.tasks.maximum", "2"),增加线程池的线程数。
测试代码,增加了一个分区器,可以得到2个Partition
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
// 自定义分区器
public static class CustomPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// 如果key以"1"开头,分配到分区1;否则分配到分区2
return key.toString().startsWith("1") ? 1 : 0;
}
}
// Mapper 类
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
System.out.println(Thread.currentThread()+" 线程id:"+Thread.currentThread().getId());
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one); // 输出键值对 (单词, 1)
}
}
}
// Reducer 类
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
System.out.println(Thread.currentThread()+" 线程id:"+Thread.currentThread().getId());
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); // 输出键值对 (单词, 总次数)
}
}
// 主函数
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 本地模式关键配置
conf.set("fs.defaultFS", "file:///"); // 使用本地文件系统
conf.set("mapreduce.framework.name", "local"); // 本地模式
conf.set("mapreduce.local.map.tasks.maximum", "2");
// conf.set("mapreduce.local.reduce.tasks.maximum", "2");
Job job = Job.getInstance(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class); // 可选:Combiner优化
job.setReducerClass(IntSumReducer.class);
job.setPartitionerClass(CustomPartitioner.class); // 设置自定义分区器
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2); // 必须设置为2,因为分区器返回0或1
// 输入输出路径(使用绝对路径)
FileInputFormat.addInputPath(job, new Path("E:\\study\\projects\\mapreduce\\src\\main\\resources\\input")); // 输入目录
FileOutputFormat.setOutputPath(job, new Path("E:\\study\\projects\\mapreduce\\src\\main\\resources\\output")); // 输出目录
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
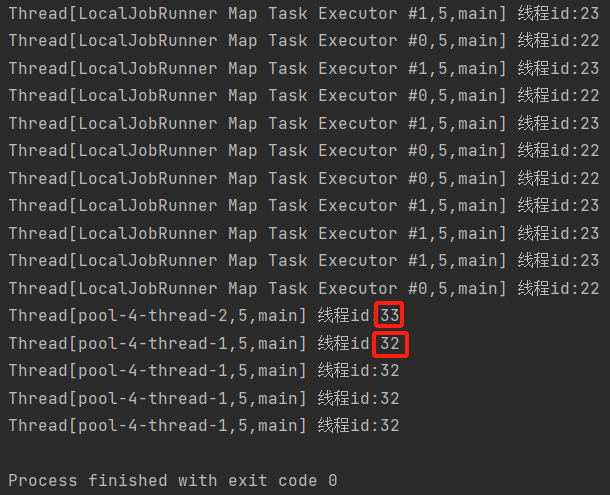
}设置conf.set("mapreduce.local.reduce.tasks.maximum", "2")前
设置conf.set("mapreduce.local.reduce.tasks.maximum", "2")后

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









