






Policy Gradients
- Q learning学习奖惩值, 根据自己认为的高价值选行为, Policy Gradients不通过分析奖励值, 直接输出行为的方法
- 最大好处就是, 它能在一个连续区间内挑选动作, 而基于值的, 如 Q-learning, 做不到
Policy Gradients的反向传递
- 没有误差反向传递
- 反向传递目的是让这次被选中的行为更有可能在下次发生. 通过reward 奖惩来决定被增加被选的概率
核心思想
-
也是靠奖励来左右神经网络反向传递.
-
观测的信息通过神经网络分析, 选出了①行为, 直接进行反向传递, 使之下次被选的可能性增加,根据奖惩信息,如果行为好增加动作可能性增加的幅度 ,不好则减低
算法
不像 Value-based 方法 (Q learning, Sarsa), 但他也要接受环境信息 (observation), 不同的是他要输出不是 action 的 value, 而是具体的那一个 action, policy gradient 跳过了 value 这个阶段
- 第一个算法是一种基于 整条回合数据 的更新

更新神经网络参数时: - 更新参数依据先往这个方向更新,根据Vt判断方向是否正确,如果正确,则在这个方向幅度大一点;Vt不好幅度小一点,下次选中的概率略微少一点
- log形式的概率是为了更好地收敛性
- 以回合为基础,回合完了一次性更新(Qlearning单步更新)
代码结构

建立 policy 神经网络
- 第一层建立全连接层
- 第二层输出所有action
- 将每个输出的值转换成概率
- 计算误差(policy 是没有误差的)此处‘loss’是指反向传递后,使下一次选择这个动作的概率的增加一点乘以增加的幅度
self.all_act_prob = tf.nn.softmax(all_act, name='act_prob') # 激励函数 softmax 出概率
with tf.name_scope('loss'):
# 最大化 总体 reward (log_p * R) 就是在最小化 -(log_p * R), 而 tf 的功能里只有最小化 loss
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # 所选 action 的概率 -log 值
# 下面的方式是一样的:
# neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # (vt = 本reward + 衰减的未来reward) 引导参数的梯度下降
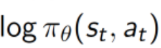 tf.log(self.all_act_prob),all_act_prob所有action的概率
tf.log(self.all_act_prob),all_act_prob所有action的概率- 放到记忆库中action是单个单个的值,如第0个action,放到记忆库中是0,第一个action放到记忆库中是1,。。。如果要进行如上的计算,最好变成矩阵的形式与概率tf.log(self.all_act_prob)相乘,one_hot(self.tf_acts, self.n_actions)采取action为1(没有采取为0)与相乘,筛选出采取了哪个对应action的概率
- 负号 因为Tensorflow只能最小化loss。因为是想要得到奖励概率越来越大所以用负号将minimize换成max
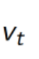
self.tf_vt幅度
选行为
不通过 Q value 来选定的, 而是用概率来选定. 虽然不用epsilon-greedy, 也具有一定的随机性.
def choose_action(self, observation):
prob_weights = self.sess.run(self.all_act_prob, feed_dict={self.tf_obs: observation[np.newaxis, :]}) # 所有 action 的概率
action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # 根据概率来选 action
return action
- np.random.choice()根据概率来产生随机数
存储回合
将这一步的 observation, action, reward 加到列表中去. 因为本回合完毕之后要清空列表, 然后存储下一回合的数据, 所以会在 learn() 当中进行清空列表的动作.
def store_transition(self, s, a, r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
学习
def learn(self):
# 衰减, 并标准化这回合的 reward
discounted_ep_rs_norm = self._discount_and_norm_rewards() # 功能再面
# train on episode
self.sess.run(self.train_op, feed_dict={
self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs]
self.tf_acts: np.array(self.ep_as), # shape=[None, ]
self.tf_vt: discounted_ep_rs_norm, # shape=[None, ]
})
self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # 清空回合 data
return discounted_ep_rs_norm # 返回这一回合的 state-action value
- 将reward处理过程放到train
- 输入observation、action、vt到Tensorflow
- 清空列表用于下一个回合
RL_brain.py
import torch
import torch.nn as nn
import numpy as np
class PolicyGradientNet(nn.Module):
def __init__(self, n_actions, n_features, n_hiddens):
super(PolicyGradientNet, self).__init__()
self.fc1 = nn.Sequential(
nn.Linear(n_features, n_hiddens),
nn.Tanh()
)
self.fc2 = nn.Sequential(
nn.Linear(n_hiddens, n_actions),
nn.Softmax()
)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
class PolicyGradient():
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.95,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.obs = []
self.acs = []
self.rws = []
self.net = PolicyGradientNet(n_actions, n_features, 10)
self.loss = nn.CrossEntropyLoss()
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=learning_rate)
def choose_action(self, observation):
self.net.eval()
actions = self.net(torch.Tensor(observation[np.newaxis, :]))#增加维度
action = np.random.choice(range(actions.shape[1]), p=actions.view(-1).detach().numpy())
return action
#policy gradient是在一个完整的episode结束后才开始训练,因此,在一个episode结束前,
# 要存储这个episode所有的经验,即状态,动作和奖励。
def store_transition(self, s, a, r):
self.obs.append(s)
self.acs.append(a)
self.rws.append(r)
def _discount_and_norm_rewards(self): # 衰减回合的 reward
discount = np.zeros_like(self.rws)#得到处理后的reward列表,为输入到网络中的vt值(统计一个回合的奖励)
# numpy.zeros_like(a)返回一个零矩阵与给定的矩阵相同形状
tmp = 0
for i in reversed(range(len(self.rws))):#reversed()函数是返回序列seq的反向访问的迭代子,
# 如果self.rws列表中存储有5个reward值,长度为5,则这里i取值为43210,倒序是为了可以取未来值计算
# 我们之前存储的奖励是当前状态s采取动作a获得的即时奖励,而当前状态s采取动作a所获得的真实奖励
# 应该是即时奖励加上未来直到episode结束的奖励贴现和。
tmp = tmp * self.gamma + self.rws[i]#计算矩阵平均值
discount[i] = tmp#计算矩阵标准差
#标准化集奖励 对discount 列表进行正则化规约reward值
discount -= np.mean(discount)
discount /= np.std(discount)
return discount
def learn(self):
#给模型的并不是存储的奖励值,而是在经过上一步计算的奖励贴现和。
# 另外,需要在每一次训练之后清空经验池。
self.net.train()
discount = self._discount_and_norm_rewards()#衰减, 并标准化这回合的 reward
output = self.net(torch.Tensor(self.obs))
one_hot = torch.zeros(len(self.acs), self.n_actions).\
scatter_(1, torch.LongTensor(self.acs).view(-1,1), 1)
neg = torch.sum(-torch.log(output) * one_hot, 1)
loss = neg * torch.Tensor(discount)
loss = loss.mean()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.acs = []
self.obs = []
self.rws = []
#vt = 本reward + 衰减的未来reward
return discount
run_CartPole.py
import gym
from RLPolicyG.RL_brain import PolicyGradient
import matplotlib.pyplot as plt
DISPLAY_REWARD_THRESHOLD = 400 # 如果总事件奖励大于此阈值,则呈现环境
RENDER = False # 边训练边显示会拖慢训练速度,我们等程序先学习一段时间
env = gym.make('CartPole-v0')#创建 CardPole这个模拟
env.seed(1) # 创建随机种子
env = env.unwrapped## 取消限制
print('env.action_space',env.action_space)#输出可用的动作
print('env.observation_space',env.observation_space)# 显示可用 state 的 observation
print(env.observation_space.high) # 显示 observation 最高值
print(env.observation_space.low)# 显示 observation 最低值
#主循环
RL = PolicyGradient(
n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],# 状态向量的长度
learning_rate=0.02,
reward_decay=0.99,
# output_graph=True,
)
for i_episode in range(3000):
observation = env.reset() # 获取回合 i_episode 第一个 observation
while True:
if RENDER: env.render() # 因为RENTER为true时,才会显示模拟窗口,否则不需要要刷新界面。环境刷新
action = RL.choose_action(observation) # 选行为
observation_, reward, done, info = env.step(action)# 获取下一个state
RL.store_transition(observation, action, reward)# 存储这一回合的transition
if done: # 一个回合结束,开始更新参数
ep_rs_sum = sum(RL.rws) # 统计每回合的reward
if 'running_reward' not in globals(): #globals() 函数会以字典类型返回当前位置的全部全局变量
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True #判断是否开始模拟
print("episode:", i_episode, " reward:", int(running_reward))
vt = RL.learn()#学习, 输出 vt,即这里是return discounted_ep_rs_norm
if i_episode == 0:
plt.plot(vt) # plot 这个回合的 vt
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
break
observation = observation_
# 一个回合更新一次网络参数,一个回合是指在杆子倒下的一系列动作和状态
# 所以在done之前将一系列动作、状态、奖赏值都存储在列表中,即done前网络中的输入的观测值,只是我当前一条observation
# done后堆叠起来observation输入给NN,进行一次反向传播更新参数















 1756
1756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









