






本篇内容为笔者对ANUSPLINA的学习笔记,以及相关信息,参考了以前许多文档和原文档,最终总结出的最全指南,可以解决除原始数据问题之外的任何问题!可以使用Excel、SPSS、ArcGIS等工具,也可以只是用Python进行处理,任君自行选择。下面就开始吧!
一、预处理数据
1.1 DEM数据
在其他教程中可以很方便的看到处理DEM数据的过程,在本文中只简要介绍。
- 确定目标坐标系(哪个投影坐标系或地理坐标系)和空间分辨率(如1000m或0.05度)
- 获取DEM文件
- 如果DEM的坐标系信息与目标坐标系不同,则可通过ArcGIS中的裁剪栅格、投影转换、重采样或领域的聚合分析(如果为升尺度,如从500m换为1000m,则推荐此方法)工具将DEM文件转换为目标坐标系下的目标范围内的目标空间分辨率文件
- 使用转换工具中的Raster to ASCII转换为对应的txt文件,请选择"TXT"选项以免后面出现莫名错误。
1.2 气象站点数据
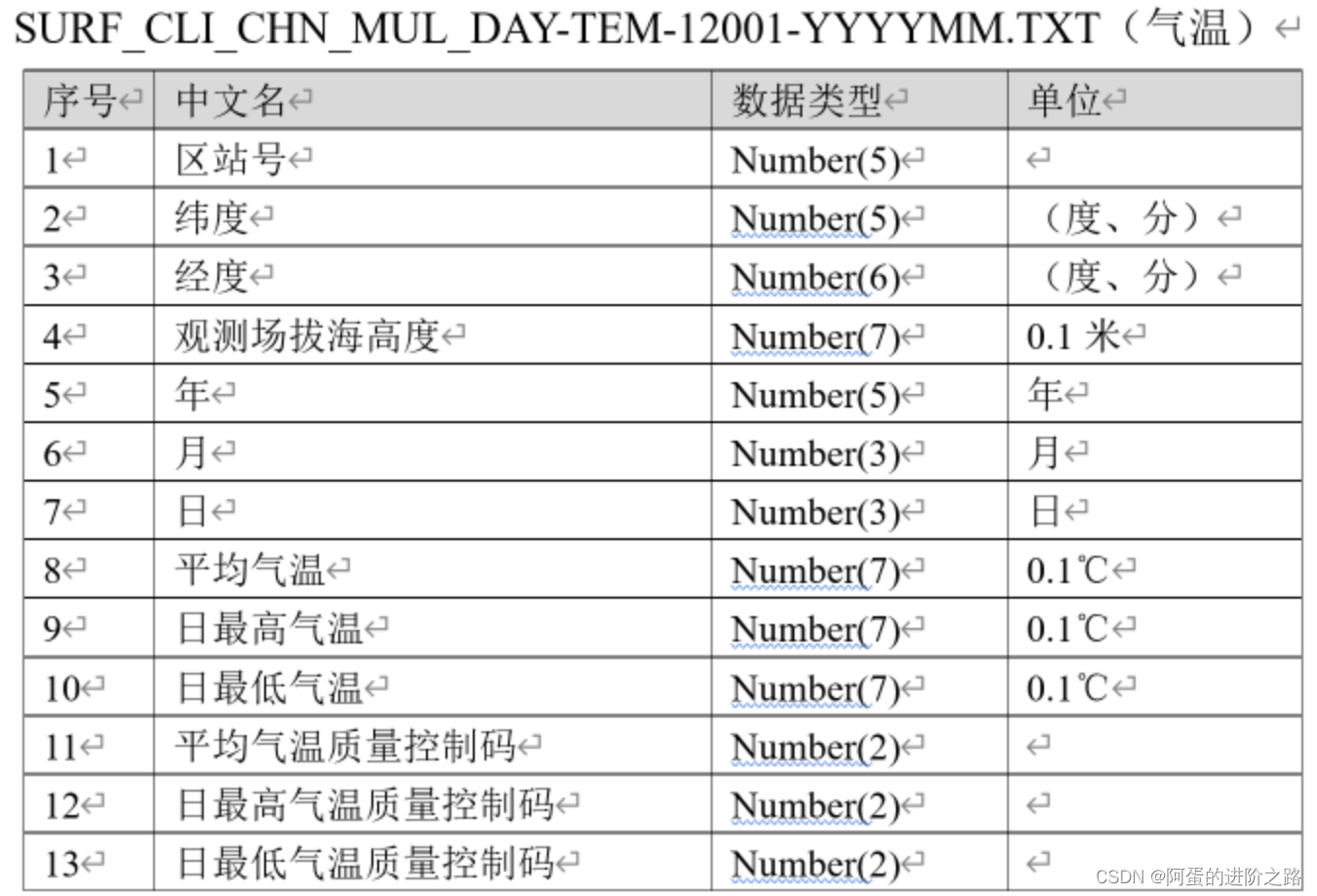
首先,对于任何获取到的数据,应首先观察其元数据,元数据中包含大量说明信息,能够帮助你更快地了解和使用数据。以经典的中国气象站点数据(中国地面气候资料日值数据集(V3.0))为例,在气象数据共享网站官网获取元数据文档(.doc/.docx)。可以看到数据的命名规则,特征值,数据单位等信息。而这些信息对于之后的数据处理和插值至关重要!!

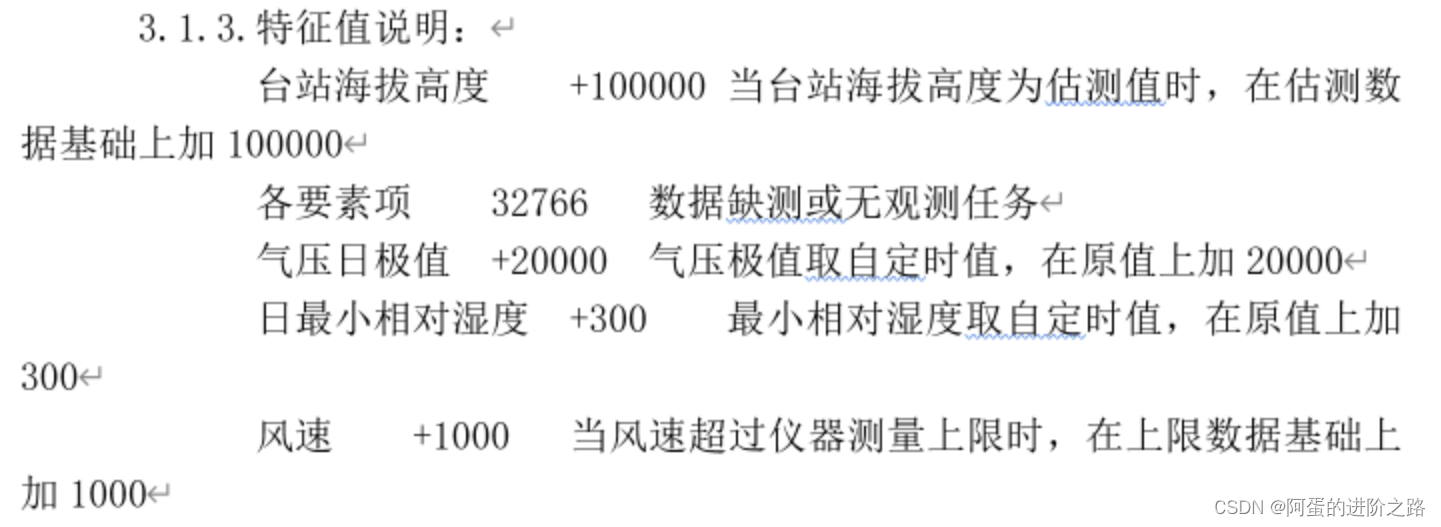

最重要的是类似下面的元数据。例如下图指出了经纬度采用度分为单位,这与ANUSPLIN要求的十进制度单位不同,因此在数据预处理时应完成度分->十进制度的换算!!!!下面将以TEM为例讲解需要完成的预处理操作。
1. 标准化经纬度
在进行经纬度处理时,应将原来的度分结构转为十进制度,逻辑顺序如下:
- 分割:5位或4位经纬度数据中,如11512代表115度12分,应将其首先分割为前3(2)位与后2位。如Excel中将一列数据分割为两列,对应分别为115和12,具体方法可搜索Excel的Right等方法
- 计算:新的经纬度应为原来两列的计算,公式如下,如11512就转换为115.2。
2. 筛选站点号
在进行数据文件内部的预处理之前,应首先基于目标范围筛选已有的站点号,将含有站点号和对应十进制度单位的经纬度表格导出为csv,使用ArcGIS打开,导入处理好的DEM,然后通过空间分析工具-提取工具-值提取至点工具将DEM的高程值赋值给站点。然后打开生成的图层属性表,导出为文本文件(选择TXT格式),这样我们就得到了一个包含插值所用站点以及其可用的高程信息。
3.处理DEM
由于ANUSPLIN要求站点高程应与协变量中的DEM文件相匹配,因此在此不对原始提供的搞成值做处理,但需要计算的可以将其×0.1进行计算。
4.筛选
筛选去除掉有32766的值,或使用内插方法填补,总之,在用来插值前,要保证文本文件中没有空值!!!
同时根据获取的将使用的站点进行筛选,只保留需要的站点(此步骤按理论来说可以省掉,因为源文件说SPLINA会进行一次筛选)
将获取到的站点的高程与含有要素数据的文件中的站点一一对应
5.标准化
需要看需求是否要同时插值n个要素,如果只插值一个时间点的一个要素,则可以按照站点号、经度、纬度、高程、数值的列来进行标准化存储文本文档,该过程可以使用SPSS,流程可参照其他博客,都讲的很详细,在此不再赘述,给出一个python的解决方案。
假设经过处理后的原始要素数据在第5列或从第5列开始,其他列可以自行更改
如果要是同时插值多个要素,则将4:5变为对应的列如4:7(3个要素)
import pandas and pd
data=pd.read_csv(yourfilepath)
formatted_df['station'] = data['station'].apply(lambda x: f"{int(x):5}")
formatted_df['X'] = data['X'].apply(lambda x: f"{x:15.6f}")
formatted_df['Y'] = data['Y'].apply(lambda x: f"{x:15.6f}")
formatted_df['DEM'] = data['DEM'].apply(lambda x: f"{x:10.2f}")
formatted_df.iloc[:, 4:5] = data.iloc[:, 4:5].applymap(lambda x:f"{x:15.6f}")
combined_rows = formatted_df.apply(lambda row: ''.join(row), axis=1)
with open(youroutfilepath, 'w') as file:
for row in combined_rows:
file.write(row + '\n') # Adding a new line for each row这里要注意的是,并非采取分隔符的形式存储,而是格式化字符串,因此需要记住这里的格式化方式,如上述代码中使用的则是整数5、2个浮点15.6(长度为15位,保留6位小数)、浮点10.2、浮点15.6的格式,提前准备好后面需要的字符串即为
(a5,2f15.6,f10.2,f15.6)其中a代表整数,f代表浮点数,字母后面跟的数字为对应的位数(精确度),字母前面的数字代表从左到右连续相同格式的列数,没有即为1,中间用逗号隔开。
1.3 配置文件
1.3.1 SPLINA.cmd
InterpoName #输出表名称,基本没有什么用
5 #插值的单位,0表示无单位,常用的有1或者5,1代表米,5代表十进制度
2 #自变量的个数,这里指经纬度
1 #协变量的个数,这里指dem,注意也可以将高程设置为自变量,但常用的都是协变量,可以直接用不用改
0
0
90 100 0 1 0.01 ##前两数是要生成的表面文件的经度范围,程序会根据此筛选站点以生成SUR
40 50 0 1 0.01 ##同上,可以大于DEM文件范围,也可以等于DEM范围
-400 8000 1 1 0.01 ##前两数请大于dem文件的上下限,注意这三个0.01分别为对应的分辨率
0.0001 ##dem单位转换,当前面填了第五个辅助信息后,这行就没用了,前面每行只有四个数字的话这行有用
0
2
1 ##需要插值的个数。如为批量插值,则为对应的数量
0
1
1
hktem.dat ## 处理好的插值文本文件
50 ##站点的个数,可以设置的比实际站点数量大些
5 #站点标签的长度
(a5,2f15.6,f10.2,f15.6) #数据的格式,用之前准备的放到这里。如为批量插值,最后的f15.6可写nf15.6
hktem.res
hktem.opt
hktem.sur
hktem.lis
hktem.cov
#空6行
1.3.2 LAPGRD.cmd
splina.sur #sur文件地址
0 #若是1个设置为1,若是多个设置为0
1
splina.cov #cov文件地址
2
1 #网格采样位置:像元中心
1
91 100 0.01 #输出的grd范围,要与dem一致,而且要在sur的经纬度范围内,
2
35 40 0.01 #接上,否则会报错INCOMPATIBLE NCOLS或LIMITS EXCEED SURFACE COORDINATE LIMITS
0 #掩膜文件:无
2
dem_res0.txt #dem转出的ASCII文本文件地址
2 #输出的栅格格式:ARC/INFO GRID
-9999
2000TEM.grd #输出的ARCINFO文件名字,若多个跑,则每行一个名字分多行来写,结束后用空行与下面分隔
2 #误差文件表面格式
-9999.0 #空值数据
2000TEMstd.grd #标准差文件,后面空6行
使用时请将#号即后面的都删除掉
新建文本文档,将内容分别粘贴进去并按需修改,保存后将txt的后缀名改为cmd,有的人没有打开后缀名显示,可以先搜一下如何打开后缀名显示。
新建一个run.cmd文件并写入下面的内容,然后将以上所有文件以及程序文件splina.exe和lapgrd.exe都放到一个文件夹里,双击run.cmd运行就可以了。
splina<SPLINA.cmd>splina.log
lapgrd<LAPGRD.cmd>lapgrd.log三、一个小技巧
当程序中遇到错误的时候,假设使用者懂英文或者会使用翻译软件,请首先查看对应的.log文件,由于上述两个程序是逐行执行.cmd配置文件,因此遇到错误的时候会卡住,即卡在对应的位置上不会在.log文件中全部显示,查看报错信息以及对应位置后便可基本了解对应的错误发生在什么地方。
四、说在后面的话
笔者已经使用开头所提到的数据进行了国家尺度的插值,开发了一套代码用来进行快速批量插值(数量2W+),也可以提供有偿的按需插值帮助或速度更快的代插值服务,可以私信(不定期上线回复较慢)或闲鱼搜索用户"宝保包饱爆"私信,24h回复率100%。

















 2082
2082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









