







初识推荐系统
1、推荐算法
基于人口统计的推荐
基于内容的推荐
根据物品的元数据
基于协同过滤的推荐
pass
吐槽一下:店小二要学会察言观色!
2、推荐系统能做什么
where when how what who
在合适的场景,合适的时间,通过合适的渠道,把合适的内容,推荐给合适的人。
吐槽一下:让客官购买合适的商品!
3、推荐系统作用
通过
1、提升用户忠诚度、用户粘性
增加
2、提升销售额、长尾销售
最终
3、提升毛利
吐槽一下:客官请留步,客官请刷卡!
4、推荐系统任务
1、评分预测(Rating Prediction)
2、Top-N 推荐(Top-N Recommendation)
吐槽一下:预测出客官喜欢的内容、商品,赚钱赚钱赚钱!!!
5、什么是好的推荐系统
交互和设计角度 40%
数据的角度 30%
领域知识的角度 20%
模型的角度 10%
吐槽一下:这个店小二会来事!
6、什么时候需要推荐系统
信息过载
留存了大量的用户、物品信息,并且无法做完整展现。
足够反馈
用户对物品的交互信息,浏览、点击量等。
搜索无法解决的
搜索引擎 vs 推荐系统
吐槽一下:老板,这活儿没法干了。
7、数据-显示反馈
赞👍 踩👎
问题:样本少、评分不靠谱
8、数据-隐式反馈
浏览、点击、购买、收藏
吐槽一下:客官干了啥,老板一清二楚!
选择参考
订单、待付款订单、心愿清单加购、搜索、收藏、评分、分享、悬停浏览、快速预览
优先级:高到低
数据量:少到多

吐槽一下:比客官更了解他自己!
深入理解推荐系统
推荐系统:解决信息量过载的问题,从海量的数据中挖掘有价值的数据信息。
个性化推荐:根据用户的兴趣特点和行为,向用户推荐用户感兴趣的信息。
9、体系架构
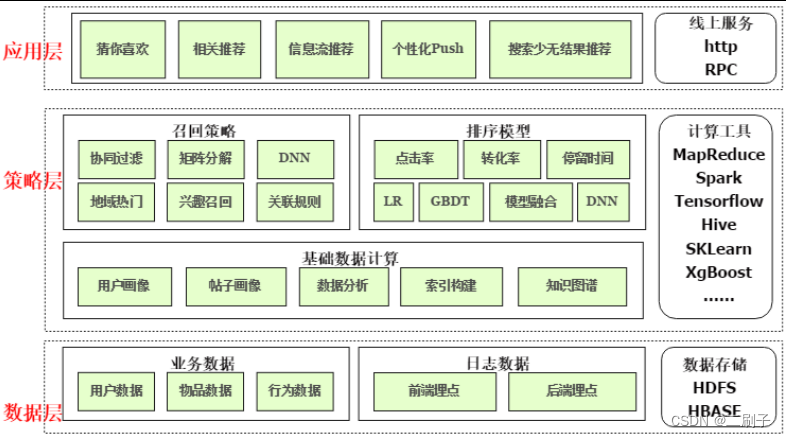
推荐规则
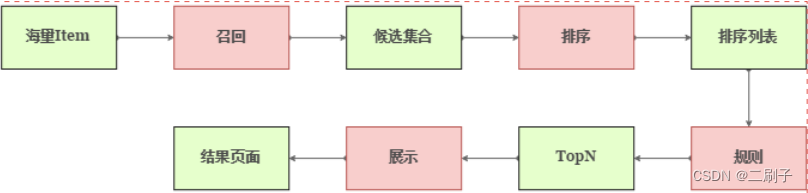
召回:筛选出用户感兴趣的大量商品
排序:对商品列表打分排序
规则:通常是过滤规则,去重、业务过滤(比如明确不喜欢的)
技术处理
Offline 层:海量数据离线处理,如MapReduce、Spark
Nearline层:实时数据流式处理,如Storm、SparkStreaming
Online 层:运算逻辑在线计算,如:在线引擎
问题
1、用户通过搜索,推荐系统如何从上亿商品秒级反馈展示对应搜索数据?
通过推荐系统
DAU:每天活跃的用户,MAU:每月活跃的用户
10、处理架构
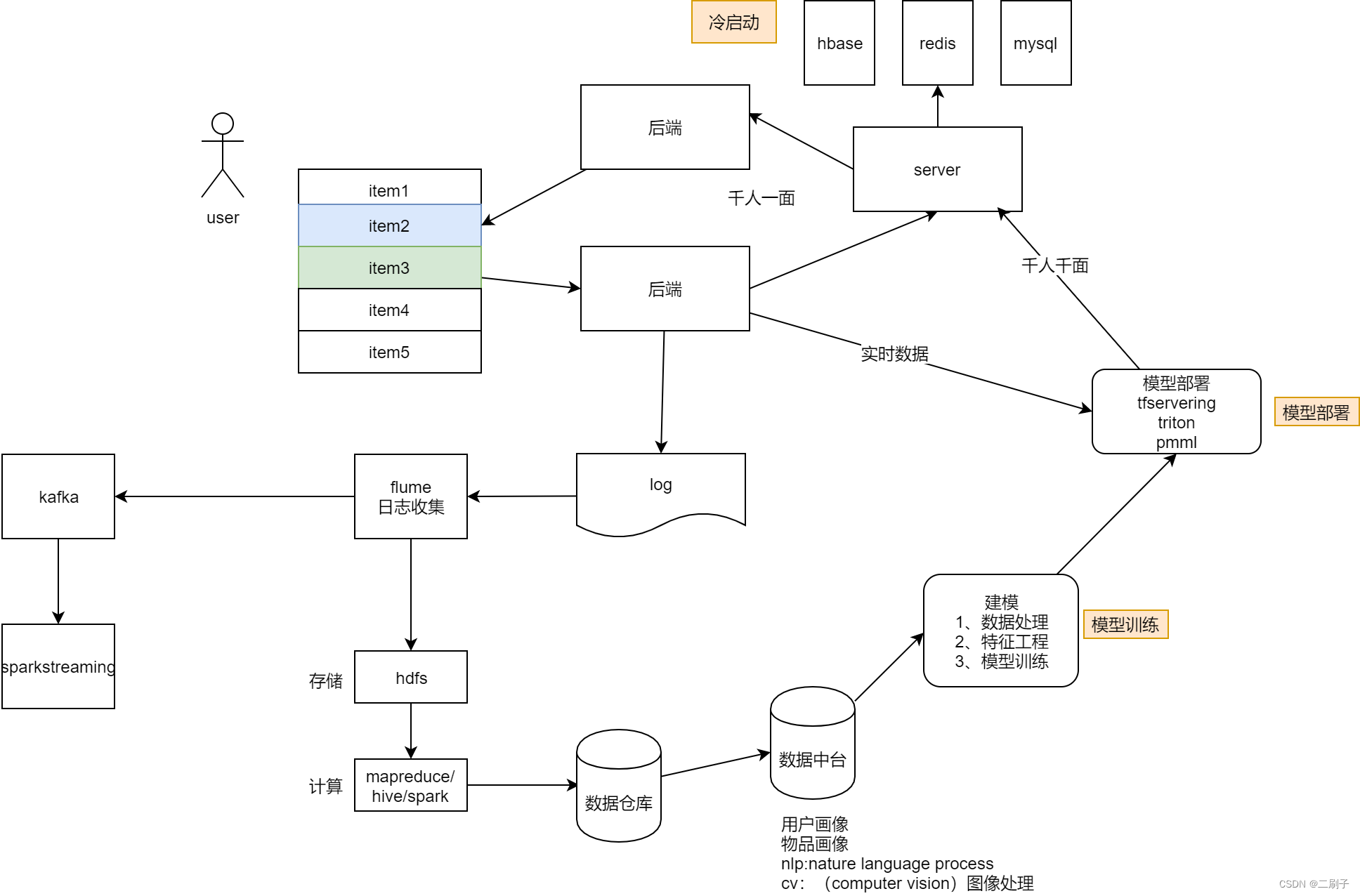
11、模型
f(uid, itemid,exp_time) = score
训练过程
f(uid,itemid,exp_time) = a * uid + b * itemid + c*expitme + d
参数:a b c d 是未知的,需要被不断的训练出来
阈值
真实的数据带入模型,计算阈值。
>= 0.5 lable=1
< 0.5 lable=0
模型调参、超参
待补充
假设模型训练好了:
f(uid, itemid, exp_time) = 0.45 * u1 + 0.234 * i1 + 0.453 *e1 + 0.121
12、目的
在合适的时间合适的场景给合适的用户推荐合适的商品。
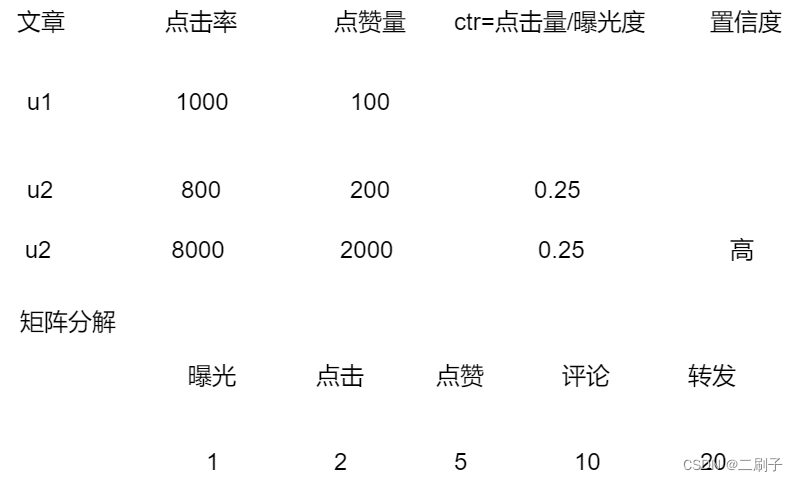
协同过滤认识
召回:从海量物品中筛选出用户可能感兴趣的物品。粗粒度的筛选。
排序:从用户召回的结果中对物品重新排序,细粒度的筛选。
归一化:解决标准不一致产生的偏差。















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









