








项目是串联知识点的最好的方式,这个项目之前看过,但是笔记并没有整理,并且环境已经破坏.由于项目二的需要,需要将这个项目进行重新搭建,对于之前的知识点使用这个项目进行重新复习.---最后一次搭建这个项目环境,供给后面使用,步步为营
目录
一. 数仓的基本概念

不要那么多的名词,直接是用来存取 管理数据的,进而对相应的数据进行分析处理 计算.数据仓库不是数据的最终目的,而是为数据最终的目的做好准备.得到相应的数据结果,使用数据进行分析,将使用企业的决策进行数据支持.
报表系统:BI,商业智能.
二. 数仓基本架构

三. 项目需求分析
A. 项目需求:
1.用户行为数据采集平台搭建
2.业务数据采集平台搭建
3.数据仓库维度建模
4.分析,设备 会员 商品 地区 活动等电商核心主题进行分析,统计报表指标大概是100个,完成相应的对比.(哈哈哈,写SQL写到吐)
5.采用即席查询工具,进行随时指标分析.
6.对于集群性能进行监控,发生异常需要进行报警.(发个短信或者打个电话,类似与运维的东西)
7.元数据的管理(管理hive的数据)
8.质量监控(监控数据分析的质量)
B. 思考
1.项目技术如何选型?
2.框架的版本是如何进行相应的选择?
3.服务器是选择物理机还是云服务器?
4.如何确定相应的云规模?
四. 用户行为_项目架构_技术选型
技术选型主要考虑的一些因素:数据量的大小 业务需求 行业内经验 技术成熟度 开发维护成本 总成本预算
上面展示的红色的东西就是基本一套东西要使用的.
数据传输:这里为什么我们要选择Flume(Hadoop),不选择Logstash(ELK),二者的技术栈是不一样的.Sqoop和DataX是差不多的,Sqoop是完全开源的,DataX是阿里的比较强大的,我们这里用不到那么强大的功能的,因此,我们使用的是Sqoop.
数据存储:HBase Redis MongoDB属于的是NoSQL数据库,它们在离线的数据库之中是用不着的,一般是在相应的实时数据库之中使用,效率很高.
数据计算:基于Hive的Tez Spark等等.Spark Flink Storm是支持实时处理的.
数据查询:暂时先不多说,因为这里没学,哈哈哈哈,听不懂
数据可视化:就是什么饼状图 柱形图什么的,百度的Echars,阿里的DataV.Superset是完全开源的,使用它.
任务调度:Azkaban是属于Apache生态的,Oozie是属于CDH生态.
五. 框架版本选型
A. 如何选择Apache/CDH/HDP版本?
(1)Apache:运维麻烦,组件间兼容性需要自己调研.(一般是大厂使用,技术实力雄厚)
(2)CDH:国内使用的是最多的,但是CM不是开源的,开始收费了,一个节点一万美元.[花点钱就直接办了]
(3)HDP:开源,可以进行二次开发,没有CDH稳定,国内使用是比较少的.
B. 具体框架的版本号
上面的版本号是已经进行调研过之后进行使用的.
六. 服务器选型
服务器选择物理机还是云主机?
1)物理机:
128G内存,20核物理CPU,40线程,8THDD和2TSSD硬盘,戴尔单台报价大约是4W.由于老化,一般的物理机是使用5年左右.
需要有相应的运维人员,平均是1个月1W,电费也是不少的开销.(专业的机房,无尘 恒温 防震)
2)云主机:
云主机:以阿里云为例,差不多的配置,每年5W,买服务
很多的运维工作都是由阿里云完成的,运维是比较简单的
3)企业选择
金融有钱的公司和阿里云没有冲突的,直接选择阿里云
中小公司 为了融资上市,选择阿里云,拉到融资后买物理机
长期打算,资金充足,选择物理机
七. 集群规模
瞎买?咋可能.
1) 如何确定集群规模?(假设:每台服务器8T磁盘,128G内存)
(1)每天日活跃用户100万,每人一天平均100条:100万*100条=1亿条
(2)每条日志1K左右,每天是一亿条:100000000/1024/1024=约100G
(3)半年内不扩容:100G*180天=约18T
(4)保存三个副本:18T*3=54T
(5)预留20%-30%Buf=54T/0.7=77T
(6)约8T*10台服务器
2) 考虑数仓分层?数据压缩?需要重新进行计算.
3) 集群规划
测试集群服务器规划
| 服务名称 | 子服务 | 服务器 hadoop102 | 服务器 hadoop103 | 服务器 hadoop104 |
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka) | Flume | √ | ||
| Hive | Hive | √ | ||
| MySQL | MySQL | √ | ||
| Sqoop | Sqoop | √ | ||
| Presto | Coordinator | √ | ||
| Worker | √ | √ | ||
| Azkaban | AzkabanWebServer | √ | ||
| AzkabanExecutorServer | √ | |||
| Druid | Druid | √ | √ | √ |
| Kylin | √ | |||
| Hbase | HMaster | √ | ||
| HRegionServer | √ | √ | √ | |
| Superset | √ | |||
| Atlas | √ | |||
| Solr | Jar | √ | ||
| 服务数总计 | 18 | 9 | 9 |
八. 系统数据流程设计

业务数据: 登陆 下订单 支付
用户行为数据:埋点操作采集数据
Nginx:是用来做负载均衡的,就是将相应的请求进行分配.
这里的上游的Flume可以直接给到HDFS,但是为什么没有这么做,使用Kafka做一层缓冲,减低HDFS的压力.并且Kafka可以做到实时处理这个数据.
我们一般是在SpringBoot后面开始进行操作,前面一般是相应的前端 后端程序员进行操作的.
九. 数据生成模块_目标数据
收集和分析的数据主要包括页面数据 事件数据 曝光数据 启动数据和错误数据.
A. 页面
页面数据主要记录的是一个页面的用户访问的情况,包括访问时间 停留时间 页面路径等信息.
如上图所示,是京东的一个界面,其中的跳入时间进行记录的是毫秒值.
B. 事件数据
事件数据主要进行记录的是应用内一个具体的操作行为,包括操作类型 操作对象 操作对象描述等信息.
C. 曝光
曝光数据主要记录的是页面所曝光的内容,包括曝光对象 曝光类型等信息.
D. 启动
启动数据记录应用的启动信息.
E. 错误
错误数据记录应用使用过程中的错误信息,包括错误编号及错误信息.
十. 主流埋点方式(了解即可)
埋点方式有代码埋点(前端/后端) 可视化埋点 全埋点三种.这里就是一个代码包,放到相应的触发地方,当在使用点击的时候,就会发送到后面的数据之中.
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。(一般是存在两个页面,通过两个页面的交互配置需要的信息)
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。(所有的用户行为都是会进行采集的,但是这里我们采集的数据并不是我们都想要的)
上述的可视化埋点和全埋点一般是直接使用第三方的东西就是可以的,比如说什么神策大数据 GrowingIO等等.
比如说一个前端进行使用的一个过程.代码是如下所示:
<!DOCTYPE html>
<html>
<head>
<title></title>
<script type="text/javascript">
function clickbutton(){
//alert("是谁在点我");
//采集数据,发给日志服务器
var searchValue = document.getElementById('search').value ;
//alert("搜索了 " + searchValue);
window.location.href= "http:www.baidu.com"
}
</script>
</head>
<body>
第一个HTML页面
<br/>
<input type="text" id="search" />
<input type="button" value="搜索" onclick="clickbutton();"/>
</body>
</html>上面的clickbutton()是进行一个埋点过程的一个事件,使用这个事件进行相应的埋点,返回到自己想要得到的东西.上述代码是一个比较简单的前端界面,它的界面是如下所示:

上述就是一个最简单进行一个埋点的过程.
十一. 埋点数据日志结构
日志结构大致是分为两类的:一类是普通页面的埋点日志,另一类是启动日志.
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的common字段。
1) 普通页面埋点日志格式(JSON格式)
{
"common": { -- 公共信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"is_new": "1",--是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [ --动作(事件)
{
"action_id": "favor_add", --动作id
"item": "3", --目标id
"item_type": "sku_id", --目标类型
"ts": 1585744376605 --动作时间戳
}
],
"displays": [
{
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1, --出现顺序
"pos_id": 2 --曝光位置
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2,
"pos_id": 1
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3,
"pos_id": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4,
"pos_id": 2
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5,
"pos_id": 1
}
],
"page": { --页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面ID
"sourceType": "promotion" -- 来源类型
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}2)启动日志格式
启动日志相对于比较简单,主要是包含相应的公共信息,启动信息和错误信息.
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"is_new": "1",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}十二. 埋点数据的上报时机
埋点数据上报时机包括两种方式。
方式一,在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
方式二,每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大。
我们最终采用的是第一种方式进行相应的操作,统一进行相应的上报操作.
开始写代码啦
十三. 准备3台服务器(重新搭建服务器)
1)首先是对于模板机进行一个复制,复制三台机器,得到相应的机器.
#ifconfig 查看是否进行配置成功
#vim /etc/hosts 修改相应的映射
#systemctl status firewalld 查看防火墙状态
#systemctl is-enable firewalld 查看防火墙的自启动
#id atguigu 配置好了
#vim /etc/sudoers 
#ll 查看相应的目录 
也就是说,这里我们只有相应的机器的名字和一个配置没有进行相应的更改
#vim /etc/hostname
#vim /etc/sysconfig/network-scripts/ifcfg-ens33
这里地方相应的配置是需要根据自己的电脑进行配置的,自己进行相应的分配与更改.
这个地方如果要是配置错误的时候,一般情况问题是存在与下面的两个位置(根据我的经验,因为我这里是这个地方配置错了)#vim /etc/hosts #vim /etc/sysconfig/network-scripts/ifcfg-ens33
2)想要更加快速的使用xshell进行连接
$ sudo vim /etc/ssh/sshd_config ------ /DNS(进行搜索) ------ 改成如下所示(将DNS解析改为no):
之后重新启动sshd这个服务$ sudo systemctl restart sshd.(到这里就是将三个机器已经搭配好了)
十四. 分发脚本_免密登陆
1)分发脚本
在hadoop1002的根目录下面,直接创建一个bin目录,$ mkdir bin,,进入bin目录,$ cd /bin,$vim xsync.sh,创建相应的分发脚本的代码,如下所示:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop1003 hadoop1004
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done修改分发脚本的权限,$chmod u+x xsync.sh
2)配置免密登陆 比如说要登陆A机器,这里只有一个公钥的情况下,那么我们是可以伪造公钥进而登陆到机器A上,这时候就是看出了私钥的重要性了.
比如说要登陆A机器,这里只有一个公钥的情况下,那么我们是可以伪造公钥进而登陆到机器A上,这时候就是看出了私钥的重要性了.
首先在hadoop1002机器上生成相应的公私钥$ ssh-keygen -t rsa,直接回车
然后,将上面的钥匙分发一下,自己也是需要的$ ssh-copy-id hadoop1002,然后给hadoop1003和hadoop1004进行钥匙分配,下图是我进行分钥匙的代码: 之后,测试是否成功$ ssh hadoop1003,退出 $ exit.
之后,测试是否成功$ ssh hadoop1003,退出 $ exit. 
看,配置成功了.
然后在hadoop1003和hadoop1004之中的操作也是这样进行.(去恰饭)
十五. 安装JDK
1) 安装JDK
首先查询一个JDK,$ rpm -qa | grep -java,由于我们安装的是无界面化的Linux,因此,这里是空的.可以进行放心大胆的安装.
$ cd /opt/software 进入到相应的软件目录下面,将jdk-8u212-linux-x64.tar.gz传输上去.
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C ../module/ 将其进行安装
2) 配置环境变量
$ cd /etc/profile.d/
$ sudo touch my_env.sh
$ sudo vim my_env.sh
代码是如下所示:
#java
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin$ source /etc/profile 让上面的配置生效
$ java -version 查看是否生效
$ echo $PATH 查看是否生效的第二种方式
3) 分发软件和环境变量
$ xsync.sh /opt/module/jdk7.8.0_212/ 分发软件
$ scp -r /etc/profile.d/my_env.sh root@hadoop1003:/etc/profile.d/ 分发环境变量
$ scp -r /etc/profile.d/my_env.sh root@hadoop1004:/etc/profile.d/
$ 让上面的环境变量进行起作用,断开重新连接或者source一下
十六. 环境变量配置说明
常见的配置环境变量的地方:
1) $ sudo vim /etc/profile
2) ~$ ll -a
$ vim .bashrc 
3) $ vim /etc/bashrc
4) 我们这里使用的是$ vim /etc/profile.d/之中配置.sh脚本文件.
上述之中,不同的配置方法是有什么区别吗?
第一种是登陆式shell,一直是可以使用的,它是会加载/etc/profile文件.
第二种是非登陆式shell,如$ ssh hadoop1003 mkdir /opt/software/abc,还是会回到原来的hadoop102之中,只是去了一次,然后又回来了,它是加载~/.bashrc文件的.
根据不同的加载文件,需要配置不同地方的环境变量,/etc/profile.d/***.sh是可以使用登陆式shell,也可以是非登陆式shell.
十七. 模拟生成数据
这我们使用的是mock,已经写好的东西进行规划使用.
$ cd /opt/module
$ mkdir applog
$ cd applog
接下来就是上传在相应的mock文件夹下面的几个文件.
解释一下这里的gamll2020-mock-log-2021-01-22.jar的含义,它就是进行生成数据的东西,其使用springboot.那打开一下上面的application.yml文件进行看一下.
对logback.xml文件进行解释: 
path.json文件的说明:
老师说,上面的东西没有必要进行深究.
必须在相应的jar包所在的位置进行相应的使用日志生成,$ java -jar gmall2020-mock-log-2021-01-22.jar 
在原来的路径下面会产生一个log文件,这个文件就是想要的那个文件. 但是里面的日期是数据配置模拟的日期.
但是里面的日期是数据配置模拟的日期.
$ cd log
$ tail -n 300 app***(就是那个名字),由于数据太多了,就是看个演示.
{"common":{"ar":"370000","ba":"iPhone","ch":"Appstore","is_new":"0","md":"iPhone 8","mid":"mid_258171","os":"iOS 13.3.1","uid":"28","vc":"v2.1.134"},"page":{"during_time":6242,"item":"9,27","item_type":"sku_ids","last_page_id":"trade","page_id":"payment"},"ts":1592141762000}
上面的数据,会发现是十分的难以看出来什么东西,因此,使用一个json格式化的东西,将上面的数据进行格式化操作.使用的工具如下所示:
JSON在线解析及格式化验证 - JSON.cnJson中文网致力于在中国推广Json,并提供相关的Json解析、验证、格式化、压缩、编辑器以及Json与XML相互转换等服务![]() https://www.json.cn/转换一行代码,可以得到如下所示解析代码:
https://www.json.cn/转换一行代码,可以得到如下所示解析代码:
{
"common":{
"ar":"370000",
"ba":"iPhone",
"ch":"Appstore",
"is_new":"0",
"md":"iPhone 8",
"mid":"mid_258171",
"os":"iOS 13.3.1",
"uid":"28",
"vc":"v2.1.134"
},
"page":{
"during_time":6242,
"item":"9,27",
"item_type":"sku_ids",
"last_page_id":"trade",
"page_id":"payment"
},
"ts":1592141762000
}一般身为大数据开发人员,是在这个地方进行接手相应的数据的.
二十. 模拟生成数据脚本
在生成数据的时候,是有多台日志生成服务器.

#!/bin/bash
for i in hadoop1002 hadoop1003
do
ssh $i 'cd /opt/module/applog;java -jar gmall2020-mock-log-2021-01-22.jar &'
done
这里是将hadoop1002和hadoop1003作为两个日志服务器进行生成相应的日志.
但是在使用的过程之中会产生很多的字母码,因此,这里这里通过修改logback.xml文件的方式,让它不打印这些东西,窗口也就是不会再阻塞了.
将上面用红线标出的代码删除掉即可.
第二种方式:使重新定向的方式
#!/bin/bash
for i in hadoop1002 hadoop1003
do
ssh $i 'cd /opt/module/applog ;java -jar gmall2020-mock-log-2021-01-22.jar 1>/dev/null 2>&1 &'
done
 上图之中的1>dev/null就是相当于一个黑洞,放在里面的东西都是进行删除掉.
上图之中的1>dev/null就是相当于一个黑洞,放在里面的东西都是进行删除掉.
创建相应的脚本文件,$ cd /bin,$ vim log.sh,然后将上面的东西放进去就是可以的.
并且将上述的applog分发到hadoop1003之中,这里是不使用哪个xync.sh分发脚本文件的.
$ scp -r applog hadoop1003:/opt/module
之后是使用$ log.sh进行脚本的运行,然后分别在hadoop1002和hadoop1003两个机器上进行使用jps,看看是否是正常的,如果要是正常的情况,就是出现一个jar.(一定要验证,我这个地方错了,发现前面写代码的时候,丢掉了一个/)如下所示:
十九. 阿里云购买
阿里云可以用来当藏匿私房钱的地方,可以提现的
https://www.aliyun.com/![]() https://www.aliyun.com/
https://www.aliyun.com/ 这里就不进行详细描述啦,花钱谁不会?
这里就不进行详细描述啦,花钱谁不会?
付费模式 - 按量付费 (太贵啦包年包月,不建议使用;抢占式有点不安全,但是最便宜的)
地域选择 - 必须是同一个地方,尽量是一个区.(这里建议使用张家口,但是我发现这里不能选张家口,就选了一个什么布什么地方)
分类选型:2CPU 8G
不使用限价.
买三台.


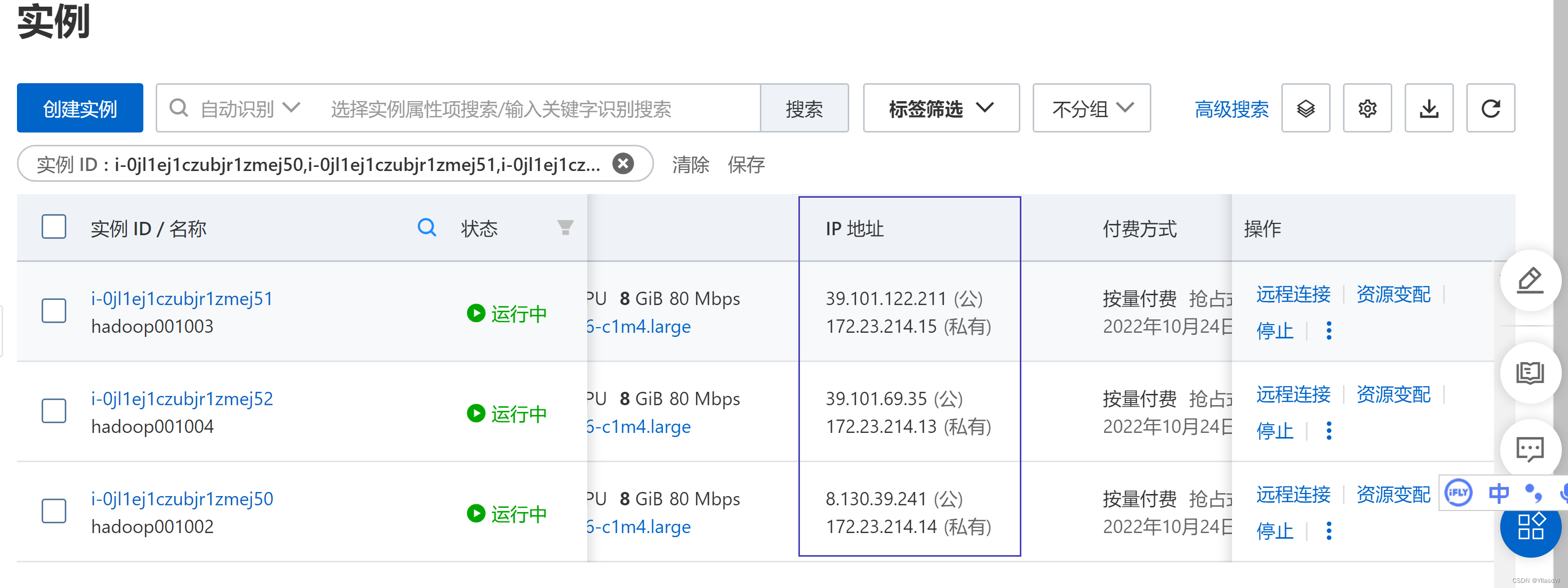
就是使用的时候,我们使用的是公网的ip.使用xshell连接,操作过程是非常简单的.
停机操作是如上所示.(回去恰觉)
二十. 辅助脚本
1) 查看集群所有进程的脚本,jps是java提供的一个环境变量.
$ vim myjps.sh
#!/bin/bash
for i in hadoop1002 hadoop1003 hadoop1004
do
echo "=================> $i JPS <================="
ssh $i /opt/module/jdk1.8.0_212/bin/jps
done $ chmod u+x myjps.sh
演示图片:
2) 上面的代码还有一个通用的版本: 传入什么干什么,这个代码的意思.
$ vim xcall.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Error!!!!"
exit;
fi
for i in hadoop1002 hadoop1003 hadoop1004
do
echo "=================> $i <================="
ssh $i "$*"
done$ chmod u+x xcall.sh
演示图片:
二十一. Hadoop安装配置
1) 集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
| HDFS | NameNode DataNode | DataNode | DataNode SecondaryNameNode |
| Yarn | NodeManager | Resourcemanager NodeManager | NodeManager |
2) 步骤:
A.
$ cd /opt/software 上传hadoop-3.1.3.tar.gz
$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module 进行解压操作
$ cd /opt/module/hadoop-3.1.3 
这里的bin和sbin之中都是我们需要的命令和脚本;
etc里面放的是配置文件;
share里面放置的是我们需要的jar包;
lib放的是本地库,***.so文件(可以理解为windows里面的.dll文件);
B. 配置环境变量
$ vim /etc/profile.d/my_env.sh
#java
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#hadoop
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3) Hadoop配置文件
$ cd /opt/module/hadoop-3.1.3/etc/hadoop
A.core-site.xml
<configuration>
<!-- 指定NameNode的地址(配置之后是HDFS)相当于是hdfs://hadoop1002:8020/opt/module/hadoop/input : 官网之中默认的配置地址是file:///(本地模式)相当于file:///opt/module/hadoop/input -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1002:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu
这里是相当于在web端口用户的一个权限的设置 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
</configuration>
对于上面的一些解释:
<!-- 指定NameNode的地址
(配置之后是HDFS)相当于是hdfs://hadoop1002:8020/opt/module/hadoop/input ;
官网之中默认的配置地址是file:///(本地模式)相当于file:///opt/module/hadoop/input -->
<!-- 指定hadoop数据的存储目录
后面是会用到的-->
<!-- 配置HDFS网页登录使用的静态用户为atguigu:访问的9870的那个界面,里面是可以进行相应的文件的删除等等.
默认是dr.who
这里是相当于在web端口用户的一个权限的设置 -->
<!-- 后面的代理是用来操作HDFS,hive端口(知道一下就是可以的),允许的主机 所有组 用户 -->
B. hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1002:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1004:9868</value>
</property>
</configuration>
~ <!-- nn web端访问地址:
默认是0.0.0.0:9870-->
<!-- 2nn web端访问地址:
默认配置是0.0.0.0:9868 -->
<!-- 还可以配置一个副本数量,副本数量默认是3个,如果要是进行配置的话,使用dfs.replication -->
<!-- dfs.blocksize 块大小的配置 -->
<!-- dfs.namenode.name.dir namenode数据存储目录 -->
<!-- dfs.datanode.data.dir datanode数据存储目录 -->
<!-- dfs.datanode.checkpoint.dir 2nn的存储目录 -->
上面的三个目录根据第一个core-size.xml目录设置,这里二namenode一般是不用更改的,但是在这里的datanode一般是更改的,将上面的目录进行相应的更改,后面是会说的的,重要)
C. yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址,默认地址是0.0.0.0-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1003</value>
</property>
<!-- 环境变量的继承,这个主要让container使用,让Task使用 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存,极限了512 4096 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小,默认是8个G,由于虚拟机配置的是4个G,因此,我们是使用4个G -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
D. mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>本地模式和集群模式由其决定,hadoop刚装好的时候,跑的是一个本地模式(local),但是这个配置配置成为yarn之后,就是在yarn上面进行相应的跑动.
4) 配置历史服务器
查看任务历史的东西.
需要在mapred-site.xml之中进行相应的配置.
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1002:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1002:19888</value>
</property>再增加日志的聚集功能.
在yarn-site.xml文件之中进行配置,一个map和reduce可能会在很多的东西之中进行运行,在任务执行完成之后,就会将上面执行产生的日志集中发送到hdfs端口,可以在相应的历史服务器里面看到日志的记录.
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1002:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>最后需要将workers进行配置,
hadoop1002
hadoop1003
hadoop1004配置好上面的东西之后,将hadoop-3.1.3直接分发一下.
$ cd /opt/module
$ xsync.sh hadoop-3.1.3/
分发相应的环境变量
scp /etc/profile.d/my_env.sh root@hadoop1003:/etc/profile.d/
scp /etc/profile.d/my_env.sh root@hadoop1004:/etc/profile.d/
断开重新连接 ,xcall.sh hadoop version
这里我的配置是完全是没有问题的.
二十二. Hadoop的启动
$ hdfs namenode -format 进行格式化namenode
hadoop1002 $ start-dfs.sh
hadoop1003 $ start-yarn.sh
地址栏输入:hadoop1002:9870 --- hdfs
hadoop1003:8088 --- yarn
但是我这里发现启动不了:
解决办法:在物理机器上找到:C:\Windows\System32\drivers\etc的hosts文件,我的电脑是不能够直接进行更改这个文件的,因此是将这个文件复制到桌面,使用记事本打开,在里面输入如下指令:
192.168.186.202 hadoop1002
192.168.186.203 hadoop1003
192.168.186.204 hadoop1004上面的东西是按照自己的定义进行更改的,然后再覆盖掉之前的hosts文件,就是可以的.

 完美运行.,莫有大问题.
完美运行.,莫有大问题.
简单测试集群:
$ hadoop fs -mkdir /input
$ hadoop fs -put README.txt /input
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
我们是可以看到对应的文件进行了生成:
$ mapred --daemon start historyserver 启动历史服务器
就是可以在相应的页面上看到历史服务器,但是不知道为啥我的QQ浏览器就是不能看到,只好换了谷歌浏览器

二十三. Hadoop使用经验_HDFS使用的存储多目录
$ cd /opt/module/hadooop-3.1.3
$ cd data/dfs/ 可以看到上面的单目录存储的
可以看到上面的单目录存储的
这里的namenode是没有必要存储多目录的,单目录就是可以的.在生产环境下是高可用的,自身就是一个有备份的作用,没有必要再进行相应的备份.datanode是通过副本进行备份的.
生产环境之中的磁盘情况: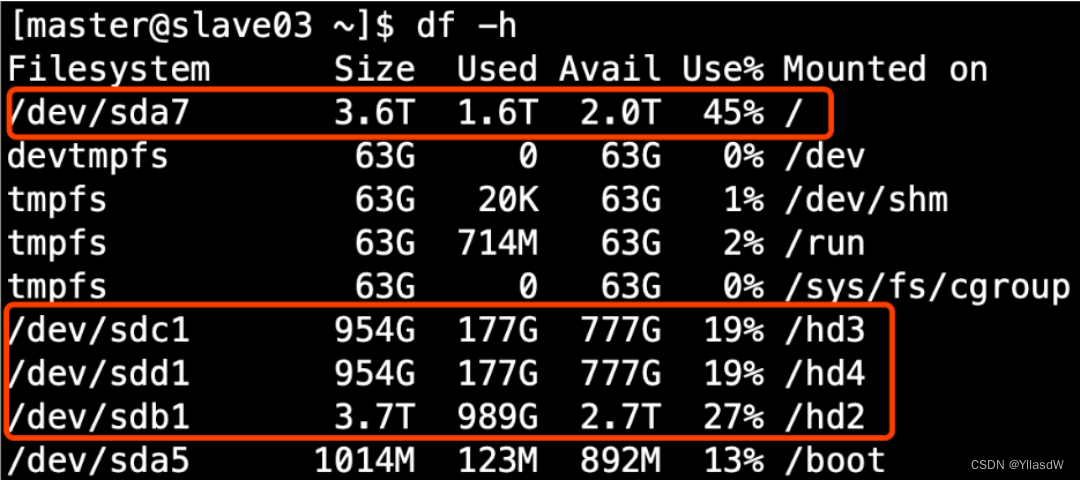
datanode分配在相应的hdfs-site.xml文件之中进行配置.
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>这里的代码就是根据上面的盘进行配置过程代码使用,这就是相应的多个目录,由物理机所分配的方式是使用多目录的方式进行配置.
二十四. Hadoop使用经验_集群数据均衡
1)节点间数据均衡(hadoop2.x 之后才有)
开启数据均衡命令:
start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令
stop-balancer.sh
2)磁盘间数据均衡(hadoop3.x 之后才有)
(1)生成均衡计划(我们只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
二十五. LZO压缩配置
1)hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译,百度一下hadoop-lzo(墙一下,Github,讲了hadoop和lzo是如何走在一起的)。
2)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
3)同步hadoop-lzo-0.4.20.jar到hadoop1003 hadoop1004
$ xsync hadoop-lzo-0.4.20.jar
4)core-site.xml增加配置支持LZO压缩(下面的代码有错,为什么错了见后面的解释,以及改正过程)
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>第一部分是进行增加的是相应的增加压缩的东西,lzo是不支持切片的,支持切片的是lzop.
5)同步core-site.xml到hadoop1003、hadoop1004
$ xsync core-site.xml
6)启动及查看集群
$ start-dfs.sh
$ start-yarn.sh
7) 测试lzo
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /lzo-output
注意上面的-D是进行使用lzo的过程.
我这个地方出现了错误(去恰饭,一会儿再看)
这里的出错原因就是上面在使用的代码出现了错误,我看了一下,就是这里的空格什么要进行注意,好的配置文件如下所示:
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>将上面的core-site.xml文件之中相应的地方改成这个样子,就是可以的.
二十六. LZO切片
方式一:
$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /lzo-input /lzo-output
可以发现并没有进行相应的切片,这里的数量是1,因此我们需要进行强制的停止这个任务.(不能够使用ctrl + c进行相应的停止)
hadoop1003:$ yarn application -list
hadoop1003:$ yarn application -kill application_1666688107237_0005
可以见到上面的文件明没有进行相应的切片.
方法二:
建立索引
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /lzo-input/bigtable.lzo
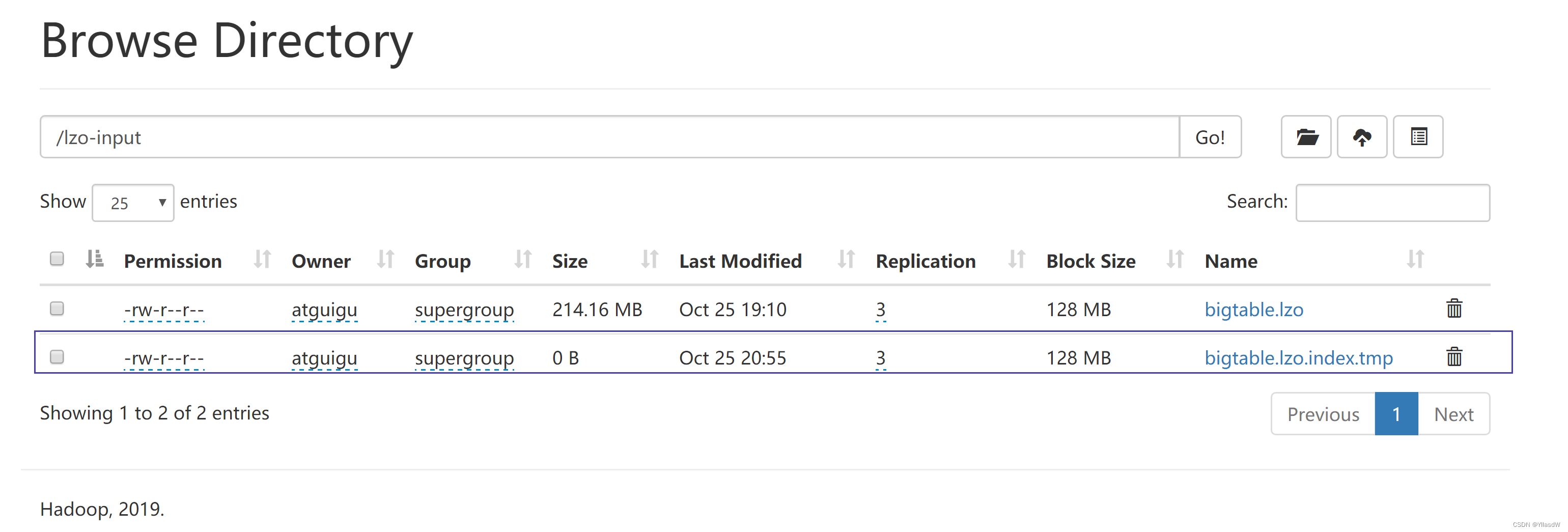
$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /lzo-input /lzo-output(用下面的那一个)
上面就是相应的索引文件. (切片的含义就是从哪个文件的哪个地方进行相应的读取,直到哪一个地方)
上述的两个文件进行切片的过程是:
map1 : Processing split: hdfs://hadoop102:8020/lzo-input/bigtable.lzo:0+224565455
map2 : Processing split: hdfs://hadoop102:8020/lzo-input/bigtable.lzo.index:0+11864
出现问题的原因:上面进行相应的切片是由于我们已经给定的地方,要指定input的类型是lzo类型的.
因此,我们是需要将上述的使用的代码改为下面的这一个:
$ jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /lzo-input /lzo-output
上面的文件就不再使用默认的输入的哪个文件类型了.
Processing split: hdfs://hadoop102:8020/lzo-input/bigtable.lzo:0+134338830
Processing split: hdfs://hadoop102:8020/lzo-input/bigtable.lzo:134338830+90226625
上面的过程之中,并没有将索引文件当成一个使用的文件进行使用.
二十七. 基准测试(千万不要测试)
$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 6 -fileSize 128MB
这里测试的8个CPU,由于一个container和一个application的占用,需要测试6个CPU.
测试了一下,然后电脑屏幕开始了不正常操作:
开始这样......
后来这样.......
再后来这样...... 人麻了。。。。。。。。。。。。。。。。。。。。。。。。。。。
人麻了。。。。。。。。。。。。。。。。。。。。。。。。。。。
二十八. 参数调优
二十九. Zookeeper安装配置
集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
$ cd /opt/software 上传zoopkeeper_3.5.7
$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C ../module/
$ mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7 改个名字
1) 增加环境变量
$ sudo vim /etc/profile.d/my_env.sh
#java
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#hadoop
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#zookeeper
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export PATH=$PATH:$ZOOKEEPER_HOME/binSource一下,zkServer Tab一下,可以Tab出来,说明是配置成功的.环境变量是没有问题的.
2)修改相应的zoo_sample.cfg文件
首先是在/opt/module/zookeeper-3.5.7之中创建一个zkData文件夹.
然后将/opt/module/zookeeper-3.5.7/zoo_sample.cfg文件夹进行重命名,命名为zoo.cfg,将其中的DataDir进行修改:
在zkData之中touch 一个myid文件,将其中的内容写成2(hadoop1002),以此类推.
重新进入到响应zoo.cfg之中,添加如下数据
这里的2888代表的是头部数据,3888代表的是相应的选举号.
接下来就是进行分发上述的配置zookeeper,$ xsync.sh /opt/module/zookeeper-3.5.7/
记着要对于里面的myid进行修改,hadoop1003修改成为3,hadoop1004修改为4.
分发环境变量:$ scp /etc/profile.d/my_env.sh root@hadoop1003:/etc/profile.d/
$ scp /etc/profile.d/my_env.sh root@hadoop1004:/etc/profile.d/
再source一下
3) zookeeper启动
$ zkServer.sh start
$ zkServer.sh status 查看相应的zookeeper的状态,发现是如下所示的状态,因为是集群,要求是半数以上启动才是可以的.
那就再把hadoop1003的启动起来.
Hadoop1004的 完美运行.
完美运行.
4) zookeeper的停止
$ zkServer.sh stop
5) zookeeper的启动停止脚本
$ cd /bin
$ vim zk.sh
$ chmod u+x zk.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: zk.sh {start|stop|status}"
exit
fi
case $1 in
start)
for i in hadoop1002 hadoop1003 hadoop1004
do
echo "=================> START $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
done
;;
stop)
for i in hadoop1002 hadoop1003 hadoop1004
do
echo "=================> STOP $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
done
;;
status)
for i in hadoop1002 hadoop1003 hadoop1004
do
echo "=================> STATUS $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh status
done
;;
*)
echo "USAGE: zk.sh {start|stop|status}"
exit
;;
esac 三十. Zookeeper基本操作
三十. Zookeeper基本操作
$ zk.sh start
$ zkCli.sh
$ help
(回宿舍)
三十一. Kafka安装模块
1) 集群规划:
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
| Kafka | Kafka | Kafka | Kafka |
2) 安装
将需要开发的Kafka上传到相应的/opt/software之中.
$ tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module
可以见到文件之中出现一个kafka_2.11-2.4.1:这里的2.11代表的是开发Kafka所用的Scala语言的版本.2.4.1代表的是这里的Kafka的版本.
$ cd /opt/module/kafka_2.11-2.4.1/
$ mkdir datas 注意这个地方是datas,不能改成logs,这里用来存放kafka的消息.
$ cd config/
$ vim server.properties

 上面的是用来存放消息的目录.
上面的是用来存放消息的目录.
那么产生的日志在哪里呢?
$ cd /opt/module/kafka_2.11-2.4.3/bin
$ vim kafka-run-class.sh ---- 在kafka安装目录的下面
配置环境变量:$ sudo vim /etc/profile.d/my_env.sh
#kafka
export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin$ xsync.sh kafka_2.11-2.4.1
$ scp /etc/profile.d/my_env.sh root@hadoop1003:/etc/profile.d/
$ scp /etc/profile.d/my_env.sh root@hadoop1004:/etc/profile.d/
更改其他的broker.id
3) 启动
进入到kafka的bin目录下面:
$ kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties
(注意:先要启动相应的zookeeper,才能启动kafka)
$ zkCli.sh
4) 停止
$ kafka-server-stop.sh
5) 启动 停止脚本
$ cd /~/bin
$vim kafka.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: kafka.sh {start|stop}"
exit
fi
case $1 in
start)
for i in hadoop1002 hadoop1003 hadoop1004
do
echo "=================> START $i KF <================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties
done
;;
stop)
for i in hadoop1002 hadoop1003 hadoop1004
do
echo "=================> STOP $i KF <================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-stop.sh
done
;;
*)
echo "USAGE: kafka.sh {start|stop}"
exit
;;
esac$ chmod u+x kafka.sh
三十二. Kafka的基本操作
1) 定义一个主题

这里的分区的数量是自己进行定义的,副本的数量不大于三个.
2) 生产数据(生产者)
3) 消费数据(消费者)
以组为单位进行消费
启动两个组进行消费,不会消费到相同分区的数据.
三十三. kafka压力测试
吸取上次测试的教训,没有测试,下面文档对于相关测试过程进行了说明.
1)Kafka压测
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
2)Kafka Producer压力测试
(1)在/opt/module/kafka/bin目录下面有这两个文件。我们来测试一下
[atguigu@hadoop1002 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
说明:
record-size是一条信息有多大,单位是字节。
num-records是总共发送多少条信息。
throughput 是每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量。
(2)Kafka会打印下面的信息
100000 records sent, 95877.277085 records/sec (9.14 MB/sec), 187.68 ms avg latency, 424.00 ms max latency, 155 ms 50th, 411 ms 95th, 423 ms 99th, 424 ms 99.9th.
参数解析:本例中一共写入10w条消息,吞吐量为9.14 MB/sec,每次写入的平均延迟为187.68毫秒,最大的延迟为424.00毫秒。
3)Kafka Consumer压力测试
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
[atguigu@hadoop1002 kafka]$ bin/kafka-consumer-perf-test.sh --broker-list hadoop1002:9092,hadoop1003:9092,hadoop1004:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
参数说明:
--zookeeper 指定zookeeper的链接信息
--topic 指定topic的名称
--fetch-size 指定每次fetch的数据的大小
--messages 总共要消费的消息个数
测试结果说明:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2019-02-19 20:29:07:566, 2019-02-19 20:29:12:170, 9.5368, 2.0714, 100010, 21722.4153
开始测试时间,测试结束数据,共消费数据9.5368MB,吞吐量2.0714MB/s,共消费100010条,平均每秒消费21722.4153条。
三十四. Kafka机器数_分区数
1) 机器数量:
Kafka机器数量(经验公式)= 2 *(峰值生产速度 * 副本数 / 100)+ 1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量 = 2 *( 50 * 2 / 100 )+ 1 = 3 台
2) 分区数量:
1)创建一个只有1个分区的topic
2)测试这个topic的producer吞吐量和consumer吞吐量。
3)假设他们的值分别是Tp和Tc,单位可以是MB/s。
4)然后假设总的目标吞吐量是Tt,那么分区数=Tt / min(Tp,Tc)
例如:producer吞吐量=20m/s;consumer吞吐量=50m/s,期望吞吐量100m/s;
分区数=100 / 20 =5分区
如何根据数据量确定Kafka分区个数、Kafka的分区是不是越多越好、Kafak生产者分发策略,消费者负载均衡 09_啊策策的博客-CSDN博客
分区数一般设置为:3-10个
三十五. Flume安装配置
这个地方就是跟之前是一样的,首先将压缩包放到software之中,然后再进行解压,重命名为Flume-1.9.0,这里需要进行修改的是lib目录之中的文件,$ ll | grep guava,$ rm -rf guava-11.0.2.jar,之后进行配置环境变量(常规操作),断开重连,$ flume-ng 能够Tab出来说明是没有问题的.
回顾Flume之中的东西,学习里面的各个组件是如何进行使用.
1)Source
(1)Taildir Source相比Exec Source、Spooling Directory Source的优势
TailDir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
Exec Source可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
Spooling Directory Source监控目录,支持断点续传。
(2)batchSize大小如何设置?
答:Event 1K左右时,500-1000合适(默认为100)
2)Channel
采用Kafka Channel,省去了Sink,提高了效率。KafkaChannel数据存储在Kafka里面,所以数据是存储在磁盘中。
注意在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可。
三十六.Kafka组件
在下面提供了一个网站,使用这个网站可以查询到相应的使用组件代码.
Welcome to Apache Flume — Apache Flume![]() https://flume.apache.org/
https://flume.apache.org/

Kafka Source相当于是一个消费者,Kafka Sink相当于是一个生产者. kafka Channel的功能还是比较强大的,比如说我们将这里的东西写到相应的Kafka之中,直接加一个Channel就可以了,不用使用完整的Source-Channel-Sink过程.在上面的英文之中就是讲了kafka的一些使用场景.
kafka Channel的功能还是比较强大的,比如说我们将这里的东西写到相应的Kafka之中,直接加一个Channel就可以了,不用使用完整的Source-Channel-Sink过程.在上面的英文之中就是讲了kafka的一些使用场景.
三十七.KafkaSource

通过查询已经提供好的那个网站,搜索自己想要的内容,进行代码的写入.
Kafka Source source-channel-sinks(logger)
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#搜索kafka source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource #类型
a1.sources.r1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092#写出相应的kafka位置
a1.sources.r1.kafka.topics = atguigu#主题
a1.sources.r1.kafka.consumer.group.id = flume#一般是默认的flume
a1.sources.r1.useFlumeEventFormat = false#这条消息之中是否包含相应的header和body
#memory channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#logger sink
a1.sinks.k1.type = logger
#注意第一个加s,第二个不加s
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1$ cd /opt/module/flume-1.9.0
$ mkdir jobs
$ cd jobs
$ vim kafkasource.conf 将上述写好的东西放进来
启动zookeeper kafka
$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/kafkasource.conf -n a1 -Dflume.root.logger=INFO,console (数据接收端)
我在运行的时候出现了错误,如下所示: 报错是关于一个无法加载kafkaSource类的问题.
报错是关于一个无法加载kafkaSource类的问题.
发现代码之中,也就是kafkasource.conf之中添加标注不能够使用#,否则就是会出现问题,我把所有的注释都删掉了,就好了.
然后打开另外一个窗口使用 $ kafka-console-producer.sh --topic atguigu --broker-list hadoop1002:9092 (数据发送端) 进行产生数据,在另外的一个窗口之中进行观察.(如果没有现象,重新启动kafka和zk)[去恰饭]
三十八.KafkaSink

Kafka sink netcat-memory-kafka
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
a1.sinks.k1.kafka.topic = atguigu
a1.sinks.k1.kafka.producer.acks = -1
a1.sinks.k1.useFlumeEventFormat = false
#不想保留相应的header,只想保留body
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1这里的步骤跟上面是一样的,
$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/kafkasink.conf -n a1 -Dflume.root.logger=INFO,console
$ nc localhost 6666 (数据生产者)
$ kafka-console-consumer.sh --topic atguigu --bootstrap-server hadoop1002:9092 (数据消费者)
三十九.KafkaSink_多topic

上面的东西过于复杂,针对于不同的主题而言.
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.EventHeaderInterceptor$MyBuilder
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
a1.sinks.k1.kafka.topic = other
a1.sinks.k1.kafka.producer.acks = -1
a1.sinks.k1.useFlumeEventFormat = false
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 上面代码之中的a1.sinks.k1.kafka.topic = other,我们这里在如果要是atguigu数据,topic指向atguigu;如果要是shangguigu,topic指向shangguigu,其他的就是不进行添加了.注意拦截器里面的名称,i1.type:先是相应的全名,后来是
拦截器的编码:
①首先进行clean;②进行package操作;相应的代码是如下所示:
package com.atguigu.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
/**
* 自定义拦截器 需要实现Flume提供的Interceptor接口.
*/
public class EventHeaderInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 拦截方法
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
//1. 获取event的headers
Map<String, String> headers = event.getHeaders();
//2. 获取event的body
String body = new String(event.getBody(), StandardCharsets.UTF_8);
//3. 判断body中是否包含 "atguigu" "shangguigu"
if(body.contains("atguigu")){
headers.put("topic","atguigu");
}else if (body.contains("shangguigu")){
headers.put("topic","shangguigu");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new EventHeaderInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
package成功界面

将其拖到flume之中的lib之中。
启动项目:$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/kafkasink-topics.conf -n a1 -Dflume.root.logger=INFO,console
消费者:
消费atguigu:$ kafka-console-consumer.sh --topic atguigu --bootstrap-server hadoop1002:9092
消费shangguigu:$ kafka-console-consumer.sh --topic shangguigu --bootstrap-server hadoop1002:9092
消费other:$ kafka-console-consumer.sh --topic other --bootstrap-server hadoop1002:9092
发送消息:$ nc localhost 6666
四十.KafkaChannal
1) 有Source的情况

a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
a1.channels.c1.kafka.topic = atguigu
a1.channels.c1.parseAsFlumeEvent = false #这个配置默认是一个true,channel到sink的过程之中,还是会输出一个格式,true是带格式的.false是不带格式的.
#他作为一个相应的kafka
a1.sinks.k1.type = logger
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1将上面的数据保存到相应的jobs目录下面的kafkachannel之中,进行常规操作.
启动kafka:$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/kafkachannel.conf -n a1 -Dflume.root.logger=INFO,console
发送消息:$ nc localhost 6666
2) 没有Source的情况(kafka生产数据)

a1.channels = c1
a1.sinks = k1
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
a1.channels.c1.kafka.topic = atguigu
a1.channels.c1.parseAsFlumeEvent = false
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1$ vim kafkachannel-nosource.conf,将上述的代码进行复制,放入到这个conf之中.
启动程序:$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/kafkachannel-nosource.conf -n a1 -Dflume.root.logger=INFO,console
生产数据:$ kafka-console-producer.sh --broker-list hadoop1002:9092 --topic atguigu
3) KafkaChannel -no sink(这个过程就将数据写到kafka之中)

a1.sources = r1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
a1.channels.c1.kafka.topic = atguigu
a1.channels.c1.parseAsFlumeEvent = false
a1.sources.r1.channels = c1启动程序:$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/kafkachannel-nosink.conf -n a1 -Dflume.root.logger=INFO,console
开始启动kafka的消费:由于看不到相应的数据,因此是需要将相应的消费者进行启动
kafka-console-consumer.sh --topic atguigu --bootstrap-server hadoop1002:9092
生产数据:nc localhost 6666
四十一.采集通道规划
这里应当进行注意,第一层Flume放到了Hadoop1002和Hadoop1003之中,第二层Flume放到了相应的Hadoop1004之中.

上游Flume


上游的Fulme,我们这里使用第二种方案,因为第二种方案的组件少一些.
下游Flume


下游的Fulme我们使用第一种方案:①使用File Channel;②增加拦截器,给source加
四十二.第一层Flume_拦截器
针对于刚刚采集到的数据,第一层Source使用拦截器,对于不合法的数据进行剔除.
编写相应的拦截器代码:
①添加依赖:pom.xml文件编写
添加进行相应的flume依赖和阿里巴巴的一个json格式检测的依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
<scope>compile</scope>
</dependency>
</dependencies>②代码的编写:
EtlInterceptor代码的编写:
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
/**
* @anthor Yang
* @create 2022-10-27 16:12
*/
public class EtlInterceptor implements Interceptor {
public void initialize() {
}
public Event intercept(Event event) {
//1.取出body
String body = new String(event.getBody(), StandardCharsets.UTF_8);
//2.通过阿里的的一个文件进行访问json,判断相应的json是否完整
try {
JSON.parseObject(body);
}catch(JSONException e){//解过程之中出现了问题析
return null ;
}
return event;
}
public List<Event> intercept(List<Event> events) {
Iterator<Event> iterator = events.iterator();
while(iterator.hasNext()){
Event event = iterator.next();
Event result = intercept(event);
if(result == null){
iterator.remove();//进行无用的数据移除掉
}
}
return events ;
}
public void close() {
}
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new EtlInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
这里应当注意的是阿里巴巴哪个依赖是否要打进那个包里面去.由于上述代码是要用到上面的类,因此是需要打进jar包之中.注意看下方之中的配置文件
这里的provided的含义是不用打进jar包之中的,因为我们这里使用的是Flume,没有必要再去打一个包.但是后面的阿里巴巴这个东西是需要用到的,因此这里是使用compile将原来的包进行打入.
[注意:这里需要使用一个打包插件,也就是在配置pom.xml文件的时候就应该加入进去.]代码如下所示:这个地方是固定的,用的时候直接固定粘贴:
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
我在复制粘贴进去之后,发现不知道出现什么问题,这个<build>标签报错.尝试了几次都是报错,因此,直接使用下面这个写好的配置pom.xml文件.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.gmall</groupId>
<artifactId>Collect0224</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>使用package进行打包,可以得到两个包,一个是带有依赖,另外一个是不带有依赖的.
将上面带有依赖的那个包,给到相应的flume之中lib之中.
四十三.第一层Flume配置
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.* #采集数据来源
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/jobs/position/position.json #记录采集位置,实现断点续传.
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = EtlInterceptor$MyBuilder
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
a1.sources.r1.channels = c1将上述的配置写入logserver-flume-kafka.conf之中,
在另一台机器上进行启动相应的另一个方式的机器,启动消费者的过程
$ kafka-console-consumer.sh --topic topic_log --bootstrap-server hadoop1002:9092
启动相应的flume
$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/logserver-flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
四十四.第一层Flume脚本
$ vim f1.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: f1.sh {start|stop}"
exit
fi
case $1 in
start)
for i in hadoop1002 hadoop1003
do
ssh $i "nohup flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/logserver-flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console 1>$FLUME_HOME/logs/flume.log 2>&1 &"
done
;;
stop)
for i in hadoop1002 hadoop1003
do
ssh $i "ps -ef | grep logserver-flume-kafka.conf | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9"
done
;;
*)
echo "USAGE: f1.sh {start|stop}"
exit
;;
esac $ chmod u+x f1.sh
$ scp -r /opt/module/flume-*** hadoop1003:/opt/module/
$ scp /etc/profile.d/my_env.sh root@hadoop1003:/etc/profile.d/
成功:
在hadoop1002之中生成相应的时间数据:(这里的目录是cd /opt/module/applog)
$ java -jar gmall2020-mock-log-2021-01-22.jar
修改 /opt/module/applog/application.xml的时间,将其改成为2020年*月20号
在hadoop1003之中也生成相应的时间数据:
$ java -jar gmall2020-mock-log-2021-01-22.jar
可以观察到上面生成的日志是不一样的.----上述的操作说明,可以实现第一层的过程,数据的产生.
四十五.第二层Flume分析
第二层的Flume是将kafka之中的数据拿到,进而传到HDFS之中.
这个地方我们为什么要使用拦截器?
2022年10月27日的数据要放在2022年10月27日的数据包之中.
hdfs.useLocalTimeStamp是一个时间戳的概念,改为false,就是不使用本地时间戳了(保证eventHeader之中存在时间戳),如果要是改为true,就是会将本地的时间戳覆盖掉原来的Header之中的时间戳.
每一条数据都是有一个"ts"时间戳,使用ts作为标识时间,那么就是可以标识数一个拦截器,将这里的ts数据变成据生成的时间,因此,这里我们使用拦截器进行这个操作.通常数据Source之中是不存在Header的,但是KafkaSource是可以自己生成相应的Header,自己就是会添加时间戳,但是它进行添加的时间戳是本地时间.
使用过程需要添加一个依赖:
<dependency>
<groupId>org.apache.flume.flume-ng-sources</groupId>
<artifactId>flume-kafka-source</artifactId>
<version>1.9.0</version>
</dependency>新建一个java类,相应的代码如下所示:
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
public class TimeStampInterception implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1. 取出body
String body = new String(event.getBody(), StandardCharsets.UTF_8);
//2. 将json字符串解析成对象 将json之中东西解析成为相应的一个对象.
JSONObject jsonObject = JSON.parseObject(body);
//3. 从对象中获取ts 将其变成一个字符串,这里是一个相应的k-v的结构
String ts = jsonObject.getString("ts");
//4.将ts的值设置到event的header中 ------ 关键之处
event.getHeaders().put("timestamp",ts);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new TimeStampInterception();
}
@Override
public void configure(Context context) {
}
}
}
四十六.第二层Flume拦截器
先清理,再打包,将上述的东西放到Flume/lib之中
我们需要将Flume和环境变量都是给予Hadoop1004的.
$ scp -r flume-1.9.0/ hadoop1004:/opt/module
$ scp /etc/profile.d/my_env.sh root@hadoop1004:/etc/profile.d/
这时候需要进入到Hadoop1004之中,将其中的flume/lib之中的扩展项进行删除.
$ rm -rf Collect0224-1.0-SNAPSHOT-jar-with-dependencies.jar
新的进行上传(为什么要进行重新上传,因为他不是会覆盖)
四十七.第二层Flume配置
方案一:kafka(source)--file(channel)--hdfs(sink)
这里我们选择相应的方案一:这里为什么要是用相应的方案一,因为这里我们是钥匙用相应的拦截器的过程,拦截器的使用是必须要是有相应的source。
方案二:kafka(channel)--hdfs(sink)
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = hadoop1002:9092,hadoop1003:9092,hadoop1004:9092
a1.sources.r1.kafka.topics = topic_log
a1.sources.r1.kafka.consumer.group.id = gmall //组id
a1.sources.r1.batchDurationMillis = 2000 #批次不能够超过多少秒
#拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = TimeStampInterception$MyBuilder
#channel------这里的channel我们使用的filechannel,用的场景不是很多
a1.channels.c1.type = file
a1.channels.c1.dataDirs = /opt/module/flume-1.9.0/jobs/filechannel #数据产生的目录,可以使用,进而写多个file,多块磁盘的含义就是可以提升速度
a1.channels.c1.capacity = 1000000 #这个地方容量的概念是在机器发生故障的时候,内存之中开辟空间维护event的一个引用,当这个event是用完的时候,就会释放掉.所以这个地方是指的内存之中的容量,并不是相应的文件只总的容量.为了防止内存崩溃,有一个内存落盘的操作
a1.channels.c1.transactionCapacity = 10000 #事务容量要求大于等于source的那个容量1000
a1.channels.c1.checkpointDir = /opt/module/flume-1.9.0/jobs/checkpoint # checkpoint含义是内存之中的数据进行落盘的时候需要落到哪一个位置.
#a1.channels.c1.useDualCheckpoints = true #落盘进行打开
#a1.channels.c1.backupCheckpointDir = /opt/module/flume-1.9.0/jobs/checkpoint-bk#因为上面的内存是很重要的,因此这里进行一个备份
a1.channels.c1.maxFileSize = 2146435071 #当写够一个文件的时候,就会向另一个文件之中进行写操作
a1.channels.c1.keep-alive = 5 #默认是3,当指针是满的,进行等待的时间,在5s之中可以进行等待,进行尝试几次
#
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10 #文件超过多长时间进行滚动一次
a1.sinks.k1.hdfs.rollSize = 134217728 #文件超过多大进行滚动一次
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream #DataStream是普通流,可以直接进行压缩
a1.sinks.k1.hdfs.codeC = lzop
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1$ vim kafka-flume-hdfs.conf
Hadoop1002启动dfs和yarn
启动kafka(Hadoop1004之中的操作):
$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/kafka-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console(这里设计到一个offset重置问题)
hadoop1002之中启动第一层Flume,然后第二层才是可以拿到相应的数据,将数据进一步处理,给到HDFS之中. f1.sh开启,log.sh生产一波数据,然后就是看到顺利进行了.
上面这个错误的产生,我看了一下别的博客,就是之前我把flume之中的guava的哪个jar包进行了删除,但是由于Hadoop 3.1.3 中的 guava 版本和 Flume 1.9.0 中的版本不一致,需要将hadoop之中的那个包进行复制粘贴过来,详见帖子如下(只是路径不同,简单的很):记一次 Flume v1.9.0启动报错ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)_一花一世界~的博客-CSDN博客报错内容ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)报错如下图集群背景(基于 Hadoop 3.3.0 集群安装部署 Flume 1.9.0)1、Hhttps://blog.csdn.net/llwy1428/article/details/112169028?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166688017116782390537997%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=166688017116782390537997&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-112169028-null-null.142%5Ev62%5Epc_search_tree,201%5Ev3%5Eadd_ask,213%5Ev1%5Econtrol&utm_term=ERROR%20-%20org.apache.flume.sink.hdfs.HDFSEventSink.process%28HDFSEventSink.java%3A459%29&spm=1018.2226.3001.4187
启动程序(hadoop1004):
$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/kafka-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
(hadoop1002)启动第一个flume:f1.sh start
(hadoop1002)启动log:log.sh
完美执行.
四十八.第二层Flume脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: f2.sh {start|stop}"
exit
fi
case $1 in
start)
for i in hadoop1004
do
ssh $i "nohup flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/kafka-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console 1>$FLUME_HOME/logs/flume.log 2>&1 &"
done
;;
stop)
for i in hadoop1004
do
ssh $i "ps -ef | grep kafka-flume-hdfs.conf | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9"
done
;;
*)
echo "USAGE: f2.sh {start|stop}"
exit
;;
esac hadoop1002:$ vim f2.sh $ chmod u+x f2.sh
 正常运行.
正常运行.
Flume优化
1)问题描述:如果启动消费Flume抛出如下异常:ERROR hdfs.HDFSEventSink: process failed java.lang.OutOfMemoryError: GC overhead limit exceeded
2)解决方案步骤:
(1)在hadoop102服务器的/opt/module/flume/conf/flume-env.sh文件中增加如下配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
(2)同步配置到hadoop103、hadoop104服务器
[atguigu@hadoop102 conf]$ xsync flume-env.sh
3)Flume内存参数设置及优化
JVM heap一般设置为4G或更高
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
-Xms表示JVM Heap(堆内存)最小尺寸,初始分配;-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发fullgc。
四十九.业务流程
针对于中小型电商一般也就是百多十个表.
双十一要快到了,买个手机吧.

我们一般是和运营打交道是最多的,一般运营是要进行相应的促销什么的,需要相应的数据支持。
五十.电商知识
SKU=Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
例如:iPhone14手机就是SPU。一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
平台属性
销售属性
五十一.业务表_初识
活动信息表 --- 什么什么活动
活动规则表 --- 满一百减20,对应着上述的活动有什么规则。
活动商品关联表 --- 能够参加活动的商品进行维护起来
平台属性表 --- 上面的属性是需要下面的东西进行维护
平台属性值表 ---
一级分类表
二级分类表
三级分类表
字典表 --- 比较标准的一个规范,维护的是一个编号,就是1001 --- 好评,相对于是kv键值对。
省份表 --- 维护省份,包含直辖市,自治区之类的。
地区表 --- 东北、华北之类的地区
品牌表 --- 某一个品牌
购物车表
评价表
优惠券信息表
优惠券优惠范围表
优惠券领用表
优惠券优惠范围表
收藏表
订单明细表 --- 订单的明细信息,指的是一个订单可能是多个商品,每个商品买了几件
订单表 --- 就是下了一个单
订单明细活动关联表 --- 订单之中某个商品参加活动
订单明细优惠券关联表
退单表
订单表
订单状态流水表 --- 记录订单的所有状态
支付表
退款表
SKU信息表 --- 一种商品
SKU平台属性表 --- 跟上面的解释是相同的
SKU销售属性表 --- 跟上面的解释是相同的
SPU信息表
SPU销售属性表 --- 颜色等等
SPU销售属性值表 --- 黑色、白色之类的颜色
用户地址表
用户信息表
五十二.业务表_深入
对于相应的业务表进行深入的了解,这个地方的笔记就不写了。(需要思考与理解)
五十三.业务表_关系
电商业务表
在进行分析的时候,是需要注意里面的核心表。
收藏操作:用户表-收藏表-SKU信息表
优惠券领用:用户表-优惠券领用表-优惠券信息表
上述的过程只是需要进行了解即可,需要的时候对上面的表再次进行查询,找到自己所需要的过程进行分析。
后台管理表
平台属性要分到相应的平台类之中。
五十四.安装MySQL
第一步:进行卸载操作
$ cd /opt/software
$ mkdir mysql-rpms
将相应的配置进行上传到上述的文件夹之中.
等待当上传完成之后,需要卸载掉原来的mysql.
$ rpm -qa | grep -i -E mysql\|mariadb
发现是存在原来的版本的,因此是需要讲原来的东西进行卸载.
$ rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
再次执行$ rpm -qa | grep -i -E mysql\|mariadb,发现就是不存在原来的sql了.
第二步:进行安装操作
$ sudo rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
安装上面的步骤以此安装,安装到05.
安装到05的时候,发现缺少一个依赖,这个时候就是需要安装一个依赖才是可以正常进行.
$ sudo yum install -y libaio ------执行这条语句之后进行安装,安装好了以后,再进行安装05操作.
第三步:进行初始化操作
$ sudo mysqld -initialize --user=mysql
$ sudo systemctl start mysqld
我的这个地方出现了错误.想了一想,我这里是这样操作进行的,就是删除掉在root之中的mysql文件.
$ su - root
$ cd /var/lib ---进入到相应的库目录之中
$ cd mysql --- 发现里面是存在好多东西的.
正常情况下,里面是没有东西的,因此,我这里犯了一个大错.用了一个rm -rf /*,然后一个系统都崩了.然后不得不用之前搭建的那一套系统了....................................(千万不要尝试rm -rf /*,我以为就是删除当前的环境之中的所有目录,结果他把所有东西都给删除了)
$ sudo systemctl status mysqld
$ sudo cat /var/log/mysqld.log | grep password
$ mysql -uroot -p
$ set password = password('123456')
> use mysql;
> select user,host from user;
> update user host = '%' where user = 'root';
> select user,host from user;
> flush privileges;
接下来就是可以使用远程的sql进行连接了.------正常运行的可以
五十五.创建表
在文档的资料之中查找相应的gmall.sql文件.
右键,生成用户脚本.

如上图所示,是我生成的一个表的样式.
如果要是使用文字的形式进行生成.
> create database gmall__1;
> use gmall__1;
> source /opt/msoftware/mysql-rpms/gmall.sql; --- 这里就是自动执行相应的脚本.
五十六.生成数据
$ cd /opt/module
$ mkdir db_log
将mock之中的两个文件传入.
这里应当需要注意的是application.properties文件之中的这些配置:
$ java -jar gmall2020-mock-db-2021-01-22.jar --- 进行相应的数据生成
一般我们查看异常的方式是看cause by.[上述的数据生成的过程,在进行第一次数据使用的时候,需要将其中的东西都是改成1的,后面需要在改成0]
上述的含义就是改成1是进行重置的,改成0是不重置的.
为了更好的生成数据,我们可以写一个脚本.将其起名字是db.sh.
#!/bin/bash
for i in hadoop102
do
echo "========== $i =========="
ssh $i 'cd /opt/module/db_log ;java -jar gmall2020-mock-db-2021-01-22.jar 1>/dev/null 2>&1 &'
done
上面的数据是自定义生成的,可见脚本是可以正常使用的.
五十七.建模工具

上面是EZDML这个工具的使用.
这是我自己画的一个表.
五十八.安装Sqoop
下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
我们这里使用的是sqoop1.4.版本的sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gzv,后面的那个名字hadoop-2.0.4代表的是兼容的sqoop的版本.
进行安装与解压的步骤就是比较成熟的东西了.
我们需要这里需要进行改变的是将sqoop-1.4.6之中conf进行配置,就是将sqoop-env-template.sh改变成为sqoop-env.sh,进行如下的添加操作.
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf配置Sqoop的环境变量
注意代码访问sql是需要进行配置相应jdbc的.在sqoop的lib目录里面.
$ cp /opt/module/mysql-rpms/mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop-1.4.6/lib
$ sqoop help --- 就是可以查看到相应的一个帮助
$ sqoop list-databases --connect jdbc:mysql://hadoop102:3306 --username root --password 123456 将sqoop连接到这里的sql之中.
Sqoop只是一个进行导入和导出的一个工具.
五十九. 使用Sqoop
sqoop从mysql将数据导入到HDFS sqoop的底层是相应的map
将user_info 表中的 id, login_name, nick_name 字段的值导入到HDFS中
要求只导入id 大于等于100 小于等于200的数据
相应的sql语句是如下所示:
select id, login_name, nick_name from user_info where id >=100 and id <=200
首先是进行数据库的连接
sqoop import --connect jdbc:mysql://hadoop102:3306/gmall --username root --password 123456
下面的代码是通过使用相应的\进行换行的使用
sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 123456 \
--table user_info \
--columns id,login_name,nick_name \
--where "id >=100 and id <=200" \ --- 条件要加入" "
--target-dir /testsqoop \ --- hdfs之中的某个路径,根目录之中的testsqoop目录
--delete-target-dir \ --- 这里进行删除的地方是如果上面的路径是存在的,将上面的路径进行删除
--num-mappers 2 \ --- map的个数,一般的map的个数是由切片进行决定,将数据分为两份进行处理,如果要不指定相应的map的个数,默认是4个.
--split-by id \ --- 这里指定的使用什么进行的切片
--fields-terminated-by "\t" --- 指定导入hdfs之中的格式.

由上面的代码执行之后,可以见到在testsqoop之中的出现了两个文件.
上述两个文件的内容是分别从100开始和从150开始的.
上述代码的另一种写法
sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 123456 \
--query "select id,login_name,nick_name from user_info where id >=100 and id <=200 and \$CONDITIONS " \ --- 这里应当注意$CONDITIONS的存在跟一个占位符含义差不多
--target-dir /testsqoop \
--delete-target-dir \
--num-mappers 2 \
--split-by id \
--fields-terminated-by "\t"
select id,login_name,nick_name from user_info where id >=100 and id <=200 and id <=149
select id,login_name,nick_name from user_info where id >=100 and id <=200 and id >=150
select id,login_name,nick_name from user_info where id >=100 and id <=200 and \$CONDITIONS //这个地方是进行相应的执行过程,是需要进行加一个条件判断
select id,login_name,nick_name from user_info where 1=1 and \$CONDITIONS
//注意的地方是都是存在相应的and \$CONDITIONS
六十.同步策略
数据同步策略的类型包括:全量同步、增量同步、新增及变化同步、特殊情况
-
全量表:存储完整的数据。---数据量不大,每天没有新插入的数据,也没有修改的数据,并且数据量不大.

-
增量表:存储新增加的数据。---适用于数据量大,只会有新数据的插入.

-
新增及变化表:存储新增加的数据和变化的数据。每日新增及变化就是存储创建时间和操作时间就是今天的数据.适用的场景是,表的数据量大,既会有新增,也会有变化的过程.

-
特殊表:只需要存储一次。
某些特殊的表,可不必遵循上述同步策略。
例如没变化的客观世界的数据(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份。
在生产环境,个别小公司,为了简单处理,所有表全量导入。
中大型公司,由于数据量比较大,还是严格按照同步策略导入数据。

六十一.脚本分析
if [ -n $2 ]
then
importdate=$2 如果传递了时间,就导入指定时间的数据
else
importdate=`date -d '-1 day' +%F` 如果没有传递时间,就正常导入昨天的数据,` `在这里的使用,其含义就是输出,或者用$()
function import_data(){
sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 123456 \
--query " $1 and \$CONDITIONS " \
--target-dir /origin_data/gmall/db/$2/$importdate \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
}
function import_user_info(){
import_data "select * from user_info where createtime =$importdate or operatetime = $importdate " user_info
}
function import_order_detail(){
import_data "select * from order_detail where createtime=$importdate" order_detail
}
function import_spu_info(){
import_data "select * from spu_info where 1 = 1 " spu_info
}
......
case $1(调用脚本时传入的第一个参数,表示要导哪些表的数据) in
all)
import_user_info
import_order_detail
import_spu_info
............
;;
user_info)
import_user_info
;;
六十二.首日导入数据
首日导入数据脚本:vim mysql_to_hdfs_init.sh
#! /bin/bash
APP=gmall
sqoop=/opt/module/sqoop/bin/sqoop
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;then
do_date=$2
else
echo "请传入日期参数"
exit
fi
import_data(){
$sqoop import \
--connect jdbc:mysql://hadoop102:3306/$APP \
--username root \
--password 123456 \
--target-dir /origin_data/$APP/db/$1/$do_date \
--delete-target-dir \
--query "$2 where \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t' \
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/$APP/db/$1/$do_date
}
import_order_info(){
import_data order_info "select
id,
total_amount,
order_status,
user_id,
payment_way,
delivery_address,
out_trade_no,
create_time,
operate_time,
expire_time,
tracking_no,
province_id,
activity_reduce_amount,
coupon_reduce_amount,
original_total_amount,
feight_fee,
feight_fee_reduce
from order_info"
}
import_coupon_use(){
import_data coupon_use "select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
expire_time
from coupon_use"
}
import_order_status_log(){
import_data order_status_log "select
id,
order_id,
order_status,
operate_time
from order_status_log"
}
import_user_info(){
import_data "user_info" "select
id,
login_name,
nick_name,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time
from user_info"
}
import_order_detail(){
import_data order_detail "select
id,
order_id,
sku_id,
sku_name,
order_price,
sku_num,
create_time,
source_type,
source_id,
split_total_amount,
split_activity_amount,
split_coupon_amount
from order_detail"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
payment_type,
trade_no,
total_amount,
subject,
payment_status,
create_time,
callback_time
from payment_info"
}
import_comment_info(){
import_data comment_info "select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
create_time
from comment_info"
}
import_order_refund_info(){
import_data order_refund_info "select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
refund_status,
create_time
from order_refund_info"
}
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
is_sale,
create_time
from sku_info"
}
import_base_category1(){
import_data "base_category1" "select
id,
name
from base_category1"
}
import_base_category2(){
import_data "base_category2" "select
id,
name,
category1_id
from base_category2"
}
import_base_category3(){
import_data "base_category3" "select
id,
name,
category2_id
from base_category3"
}
import_base_province(){
import_data base_province "select
id,
name,
region_id,
area_code,
iso_code,
iso_3166_2
from base_province"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region"
}
import_base_trademark(){
import_data base_trademark "select
id,
tm_name
from base_trademark"
}
import_spu_info(){
import_data spu_info "select
id,
spu_name,
category3_id,
tm_id
from spu_info"
}
import_favor_info(){
import_data favor_info "select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from favor_info"
}
import_cart_info(){
import_data cart_info "select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from cart_info"
}
import_coupon_info(){
import_data coupon_info "select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from coupon_info"
}
import_activity_info(){
import_data activity_info "select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from activity_info"
}
import_activity_rule(){
import_data activity_rule "select
id,
activity_id,
activity_type,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from activity_rule"
}
import_base_dic(){
import_data base_dic "select
dic_code,
dic_name,
parent_code,
create_time,
operate_time
from base_dic"
}
import_order_detail_activity(){
import_data order_detail_activity "select
id,
order_id,
order_detail_id,
activity_id,
activity_rule_id,
sku_id,
create_time
from order_detail_activity"
}
import_order_detail_coupon(){
import_data order_detail_coupon "select
id,
order_id,
order_detail_id,
coupon_id,
coupon_use_id,
sku_id,
create_time
from order_detail_coupon"
}
import_refund_payment(){
import_data refund_payment "select
id,
out_trade_no,
order_id,
sku_id,
payment_type,
trade_no,
total_amount,
subject,
refund_status,
create_time,
callback_time
from refund_payment"
}
import_sku_attr_value(){
import_data sku_attr_value "select
id,
attr_id,
value_id,
sku_id,
attr_name,
value_name
from sku_attr_value"
}
import_sku_sale_attr_value(){
import_data sku_sale_attr_value "select
id,
sku_id,
spu_id,
sale_attr_value_id,
sale_attr_id,
sale_attr_name,
sale_attr_value_name
from sku_sale_attr_value"
}
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"base_province")
import_base_province
;;
"base_region")
import_base_region
;;
"base_trademark")
import_base_trademark
;;
"activity_info")
import_activity_info
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"favor_info")
import_favor_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"spu_info")
import_spu_info
;;
"activity_rule")
import_activity_rule
;;
"base_dic")
import_base_dic
;;
"order_detail_activity")
import_order_detail_activity
;;
"order_detail_coupon")
import_order_detail_coupon
;;
"refund_payment")
import_refund_payment
;;
"sku_attr_value")
import_sku_attr_value
;;
"sku_sale_attr_value")
import_sku_sale_attr_value
;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_region
import_base_province
import_base_trademark
import_activity_info
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
import_order_detail_activity
import_order_detail_coupon
import_refund_payment
import_sku_attr_value
import_sku_sale_attr_value
;;
esac每日导入脚本:vim mysql_to_hdfs.sh
#! /bin/bash
APP=gmall
sqoop=/opt/module/sqoop/bin/sqoop
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
import_data(){
$sqoop import \
--connect jdbc:mysql://hadoop102:3306/$APP \
--username root \
--password 123456 \
--target-dir /origin_data/$APP/db/$1/$do_date \
--delete-target-dir \
--query "$2 and \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t' \
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/$APP/db/$1/$do_date
}
import_order_info(){
import_data order_info "select
id,
total_amount,
order_status,
user_id,
payment_way,
delivery_address,
out_trade_no,
create_time,
operate_time,
expire_time,
tracking_no,
province_id,
activity_reduce_amount,
coupon_reduce_amount,
original_total_amount,
feight_fee,
feight_fee_reduce
from order_info
where (date_format(create_time,'%Y-%m-%d')='$do_date'
or date_format(operate_time,'%Y-%m-%d')='$do_date')"
}
import_coupon_use(){
import_data coupon_use "select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
expire_time
from coupon_use
where (date_format(get_time,'%Y-%m-%d')='$do_date'
or date_format(using_time,'%Y-%m-%d')='$do_date'
or date_format(used_time,'%Y-%m-%d')='$do_date'
or date_format(expire_time,'%Y-%m-%d')='$do_date')"
}
import_order_status_log(){
import_data order_status_log "select
id,
order_id,
order_status,
operate_time
from order_status_log
where date_format(operate_time,'%Y-%m-%d')='$do_date'"
}
import_user_info(){
import_data "user_info" "select
id,
login_name,
nick_name,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time
from user_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'
or DATE_FORMAT(operate_time,'%Y-%m-%d')='$do_date')"
}
import_order_detail(){
import_data order_detail "select
id,
order_id,
sku_id,
sku_name,
order_price,
sku_num,
create_time,
source_type,
source_id,
split_total_amount,
split_activity_amount,
split_coupon_amount
from order_detail
where DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
payment_type,
trade_no,
total_amount,
subject,
payment_status,
create_time,
callback_time
from payment_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'
or DATE_FORMAT(callback_time,'%Y-%m-%d')='$do_date')"
}
import_comment_info(){
import_data comment_info "select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
create_time
from comment_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_order_refund_info(){
import_data order_refund_info "select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
refund_status,
create_time
from order_refund_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
is_sale,
create_time
from sku_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id,
name
from base_category1 where 1=1"
}
import_base_category2(){
import_data "base_category2" "select
id,
name,
category1_id
from base_category2 where 1=1"
}
import_base_category3(){
import_data "base_category3" "select
id,
name,
category2_id
from base_category3 where 1=1"
}
import_base_province(){
import_data base_province "select
id,
name,
region_id,
area_code,
iso_code,
iso_3166_2
from base_province
where 1=1"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region
where 1=1"
}
import_base_trademark(){
import_data base_trademark "select
id,
tm_name
from base_trademark
where 1=1"
}
import_spu_info(){
import_data spu_info "select
id,
spu_name,
category3_id,
tm_id
from spu_info
where 1=1"
}
import_favor_info(){
import_data favor_info "select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from favor_info
where 1=1"
}
import_cart_info(){
import_data cart_info "select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from cart_info
where 1=1"
}
import_coupon_info(){
import_data coupon_info "select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from coupon_info
where 1=1"
}
import_activity_info(){
import_data activity_info "select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from activity_info
where 1=1"
}
import_activity_rule(){
import_data activity_rule "select
id,
activity_id,
activity_type,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from activity_rule
where 1=1"
}
import_base_dic(){
import_data base_dic "select
dic_code,
dic_name,
parent_code,
create_time,
operate_time
from base_dic
where 1=1"
}
import_order_detail_activity(){
import_data order_detail_activity "select
id,
order_id,
order_detail_id,
activity_id,
activity_rule_id,
sku_id,
create_time
from order_detail_activity
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_order_detail_coupon(){
import_data order_detail_coupon "select
id,
order_id,
order_detail_id,
coupon_id,
coupon_use_id,
sku_id,
create_time
from order_detail_coupon
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_refund_payment(){
import_data refund_payment "select
id,
out_trade_no,
order_id,
sku_id,
payment_type,
trade_no,
total_amount,
subject,
refund_status,
create_time,
callback_time
from refund_payment
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'
or DATE_FORMAT(callback_time,'%Y-%m-%d')='$do_date')"
}
import_sku_attr_value(){
import_data sku_attr_value "select
id,
attr_id,
value_id,
sku_id,
attr_name,
value_name
from sku_attr_value
where 1=1"
}
import_sku_sale_attr_value(){
import_data sku_sale_attr_value "select
id,
sku_id,
spu_id,
sale_attr_value_id,
sale_attr_id,
sale_attr_name,
sale_attr_value_name
from sku_sale_attr_value
where 1=1"
}
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"base_province")
import_base_province
;;
"activity_info")
import_activity_info
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"favor_info")
import_favor_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"spu_info")
import_spu_info
;;
"activity_rule")
import_activity_rule
;;
"base_dic")
import_base_dic
;;
"order_detail_activity")
import_order_detail_activity
;;
"order_detail_coupon")
import_order_detail_coupon
;;
"refund_payment")
import_refund_payment
;;
"sku_attr_value")
import_sku_attr_value
;;
"sku_sale_attr_value")
import_sku_sale_attr_value
;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_trademark
import_activity_info
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
import_order_detail_activity
import_order_detail_coupon
import_refund_payment
import_sku_attr_value
import_sku_sale_attr_value
;;
esac$ mysql -uroot -p123456
> show databases;
> drop databases gmall;
> drop databases gmall1;

上面的操作已经成功删除了.
> create database gmall;
> use gmall;
> source /opt/software/mysql-rpms/gmall.sql;
> show tables;
将上述文件之中的配置进行修改.
$ db.sh --- 开始进行相应的数据生成.
$ mysql_to_hdfs_init.sh all 2020-06-13 --- 进行的是首日导入,这个导入的过程是非常慢的.
六十三.安装hive
安装过程和往常是一样的,这里我们讲hive重命名还是hive.
解决jar包冲突:$ /opt/module/hive/lib mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
将sql之中的进行拷贝:[atguigu@hadoop102 lib]$ cp /opt/software/mysql-connector-java-5.1.48.jar /opt/module/hive/lib/
在hive conf之中进行新建:vim hive-site.xml
添加如下配置:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>创建元数据库
$ mysql -uroot -p123456
mysql> create database metastore; ---- 这个地方是由最开始的配置决定的.
mysql> quit;
初始化元数据库
$ schematool -initSchema -dbType mysql -verbose
由于我这里之前创建过数据库,因此这里出现了错误,需要将之前创建的进行删除.重新进行配置,可以正常运行.
启动hive
$ hive
> show databases;
可以见到这里的数据是正常的.
到hive之中的修改hive之中log4j2一个文件,将里面的templete删除掉,修改如下配置 
相应的日志就可以得到.
六十四.多日导入数据
其操作和首日导入差不多.
$ cd /opt/module/db_log
$ vim application.properties
vim ---- 将文件之中的日期进行修改 重置进行修改
$ db.sh ---- 生成数据,在mysql之中存在了,数据
$ mysql_to_hdfs.sh all 2020-06-14(跟上面指定的时间是一致的.)
下面的虚拟的环境是博主自己搭建的,一共36.92G,有需要的话可以直接下载进行使用.
链接:https://pan.baidu.com/s/1fYvS0nqJ_6vmZSwfLjvLEQ?pwd=1111
提取码:1111
--来自百度网盘超级会员V4的分享














 2046
2046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









