









1.什么是内存对齐
(1) 编译器为每个“数据单元”按排在某个合适的位置上。
(2) C、C++语言非常灵活,它允许你干涉“内存对齐”。也就是可以人为的设置编译器的对齐方式。
2.为什么要对齐
性能原因:在对齐的地址上访问数据快。如果是字节对齐方式存储的话,CPU读取的时候只需要进行一个总线周期即可全部读取完毕,如果不对齐的话,对于32位的系统,CPU读取的时候一般架构都是从偶地址开启的,一次只能读取4个字节,因此需要两个总线周期才能完成,并且还需要进行寄存器里面的数据合并,还需要进行数据移位那么这样的效率就是很低的。
3.如何对齐
(1) 第一个数据成员放在offset为0的位置
(2) 其它成员对齐至min(sizeof(member),#pragma pack所指定的值)的整数倍。
(3)整个结构体也要对齐,结构体总大小对齐至各个成员中最大对齐数的整数倍。
代码示例:
//main.cpp
#include <iostream>
using namespace std;
#include <stdio.h>
#pragma pack(2)//修改对齐数
struct Test
{
char a;//1个字节
double b;//8个字节
char c;//1个字节
};
#pragma pack()
//对齐规则
//1.第一个成员与结构体变量的偏移量为0。也就是&test = &test.a;
//2.其它成员要对齐到某个数字(对齐数)的整倍数的地址
//3.对齐数取编译器预设的一个对齐整数与该成员大小的较小值,VS中是默认值是8,所以上述打印出来就是24,取值可以是1,2,4,8,16
//4.结构体总大小为最大对齐数的整数倍
int main(void)
{
Test test;
//&test = &test.a;
char *p= (char*)&test;
//cout<<p<<endl;
printf("结构体起始地址:%p\n", p);
p = &test.a;
printf("a起始地址:%p\n", p);
p = (char *)&test.b;
printf("b起始地址:%p\n", p);
p = &test.c;
printf("c起始地址:%p\n", p);
cout<<sizeof(Test)<<endl;
return 0;
}
运行结果:
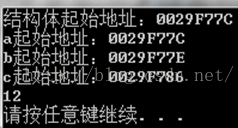
以上例结构体为例,取值范围在VS中和在linux系统中的g++编译器,不同的对齐数的起止偏移地址,以及占用字节数如下所示:
| 编译器 | VS | G++ | ||
| 对齐数 | 起始地址--结束地址 | 占用字节数 | 起始地址--结束地址 | 占用字节数 |
| 1 | a:0--0 b:1—9 c:10-10 | 10 | a:0--0 b:1—9 c:10-10 | 10 |
| 2 | a:0--1 b:2—10 c:11-12 | 12 | a:0--1 b:2—10 c:11-12 | 12 |
| 4 | a:0--3 b:4—11 c:12-15 | 16 | a:0--3 b:4—11 c:12-15 | 16 |
| 8 | a:0--7 b:8—15 c:16-24 | 24 | 不支持 | 不支持 |
| 16 | a:0--15 b:16—31 c:32-47 | 48 | 不支持 | 不支持 |















 1367
1367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









