







一、SQL概要
数据库是不认识JAVA语言的,但是我们同样要与数据库交互,这时需要使用到数据库认识的语言SQL语句,它是数据库的代码。
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
1. SQL分类:
数据定义语言:简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等。
关键字:create,alter,drop,show,use,desc,rename等
数据操作语言:简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新。
关键字:insert into,update..set,delete from
数据控制语言:简称DCL(Data Control Language),用来定义数据库的访问权限和安全级别,及创建用户。
数据查询语言:简称DQL(Data Query Language),用来查询数据库中表的记录。
关键字:select.. from,where等
2. SQL通用语法:
a. SQL语句可以单行或多行书写,以分号结尾
b. 可使用空格和缩进来增强语句的可读性
c. MySQL数据库的SQL语句不区分大小写,建议使用大写,例如:SELECT * FROM user。
d. 同样可以使用/**/的方式完成注释
3. SQL数据类型:
| 分类 | 类型名称 | 说明 |
| 整数类型 | tinyInt | 很小的整数 |
| smallint | 小的整数 | |
| mediumint | 中等大小的整数 | |
| int(integer) | 普通大小的整数 | |
| 小数类型 | float | 单精度浮点数 |
| double | 双精度浮点数 | |
| decimal(m,d) | 压缩严格的定点数 例:sal decimal(7,4),则在表中的数据格式为2.3000 | |
| 日期类型 | year | YYYY 1901~2155 |
| time | HH:MM:SS -838:59:59~838:59:59 | |
| date | YYYY-MM-DD 1000-01-01~9999-12-3 | |
| datetime | YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59 | |
| timestamp | YYYY-MM-DD HH:MM:SS 1970~01~01 00:00:01 UTC~2038-01-19 03:14:07UTC 在赋值时必须赋值null,然后自动更新为当前时间,如果不赋值,或者赋值其他值结果会是null,或者0000..!!! | |
| 文本、二进制类型 | CHAR(M) | M为0~255之间的字符 |
| VARCHAR(M) | M为0~65535之间的字符 | |
| TINYBLOB | 允许长度0~255字节 | |
| BLOB | 允许长度0~65535字节 | |
| MEDIUMBLOB | 允许长度0~167772150字节 | |
| LONGBLOB | 允许长度0~4294967295字节 | |
| TINYTEXT | 允许长度0~255字节 | |
| TEXT | 允许长度0~65535字节 | |
| MEDIUMTEXT | 允许长度0~167772150字节 | |
| LONGTEXT | 允许长度0~4294967295字节 | |
| VARBINARY(M) | 允许长度0~M个字节的变长字节字符串 | |
| BINARY(M) | 允许长度0~M个字节的定长字节字符串 |
常用数据类型:

二、SQL命令
可以通过↑或者↓翻看我们之前执行过的SQL命令。
1. DDL:【对数据库或者表或者列进行增删改查】
一、操作数据库
1、新建数据库
create database student;
create database student character set gbk;
create database student character set gbk collate gbk_chinese_ci;
2、查询所有数据库
show databases;
3、查看已创建的数据库
show create database student;
4、修改数据库
alter database student character set utf8;
5、删除数据库
drop database student;
6、查看当前正在使用哪个数据库。
select database(); // 当前没有选择数据库时,返回null
7、切换数据库
use student1;
注意事项:
create database student;//创建数据库如果没有指定字符集,默认是安装时指定的字符集。
二、操作表
1、新建表:一定要先指定数据库
create table student_record(id int(3) not null primary key auto_increment,name varchar(10) null,card_id int(18) not null unique,sex varchar(1) default '男');//主键、递增排序、唯一
create table student_record(id int(3) not null auto_increment,name varchar(10) null,card_id int(18) not null,primary key(id,card_id));//只有此方法可以指定联合主键!
什么是主键?
一个数据库表,必须给定主键【不给也不报错,会警告】,主键就是能够区分该条记录是唯一的一个或者多个字段。
表中的每一条记录都是唯一的,这个唯一性靠主键区分。
2、查看当前数据库下的所有表
show tables;
3、查看表结构 查看各个字段详情
desc student_record;
4、删除表
drop table student_record;
5、对表名进行重命名
rename table student_record to jsjstudent_record;
三、操作列
1、新增字段
alter table employee add image blob;
2、修改字段
alter table employee modify salary double(7,2);
3、删除列
alter table employee drop image;
四、主键约束
1、添加主键
alter table emp add primary key(empno,deptno);//注:添加主键之前必须删除原来的主键!
2、删除主键:
alter table 表名 drop primary key;
2. DML语句:主要是通过SQL语句对数据库中的数据进行增删改。
1、新增数据//可为null字段在赋值时可写null
insert into student_record(id,name,card_id) values(1,null,21);//指定所有字段赋值
insert into student_record(id,name) values(2,'Mantis');// 指定部分字段赋值
insert into student_record values(3,'jack',null);//默认是所有的字段,必须赋值所有的
2、修改数据//null 无法参与运算
update student_record set name = '阿宝' where id = 1 and card_id = 21;
update student_record set salary = IFNULL(salary,0) + 1000;//IFNULL(字段,0)是指如果该字段的值为null,则设为0;
3、删除表中的数据
delete from student_record where salary is null;
delete from student_record;//1.删除表中所有数据,一条一条的,效率慢2.一行行删除,表结构还在,数据还有可能找回
truncate table 表名;//1.删除表中所有数据,效率快2.直接删除表,然后重新创建一个一模一样的表,数据无法找回
3. DQL 语句: 查询表中的数据
语法:SELECT 列名 FROM表名
1、查询一个表中的所有数据
select * from 表名;
2、有条件查询
select * from employee where id not in(‘1’,’2’);//查询满足where条件的所有字段信息
select name,id from employee;//查询部分字段
4. 一些关键字:
- distinct 去重:select distinct deptno from emp;
- IFNULL(列名,value)如果该列为空,则赋值为value:select empno,sal+IFNULL(sal,0) from emp;
- Order by 字段名 asc:升序
- Order by 字段名 desc:降序
- as 别名(可省略): select e1.ename (as) ‘姓名’ from emp e1;
- Count(字段名/1)计数:它判断null,为null时=0,例:select count(1) from emp;//一般在里面写1!! COUNT(条件表达式),不管记录是否满足条件表达式,只要非NULL就加1(无用)!
- Sum(字段名)
sum(列名)计算列名的值的相加,而不是有值项的总数。
sum(条件表达式),如果记录满足条件表达式就加1,统计满足条件的行数!!!
- Avg(字段名)
- Max(字段名),min(字段名)
- Group by 字段名:字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。
分组的目的就是为了统计,一般分组会跟聚合函数一起使用。例:select deptno,sun(sal) from emp group by deptno; 所以在分组情况下: select 和 from之间一般写 group by之后的字段或者聚合函数。 - Limit a,b//1.select * from emp limit 5;//从0开始输出5行2.select * from emp limit 6,5;//从第6行开始输出5行
- auto_increment自动递增//auto_increment 只针对整型数据类型!!!
- defalut:设置默认值(填null为null,不填为默认值)
where条件的种类:
| 比较运算符 | > < <= >= = <> | 大于、小于、大于(小于)等于、不等于 |
| BETWEEN ...AND... | 显示在某一区间的值(含头含尾) 例:age BETWEEN 80 AND 100 | |
| IN(set) | 显示在in列表中的值,例:in(100,200) | |
| LIKE 通配符 | 模糊查询,Like语句中有两个通配符: % 用来匹配多个字符;例first_name like ‘a%’; _ 用来匹配一个字符。例first_name like ‘a_’; | |
| IS NULL | 判断是否为空 is null; 判断为空 is not null; 判断不为空 | |
| 逻辑运算符 | and | 多个条件同时成立 |
| or | 多个条件任一成立 | |
| not | 不成立,例:where not(salary>100); |
查询语句书写顺序:
Select-->from-->where-->group by-->having-->order by-->limit;
执行顺序:
From-->where-->group by-->having-->select-->order by-->limit;
SQL语言优化:
- SQL语句关键字大写
- 查询语句不要*,要指定你想要输出的字段
- 注意where语句的and的前后顺序(比如要先判断性能性别再判断名字,这样去掉一半),先把可以滤掉大部分数据的条件放在前面,后面就可以根据前面的结果集继续过滤
- Count(*)效率不高,建议写成count(1)
蠕虫复制:
语法格式:注意两个表的字段一定是一样的!(字段个数和数据类型)
1.将表名 2 中的所有的列复制到表名 1 中:
INSERT INTO 表名 1 SELECT * FROM 表名 2;
例:insert into dept_copy select * from dept;
2.只复制部分列:
INSERT INTO 表名 1(列 1, 列 2) SELECT 列 1, 列 2 FROM student;
例:insert into employee(name,salary) select ename,sal from emp;
复制与还原格式:
1.备份格式: DOS 下,未登录的时候。这是一个可执行文件.exe,在 bin 文件夹;
mysqldump -u 用户名 -p 密码 数据库 > 文件的路径
例:mysqldump -uroot -proot day21 > d:/day01.sql
2.还原格式:mysql 中的命令,需要登录后才可以操作
USE 数据库;
SOURCE 导入文件的路径;
例:use day01;
source d:/day01.sql;
5. 数据完整性
作用:保证用户输入的数据保存到数据库中是正确的。确保数据的完整性 = 在创建表时给表中添加约束。
完整性的分类:
a.实体完整性:标识每一行数据不重复,包括主键约束(primary key)、唯一约束(unique)、引用完整性(auto_increment);
b.域完整性:限制此单元格的数据正确,包括非空约束(not null)、默认值约束 (default)
c.引用完整性:外键约束(foreign key)
例子:
1. create table stu_score(id_num int(10) not null,score int(3) null,stu_id int(3) not null , constraint fk_库名_表名 foreign key(stu_id) references stu_record(stu_id));//外键列的数据类型一定要与主键的类型一致
2. 添加外键方式:ALTER TABLE stu_score ADD CONSTRAINT fk_student_stu_score FOREIGN KEY(stu_id) REFERENCES stu_record(stu_id);
6. 多表查询
1. 合并结果集;UNION (去重)、 UNION ALL(不去重)---->(变长了)
//被合并的两个结果集:列数、列类型必须相同
SELECT* FROM t1 UNION SELECT * FROM t2;
SELECT * FROM t1 UNION ALL SELECT * FROM t2;
2. 连接查询 ---->(变宽了)
select * from emp,dept(where emp.deptno = dept.deptno); //产生笛卡儿积
(使用主外键关系做为条件来去除无用信息)
2.1内连接 [INNER] JOIN ON (内连接的特点:查询结果必须满足条件 )
//SELECT * FROM emp e INNER JOIN dept d ON e.deptno=d.deptno;
2.2外连接 OUTER JOIN ON(外连接的特点:查询出的结果存在不满足条件的可能 )
左外连接 LEFT [OUTER] JOIN
//SELECT * FROM emp e LEFT OUTER JOIN dept d ON e.deptno=d.deptno;
//左连接是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的显示NULL。
右外连接 RIGHT [OUTER] JOIN
全外连接(MySQL不支持)FULL JOIN
2.3 自然连接 NATURAL JOIN
3. 子查询(一个select语句中包含另一个完整的select语句。 )
三、DOS操作数据乱码解决
我们在dos命令行操作中文时,会报错
insert into user(username,password) values(‘张三’,’123’);
ERROR 1366 (HY000): Incorrect string value: '\xD5\xC5\xC8\xFD' for column 'username' at row 1
原因:因为mysql的客户端编码的问题我们的是utf8,而系统的cmd窗口编码是gbk
解决方案(临时解决方案):修改mysql客户端编码。
show variables like 'character%'; //查看所有mysql的编码

在图中与客户端有关的编码设置:
client connetion result 和客户端相关
database server system 和服务器端相关
例:将客户端编码修改为gbk.
set character_set_results=gbk; / set names gbk;
以上操作,只针对当前窗口有效果,如果关闭了服务器便失效。如果想要永久修改,通过以下方式:
在mysql安装目录下有my.ini文件
default-character-set=gbk 客户端编码永久设置
character-set-server=utf8 服务器端编码永久设置
注意:修改完成配置文件,重启服务
四、SQL语句示例
1.设有成绩表score如下所示
编号id 姓名name 科目subject 分数score
1 张三 数学 90
2 张三 语文 50
3 张三 地理 40
4 李四 语文 55
5 李四 政治 45
6 王五 政治 30
7 李四 数学 53
8 王五 语文 70
1.查询两门及两门以上不及格的学生姓名
select name from score where score<60 group by name having count(1) >= 2;
2.查询学生平均分
select name,avg(score) from score group by name ;
3.查询姓名是张三的学生 成绩和
select name,sum(score) from score where name = '张三';
4.将学生信息按照 分数倒序
select * from score order by score desc;
4+.将每个学生信息按照分数倒序显示
select * from score order by name asc,score desc;
5.获取学生信息中 分数最低的学生姓名和分数最高的学生姓名
select * from score where score = (select max(score) from score ) or score = (select min(score) from score );
6.查询两门及两门以上不及格同学的平均分。
select name,avg(score) from score group by name having sum(score<60) >=2;
select s1.name,avg(score) from score s1 where s1.name in( select name from score where score<60 group by name having count(1) >= 2) group by s1.name;
7、查询全部科目都不及格的学生的姓名。
select a.name from
(select name,count(1) c from score where score <60 group by name) a,
(select name,count(1) c from score group by name) b
where a.name= b.name and a.c= b.c;
或者以下方式
select name from score group by name having sum(score>60) = 0;
8、请用一条sql写出总分排名前三的学生姓名,总分,平均分
select name,sum(score),avg(score) from score group by name order by sum(score) desc limit 3;
2.写出 SQL语句的格式 : 插入 ,更新 ,删除
表名 user
name tel content date
张三 13333663366 大专毕业 2006-10-11
张三 13612312331 本科毕业 2006-10-15
张四 021-55665566 中专毕业 2006-10-15
(a).有一新记录(小王 13254748547 高中毕业 2007-05-06)请用SQL语句新增至表中
insert into user values ('小王', '13254748547', '高中毕业', '2007-05-06');
(b).请用sql语句把张三的时间更新成为当前系统时间
update user set date=curdate() where name ='张三';
(c).请写出删除名为张四的全部记录
delete from user where name ='张四'
3.写出 SQL语句的格式 :对emp表进行查询操作
1.找出奖金高于工资的雇员
select ename from emp where ifnull(comm,0)>sal;
2.找出奖金高于工资20%的雇员
select ename from emp where ifnull(comm,0)>sal*0.2;
3.找出部门10中所有经理和部门20中所有店员的信息
select * from emp where deptno=10 and job='MANAGER'
union
select * from emp where deptno=20 and job='SALESMAN';
5.薪资大于或等于2000的所有员工的信息。
select * from emp where sal+IFNULL(comm,0) >=2000;
6.查询没有奖金或者奖金低于100的员工信息
7.查询姓名不带”R”的员工姓名
select ename from emp where ename not like '%R%';
8.显示员工的姓名和入职时间,根据入职时间,将最老的员工排放在最前面。
select ename,hiredate from emp order by hiredate asc;
9.显示所有员工的姓名、工作和工资,按照工作的降序排序,若工作相同则按工资升序排序。
select ename,job,sal from emp order by job desc,sal asc;
4.请你按照下面要求写出sql语句
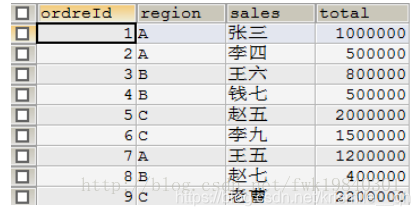
1.统计出每个地区的合同金额合计并按此倒序排列显示。
select region,sum(total) from Orders group by region order by sum(total) desc;
2.统计出每个地区销售人员数量
Select count(1),region from orders group by region;
3.统计出每个地区合同金额最少的销售人员
Select sales from orders o1,
(Select min(total) t,region from orders group by region) o2
Where o1.total = o2.t and o1.region=o2.region;
4.统计出所有超过本地区合同金额平均值得合同及金额
select sales from orders o1,
(Select avg(total) t,region from orders group by region) o2
Where o1.region=o2.region and o1.total>o2.t;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









