







在学习深度学习的过程中,我们常用的一种优化参数的方法就是梯度下降法,而一般情况下,我们搭建的神经网络的结构是:输入→权重矩阵→损失函数。如下图所示。
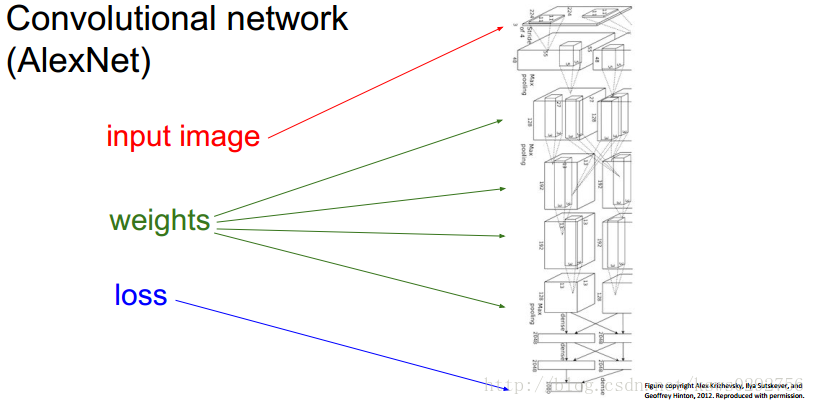
而在给定输入的情况下,为了使我们的损失函数值达到最小,我们就需要调节权重矩阵,使之满足条件,于是,就有了本文现在要介绍的深度学习中的一个核心方法——反向传播。
光听名字可能不太好理解,下面我们用一个简单的例子来讲解反向传播是如何工作的(了解高数中求导的链式法则有助于理解该方法)。
如下图所示,首先定义一个简单的函数,它具有3个自变量
x,y,z
,接着,定义中间变量
q=x+y
,然后令
q
分别对
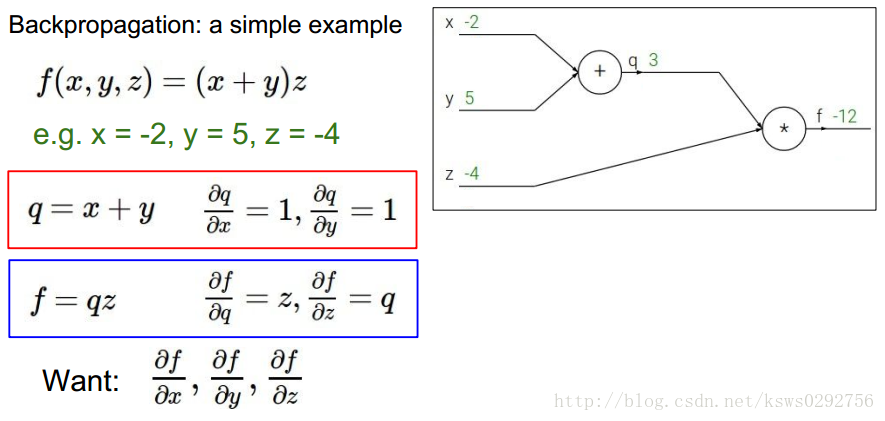
要使用反向传播方法,我们首先获取一组给定的样本值,如下图所示,假设为
x=−2,y=5,z=−4
,由此我们可以通过计算得出
q=3,f=−12
。接下来,我们首先求
f
对自身的导数,等于1(图中红色数字为导数值),然后我们再分别求
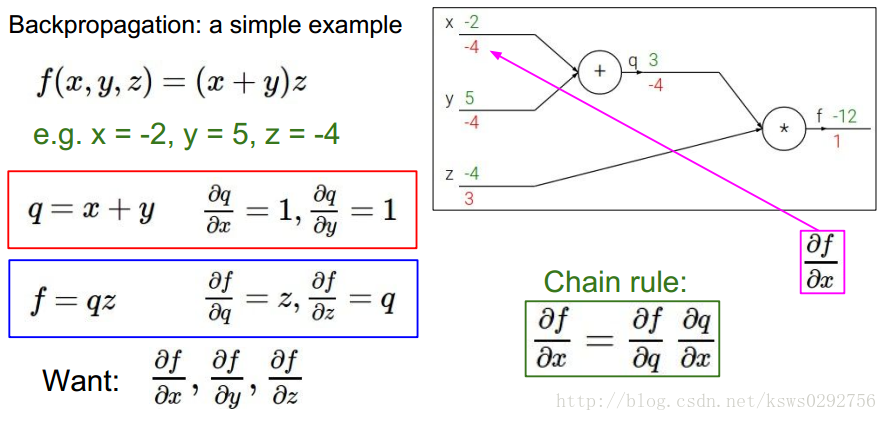
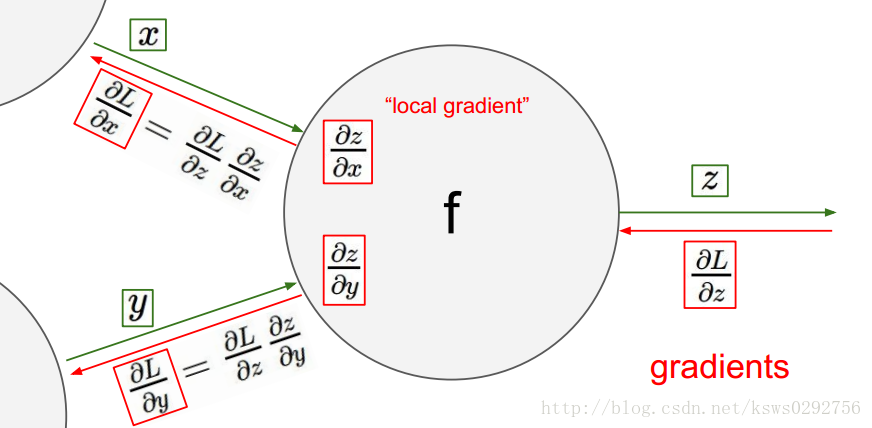
反向传播的运算流程可以用下面这幅图来描述,首先是顺着绿色的箭头计算出相应的变量并存储起来,然后再顺着红色的箭头算出我们需要的梯度值。
为了说明这种方法确实很有用,我们再列举另一个比较复杂的函数例子。如下图所示,我们首先给出函数的具体形式,并计算相应的中间变量和结果变量。
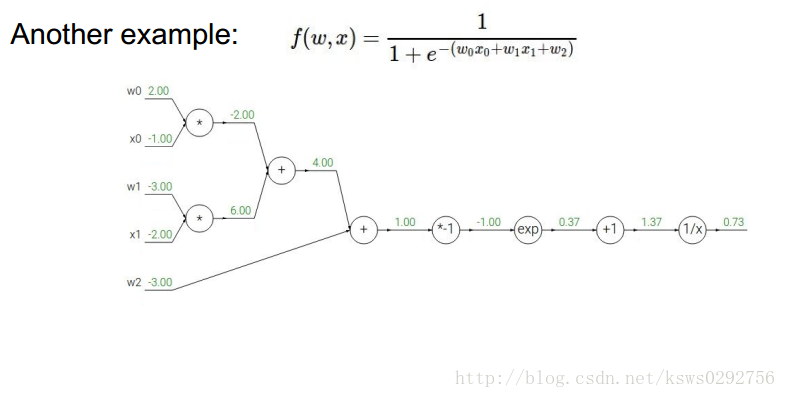
接着,我们根据反向传播的规则和链式法则求出每一个变量对应的梯度值,具体如下图所示。
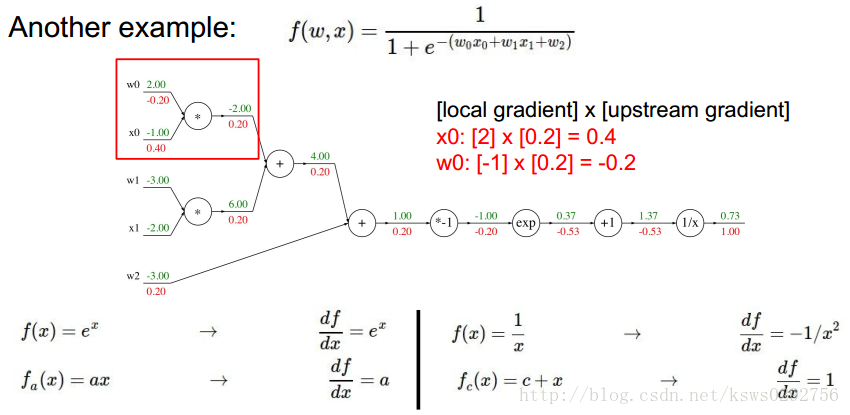
从这里我们可以看出,如果不使用反向传播方法而直接去计算梯度的话,过程将会变得十分麻烦,更何况实际中我们使用的函数还要更加复杂!















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









