







 本文主要介绍了深度学习中的反向传播(backpropagation)算法,这是训练神经网络的关键步骤。通过复习表达形式,详细阐述了反向传播的四个基本方程,包括输出层误差、非输出层误差、损失函数关于偏置的偏导数以及损失函数关于权值的偏导数。这些公式揭示了误差如何从输出层反向传播到输入层,以及如何利用这些信息更新权重和偏置,以改善神经网络的性能。文章强调理解反向传播算法的重要性,并指出激活值的大小对学习速度的影响,特别是在sigmoid函数中,饱和区的学习速度会降低。
本文主要介绍了深度学习中的反向传播(backpropagation)算法,这是训练神经网络的关键步骤。通过复习表达形式,详细阐述了反向传播的四个基本方程,包括输出层误差、非输出层误差、损失函数关于偏置的偏导数以及损失函数关于权值的偏导数。这些公式揭示了误差如何从输出层反向传播到输入层,以及如何利用这些信息更新权重和偏置,以改善神经网络的性能。文章强调理解反向传播算法的重要性,并指出激活值的大小对学习速度的影响,特别是在sigmoid函数中,饱和区的学习速度会降低。
接上一篇的最后,我们要训练多层网络的时候,最后关键的部分就是求梯度啦。纯数学方法几乎是不可能的,那么反向传播算法就是用来求梯度的,用了一个很巧妙的方法。
反向传播算法应该是神经网络最基本最需要弄懂的方法了,要是反向传播方法不懂,后面基本上进行不下去。
非常推荐的是How the backpropagation algorithm works
在最开始的博客中提过,这本书是这篇笔记用到的教材之一,这节反向传播也是以上面那个链接中的内容作为笔记的,因为反向传播部分写的很好。
首先,需要记住两点:
1.反向传播算法告诉我们当我们改变权值(weights)和偏置(biases)的时候,损失函数改变的速度。
2.反向传播也告诉我们如何改变权值和偏置以改变神经网络的整体表现。
一.表达形式复习
这里的表示形式指的是,我们怎么用数学的方式来表示整个神经网络中的各个权值偏置激活函数等等,以及其矩阵形式,算是对于后面推导过程的约定。详细的之前写过了:神经网络(一):概念
这里稍微复习一下。
对于权值来说:
我们用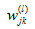
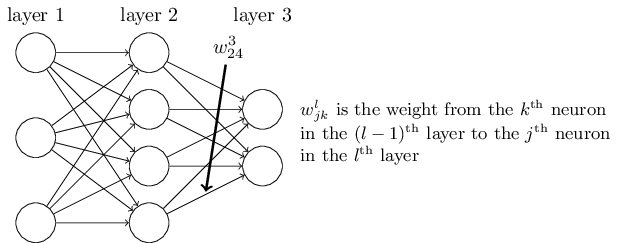
比如下面这幅图就是第2层的第4个元素到第三层的第二个元素之间的权重。
对于偏置来说:
我们用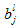
对于激活值来说:
我们用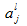
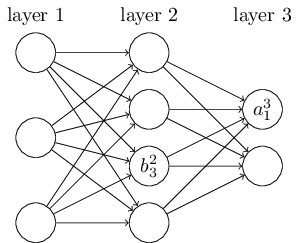
比如上面的第二层的第三个神经元的偏置和第三层第一个神经元的激活值。其实很容易理解。这里要注意,因为是多层结构,如果这层不是输出层,那么这个激活值作为下一层的一个输入。
那么激活值,偏置和权重之前有什么关系呢?
之前假设过我们现在只有sigmoid函数作为激活函数,参考神经网络(一):概念,可以知道:
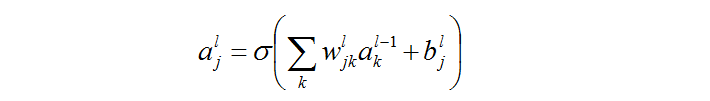
解释一下这个公式&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









