







PCA适用于无标签的数据中,LDA适用于有标签。
希望类间距离越大越好。 类内距离越小越好--Fisher判别准测
经过推导,目标函数变为:
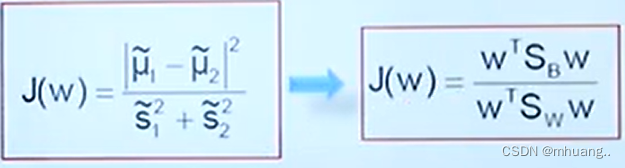
其中Sb是样本间均值的差,表达式为: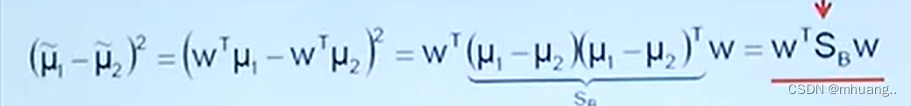
Sw就是各样本散度矩阵之和:
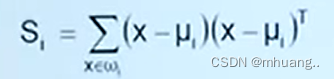

其完整公式推导为:
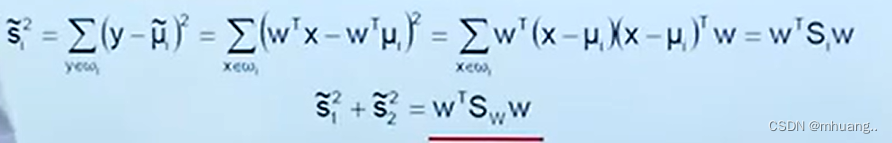
在实际应用中,可以用计算协方差的公式来计算散度矩阵,一般的仿真平台都会封装好计算协方差的函数,对于一个协方差公式 来说,其散度矩阵的表达式就为
。
LDA特点:
rank非满秩
Sw可能是奇异的,(如果存在数据属性方差为0) 那么就求不了逆 也就是算不出Sw 。 这种情况一般需要先进行PCA处理然后再LDA。
当样本均值相等时,LDA会失效,因为对于如果两样本均值相等,那么分子一定为0,在这个情况下怎么投影都没有用。
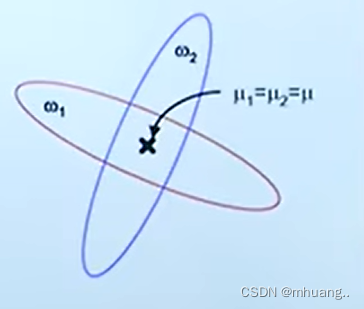
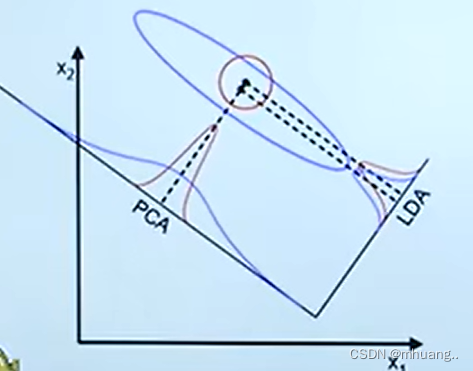
所以,哪怕在有标签类别的数据中,LDA也不是一定比PCA好的(比如下图的情况),所以在实际情况中需要先对样本进行分析。
Python实现PCA与LDA代码示例:
import copy
import numpy as np
c1 = [(1, 2), (2, 3), (3, 3), (4, 5), (5, 5)]
c2 = [(1, 0), (2, 1), (3, 1), (3, 2), (5, 3), (6, 5)]
"""
PCA主成分分析
"""
# 转换为Np类型
mat1 = np.array(c1)
mat2 = np.array(c2)
# 数据拼接
mat = np.vstack((mat1, mat2))
mat_ = copy.deepcopy(mat)
# 计算平均值
average = np.mean(mat, axis=0)
# 去中心化
mat = np.subtract(mat, average)
# 计算协方差矩阵
mat = np.dot(mat.T, mat)/(len(mat)-1)
# 计算协方差矩阵的特征值和特征向量
lamd, vector = np.linalg.eig(mat)
print("特征值:\n{}\n特征向量:\n{}".format(lamd, vector))
# 找到最大特征值(最大方差)对应的特征向量
max_axis = np.argmax(lamd)
contr = np.divide(lamd, np.sum(lamd))
print("主成分贡献率:{}".format(contr))
print("主成分对应的特征向量:", vector[max_axis])
print("将原数据映射到主成分上实现降维:", np.dot(mat_, vector[max_axis]))
print("-------------------")
"""
LDA线性判别分析
"""
# 转换为Np类型
mat1_ = np.array(c1)
mat2_ = np.array(c2)
# 计算样本间的均值
u1, u2 = np.mean(mat1_, axis=0), np.mean(mat2_, axis=0)
u = u1 - u2
S_B = np.dot(u[:, np.newaxis], u[:, np.newaxis].T)
# 中心化
mat1 = mat1_ - u1
mat2 = mat2_ - u2
cov1 = np.dot(mat1.T, mat1)/(len(mat1)-1) # 等价于cov = np.cov(mat1.T)
cov2 = np.dot(mat2.T, mat2)/(len(mat2)-1)
# 计算散度矩阵
cov1 = cov1 * (len(mat1) - 1)
cov2 = cov2 * (len(mat2) - 1)
S_w = cov1 + cov2
# 计算S_w的逆
S_w_ = np.matrix(S_w).I
S_w_ = np.linalg.inv(S_w)
# 计算S_w的逆* S_B
W_B = np.dot( S_w_, S_B)
lamd, vector = np.linalg.eig(W_B)
# 将原数据投影到主方向上
main_vector = vector.T[np.argmax(lamd)]
print("主方向:", main_vector)
print("c1降维在主方向的数据:", np.dot(mat1_, main_vector))
print("c2降维在主方向的数据:", np.dot(mat2_, main_vector))














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









