








因为要给团队的小伙伴普及 用户画像的应用、设计、开发经验,所以周末比较系统的梳理了下此前的经验。在此,也分享给各位同道中人。 瑕疵较多,欢迎大家讨论。
随着互联网技术的发展,大数据时代的到来,用户画像的概念被频繁的提及到。用户画像不被用于互联网领域,在很多传统行业(汽车、零售)也逐渐被重视。企业可以通过用户画像技术,更加精准的了解每一个用户,并针对每个用户制定不同的推荐策略、营销策略。如今,用户画像已经成为广告、智能推荐、智能营销等大数据应用的基础。
1 用户画像的需求背景
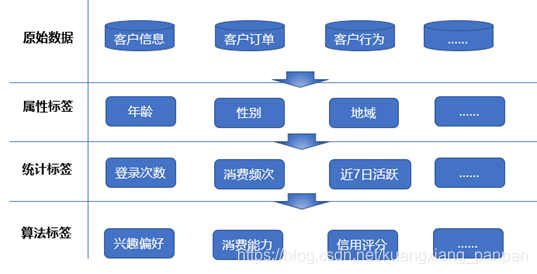
用户画像是指根据用户的属性、偏好、生活习惯、行为等信息,抽象出来的标签化用户模型。通俗说就是给用户打标签,而标签是通过对用户信息分析而来的高度精炼的特征标识。通过打标签可以利用一些高度概括、容易理解的特征来描述用户,可以让人更容易理解用户,并且可以方便计算机处理。

用户标签集合
标签分为3类:
-
- 属性标签:属性标签是针对用户的基础属性的定义,比如年龄、性别等
- 统计标签:通过特定维度和度量统计得出的标签,比如最近7日活跃用户、客单价大于1万的用户、消费频次等。
- 算法标签:需要通过复杂的机器学习算法,进行精准预测后得出。如兴趣偏好、信用评分、用户违约率、用户未来消费能力,用户潜在需求等。
2 用户画像的系统设计
用户画像的主要工作就是给用户打上标签。一般分为场景分析、设计标签体系、画像构建三步。接下来,本文将以视频App为例介绍如何实现用户画像。
1. 场景分析
在视频App中,用户画像通常有如下细化使用场景:
- 个性化栏位运营:根据用户画像,设置每一个用户打开App后能够看到的栏位及栏位的展示顺序。比如,足球爱好者进入App后,首页面的第一个栏位专区可以显示足球专区;电影爱好者,则优先展示电影专区。
- 个性化内容推荐:为用户推荐喜欢的视频内容。比如,我们可以根据用户喜欢的电影类型、演员等偏好,推荐具体的电影视频。可参考腾讯视频、爱奇艺App上的“猜你喜欢”专区。
- 智能搜索:根据用户画像,猜用户可能会搜索的关键词。比如2018年世界杯期间,梅西的粉丝,搜索框输入“m”或者什么也不输入,则App提示“梅西射门!球进啦”
- 精准营销:举一个短信营销的例子。比如电影《叶问4》在App上架后,运营人员可通过短信将上架消息推送给可能喜欢此类电影或者喜欢甄子丹的用户,以便达到通过精品内容拉新促活的目的。
2. 标签体系
经过场景分析后,我们明确了用户画像的业务场景和目标,接下来我们设计适合于视频App的标签体系。
在定义用户标签体系之前,我们通常需要定义用户的标识。看似简单的问题,仍然需要结合业务场景来考虑。视频App用户为分手机号登录用户和游客用户,也存在着一开始使用游客身份浏览视频一段时间后转为登录用户甚至付费用户的情况。
所以,我们使用手机号和设备ID(安卓手机使用 IMEI,苹果手机使用IDFA)来做为用户的标识。在实际识别用户的过程中,优先使用手机号识别;若没有手机号,则再使用设备ID识别用户。
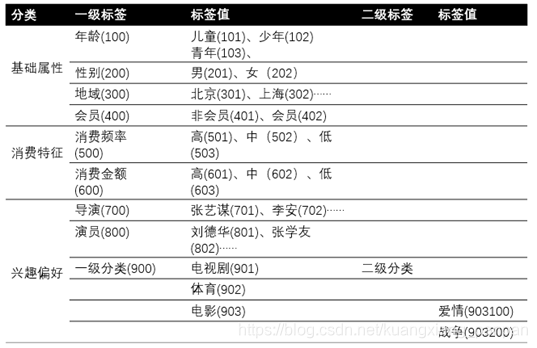
接下来,根据场景分析,我们设计出如下所示的标签体系。每一个标签,需要定义出标签名称、标签值(通常是枚举)、标签所属父标签。
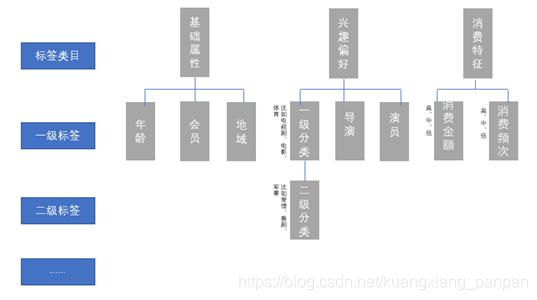
需要一提的是,这里的标签并非单纯指技术上的标签数据,而是一种经过业务化的可被相关人员理解的数据。对于标签体系的制定,即需要业务知识也需要大数据知识,因此需要业务领域专家和大数据技术专家共同参与,保证即能体现业务价值,又能具备技术可行性。
实际应用中经常会对一些连续性数据做离散化处理,以满足业务需要。举例:消费金额在这里通常不再是指连续性的数字,而是一种根据业务处理过的离散值:高、中、低。此外,年龄也通常会离散化处理,划分成若干个年龄段。
另外,本例中为了讲解方便,所以对标签体系进行了简化。在实际应用过程中,除了视频类型,还会有以下维度需要考虑:
| 维度 | 举例 |
| 视频风格 | 轻松、恐怖、幽默、调侃、烧脑、悬疑、催人泪下、唯美、无厘头、沉重、魔幻、悬疑、血腥、暴力、平铺直叙 |
| 情节模式 | 鬼怪屋、自我认知、绝地反击、英雄主义、绝境脱困、人生变迁、伙伴之情、推理侦探、愚者成功、超级英雄、被制度化、拯救地球,恋爱受阻、同族仇怨、绑劫 |
| 时代背景 | 春秋战国、汉朝、三国两晋、隋唐、宋朝、元朝、明朝、清朝、抗站时期、远古、古代、中世纪、18世纪、19世纪、近代、现代、未来、虚拟时代 |
| 冲突类型 | 人际冲突、人物内心冲突、人与自然冲突、人与社会冲突、人与鬼神冲突 |
| 屏幕呈现 | 简洁、灰白、藻丽、平实、典雅、人文、暴雨、风光、油画、仙境、雷鸣、闪电、炫丽、实景拍摄、梦境 |
| 剧本来源 | 经典文学改编、网红小说改编、戏剧改编、历史故事改编、IP改编、漫画改编、真实事件改编、游戏改编、原创 |
3. 画像构建
画像的构建,首先要考虑低层数据结构。一般而言,画像涉及的标签数据有两种存储形式:纵表 横表。
- 纵表,类似K-V表,每行表示对象的一个标签,通常的结构如下。使用纵表,模型稳定、易扩展,但实现起来较为复杂。
| 标识 | 标签名 | 标签值 | 所属类目 |
- 横表:就是普通的二维表,每行表示一个对象,包含对象的多个标签,通常结构如下,使用横表,模型不稳定不易扩展新标签,但实用起来较为方便。
| 标识 | 所属类目 | 标签1 | 标签2 | …… |
在实际应用中,通过使用Hbase进行标签数据的存储,以兼具纵表和横表的优点。为了响应高并发的需求,还会在Redis中进行缓存。
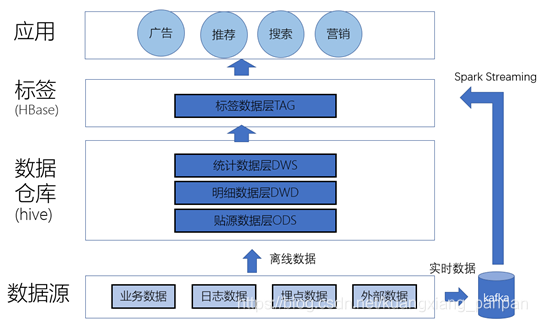
最后,需要依据一定的优先顺序来进行构建:先从最基础的属性标签、再到算法标签,最后再进行预测标签的构建。
属性标签
用户画像的属性类标签,如姓名、年龄、性别之类,通常比较稳定,构建一次后通常可以很久不更新,一般有效在一个月以上。一般通过类似ETL的工具即可实现。
统计标签:
统计类标签,如消费频率、七日活跃、是否流失等,此类数据通过是基于T-1日离线数据,每日构建。通过使用HiveSQL或者spark SQL进行数据开发后计算得到。
算法标签:
算法标签,比如本例中的兴趣偏好标签,是需要我们重点介绍的。用户的兴趣偏好画像是互联网领域中运用最广泛的画像,互联网广告、个性化推荐、精准营销的核心都是用户的兴趣偏好。
通常在计算此类用户画像数据之前我们需要定义内容画像。本例中,我们需要定义视频的内容标签体系,并为每一部视频打标签,比如视频的类型、导演、演员等。其中视频类型,又是一个树状结构,可为分一级分类、二级分类,甚至还有三级分类、四级分类,具体的分类粗细粒度,需要考虑需要的应用场景。内容画像针对一些上新频率不高的视频,可使用人工标注的方式,如电影电视剧,每个月更新的增量内容,使用人工方式性价比高、效果好;但针对一些上新频率很高的视频,比如新闻、短视频,则需要结合自然语言解析(NLP)、图片识别、视频识别技术进行自动标注。本文就不详细介绍。
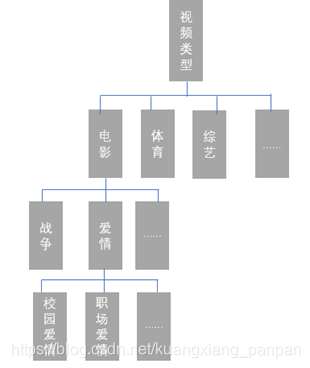
在建构了用户画像后,接下来就会考虑如何构建用户兴趣画像了。
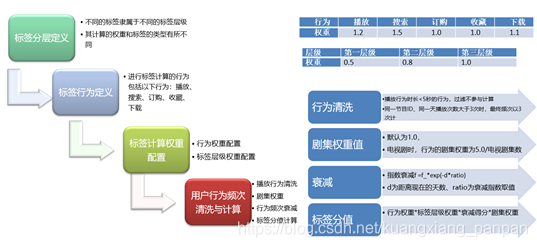
标签分层定义:标签所在分层越大,表示标签的颗粒度越细,也就表示标签更为的精准。所以应该配置更大的权重。
标签行为定义:选择一些关键性的用户行为,用以确认用户偏好哪些内容。最后,这些内容的标签就会转化为用户的兴趣偏好。通常关键性用户行为,会有多种,如视频App中的播放、搜索、订购、收藏、下载等,不同的行为也代表着用户对内容不同的关切程度,因此也需要我们配置不同的权重。
行为清洗:针对一些异常的、或者无意义的行为数据,进行清选。如小于5秒的播放行为可能表示用户误操作。
兴趣衰减:借助牛顿冷却定律,推导出兴趣衰减方程:f =f_init*exp(-d*ratio),其中f为当前兴趣分值;f_init为初始兴趣分值,默认是100份;d为用户行为发生时间即当前时间的天数,ratio为冷却系数。若希望用户的关键行为在间隔60天后衰减到1分,则ratio可设置为:0.077。
剧集权重:这里只要针对连续剧的场景,一部连续剧中会有很多集,不同的集因为剧情的平淡或高潮,也需要设置不同的权重。
标签分值:行为权重*标签层级权重*衰减得分*剧集权重。通常得分最高的就是用户的兴趣偏好标签。当然,在实际应用中,可能存在同一个用户有多种兴趣偏好的情况,比如同一个用户喜欢什么样的电影、什么样的电视剧和什么样的体育赛事。
接下来,不得不提一下实时性问题。用户画像(尤其是用户兴趣偏好画像)又可根据数据的实时性,分为实时用户画像和离线用户画像。
实时用户画像,根据Kafka等消息队列中实时接入的用户最新行为数据,基于Spark streaming或flink等流计算引擎进行实时计算,计算完成存入Hbase或Redis当中。比如用户的兴趣偏好,在个性化推荐场景中,通常需要结合用户在过去几分钟甚至几秒中的行为数据来判断用户的喜好。
离线用户画像,一般基于用户过去较长时间的用数据(如最近3个月),使用较复杂的处理逻辑或者各种离线机器学习模型来保证画像的准确性,并最终将计算结果保存至Hbase中或Redis中。
3 用户画像的系统实现
本例为求简化 ,一方面省略底层源数据的清洗过程,并只针对离线画像进行代码实现;另一方面,假设内容画像维表的数据已经提前准备好,可直接用于训练用户画像。
- 系统开发环境
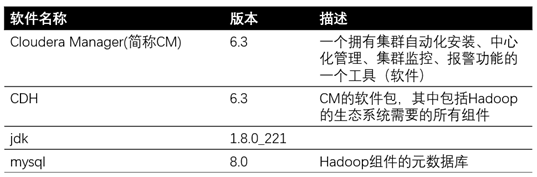
本示例中,考虑到Apache Hadoop版本兼容差、管理难度高,所以准备利用Cloudera Manager快速搭建CDH平台(Cloudera’s Distribution Including Apache Hadoop),提供可扩展、易维护、易管理的Hadoop平台。Cloudera公司本身也是Hadoop开源生态圈最大的代码贡献者之一。
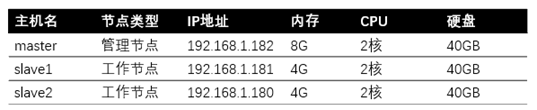
1.1硬件环境
笔者从阿里云上购买了三台linux虚拟机,做为hadoop集群的硬件环境,相关配置如下所示:
1.2软件环境
- 数据仓库的实现
数据仓库分为三层:贴源数据层ODS、明细数据层DWD和数据汇聚层DWS。本实例中,省略数据清洗过程(比如忽略播放时长小于5秒的行为,补齐缺失的字段信息、统一来自不同业务系统的数据的单位、枚举定义等),直接从DWD层开始。同时,为简化示例,没有使用分区表。
按照前提假设,先准备好数据表内容画像数据,即内容标签表。在真实应用中,多采用HBase进行存储。本例中为演示方便,采用Hive表代替HBase表。如下所示:
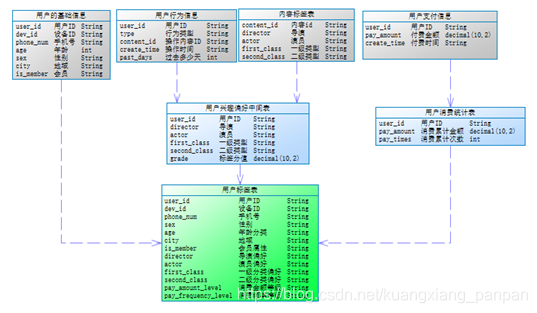
第一步:构建用户兴趣偏好中间表。这里标签分层权重和剧集权重都默认为1。

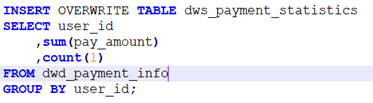
第二步:构建用户消费统计表,计算用户消费的累计金额和累计次数。
第三步:构建用户标签表。这里涉及到将用户的年龄、累计消费金额、累计消费次数进行离散化的操作,即进行分箱操作。比较常见的分箱,包括等宽分箱、等频分箱或者根据业务人员的人工划分进行分箱。本例中,采用人工划分的方式分箱。此外,在实际应用中通常会取标签分值前N名的兴趣偏好标签作为用户的最终标签,本例中仅取分值第一的标签。
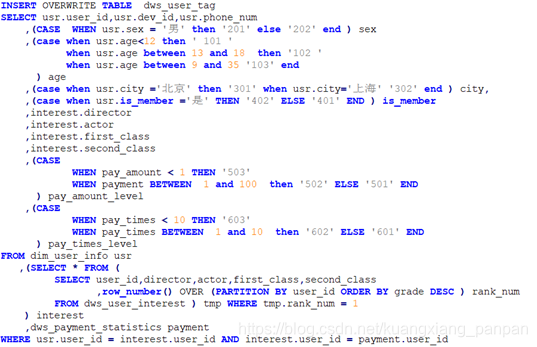
- HBase标签数据库的实现
为方便对外提供查询服务,通常标签数据会最终存在HBase或Redis中。本文以HBase方式进行举例。
HBase 表结构:
| rowkey | basic | intserest | payment |
| 用户唯一标识 (优先级: phone_num>dev_id)
| 基础属性列簇 | 兴趣偏好列簇 | 消费特征列簇 |
接下来要做的事,是将Hive中计算出的数据导出HBase中。在数据量不大的情况,可直接用Hive表映射HBase表的方式来实现。
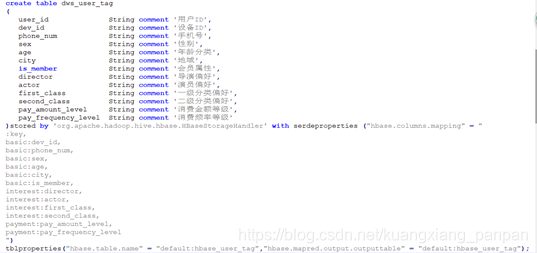
建立映射关系后,往Hive表dws_user_tag表写入数据,即是往HBase表:hbase_user_tag表中写入数据。
- 标签服务的实现
完成用户画像的计算和存储后,需要将用户标签数据,以Rest API的方式向外开放。
- 输入参数
| 名称 | 类型 | 是否必须 | 描述 | 长度 | 最大最小值 |
| userId | String | 是 | 用户标识 | 0-32 |
|
- 返回结果
| 名称 | 类型 | 描述 | 支持排序 |
| group | string | 列簇名 |
|
| key | String | 列名(标签名) |
|
| value | String | 列值(标签值) |
|
| 返回样例:
| |||

接下来,就是通过Java或Python访问HBase并提供Rest API。这里,本文就不再详细介绍了。
4用户画像的效果评估
如果把未经验证的用户画像直接上线,风险是非常大的。所以我们需要通过一些手段对用户画像的效果进行验证,分为离线测试阶段的指标评估和灰度发布阶段的A/B Test。
指标评估
用户画像的评估指标主要是指准确率、覆盖率、时效性等指标。
标签的准确率指的是被打上正确标签的用户比例,准确率是用户画像最核心的指标,一个准确率非常低的标签是没有应用价值的。准确率的评估一般有两种方法:一种是在标注数据集里留一部分测试数据用于计算模型的准确率;另一种是在全量用户中抽一批用户,进行人工标注,评估准确率。
标签的覆盖率指的是被打上标签的用户占全量用户的比例,我们希望标签的覆盖率尽可能的高。但实际应用过程中,针对很长时间不活跃的“僵尸用户”是很难计算其用户画像的,所以为了提高覆盖率需要定期清除“僵尸用户”。
标签的时效性指用户的兴趣偏好随时都在发生变化,需要及时更新用户标签。测试阶段针对离线用户画像需要验证兴趣衰减规则是否生效,针对实时用户画像需要验证用户过去几分钟甚至几秒中的行为是否被更新到用户画像中。
A/B 测试
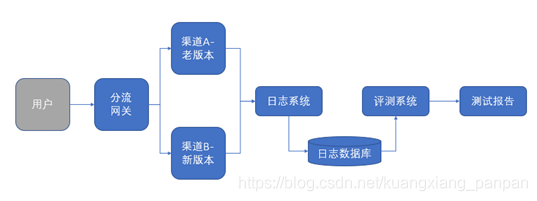
A/B测试(也称为分割测试或桶测试)是一种将应用程序的两个版本相互比较以确定哪个版本更好的方法,是一种常用的在线评测算法的实验方法。具体原理就是将线上用户进行分流(比如按地域或者渠道抽样成两份小流量进行分流实验),先将少部分用户分流到新版本用户画像上,根据给定的指标验证实验结果。具体操作步骤如下所示:
确定目标:假设用户画像用于视频App的个性化推荐,我们通常关注内容的点击率指标(即内容被点击效率/曝光次数),通过点击率评估测试验证是否通过。
设置分流规则:我们通常选取同一地域的两个相似渠道进行分流,渠道A仍然使用老版本的用户画像,渠道B使用新版本的用户画像。
运行实验:根据分流规则实施原流,并采集计算点击率相关的数据。
分析结果:个性化推荐收集运行实验后1天左右的数据,计算渠道A和B的点击率并进行比较,若渠道A的点击率<渠道B的点击率,则表示本次实验通过。

















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









