






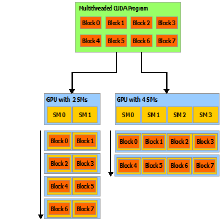
CUDA中的虚拟内存管理(Virtual Memory Management)
在现代GPU编程中,内存管理是一个至关重要的环节。随着CUDA版本的不断更新,NVIDIA引入了虚拟内存管理(Virtual Memory Management)机制,使得开发者能够更灵活地管理GPU内存。本文将详细介绍CUDA中的虚拟内存管理,并通过代码示例帮助读者更好地理解这一概念。
什么是虚拟内存管理?
虚拟内存管理是一种内存管理技术,它允许程序使用虚拟地址空间来访问物理内存。在CUDA中,虚拟内存管理机制使得开发者能够更高效地管理GPU内存,特别是在处理大规模数据时。通过虚拟内存管理,开发者可以动态地分配和释放内存,而不需要关心物理内存的具体布局。
CUDA虚拟内存管理的基本概念
在CUDA中,虚拟内存管理主要通过以下几个API来实现:
cuMemCreate: 创建一个物理内存块,并返回一个虚拟地址。cuMemMap: 将虚拟地址映射到物理内存块。cuMemUnmap: 取消虚拟地址与物理内存块的映射。cuMemRelease: 释放物理内存块。cuMemSetAccess: 设置内存块的访问权限。
代码示例
下面我们通过一个简单的代码示例来演示如何使用CUDA的虚拟内存管理API。
示例1:创建和映射虚拟内存
#include <cuda.h>
#include <stdio.h>
#define CHECK_CUDA(call) \
{ \
CUresult err = call; \
if (err != CUDA_SUCCESS) { \
const char* errStr; \
cuGetErrorString(err, &errStr); \
printf("CUDA error at %s:%d - %s\n", __FILE__, __LINE__, errStr); \
exit(EXIT_FAILURE); \
} \
}
int main() {
// 初始化CUDA
CHECK_CUDA(cuInit(0));
// 获取设备
CUdevice device;
CHECK_CUDA(cuDeviceGet(&device, 0));
// 创建上下文
CUcontext context;
CHECK_CUDA(cuCtxCreate(&context, 0, device));
// 创建一个物理内存块
CUmemAllocationProp prop = {};
prop.type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
prop.location.id = device;
size_t size = 1024 * 1024; // 1MB
CUmemGenericAllocationHandle handle;
CHECK_CUDA(cuMemCreate(&handle, size, &prop, 0));
// 分配虚拟地址空间
CUdeviceptr ptr;
CHECK_CUDA(cuMemAddressReserve(&ptr, size, 0, 0, 0));
// 将虚拟地址映射到物理内存块
CHECK_CUDA(cuMemMap(ptr, size, 0, handle, 0));
// 设置内存访问权限
CUmemAccessDesc accessDesc = {};
accessDesc.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
accessDesc.location.id = device;
accessDesc.flags = CU_MEM_ACCESS_FLAGS_PROT_READWRITE;
CHECK_CUDA(cuMemSetAccess(ptr, size, &accessDesc, 1));
// 使用虚拟内存
int* data = (int*)ptr;
data[0] = 42;
printf("Data: %d\n", data[0]);
// 取消映射并释放内存
CHECK_CUDA(cuMemUnmap(ptr, size));
CHECK_CUDA(cuMemAddressFree(ptr, size));
CHECK_CUDA(cuMemRelease(handle));
// 销毁上下文
CHECK_CUDA(cuCtxDestroy(context));
return 0;
}
代码解释
- 初始化CUDA: 使用
cuInit初始化CUDA环境。 - 获取设备: 使用
cuDeviceGet获取第一个可用的CUDA设备。 - 创建上下文: 使用
cuCtxCreate创建一个CUDA上下文。 - 创建物理内存块: 使用
cuMemCreate创建一个物理内存块,并返回一个句柄。 - 分配虚拟地址空间: 使用
cuMemAddressReserve分配一段虚拟地址空间。 - 映射虚拟地址: 使用
cuMemMap将虚拟地址映射到物理内存块。 - 设置访问权限: 使用
cuMemSetAccess设置内存块的访问权限。 - 使用虚拟内存: 通过虚拟地址访问内存,并进行读写操作。
- 取消映射并释放内存: 使用
cuMemUnmap取消虚拟地址的映射,并使用cuMemAddressFree释放虚拟地址空间,最后使用cuMemRelease释放物理内存块。 - 销毁上下文: 使用
cuCtxDestroy销毁CUDA上下文。
示例2:多GPU虚拟内存管理
在某些情况下,我们可能需要在多个GPU之间共享内存。CUDA的虚拟内存管理机制也支持跨GPU的内存管理。
#include <cuda.h>
#include <stdio.h>
#define CHECK_CUDA(call) \
{ \
CUresult err = call; \
if (err != CUDA_SUCCESS) { \
const char* errStr; \
cuGetErrorString(err, &errStr); \
printf("CUDA error at %s:%d - %s\n", __FILE__, __LINE__, errStr); \
exit(EXIT_FAILURE); \
} \
}
int main() {
// 初始化CUDA
CHECK_CUDA(cuInit(0));
// 获取设备数量
int deviceCount;
CHECK_CUDA(cuDeviceGetCount(&deviceCount));
if (deviceCount < 2) {
printf("至少需要两个GPU来运行此示例\n");
return 1;
}
// 获取两个设备
CUdevice device1, device2;
CHECK_CUDA(cuDeviceGet(&device1, 0));
CHECK_CUDA(cuDeviceGet(&device2, 1));
// 创建两个上下文
CUcontext context1, context2;
CHECK_CUDA(cuCtxCreate(&context1, 0, device1));
CHECK_CUDA(cuCtxCreate(&context2, 0, device2));
// 在第一个设备上创建物理内存块
CUmemAllocationProp prop1 = {};
prop1.type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop1.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
prop1.location.id = device1;
size_t size = 1024 * 1024; // 1MB
CUmemGenericAllocationHandle handle1;
CHECK_CUDA(cuMemCreate(&handle1, size, &prop1, 0));
// 在第二个设备上创建物理内存块
CUmemAllocationProp prop2 = {};
prop2.type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop2.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
prop2.location.id = device2;
CUmemGenericAllocationHandle handle2;
CHECK_CUDA(cuMemCreate(&handle2, size, &prop2, 0));
// 分配虚拟地址空间
CUdeviceptr ptr;
CHECK_CUDA(cuMemAddressReserve(&ptr, size, 0, 0, 0));
// 将虚拟地址映射到第一个设备的物理内存块
CHECK_CUDA(cuMemMap(ptr, size, 0, handle1, 0));
// 设置第一个设备的访问权限
CUmemAccessDesc accessDesc1 = {};
accessDesc1.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
accessDesc1.location.id = device1;
accessDesc1.flags = CU_MEM_ACCESS_FLAGS_PROT_READWRITE;
CHECK_CUDA(cuMemSetAccess(ptr, size, &accessDesc1, 1));
// 使用第一个设备的虚拟内存
int* data = (int*)ptr;
data[0] = 42;
printf("Device 1 Data: %d\n", data[0]);
// 取消映射
CHECK_CUDA(cuMemUnmap(ptr, size));
// 将虚拟地址映射到第二个设备的物理内存块
CHECK_CUDA(cuMemMap(ptr, size, 0, handle2, 0));
// 设置第二个设备的访问权限
CUmemAccessDesc accessDesc2 = {};
accessDesc2.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
accessDesc2.location.id = device2;
accessDesc2.flags = CU_MEM_ACCESS_FLAGS_PROT_READWRITE;
CHECK_CUDA(cuMemSetAccess(ptr, size, &accessDesc2, 1));
// 使用第二个设备的虚拟内存
data[0] = 24;
printf("Device 2 Data: %d\n", data[0]);
// 取消映射并释放内存
CHECK_CUDA(cuMemUnmap(ptr, size));
CHECK_CUDA(cuMemAddressFree(ptr, size));
CHECK_CUDA(cuMemRelease(handle1));
CHECK_CUDA(cuMemRelease(handle2));
// 销毁上下文
CHECK_CUDA(cuCtxDestroy(context1));
CHECK_CUDA(cuCtxDestroy(context2));
return 0;
}
代码解释
- 初始化CUDA: 使用
cuInit初始化CUDA环境。 - 获取设备数量: 使用
cuDeviceGetCount获取可用的CUDA设备数量。 - 获取设备: 使用
cuDeviceGet获取两个CUDA设备。 - 创建上下文: 使用
cuCtxCreate为每个设备创建一个CUDA上下文。 - 创建物理内存块: 分别在两个设备上创建物理内存块。
- 分配虚拟地址空间: 使用
cuMemAddressReserve分配一段虚拟地址空间。 - 映射虚拟地址: 将虚拟地址映射到第一个设备的物理内存块,并设置访问权限。
- 使用虚拟内存: 通过虚拟地址访问第一个设备的内存,并进行读写操作。
- 取消映射: 使用
cuMemUnmap取消虚拟地址的映射。 - 重新映射: 将虚拟地址映射到第二个设备的物理内存块,并设置访问权限。
- 使用虚拟内存: 通过虚拟地址访问第二个设备的内存,并进行读写操作。
- 取消映射并释放内存: 使用
cuMemUnmap取消虚拟地址的映射,并使用cuMemAddressFree释放虚拟地址空间,最后使用cuMemRelease释放物理内存块。 - 销毁上下文: 使用
cuCtxDestroy销毁CUDA上下文。
总结
CUDA的虚拟内存管理机制为开发者提供了更灵活的内存管理方式,特别是在处理大规模数据和多GPU协同工作时。通过本文的介绍和代码示例,希望读者能够更好地理解并应用CUDA中的虚拟内存管理技术。在实际开发中,合理使用虚拟内存管理可以显著提高程序的性能和可维护性。


















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











