






目录
异步的逻辑:
1.获取单个页面的数据
2.上线程池,多个页面同时获取
一、发起请求+获取响应数据
尝试对单个页面发起请求,然后使用for循环循环遍历每个页面,使用三个请求头的列表进行UA伪装随机发起请求
(我访问的网站并没有反爬,所以这一步跟随机休眠可以省略)
import requests
import random
def single_page(url):
user_agent_list = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.200']
head = {'user-agent': random.sample(user_agent_list, 1)[0]}
parm={'limit': '20',
'current': '1',
'pubDateStartTime': '',
'pubDateEndTime': '',
'prodPcatid': '',
'prodCatid': '',
'prodName': ''}
resp=requests.post(url,params=parm,headers=head).json()该网站发起 Post 请求返回的是 Json() 形式的数据,在网页查看比较清晰明了,是这样的结构:

二、处理数据
直接得到了Json数据,就不需要用正则啥的想办法处理源码了,直接当做列表字典来处理,我们想要的数据在响应数据的 'list' 键里面,一页20个数据都以字典形式在 list 里
for k in range(len(resp['list'])):
print([resp['list'][k]['prodCat'],
resp['list'][k]['prodName'],
resp['list'][k]['lowPrice'],
resp['list'][k]['highPrice'],
resp['list'][k]['avgPrice'],
resp['list'][k]['prodName'],
resp['list'][k]['place'],
resp['list'][k]['unitInfo'],
resp['list'][k]['pubDate']])这里刚开始报错: k 是字典数据的位置索引,由于 list 里面存着一个20个字典的列表,通过对应键取值的时候,需要知道是哪个字典里的键
['蔬菜', '大白菜', '0.4', '0.6', '0.5', '大白菜', '冀', '斤', '2023-08-17 00:00:00']
['蔬菜', '娃娃菜', '0.7', '1.0', '0.85', '娃娃菜', '冀', '斤', '2023-08-17 00:00:00']
...
['蔬菜', '绿菜花', '1.4', '2.0', '1.7', '绿菜花', '冀', '斤', '2023-08-17 00:00:00']
['蔬菜', '绿豆芽', '0.95', '1.0', '0.98', '绿豆芽', '', '斤', '2023-08-17 00:00:00'] 补充:页面有如下这种数据,这里的 '袋\箱' 里的 '\' 号可能导致程序出错,所以有时候可能需要替换或删除(用 str.replace)![]()
三、存储文件
我将获得的数据写入csv文件(以下除了 import 写在定义任务的第一行)
这里模式必须是 'a' 而不能是 'w'!!!因为 'w' 模式每次写入都会覆盖掉上一次的内容,无法获得全部数据
import csv
data_table=open (r'C:\Users\yysc\Desktop\data_table.csv',mode='a',newline = '')
csv_writer=csv.writer(data_table)
# 实例化一个writer,将一行行data数据写入data_table再在for循环里加上写入文件的操作
for k in range(len(resp['list'])):
data=[resp['list'][k]['prodCat'],
resp['list'][k]['prodName'],
resp['list'][k]['lowPrice'],
resp['list'][k]['highPrice'],
resp['list'][k]['avgPrice'],
resp['list'][k]['prodName'],
resp['list'][k]['place'],
resp['list'][k]['unitInfo'],
resp['list'][k]['pubDate']]
csv_writer.writerow(data)
# 一行行写入,writerows是一次写入多行,这里用writerows表格会变得非常混乱
print('第'+parm['current']+'页提取完毕')
第1页提取完毕运行程序
if __name__ == '__main__':
single_page(url='http://www.xinfadi.com.cn/getPriceData.html') 成功获取了第一页的数据,我的目录是存在桌面的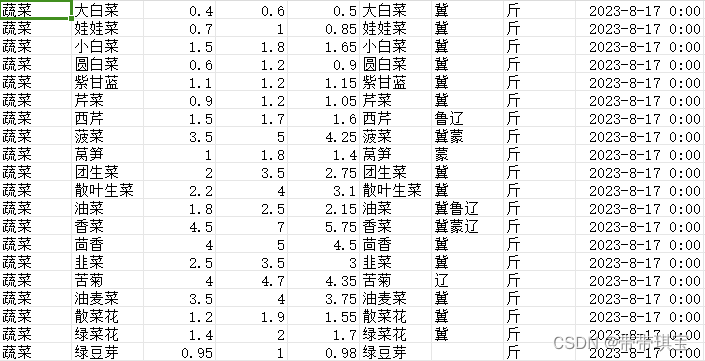
关于csv文件处理查看:
Python 使用csv库处理CSV文件_python csv库_一杯冰糖的博客-CSDN博客
四、上线程池获取所有数据
(一)循环执行
每次换页面的时候网页 url 其实并没有改变,只是参数 current 改变了
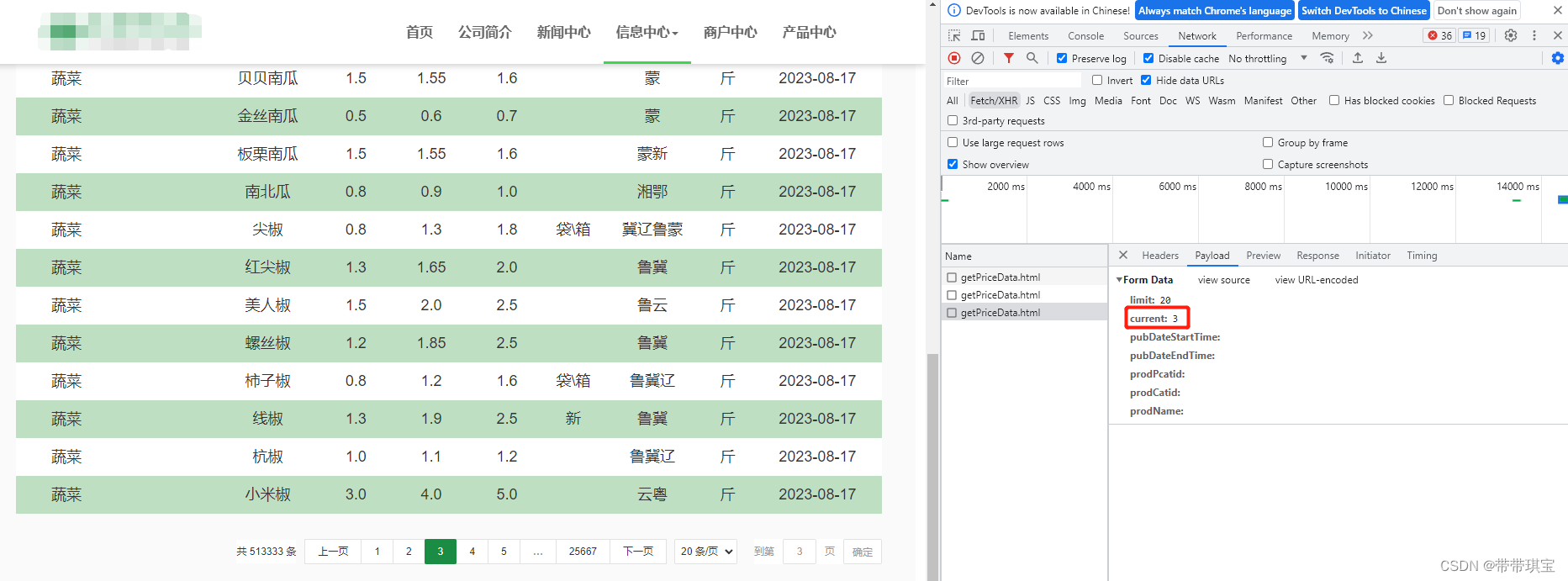
因此我将 parm 里面的 current 改为动态的,在每次发起请求时传入页面的参数,就能访问到不同页面了
def single_page(url,page):
parm={'limit': '20',
'current': page, # 该参数决定页面
'pubDateStartTime': '',
'pubDateEndTime': '',
'prodPcatid': '',
'prodCatid': '',
'prodName': ''}接下来循环执行程序,一共有25667页,则range(1,20668),页面是从第一页开始的没有第0页,左闭右开,运行时记得关闭文件!!
if __name__ == '__main__':
for i in range(1,10):
single_page(url='http://www.xinfadi.com.cn/getPriceData.html',
page=str(i))
# 传入url及page参数
(二)上线程池
提交任务给50个线程,submit的时候参数是通过逗号连接的
from concurrent.futures import ThreadPoolExecutor
if __name__ == '__main__':
with ThreadPoolExecutor(50) as t:
for i in range(1,100):
t.submit(single_page,url='http://www.xinfadi.com.cn/getPriceData.html',page=str(i))(三)对比时间
使用 time.perf_counter() 可以通过开始、结束的时间计算程序运行的时间,看出效率的提升情况,看看前一百页提取情况
import time
if __name__ == '__main__':
start_time_1=time.perf_counter()
for i in range(1,100):
single_page(url='http://www.xinfadi.com.cn/getPriceData.html',page=str(i))
end_time_1=time.perf_counter()
times_1=end_time_1-start_time_1
print('Mission I All Finshed!!Spent '+str(times_1))
# 加线程池
start_time_2=time.perf_counter()
with ThreadPoolExecutor(50) as t:
for i in range(1,100):
t.submit(single_page,url='http://www.xinfadi.com.cn/getPriceData.html',page=str(i))
end_time_2=time.perf_counter()
times_2=end_time_2-start_time_2
print('Mission II All Finshed!!Spent '+str(times_2))...
第99页提取完毕
Mission I All Finshed!!Spent 25.265385799999997
...
第90页提取完毕
Mission II All Finshed!!Spent 3.0848887000000005效率提升高了很多倍
后续看到家线程池文件里面有些地方是混乱的,原因可能跟CPU本身的调度有关,是不过不是此次探究的侧重点,暂不理会

五、代码
import requests
import random
import csv
import time
from concurrent.futures import ThreadPoolExecutor
def single_page(url,page):
data_table = open(r'C:\Users\yysc\Desktop\data_table.csv', mode='a', newline='')
csv_writer = csv.writer(data_table) # 实例化一个writer,将一行行data数据写入data_table
user_agent_list = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.200']
head = {'user-agent': random.sample(user_agent_list, 1)[0],
'Referrer Policy':'strict - origin - when - cross - origin'
}
parm={'limit': '20',
'current': page,
'pubDateStartTime': '',
'pubDateEndTime': '',
'prodPcatid': '',
'prodCatid': '',
'prodName': ''}
resp=requests.post(url,params=parm,headers=head).json()
for k in range(len(resp['list'])):
data=[resp['list'][k]['prodCat'],resp['list'][k]['prodName'],resp['list'][k]['lowPrice'],resp['list'][k]['highPrice'],resp['list'][k]['avgPrice'],resp['list'][k]['prodName'],resp['list'][k]['place'],resp['list'][k]['unitInfo'],resp['list'][k]['pubDate']]
csv_writer.writerow(data) # 一行行写入,writerows是一次写入多行
print(data)
print('第'+parm['current']+'页提取完毕')
data_table.close()
pass
if __name__ == '__main__':
start_time_1=time.perf_counter()
for i in range(1,6):
single_page(url='http://www.xinfadi.com.cn/getPriceData.html',page=str(i))
end_time_1=time.perf_counter()
times_1=end_time_1-start_time_1
print('Mission I All Finshed!!Spent '+str(times_1))
start_time_2=time.perf_counter()
with ThreadPoolExecutor(50) as t:
for i in range(1,100):
t.submit(single_page,url='http://www.xinfadi.com.cn/getPriceData.html',page=str(i))
end_time_2=time.perf_counter()
times_2=end_time_2-start_time_2
print('Mission II All Finshed!!Spent '+str(times_2))















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











