







引言
计算机图形学是一门将数学、计算机科学和艺术结合起来的学科,它在现代技术中扮演着越来越重要的角色。从游戏设计到虚拟现实(VR)、增强现实(AR)和元宇宙,计算机图形学的应用无处不在。它不仅为人们提供了沉浸式的体验,还推动了技术创新和产业发展。本文将详细介绍计算机图形学的基础知识,包括2D和3D图形学,并探讨其在现代技术中的应用。
第一部分:图形学基础
2D图形学
2D图形学是计算机图形学的基础,它涉及到像素、图像和视频的处理。理解这些基本概念对于掌握更高级的图形学技术至关重要。
像素、图像和视频的概念
像素是图像的基本单位,每个像素点可以包含颜色信息。像素的排列和组合形成了我们所看到的图像。图像可以是静态的,如照片或数字艺术作品,也可以是动态的,如视频。
图像是由像素组成的二维数组,每个像素点的颜色值决定了图像的整体外观。常见的图像格式包括JPEG、PNG和BMP。JPEG是一种常用的压缩图像格式,适合用于照片,而PNG则支持无损压缩和透明背景。
视频则是一系列连续的图像帧,通过快速播放这些帧来模拟动态效果。视频的流畅度由帧率(FPS)决定,即每秒钟播放的帧数。常见的视频格式包括MP4和AVI。

分辨率和颜色编码(RGB)
分辨率是衡量图像清晰度的指标,通常以像素数表示。例如,1920×1080(1080p)和3840×2160(4K)是常见的视频分辨率。分辨率越高,图像的细节越丰富,但同时文件大小也越大。
CMYK和RGB是两种不同的颜色模型,它们在颜色表示和应用上有着显著的区别:
- RGB(红绿蓝):
- 应用领域:主要用于电子显示设备,如电视、计算机显示器、手机屏幕等。
- 颜色混合:通过红、绿、蓝三种颜色光的不同强度混合来产生各种颜色,每个通道的值范围从0到255,可以组合出超过1600万种颜色,增加每种颜色的强度会使混合出的颜色更亮,减少强度则会使颜色变暗。
- 颜色表示:每种颜色的强度范围通常是0到255,颜色空间较大,能够显示丰富的颜色。
- 优点:适合显示设备,能够产生鲜艳、明亮的颜色。
- CMYK(青色、品红、黄色、黑色):
- 应用领域:主要用于印刷行业,如书籍、杂志、宣传册等。
- 颜色混合:通过青、品红、黄三种颜料的混合来产生各种颜色,黑色(K)用于增加颜色的深度和暗度。减少每种颜色的强度会使混合出的颜色更亮,增加强度则会使颜色变暗。
- 颜色表示:每种颜色的强度范围通常是0%到100%,颜色空间相对较小,主要用于再现印刷品的颜色。
- 优点:适合印刷,能够较好地模拟实际印刷效果。
主要区别:
- 显示方式:RGB是加色模式,通过光的叠加产生颜色;CMYK是减色模式,通过颜料的吸收和反射产生颜色。
- 颜色空间:RGB颜色空间通常比CMYK颜色空间更广,能够显示更多的颜色。
- 应用场景:RGB主要用于屏幕显示,而CMYK主要用于印刷。
- 转换问题:从RGB转换到CMYK时,可能会出现颜色的偏差,因为一些在RGB中能显示的颜色在CMYK中可能无法准确再现。
在实际应用中,了解这两种颜色模型的区别对于确保颜色在不同媒介上的一致性至关重要。

帧率(FPS)及其在不同设备中的应用
帧率(FPS)是衡量视频流畅度的重要指标,它表示每秒钟显示的帧数。常见的帧率有24 FPS(电影)、30 FPS(电视)和60 FPS(游戏)。高帧率可以提供更流畅的动画效果,但同时也需要更高的数据处理能力。不同的设备和应用对帧率的需求也不同。例如,电影通常使用24 FPS,而游戏则可能需要更高的帧率以提供更流畅的体验。
第二部分:3D动画
3D图形学是计算机图形学中的一个重要分支,它涉及到3D对象的创建、渲染和动画。这一部分将详细介绍3D动画的构成、向量和显示管线,以及矩阵在3D动画中的应用。

3D动画的构成
3D动画是通过将3D对象在虚拟环境中进行动态展示来实现的。这涉及到多个关键组件:
3D对象/网格
3D对象或网格是由多边形(通常是三角形或四边形)组成的,它们定义了物体的表面。每个多边形的顶点包含位置、颜色和纹理坐标等信息。通过这些多边形的组合,可以构建出复杂的3D模型。
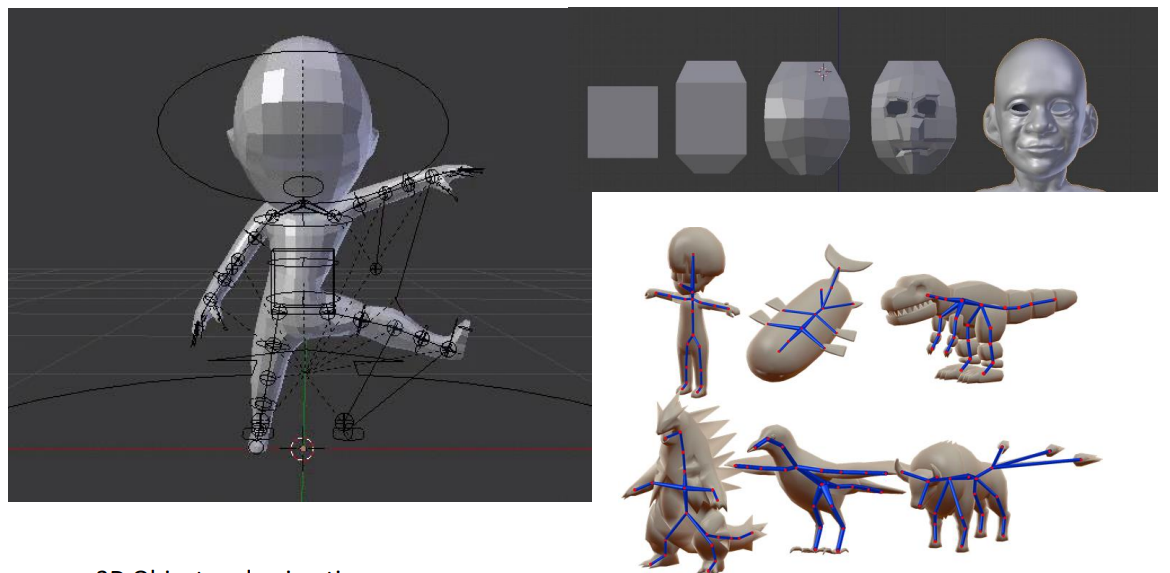
刚体和3D动画的结合
刚体是指在动画过程中不发生形变的物体。通过将刚体与3D动画结合,可以模拟物体在空间中的移动和旋转。这种动画通常用于模拟机械运动或物体的简单移动。
人类角色动画
人类角色动画是一种更复杂的动画类型,它涉及到骨骼和皮肤的绑定。通过骨骼动画,可以模拟角色的动作和姿态变化。这种动画在电影和游戏中非常常见,因为它可以提供更自然和逼真的视觉效果。
向量和显示pipeline
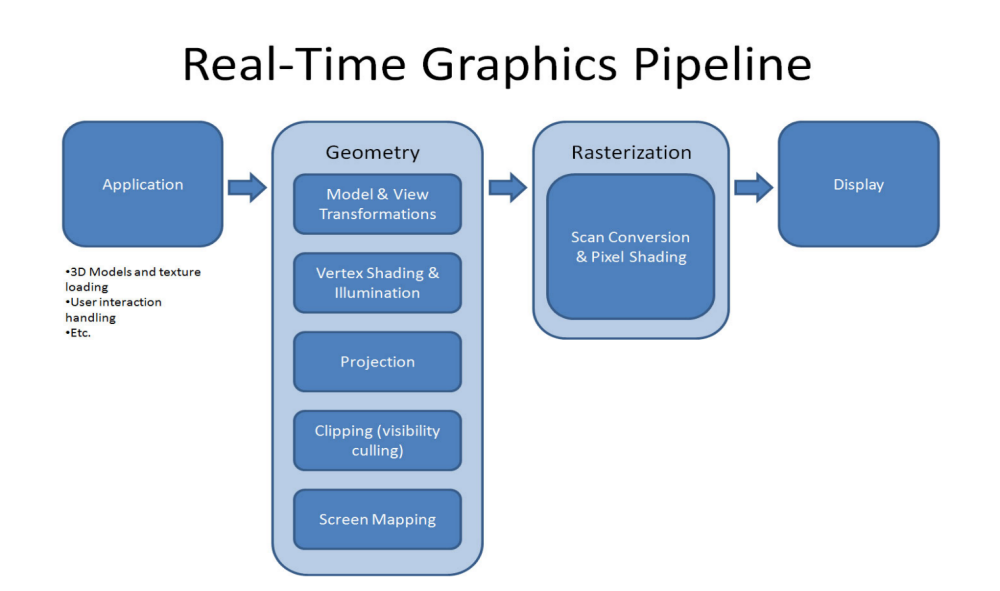
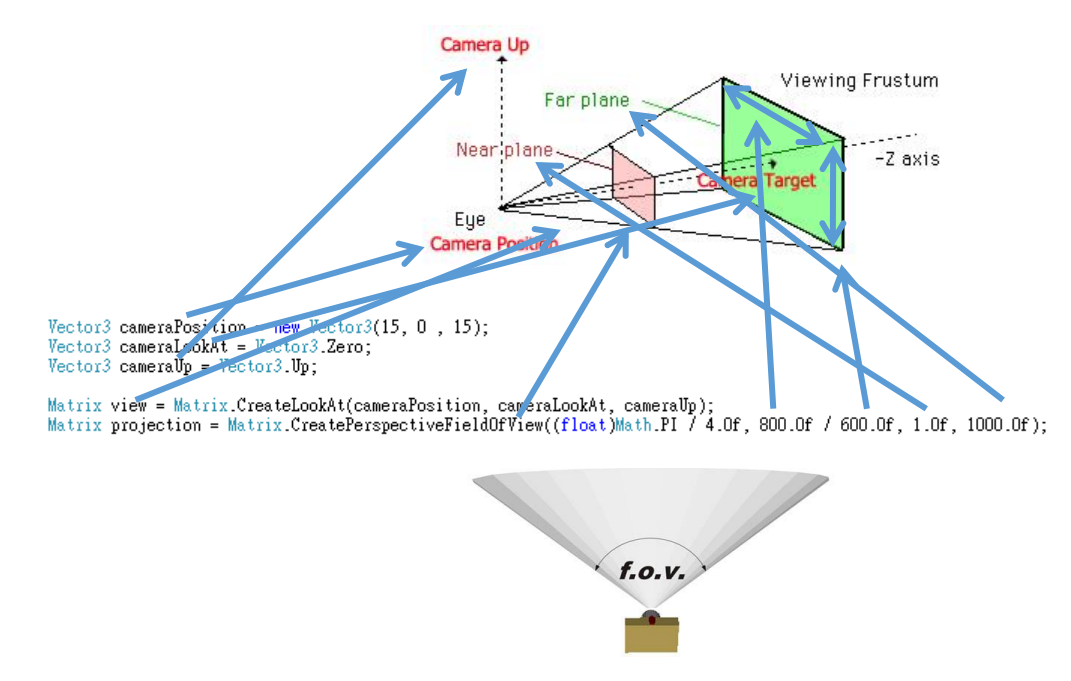
在3D图形学中,向量是描述物体位置和方向的基本工具。显示pipeline是将3D场景转换为2D图像的过程,涉及以下步骤:
- 世界坐标:定义物体在虚拟世界中的位置。
- 视图坐标:将物体的位置转换到观察者视角。
- 屏幕坐标:将视图坐标映射到2D屏幕上,形成最终的图像。
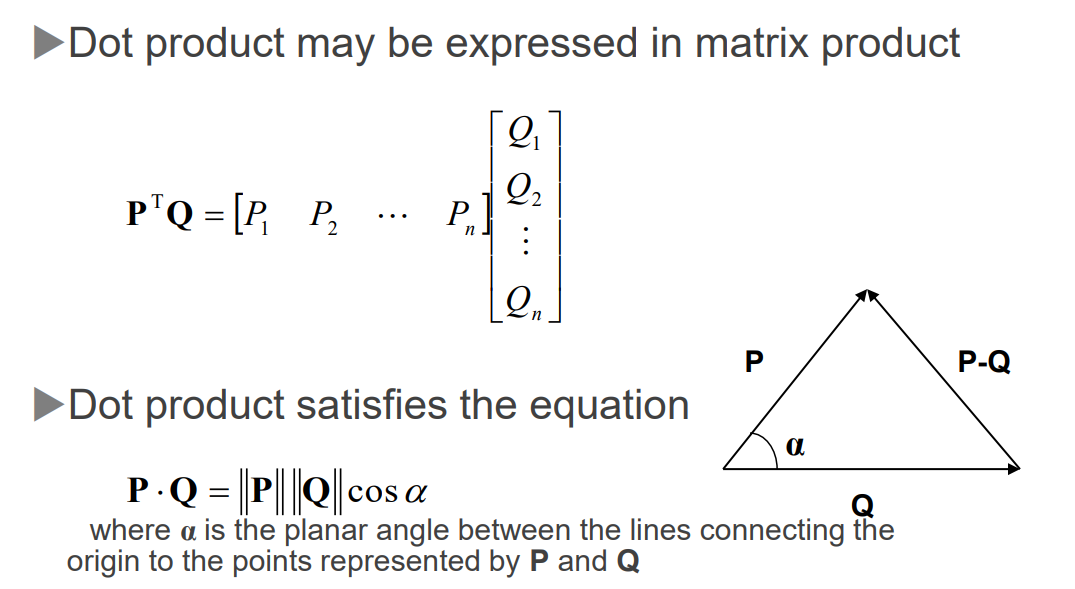
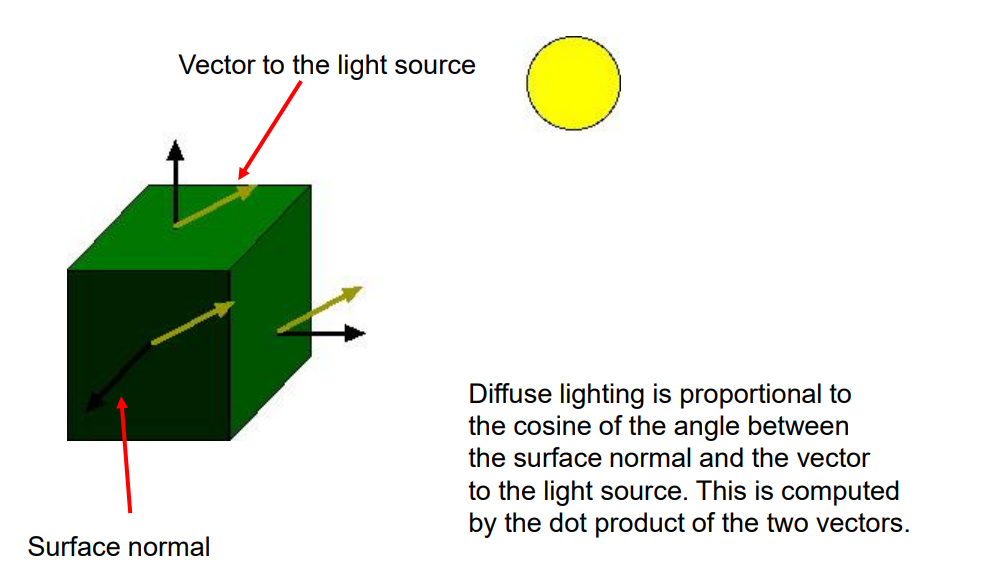
向量的基本属性和应用在游戏开发中尤为重要,例如在计算光照和阴影时。
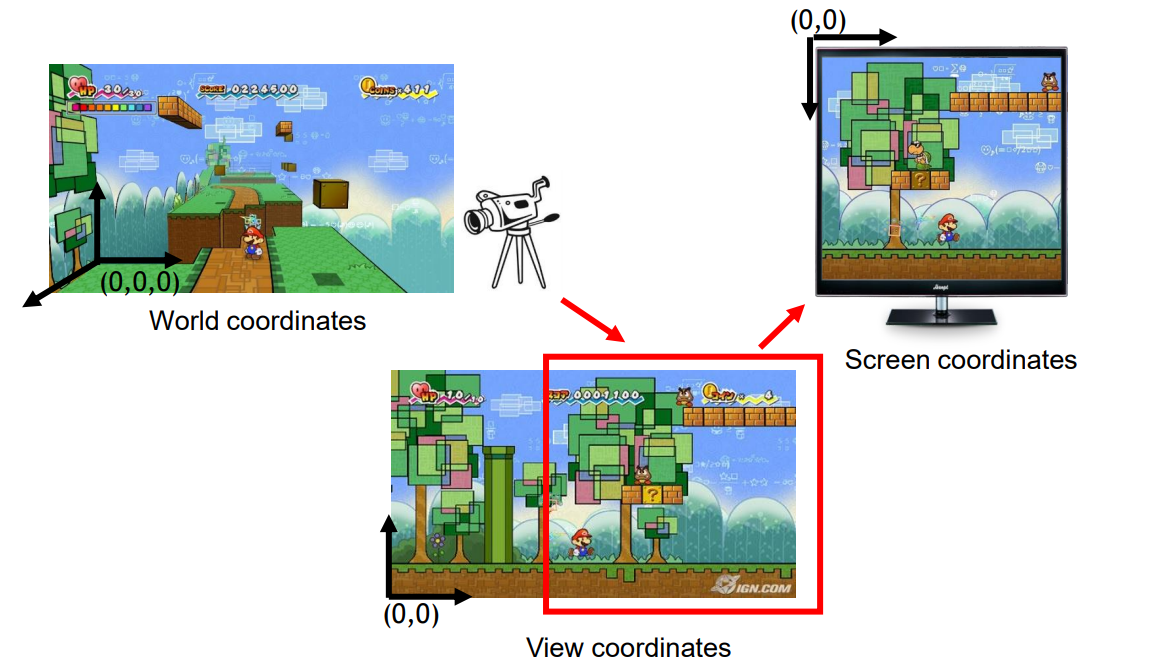
矩阵在3D动画中的应用
矩阵在3D动画中扮演着关键角色,它们用于描述和实现物体的变换,如平移、旋转和缩放。矩阵的基本属性包括其元素的排列和运算规则。

矩阵的基本属性
矩阵是一个由行和列组成的数阵。在3D图形学中,常用的是4x4矩阵,它不仅可以表示旋转、缩放和位移,还可以处理齐次坐标,从而简化变换的计算。
变换(平移、旋转和缩放)
- 平移:通过添加一个平移向量来移动物体。
- 旋转:通过旋转矩阵来改变物体的方向。
- 缩放:通过缩放矩阵来改变物体的大小。
第三部分:3D显示技术
虚拟现实(VR)和增强现实(AR)
虚拟现实(VR)技术通过头戴显示器完全替代现实世界的视觉体验,使用户感觉自己置身于一个完全虚拟的环境中。VR技术通常需要配合手柄或其他传感器来实现交互。
增强现实(AR)技术则在现实世界中叠加虚拟元素,增强用户的现实体验。AR技术可以通过智能手机、平板电脑或AR眼镜实现。
VR和AR技术的应用场景
- VR:适用于需要完全沉浸式体验的应用,如游戏、模拟训练和虚拟旅游。VR技术可以让用户完全置身于一个虚拟世界中,体验到与现实世界完全不同的环境和情境。
- AR:适用于需要增强现实体验的应用,如导航、教育和零售。AR技术通过在现实世界中叠加虚拟信息,帮助用户更好地理解和互动。
深度相机
深度相机(3D相机)就是终端和机器人的眼睛,其就是通过该相机能检测出拍摄空间的景深距离。通过深度相机获取到图像中每个点距离摄像头的距离,在加上该点在 2D 图像中的二维坐标,就能获取图像中每个点的三维空间坐标。

其原理是基本原理是,通过近红外激光器,将具有一定结构特征的光线投射到被拍摄物体上,再由专门的红外摄像头进行采集。这种具备一定结构的光线( 根据编码图案不同一般有条纹结构光enshape,编码结构Mantis Vision, Realsense(F200), 散斑结构光apple (primesense),会因被摄物体的不同深度区域,而采集反射的结构光图案的信息,然后通过运算单元将这种结构的变化换算成深度信息,以此来获得三维结构。
简单来说就是,通常采用特定波长的不可见的红外激光作为光源,它发射出来的光经过一定的编码投影在物体上,通过一定算法计算返回的编码图案的畸变来得到物体的位置和深度信息。

结构光深度相机的分类:主要分为单目结构光和双目结构光相机。
单目结构光容易受光照的影响,在室外环境下,如果是晴天,激光器发出的编码光斑容易太阳光淹没掉。
双目结构光可以在室内环境下使用结构光测量深度信息,在室外光照导致结构光失效的情况下转为纯双目的方式,其抗环境干扰能力、可靠性更强,深度图质量有更大提升空间。
此外,结构光方案中的激光器寿命较短,难以满足7*24小时的长时间工作要求,其长时间连续工作很容易损坏。因为单目镜头和激光器需要进行精确的标定,一旦损坏,替换激光器时重新进行两者的标定是非常困难的。
由于结构光主动投射编码光,因而适合在光照不足(甚至无光)、缺乏纹理的场景使用。

3D结构光目前的使用场景为:
第一,物体信息分割与识别,3D人脸识别,用于安全验证、金融支付等场景;
第二,体感手势识别,为智能终端提供新的交互方式;
第三,三维场景重建,利用深度相机生成的深度信息(点云数据),结合RGB彩色图像信息,可完成对三维场景的还原,可用于测距,虚拟装修等场景。
RGB双目
RGBD相机是一种能够同时捕捉颜色和深度信息的设备。它通过结合传统的RGB图像和深度图像,能够提供更丰富的环境信息。深度传感器则能够测量物体与相机之间的距离,生成深度图。这些技术在元宇宙中有着广泛的应用,如空间扫描、物体识别和交互。
光飞行时间法(TOF Time-Of-Flight)
通过红外发射器发射调制过的光脉冲,遇到物体反射后,用接收器接收反射回来的光脉冲,并根据光脉冲的往返时间计算与物体之间的距离。
这种调制方式对发射器和接收器的要求较高,光速那么快,对于时间的测量有极高的精度要求。
在实际应用中,通常调制成脉冲波(一般是正弦波),当遇到障碍物发生漫反射,再通过特制的CMOS传感器接收反射的正弦波,这时波形已经产生了相位偏移,通过相位偏移可以计算物体到深度相机的距离。


第四部分:文件格式和数据交换
文件格式
压缩与未压缩文件格式的比较
文件格式是存储和传输图像和视频的关键。压缩文件格式如JPEG、MP3、MPEG-4等,通过压缩算法减小文件大小,便于存储和传输。然而,压缩算法可能会损失数据,尤其是在“有损”格式中。与此相对的是未压缩文件格式,如BMP、RAW,它们保留了原始数据的完整性,但文件大小较大。
压缩文件格式的主要优势在于其较小的文件大小,这使得它们在存储和传输时更为高效。常见的压缩格式包括JPEG(图像)、MP3(音频)和MPEG-4(视频)。这些格式通过减少数据冗余来减小文件大小,但可能会牺牲一些图像或音频质量。
未压缩文件格式如BMP和RAW,保留了图像或视频的全部数据,因此能够提供更高的质量。这些格式通常用于专业领域,如摄影和电影制作,因为它们允许在后期处理中进行更多的调整。

常见的压缩格式(如JPEG、MP3、MPEG-4)和未压缩格式(如BMP、RAW)
- JPEG:一种广泛使用的图像压缩格式,支持有损压缩。它适用于照片和网页图像,因为它可以在保持可接受质量的同时显著减小文件大小。
- MP3:一种音频压缩格式,通过减少音频数据的冗余来减小文件大小。它是数字音乐的标准格式之一。
- MPEG-4:一种视频压缩格式,支持有损压缩。它广泛应用于视频流和视频下载。
- BMP:一种未压缩的图像格式,保留了图像的全部数据。它通常用于图像编辑和打印,因为其质量不受压缩影响。
- RAW:一种未压缩的图像格式,直接从相机传感器捕获数据。它提供了最大的灵活性和质量,但文件大小较大。

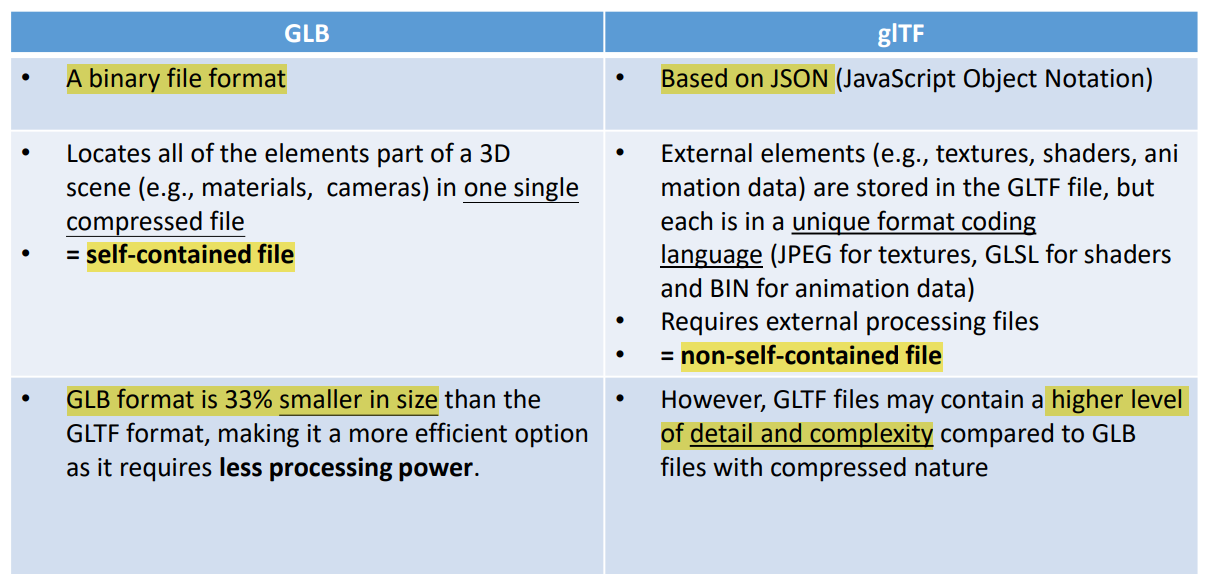
GLB和glTF文件格式
GLB和glTF是两种广泛使用的3D文件格式,它们在元宇宙和3D内容创作中扮演着重要角色。
GLB文件格式的结构和优势
GLB(GL Transmission Format Binary)是一种二进制文件格式,它将所有3D场景元素(如材质、相机、动画数据)打包在一个压缩文件中。这种格式的优势在于其轻量级和易于分享,适用于移动和网络应用。GLB文件格式的结构包括:
- JSON数据部分:包含关于3D模型的元数据,如节点层次结构、纹理和动画。
- 二进制缓冲区:包含实际的3D几何数据,如模型顶点的位置、法线和UV坐标。
GLB与glTF的比较
- GLB:是一个二进制文件,所有数据都被打包在一个文件中,便于传输和加载。GLB文件通常比glTF文件小,加载速度更快。
- glTF:基于JSON,是一种开放的文件格式,支持更复杂的数据和外部资源的引用。glTF文件通常包含更多的细节和复杂性,但文件大小较大。
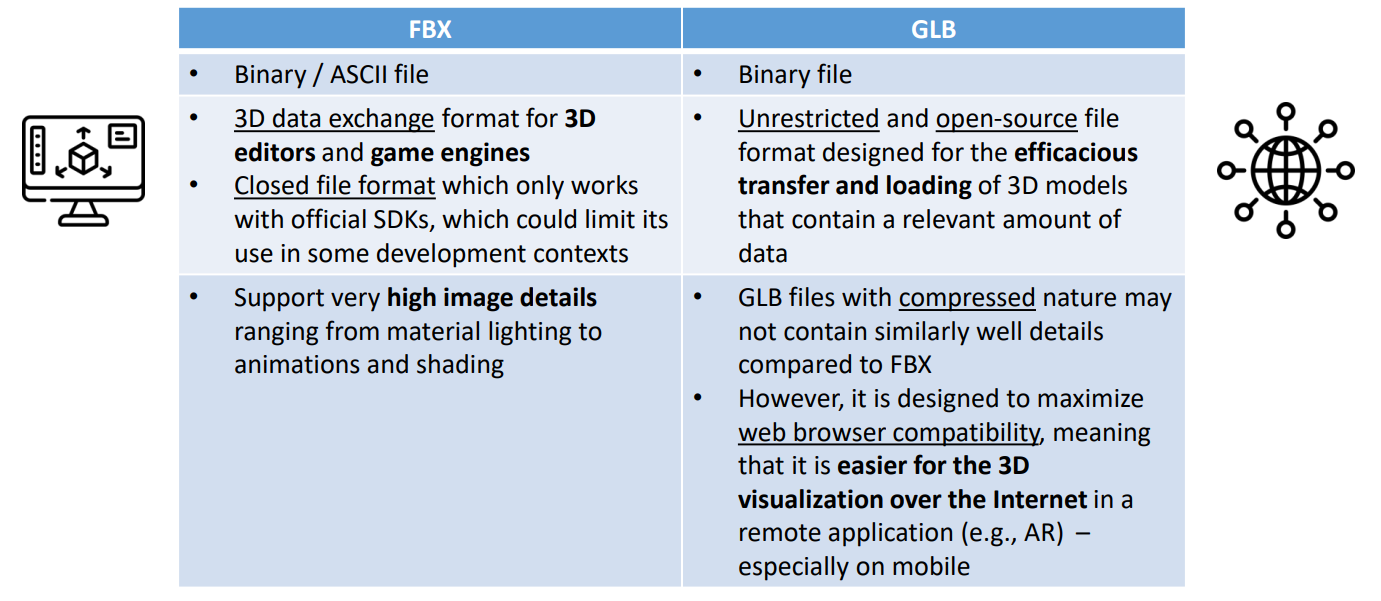
FBX文件格式
FBX文件格式是一种3D数据交换格式,广泛用于3D编辑和游戏引擎。FBX文件包含网格、材质、纹理和骨骼动画数据,适合用于复杂的3D场景。
FBX文件的特点和应用
- 特点:FBX文件是二进制或ASCII文件,支持高图像细节,包括材质、灯光、动画和着色。FBX文件可以导出和导入到多种3D软件和游戏引擎中。
- 应用:常用于电影制作、游戏开发和虚拟现实项目,因为它能够处理复杂的3D数据和动画。
FBX与GLB的比较
- FBX:更注重细节和复杂性,适合专业3D建模和动画制作。FBX文件通常较大,但提供更多的灵活性和控制。
- GLB:更注重效率和兼容性,适合网络传输和移动应用。GLB文件较小,加载速度快,但可能不支持FBX文件中的某些高级功能。
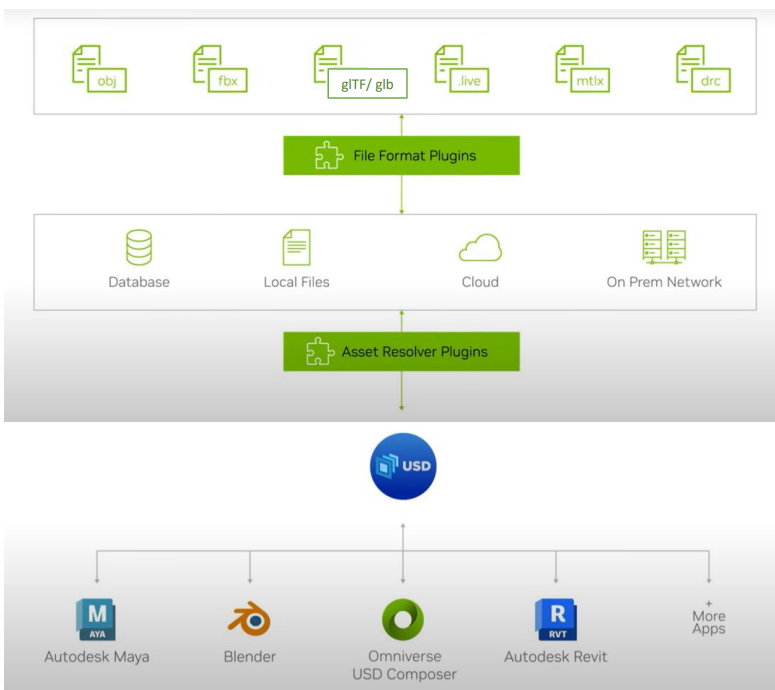
OpenUSD和Omniverse
OpenUSD(Universal Scene Description)是一种开放的3D文件格式和协作框架,由皮克斯动画工作室开发。它支持快速的二进制流传输和大规模数据存储,适用于大型虚拟世界的构建。
OpenUSD的特点和优势
- 特点:OpenUSD支持层级化的数据组合,允许不同用户在不同层上修改场景,且这些修改是无损的。它还支持自定义模式,可以扩展数据模型。
- 优势:OpenUSD的生态系统开放且可扩展,支持与其他工具的互操作性,适合大规模协作和复杂的3D场景制作。
Omniverse平台的功能和应用
Omniverse是NVIDIA推出的一个计算平台,支持基于OpenUSD的3D工作流程和应用开发。Omniverse通过其Nucleus服务器实现不同软件之间的实时同步,极大地提高了团队协作的效率。
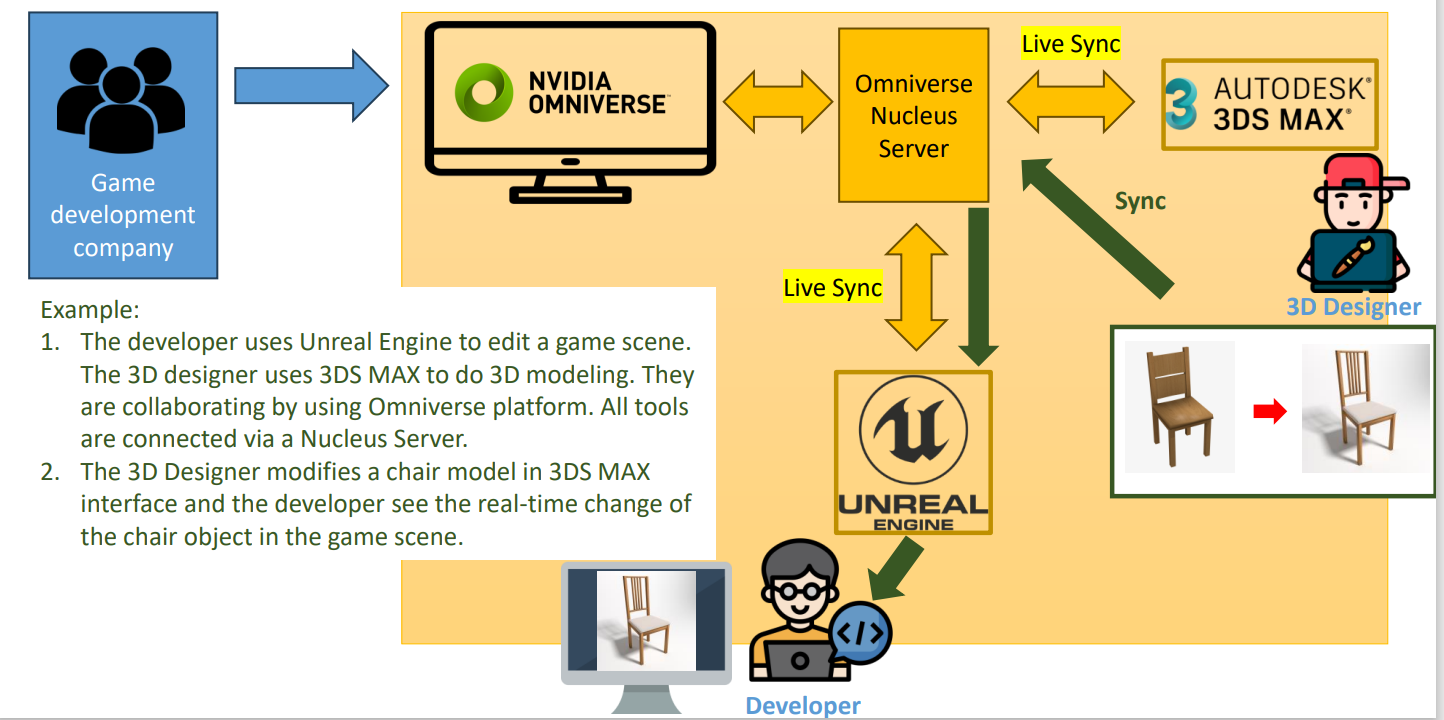
- 功能:Omniverse提供了多种工具和应用,如音频到面部动画转换、角色和环境动画制作等。它还支持与其他软件的实时同步,如Unreal Engine、3DS Max和Unity。
- 应用:Omniverse适用于电影制作、游戏开发和工业设计等领域,能够提高3D内容创作的效率和协作性。

第五部分:渲染技术
Voxel 渲染
Voxel 渲染是一种将3D场景分解为 Voxel (三维像素)并进行渲染的技术。这种方法在处理复杂场景时具有高效性,尤其是在动态规划算法的帮助下,可以优化渲染过程。

Voxel 渲染技术简介
Voxel 渲染通过将3D模型分解为许多小的立方体( Voxel ),每个 Voxel 可以独立渲染和处理。这种方法在处理大规模场景和复杂几何体时特别有效,因为它可以减少渲染时间和计算资源的消耗。
动态规划算法在体素渲染中的应用
动态规划算法是一种优化算法,可以用于体素渲染中,通过将渲染任务分解为更小的子任务,并合理安排这些子任务的执行顺序,从而提高渲染效率。这种方法特别适用于需要大量计算的复杂场景。
NeRF(神经辐射场)
NeRF是一种利用深度神经网络从2D图像合成3D场景的技术。这种方法通过学习图像中的光线和颜色信息,生成逼真的3D场景。
NeRF技术简介
NeRF通过训练深度神经网络,学习如何从2D图像中提取3D信息。这种方法可以生成逼真的3D场景,甚至可以从单张图片中重建复杂的3D结构。
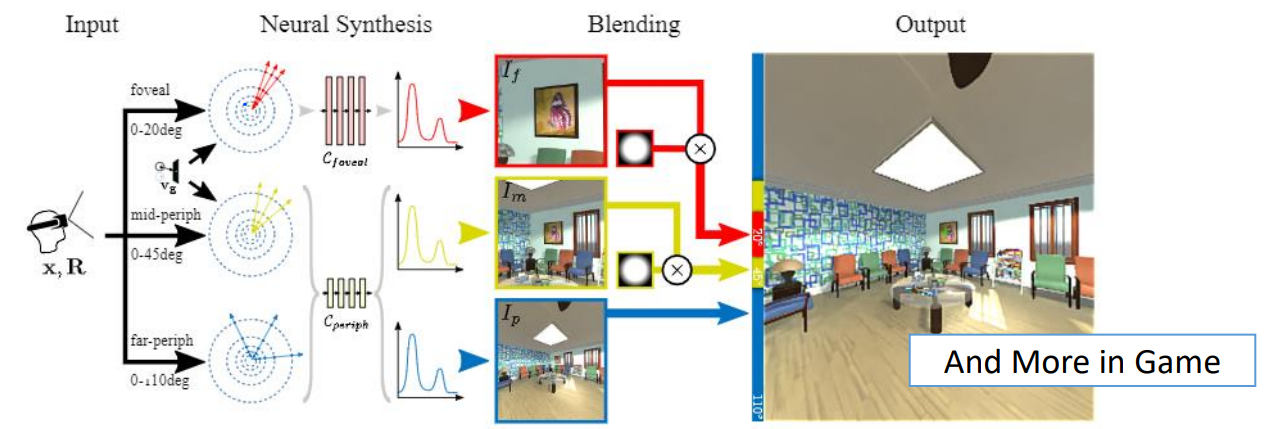
从2D图像合成3D场景的示例
通过NeRF技术,可以从单张2D图片中生成3D场景。例如,通过分析图片中的光线和阴影,神经网络可以推断出物体的几何形状和表面材质。这种方法在虚拟摄影和数字孪生领域具有巨大的潜力,能够实现从现实世界到数字世界的无缝转换。
通过这些先进的技术和工具,计算机图形学不仅在电影和游戏制作中发挥着重要作用,还在建筑设计、医学成像和科学研究等领域展现出巨大的潜力。随着技术的不断进步,计算机图形学将继续推动数字世界的创新和发展。
总结
计算机图形学在2D、3D和元宇宙中的应用广泛且深远。在2D领域,它通过像素操作、图像处理和视频制作,为数字艺术、游戏和动画提供了基础。3D图形学则通过复杂的模型构建、动画和渲染技术,推动了电影、游戏和虚拟现实的发展。元宇宙则将这些技术融合,创造了一个全新的数字世界,允许用户在虚拟环境中进行沉浸式体验和交互。
未来,计算机图形学将面临更多挑战和机遇。随着AI和机器学习技术的融入,虚拟角色和环境的智能化将成为趋势。同时,随着VR和AR技术的成熟,元宇宙的体验将更加真实和互动。然而,这也带来了数据隐私、用户体验和跨平台兼容性等挑战。此外,随着技术的发展,对更高效、更逼真的渲染技术的需求也在不断增加,这将推动计算机图形学在算法优化和硬件加速方面的创新。


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











