







引言
在自然语言处理(NLP)领域,预训练模型如BERT、GPT等在各种任务中展现出强大的性能。然而,这些模型在应用于特定任务时,通常需要进一步的微调(fine-tuning),即调整模型参数以适应新任务的数据分布。然而,传统的微调方法存在一些问题,如参数效率低下、难以扩展到大量任务以及可能导致的灾难性遗忘等。
本文将详细介绍Prefix Tuning的思路、结构、优点以及潜在的应用和挑战。首先,我们将概述Prefix Tuning的基本原理和动机;接着,详细阐述其技术实现和模型结构;然后,分析Prefix Tuning相比传统微调方法的优势;最后,讨论其在实际应用中的潜力和面临的挑战。
为什么还需要对GPT进行微调?
既然GPT已经通过各种数据集进行了问题回答、文本摘要、翻译或分类的训练,为什么还需要对GPT进行微调呢?
微调,使得模型在特定领域表现更好更稳定,而且使用成本大大降低。
微调GPT 有哪些挑战?
简单来说,定制一个GPT的意思是迭代更新其所有参数,以便它能够执行特定的工作。然而,大多数LLMs具有少则十几亿多则百亿千亿的参数,想更新所有参数非常昂贵,可能一个百亿个参数的物理文件大小都超过100GB。
如果更新一遍的微调GPT的难度很高,如何开发高效的微调方法?
解决的主要思路是不要改变那数十亿个预训练参数,而是添加一些参数层并只训练这些参数。
Prefix Tuning 核心概念
动机
传统的微调方法通过调整预训练模型的所有参数来适应新任务,这虽然有效,但存在几个显著的问题:
- 参数效率低下:每个新任务都需要一个全新的模型副本,这导致参数冗余和存储成本增加。
- 难以扩展:随着任务数量的增加,存储和训练成本迅速上升。
- 灾难性遗忘:在连续学习多个任务时,模型可能会忘记之前学习的任务。
为了克服这些问题,Prefix Tuning提出了一种新的思路:通过向预训练模型添加可训练的连续提示(prompts),而不是直接修改模型的主要参数,来实现对新任务的适应。
Prefix-tuning的概念
本文将解释Prefix-tuning (前缀微调),为了解释前缀微调,先从Prompts提示的概念开始。
Prompts (提示 )- 告诉GPT该做什么
让我们来思考一下如何使用GPT。如果你给出一个非常模糊的指令,你将无法从GPT得到一个好的答案。你的指令被称为“提示”。随着开发者开发出更大的GPT,你作为用户也学会了如何组织更好、更具体的提示,以便GPT知道如何相应地进行操作。让我们考虑一个可以产生良好结果的具体提示:
- 用小红书风格写十条高考新闻。
GPT将在其记忆中搜索十条高考新闻,然后提取信息以小红书风格写入。
- 以头条风格写十条最新的高考新闻。
GPT会修改新闻并提取信息,以头条风格的风格写成。
注意两个提示之间唯一的区别是小红书或头条的风格。提示告诉GPT要提取什么,以生成所需的结果。
受prompt的启发,有了微调方法Prefix-tuning:它在GPT的编码器和解码器之前添加前缀层,同时保持GPT的所有参数不变。因为它是GPT的预处理步骤,所以被称为前缀。前缀的作用类似于提示,告诉GPT在编码器中提取什么信息,以便在解码层生成正确的结果。
基本原理
Prefix Tuning的核心思想是在预训练模型的输入层之前添加一系列可训练的连续向量(即前缀),这些前缀作为额外的输入与原始输入一起被模型处理。通过优化这些前缀的参数,模型可以学会生成适应新任务输出的提示,而无需改变模型的主要参数。
Prefix-tuning 的灵感来自提示语。提示告诉我们,如果环境准备得好,就可以通过提示来引导GPT生成所需的结果,而不需要改变其数十亿个参数。文章“Prefix-tuning: Optimizing Continuous Prompts for Generation”[1]的作者提出了这种Prefix-tuning微调方法。
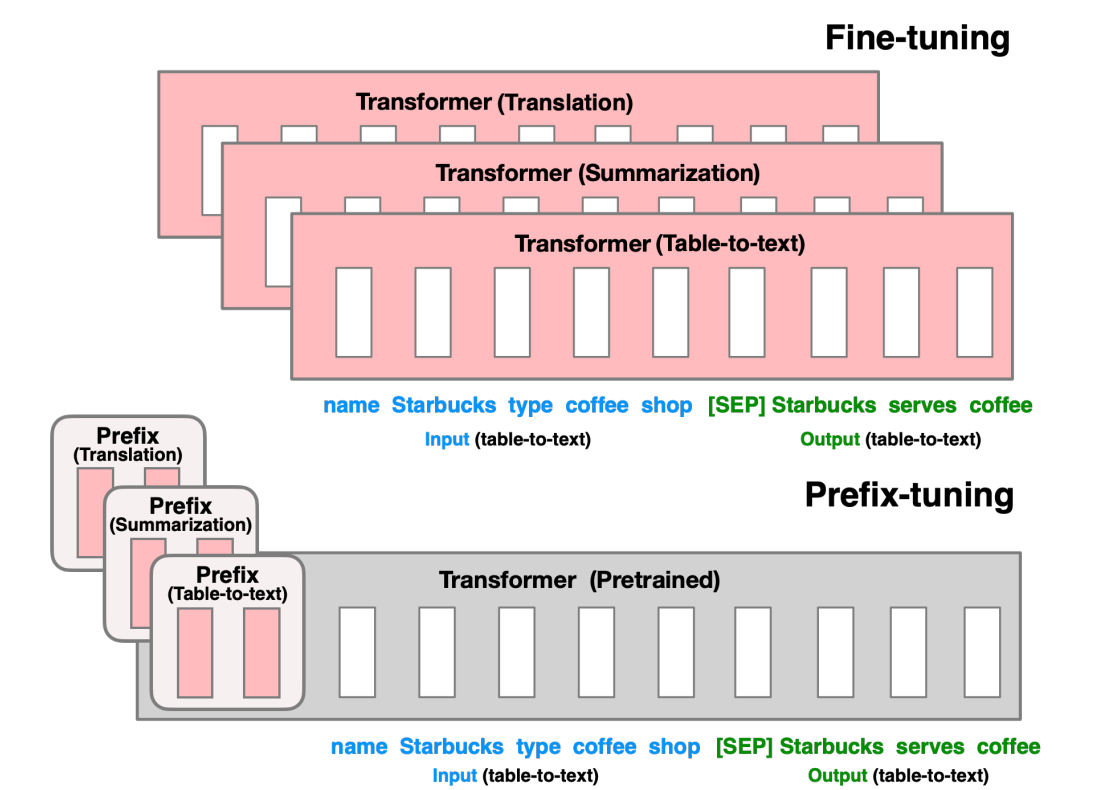
上图展示了所有参数的微调和Predix调整。作者举了一个例子,可以为数据表生成文本描述。
在(A)中,表格的输入数据是“名称”、“星巴克”、“类型”、“咖啡”和“商店”。它们被作为X(蓝色)输入到模型中。
输出Y是一个完整的句子“[SEP]星巴克提供咖啡”(绿色)。分隔符[SEP]只是用来分隔输入和输出。这里的模型可以是任何基于transformer的模型。如果目标是进行翻译、文本摘要或表格到文本转换(可能还有更多),则需要三个定制模型来完成每个任务。
那Prefix-tuning的新颖之处是什么?它在transformer模型前添加一个前缀。该前缀包含自由参数,可以在保持模型所有参数不变的情况下进行训练。如果有三个任务(翻译、摘要、表格到文本),只需要为每个任务训练前缀。当三个任务的训练完成后,只需存储三个前缀,并保留一个transformer模型的copy。由于GPT的物理大小达到几个GB,Prefix tuning并不需要存储三个GPT的copy,因此,它是空间高效且轻量级的。
Prefix Tuning的技术实现
模型结构
Prefix Tuning的模型结构相对简单,主要包括以下几个部分:
- 预训练模型:这是基础模型,如BERT、GPT等,其参数在训练过程中保持不变。
- 前缀向量:一系列可训练的连续向量,作为额外的输入添加到预训练模型的输入层之前。
- 输出层:根据任务需求设计的输出层,用于生成最终的输出。
在训练过程中,只有前缀向量的参数是可训练的,预训练模型的参数被冻结。这种设置使得Prefix Tuning在参数效率上远高于传统的微调方法。
Prefix-tuning方法的架构是什么?
像GPT2这样的自回归模型具有X输入和Y结果。GPT2的提示将引导它从X中提取什么以生成Y。基于这种直觉,Prefix-tuning在X之前添加前缀层以引导提取内容。图2展示了一个表格到文本的例子,其中输入X是一个表格“Harry Potter, Education, Hogwarts”,输出是一个描述“[SEP] Harry Potter graduated from Hogwarts”。([SEP]是一个分隔符)

Prefix-tuning将X和Y连接起来,然后在X的前缀中添加前缀,如图2所示。前缀中的参数将影响从中提取生成Y的内容。
在微调期间,前缀中的参数将被训练来记住从X中提取生成Y的信息。前缀调整初始化一个可训练的自由矩阵来存储前缀参数。前缀矩阵不需要很大。[1]的作者报告说,他们仅初始化了GPT参数数量的0.1%,就实现了其他微调方法所做的同等性能。如果是百亿参数的LLM大模型,则前缀调整将在1100万个参数上进行训练,训练规模的减少使得普通人都可以机会实现。
Prefix 前缀如何添加到Transformer模型中?
图3展示了Transformer中的多头注意力块。多头注意力图像与论文“Attention is all you need”(Vaswani等人,2017)中所示相同。自注意力块有三个输入:查询矩阵(Q)、键矩阵(K)和值矩阵(V)。现在我们开始了解Transformer的结构。Prefix-Tuning将可训练的前缀向量PK添加到键矩阵K中,将可训练的前缀向量PV添加到值矩阵V中。(有关信息参考[3])。

训练过程
Prefix Tuning的训练过程可以分为以下几个步骤:
- 初始化前缀向量:随机初始化一系列前缀向量,并将其添加到预训练模型的输入层之前。
- 前向传播:将包含前缀向量的新输入送入预训练模型,得到模型的输出。
- 损失计算:根据任务目标计算输出与目标之间的损失。
- 反向传播:通过梯度下降等优化算法更新前缀向量的参数,以最小化损失。
- 迭代训练:重复上述步骤,直到模型在验证集上的性能达到满意水平。
Prefix Tuning的特点
Prefix Tuning和Prompt Tuning最大的区别就是向每层的Transformer Block添加可训练的张量,而上一期的Prompt Tuning只是在输入的时候添加。

此外,通过全连接层(具有两层的迷你MLP和介于两者之间的非线性激活函数)来进行桥接。下图左侧为原始的Transformer块,而右侧为添加之后的Prefix Tuning架构。

根据最初的Prefix Tuning的论文,这种技术实现了与全微调的性能,然而只需要训练0.1%的参数(当然当时它对标的是GPT-2模型)。有一种猜测它的表现如此的好,是因为它调整了较少的参数,有助于减少较小训练上面的过渡拟合。下面第一行为全部参数微调训练,第五行为Prefix Tuning。

优点
相比传统的微调方法,Prefix Tuning具有以下几个显著的优点:
- 参数效率高:由于只有前缀向量的参数是可训练的,因此模型的总参数数量大大减少,降低了存储和计算成本。
- 易于扩展:由于预训练模型的参数保持不变,因此可以轻松地添加新的前缀向量来适应新的任务,而无需重新训练整个模型。
- 避免灾难性遗忘:由于预训练模型的参数被冻结,因此在连续学习多个任务时,模型不会忘记之前学习的任务。
- 灵活性高:前缀向量可以针对不同的任务进行定制,从而实现更精细化的控制。
总结
从上述论文解读中,我们收获了如下技术观点:
- Prefix Tuning的价值:追求一套预训练模型,搞定多个下游任务。
- Prefix Tuning的核心思想:增加一个新的具备提示能力的前缀向量小模型,微调小模型的少量参数,冻结预训练模型的海量参数。
- Prefix Tuning的工程实践经验:
-
- Prefix长度不宜过长或过短,需根据下游任务实验获得。
- 对Transformer做全层的Prefix效果更好。
- Prefix会影响x和y,效果优于Infix。
- Prefix的初始值需选择与下游任务相关的提示向量。
















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











