







近年来,随着生成式AI(Generative AI)和大型语言模型(LLMs)的快速发展,这些技术在商业领域的应用愈发广泛。特别是在构建企业知识图谱(Knowledge Graph,KG)方面,生成式AI和LLMs的结合为企业数据管理和知识共享提供了新的可能。本文将详细介绍如何利用生成式AI和维基知识库(Wikibase)构建企业知识图谱问答系统,并探讨其在实际应用中的潜力和挑战。
原文链接:
https://aclanthology.org/2024.kallm-1.4.pdf
引言
知识图谱用于表示实体和实体之间关系的语义网络,通过将数据结构化为图的形式,能够有效地集成和组织知识。在企业环境中,知识图谱可以帮助企业更好地理解内部数据和业务流程,提升决策效率。而生成式AI,特别是大型语言模型(LLMs),通过强大的文本生成能力,使得知识图谱可以通过自然语言交互,极大地提高了用户的使用体验。
知识图谱:数据的语义网络表示
知识图谱(Knowledge Graphs, KG)是一种用图结构来表示信息的语义网络,其中实体作为节点,关系作为边。这种结构能够高效地整合和组织多样化的数据,为各种应用提供强有力的知识支持。知识图谱在劳动力市场、教育方法和医学等多个领域均展现出了巨大的应用价值。例如,在医学领域,知识图谱能够帮助医生快速检索和分析病例,提高诊疗效率;在教育领域,则能助力教育机构更好地理解学生的学习动态,优化教学资源配置。
知识图谱之所以能在人工智能(AI)领域备受青睐,关键在于其清晰性和灵活性。通过将知识图谱与AI技术(如微软的Azure OpenAI)结合,可以极大地提升大数据的集成和分析能力,实现更高效、更准确的数据处理。在这一背景下,Wikibase作为一个开源的知识库构建工具,为知识图谱的创建提供了强有力的支持。Wikibase允许异构数据的集成、灵活的数据模式建模和协作知识策划,使得构建全面且最新的知识图谱成为可能。
大型语言模型:重塑人机交互方式
大型语言模型(LLMs)以其庞大的规模和复杂的架构,正在彻底改变自然语言处理领域。这些模型经历了严格的数据收集、预处理、模型选择、训练和微调等阶段,旨在实现最佳性能。生成式AI应用正是基于这些模型,能够生成高质量的自然语言文本,与用户进行流畅的交互。
然而,LLMs并非完美无缺。它们在扩展或修改记忆方面存在困难,预测缺乏透明度,甚至可能生成不符合事实的内容(即“幻觉”)。为了克服这些局限性,研究人员提出了检索增强生成(Retrieval-Augmented Generation, RAG)技术。RAG通过结合训练数据与公司数据,使得LLMs能够访问和解释更多相关信息,从而提升问答系统的准确性和可靠性。
知识图谱的构建
详细技术内容参考:
GraphRAG:知识图谱与RAG智能融合新纪元_微软 graphrag relationship-CSDN博客
Wikibase的优势
在构建企业知识图谱时,技术选型至关重要。在构建企业知识图谱时,Wikibase凭借其易于集成、灵活建模和协作编辑的特性,成为理想的选择。Wikibase不仅支持从多种数据源导入数据,还通过SPARQL查询语言提供了强大的数据检索能力,极大地简化了数据管理和查询流程。
数据集成与本体定义
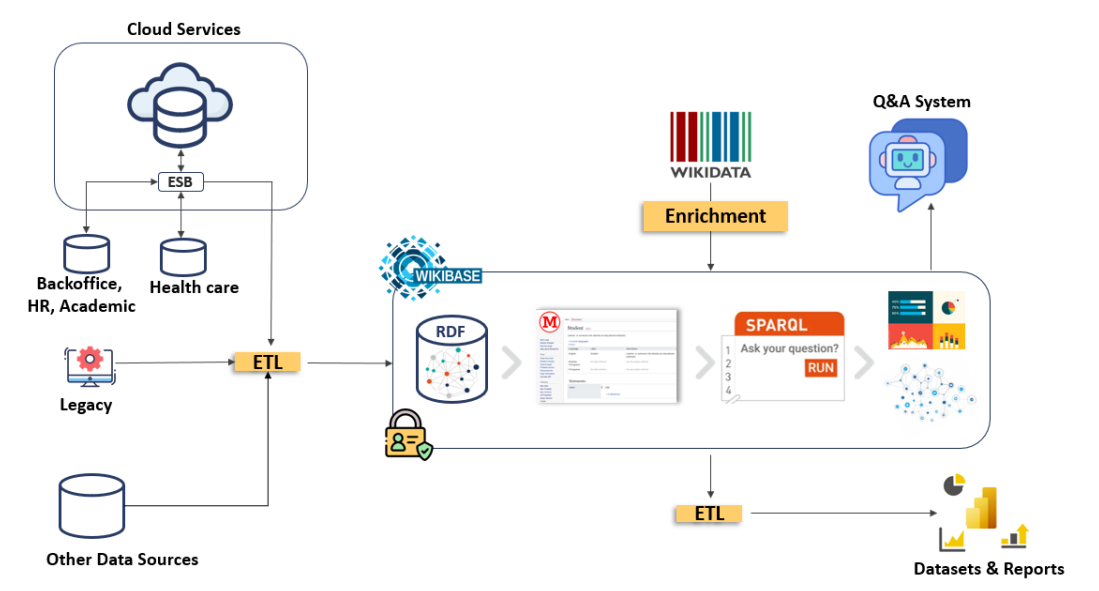
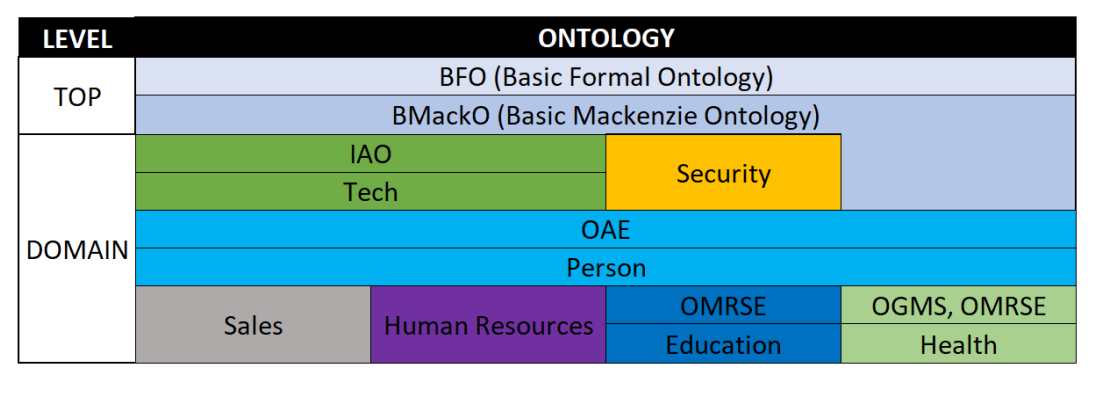
在构建知识图谱时,首先需要从企业内部各种数据源中提取数据,并通过ETL(Extract, Transform, Load)流程将数据加载到Wikibase中。数据的结构化和标准化是构建高质量知识图谱的基础。通过定义本体(Ontologies),我们可以清晰地定义知识图谱中的实体、属性和关系,从而构建一个结构清晰、易于理解的知识图谱。
在本案例中,企业知识图谱的本体基于基础形式本体(BFO)进行扩展,涵盖了技术、安全、人员、销售、人力资源、教育和医疗等多个领域。这些本体通过继承和引用,形成了一个层次分明的本体结构,为数据集成和查询提供了坚实的基础。
生成式AI在数据生成中的应用
在原型开发阶段,为了保护敏感数据,我们使用了生成式AI模型(如GPT-3)来生成高质量的合成数据。这些数据模拟了企业内部的真实数据,包括学生和患者的相关信息,同时避免了隐私泄露的风险。
实践案例:Mackenzie Presbyterian Institute的知识图谱问答系统
系统架构与实现
整个系统架构包括数据收集、知识图谱构建、问答系统开发和用户交互界面等多个环节:
- 数据收集:从内部数据源中提取实体和关系信息,包括学生信息、患者服务记录等。
- 知识图谱构建:使用Wikibase作为知识库构建工具,将收集到的数据转化为图结构表示,并通过定义本体来规范实体和关系的表达。
- 问答系统开发:基于LLMs(大型语言模型)构建问答系统,采用RAG(检索增强生成)技术整合公司数据和训练数据。系统能够理解用户的自然语言查询,并转化为SPARQL查询语句,在知识图谱中检索相关信息并生成回答。
- 用户交互界面:开发直观的用户交互界面,如聊天机器人或Web应用,使用户能够方便地通过自然语言与系统进行交互。
实验结果与应用前景
实验结果表明,该系统在回答简单查询时表现出色,尤其是在与私有知识图谱结合使用时,正确率显著提高。然而,处理复杂查询时仍存在一定挑战,如生成不符合事实的回答或漏检相关信息。展望未来,随着技术的不断进步和应用场景的不断拓展,知识图谱问答系统在企业中的应用前景将更加广阔。
知识图谱问答系统的构建
技术架构
为了构建知识图谱问答系统,我们采用了基于生成式AI的推理代理(Re-Act Agent)技术。该技术通过Python函数与Wikidata API交互,将用户问题转换为SPARQL查询,并从知识图谱中检索相关数据,最终生成人类可读的答案。
系统开发与改进
在现有GitHub仓库Langchain Wikibase的基础上,我们对Re-Act Agent进行了扩展和改进,使其能够支持本地Wikibase实例的查询,并通过Gradio库开发了一个简单的聊天机器人界面。此外,集成了多种LLMs(如Gemini 1.0 Pro和Mixtral 8×7B)以测试不同模型在问答系统中的表现。
测试结果与分析
测试结果显示,生成式AI驱动的问答系统在处理简单问题时表现出色,但在处理复杂计算或外部数据的问题时仍需优化。这主要归因于LLMs在生成SPARQL查询时的局限性以及训练数据与企业知识图谱之间的不匹配。
总结
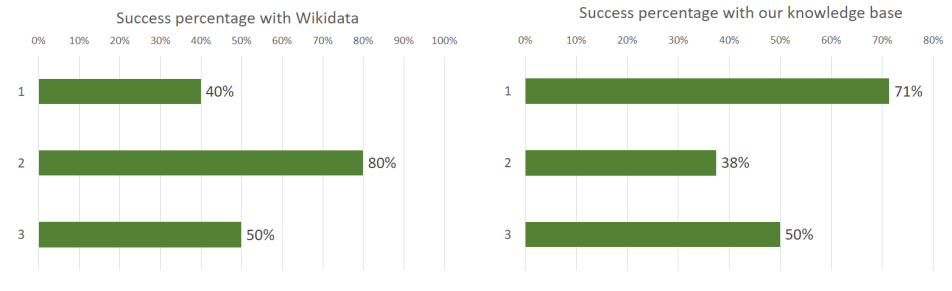
即使在原型阶段,知识图谱问答系统也表现出良好的命中率,尤其是在简单问题上。如图所示,当连接到私有知识图谱时,Re-Act代理在回答类型1问题时表现显著更好,正确率提高了31%。这一改进可以归因于企业知识图谱(EKG)仅限于公司感兴趣的主题,而Wikidata则涵盖了广泛的主题。类型2问题在本地EKG和Wikidata之间的差异可能是由于Wikidata的训练数据,因为Gemini 1.0pro知道许多PID和QID。连接到私有EKG的Re-Act代理生成的答案会包含一些Wikidata属性,导致SPARQL端点返回空结果。使用更健壮的LLM(如Gemini1.5pro或GPT-4)并对模型进行微调以更好地生成SPARQL查询可能会解决这个问题并提高成功率。此外,当使用高级LLM版本时,提供商保证不会使用私有数据来训练模型,使其适合生产版本。
在隐私方面,改进知识图谱的一个机会是根据认证用户的配置文件来隔离对项目的访问,并对提交给SPARQL端点和Wikibase查询服务(WDQS)的SPARQL查询进行访问隔离的复制。
迄今为止获得的结果有利于采用知识图谱作为数据集成解决方案,并采用LLM为企业数据构建自然语言搜索和响应界面。尽管在企业环境中采用如Wikibase这样的开放知识图谱解决方案存在隔离数据访问的挑战,但Wikidata查询服务的开箱即用数据可视化选项和Wikibase docker swarm实现的水平扩展。
应用场景
企业知识图谱问答系统具有广泛的应用场景,包括信息查询、决策支持和知识共享等。员工可以通过自然语言查询快速获取所需信息,提升工作效率;同时,基于知识图谱的数据分析也能为企业决策提供有力支持。
面临的难点
尽管企业知识图谱问答系统具有诸多优势,但在实际应用中仍面临一些难点:
- 数据隐私与安全:确保数据在生成、存储和查询过程中的隐私与安全是首要问题。
- 模型训练与优化:生成式AI模型需要大量数据进行训练和优化,且不同模型在生成SPARQL查询时的表现各异。
- 系统集成与维护:将问答系统集成到企业现有IT架构中,并保持系统的稳定性和可维护性是一个复杂的过程。
企业知识图谱问答系统的开发为企业数据管理和知识共享提供了新的解决方案。通过生成式AI和大型语言模型的结合,能够实现高效、准确的自然语言查询,显著提升用户的使用体验。在推广和应用过程中,仍需解决数据隐私、模型优化和系统集成等挑战。
















 70
70

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











