






 本文解释了内存屏障在多线程编程中的作用,防止指令重排,确保数据同步。介绍了LoadBarrier和StoreBarrier的区别,以及storebuffer如何影响数据一致性,同时讨论了loadmemorybarrier和storememorybarrier在维护程序顺序执行中的关键作用。
本文解释了内存屏障在多线程编程中的作用,防止指令重排,确保数据同步。介绍了LoadBarrier和StoreBarrier的区别,以及storebuffer如何影响数据一致性,同时讨论了loadmemorybarrier和storememorybarrier在维护程序顺序执行中的关键作用。
什么是内存屏障
通过上文介绍,CPU是存在指令重排(乱序执行)的,所以如果要防止CPU的指令重排,提出了内存屏障这个概念,内存屏障(Memory Barrier)是一种硬件或软件机制,用于控制内存操作的顺序和可见性。它们被用于多线程编程和并发控制中,确保对共享数据的操作按照预期顺序执行,并保证线程间的数据同步。内存屏障最主要的作用就是保证了内存操作的顺序性极可见性。
最直观的理解内存屏障就是:在内存屏障之前的指令全部执行完成之后,才允许执行内存屏障之后的指令,从而保证代码的顺序性,一版会针对对内存的读写(load、store)可以组合成四种内存屏障(loadload、loadstore、storeLoad、StoreStore)类型。
硬件层的内存屏障分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。
内存屏障有两个作用:
阻止屏障两侧的指令重排序;
强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
对于Load Barrier来说,在指令前插入Load Barrier,可以让高速缓存中的数据失效,强制从新从主内存加载数据;
对于Store Barrier来说,在指令后插入Store Barrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见。
内存屏障的工作原理
通过刚才简单介绍内存屏障的作用我们知道,内存屏障主要保证内存操作的顺序性,也就是避免了编译器或者CPU的指令重排,在多线程模式下对我们的程序造成不可控结果的一种控制机制,但是内存屏障是怎么工作的呢?他能够控制顺序性的原理是什么呢?
由于这部分涉及到CPU缓存的部分问题,这里首先介绍一下CPU的缓存知识,由于CPU执行速度很快(<1ns),而内存的访问速度大概是(80ns~100ns),两者之间差了两个数量级,为了提升CPU的利用率,所以衍生出CPU缓存的概念
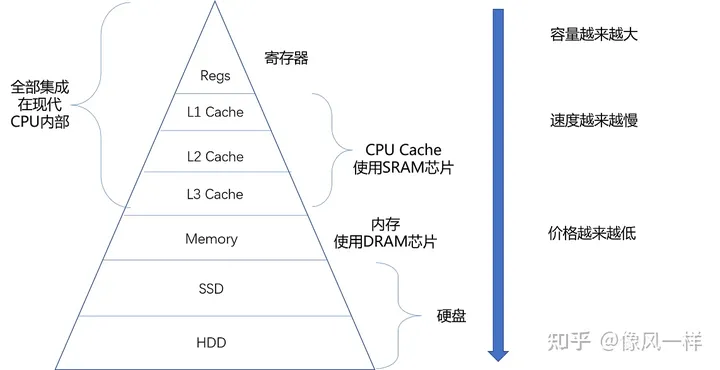
存储器金字塔结构
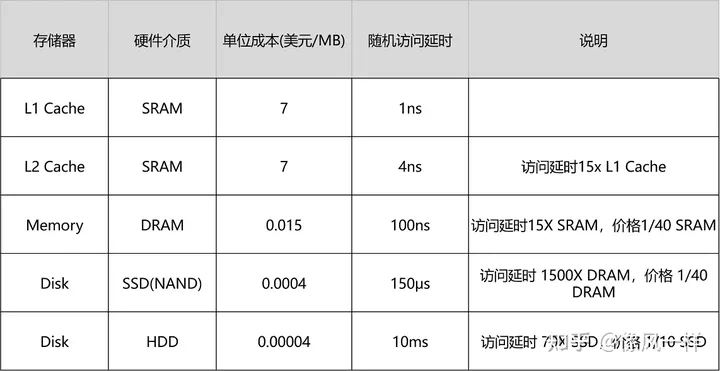
访存速度对比
从以上两幅图中可以看出,距离CPU越近的存储器,速度越快,但是价格也是越高的。
现代CPU一般有三级缓存(L1、L2、L3),本文中所说的local cache主要是只L1缓存,当然有可能有些描述也是不对的
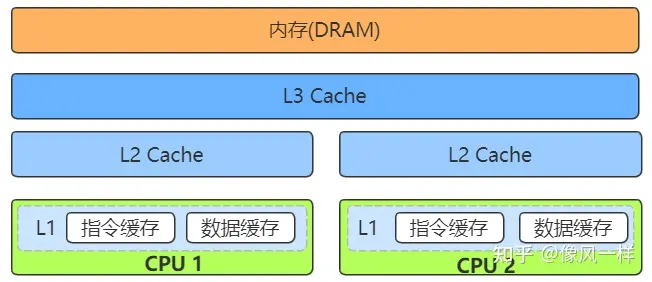
CPU缓存结构
通常来说,一个CPU的物理核心上是独享L1、L2缓存,整个CPU共享L3缓存的。
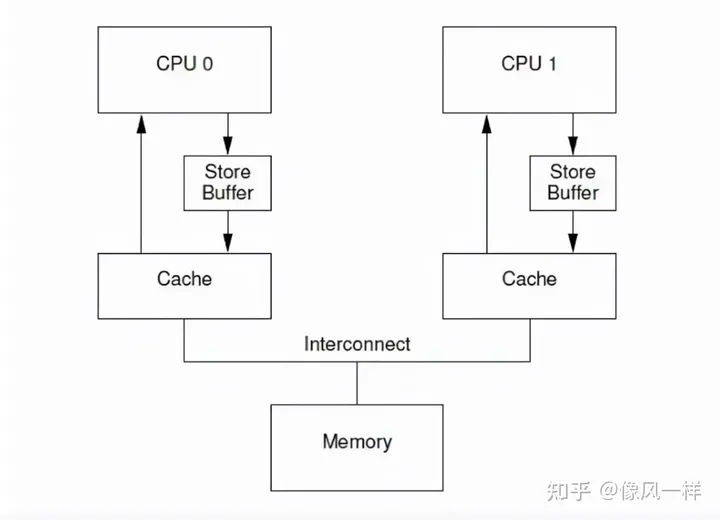
带有store Buffer的CPU结构
Store Buffer
引入的原因,由于CPU缓存一致性的问题,当一个CPU对(cache line)数据进行修改之后,会同步其他CPU该条数据无效,当收到全部CPU的回应之后,才会将数据写入到local cache中,这个等待其他CPU做回应的过程是比较浪费CPU资源的,所以为了提升CPU的利用率,引入了store Buffer的东西,即:当CPU有数据修改,并且要回写到local cache中时,会先将数据写入store Buffer中进行等待,等待其他CPU都做出回应之后,然后在进行写入本地缓存,这样就提升了CPU的利用率(减少了CPU的等待时间),但是这样操作引入了一个新的问题。即:当数据存在于store buffer中,还未收到全部CPU的相应,此时,有其他CPU要读取这部分信息,这时如果读取local cache或者内存中的数据,则数据都是老数据,所以为了保证数据的一致性,给CPU增加了一个限制,当有数据写入的过程中,且有针对这个cache line的读取操作,那么会同时读取store Buffer 跟local cache中的数据,如果store Buffer中有数据,则优先使用store buffer中的数据,这样就解决了写数据过程中,使用该部分数据的数据不一致问题。举个例子来描述一下以上的信息:
int a = 0,b = 0;
a = 1;
b = a + 1;
assert(b == 2);
1、当CPU0 执行到a = 1 这条语句时
2、CPU0 的local cache没有这段数据,发生了cache miss
3、CPU0发送read invalidate请求用于获取a的数据,同时让其他CPU中这部分数据过期
4、CPU0把a=1的信息写入到store Buffer中
5、CPU1收到了read invalidate请求,进行回应read response 和invalidate相应,同时将自己local cache中的a置为无效
6、CPU0收到CPU1回应的read response相应,得到a的值为0
7、CPU0从cache line中读取到a=0的值
8、CPU0执行b = a+1 ,由于此时a = 0,所以得到b =1,假设b的cache line与a不在一起,则b的缓存数据可以直接被写回
9、CPU 0将store buffer中的信息写入到cache line中,此时a = 1
10、CPU0 执行 assert(b == 2) 判断失败
这个问题产生的最主要原因就是因为store Buffer中的值与cache line中的值不一致,造成cache line中的数据是老数据,所以为了避免这种问题的发生,引入了store forwarding机制,即:在读取数据的时候,同时读取store Buffer与cache line的数据,如果store buffer中有数据,则直接使用store buffer中的数据,避免数据的不一致
引入store forwarding机制之后,解决了数据的不一致问题,但是问题并没有完全解决,还有内存顺序(memory order)问题
memory order问题
int a = 0,b = 0;
void func1() {
a = 1;
b = 1;
}
void func2() {
while (b == 0 ) continue;
assert(a == 1);
}
假设CPU0执行func1函数,CPU1执行func2函数,a变量在CPU1的cache中,b变量在CPU0 的cache中,上述代码的执行顺序可以是如下方式:
CPU0 执行a = 1 的赋值操作,由于a变量不在local cache中,所以CPU0将变量的数据放入到store buffer中,并发送read invalidate 请求
CPU1执行 while(b == 0)语句,由于b不在local cache中,所以CPU1 发送了一条read message请求,去其他CPU的本地缓存或者memory中获取b的数据
此时CPU0继续执行,操作b=1的赋值操作,由于b变量在CPU0的local cache中,所以CPU0可以直接操作cache line并将b的修改写回到本地缓存中
CPU0接收到CPU1发送过来的read message的请求,所以就读取本地缓存中的b的数据(此时b已经等于1)并返回给CPU1,同时将自己的cache line设置为S状态
CPU1接收到CPU0传回的b=1的信息,将b=1的数据写入到本地的缓存中,并将本cache line设置为S状态
CPU1执行while循环,由于b已经等于1,则跳出循环,并继续执行
由于CPU1中a的值还是旧值(因为CPU0的修改只是写入到了本地的store buffer中,还没有真正执行),所以这是assert(a==1)失败
接下来,CPU1接收到CPU0发送过来的read invalidate请求,然后CPU1将本地的cache line 置为无效
当CPU0 接收到全部CPU返回的read response 和invalidate ack相应之后,会将a=1的赋值操作,从store buffer中写入到本地cache中
分析一下,之所以能够产生以上的问题,主要原因就是因为存在store buffer,CPU0对store Buffer的操作并没有真正完成之前,就已经有CPU操作这些数据,造成数据的不一致(使用的数据还是旧数据)
如何去避免这种问题的产生呢?
为了避免这种情况的发生,所以产生了内存屏障,针对这种应该写入之后读取的操作,产生了写内存屏障,store memory barrier
避免上述代码出现问题,就可以写成如下方式:
int a = 0,b = 0;
void func1() {
a = 1;
smp_mb();
b = 1;
}
void func2() {
while (b == 0 ) continue;
assert(a == 1);
}
上述代码增加了一个smp_mb函数,这个函数就是写内存屏障函数,smp_mb内存屏障,保证了在这个屏障之前的所有语句都完成store之后,才会执行后续的语句,所以就可以避免上述代码中,由于a变量还在CPU0中的store buffer中,CPU1去读取到旧数据的问题,因为有了这个屏障,肯定是将a=1这个语句执行完成之后,才会去执行b=1这个语句,所以不会发生func2中b=1,但是a=0的情况
那么smp_mb函数是怎么做到程序执行的顺序性的呢?一般这种情况是通过以下两种方式来完成的
方法一:让CPU停滞,等所有的store Buffer被清空之后在继续执行(也就是所有store buffer中的数据都已经写回到cache line中之后才继续执行)
方法二:可以允许CPU继续执行,但是需要再store buffer中做点文章,保证store buffer中的数据是顺序的,并且针对屏障打标记,即便内存屏障标记之后的数据先到达,也不能执行,必须等内存屏障之前的指令全部执行完之后,才可以执行屏障之后的存储操作
store buffer大小的设置
通过上文介绍,我们知道引入store buffer 的原因,那是不是store buffer 设置的越大越好呢?答案是否定的
每个CPU的store buffer不能实现地太大,其存储队列的数目也不会太多。当CPU以中等的频率执行store操作的时候(假设所有的store操作都导致了cache miss),store buffer会很快的被填满。在这种情况下,CPU只能又进入阻塞状态,直到cacheline完成invalidation和ack的交互后,可以将store buffer的entry写入cacheline,从而让新的store让出空间之后,CPU才可以继续被执行。
invalidate Queue
通过上文分析,我们知道为了加速数据的写入,提升CPU的利用率,增加了store buffer的概念,但是数据的每一次修改,都需要其余CPU发送invalidate ACK 来确保local cache的数据已经被置空(无效),这样对其余CPU的性能也是极大的浪费,所以为了提升其余CPU的效率,引入了invalidate queue的概念,invitedate queue主要解决的问题就是,当一个CPU发送read invalidate请求的时候,不需要立即进行相应,而是将这个请求存储在invalidate queue中,只要已经成功存储到queue中,就可以发送invalidate ack响应了,这样极大的提升了CPU的效率,但是引入invalidate queue同样引入了新的问题,稍微完整一点的CPU结构如下:
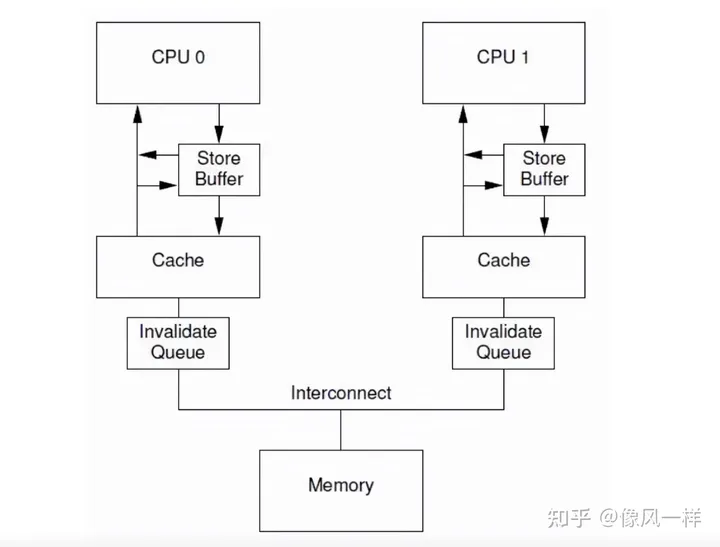
带invalidate Queue的CPU
引入invalidate Queue带来的新问题就是:当做出invalidate ack响应之后,实际还没有将cache line的数据置为无效,又读取了该数据,造成数据的不一致
读内存屏障(load memory barrier)
int a = 0,b = 0;
void func1() {
a = 1;
smp_mb();
b = 1;
}
void func2() {
while (b == 0 ) continue;
assert(a == 1);
}
还是分析这段代码,这段代码保证了b=1的时候,在store的CPU(假设为CPU0)中的local cache中肯定是a=1,但是由于有invalidate Queue的存在(假设为CPU1),这时虽然CPU0已经把数据写入到local cache,但是CPU1由于没有完全执行完invalidate Queue的内容,所以CPU1的本地缓存中,并没有把这个cache line置为无效,所以还是认为这条数据是有效的,最终读出本地缓存的数据a=0,造成assert(a==1)失败。
所以很明显,在上述的执行过程中,由于加速了invalidate ack造成了memory barrier失效了,所以这个时候ack已经没有太大的意义了,因为他造成了执行顺序的错乱
如何解决这种问题呢,这时引入了读内存屏障(load memory barrier)。
他的具体做法就是:当CPU执行memory barrier指令时,把所有invalidate queue中的entry都打上标记,这些打上标记的实体叫做marked entries ,然后在memory barrier之后的所有load操作,都必须保证marked entries都执行完成之后才能执行,这样就保证了数据已经发送invalidate ack的所有指令都执行完成之后,才执行load操作,保证了程序的顺序执行。
改造后的程序如下:
int a = 0,b = 0;
void func1() {
a = 1;
smp_mb();
b = 1;
}
void func2() {
while (b == 0 ) continue;
smp_rmb();
assert(a == 1);
}
smp_rmb()这个函数的作用就是保证执行完这个函数之后,确保在这个函数之前的数据都已经全部执行完成,然后才可以执行load操作,避免了上述过程中出现的有数据还在invalidate queue中,造成local cache中的数据还是陈旧数据的问题。
总结
本文简单介绍了CPU乱序执行的原因,然后使用一个小程序介绍了CPU乱序执行的过程及出现乱序执行的本质原因,接着介绍了内存屏障,包括写内存屏障(store memory barrier)和读内存屏障(load memory barrier),及如果要保证程序的顺序,如何添加响应的内存屏障。
接下来的文章,我们会介绍一下CPU的缓存一致性问题(本文中也涉及到了一部分一致性的问题,但是未做深入探讨)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









