







一、概念
ApacheCassandra是一个开源、分布式分散性(没有单点故障)、弹性可伸缩(动态增加减少节点)、高可用性高容错(多数据中心)、可协调一致性(复制因子成功数量由用户决定)、面向行的数据库。分布式设计基于Amazon’s Dynamo ,它的数据模型基于谷歌的Bigtable,使用了一种类似于SQL的查询语言。它由Facebook创建,现在为许多行业的云规模应用程序提供动力。
ApacheCassandra是用Java编写的,但是cassandra驱动程序有多种语言版本,包括Java、Node.js、Python、c#、PHP、Ruby和Go。
二、安装
1、官网下载最新tar包
https://dlcdn.apache.org/cassandra/4.0.5/apache-cassandra-4.0.5-bin.tar.gz
2、上传指定文件目录,tar解压
3、配置文件cassandra.yaml修改参数:数据目录、日志目录、副本数、密码、集群ip等等
4、进入bin目录启停cassandra
#启动
./bin/cassandra
#停止
ps -ef|grep cassandra kill 进程号
#官方推荐:
pgrep -uroot -f cassandra | xargs kill -9
#查看节点状态
./bin/nodetool status

5、连接客户端 CQL SHELL
#连接本机客户端
./bin/cqlsh -ucassandra -pcassandra
#连接其他节点
./cqlsh 192.168.0.178 9042 -ucassandra -pcassandra

6、Cassandra基本cql命令:
#帮助,查看所有命令
help
#查看集群
DESCRIBE CLUSTER;
#查看所有键空间
DESCRIBE KEYSPACES;
#查看版本
SHOW VERSION;
#查看键空间详情
DESCRIBE KEYSPACE my_keyspace;
#创建键空间
CREATE KEYSPACE swcs_data WITH replication = {'class':
'SimpleStrategy', 'replication_factor': 1};
#使用键空间
USE my_keyspace;
#列出所有表
desc tables;
#查看表结构
desc swcs_axis_original
#删除表
drop table swcs_axis_original;
TRUNCATE user;
#创建表
create table swcs_axis_original
(
device_code text,
date_point int,
time_point int,
user_id bigint,
route_id bigint,
acc_x text,
acc_y text,
acc_z text,
ang_x text,
ang_y text,
ang_z text,
create_time timestamp,
create_user bigint,
deleted int,
device_type int,
id bigint,
update_time timestamp,
update_user bigint,
primary key ((device_code, date_point), time_point, user_id, route_id)
) with clustering order by (time_point desc, user_id asc, route_id asc) and comment = '6轴源数据' and default_time_to_live =43200;
#修改表定义
alter table swcs_axis_original with default_time_to_live =86400;
#修改表添加列
ALTER TABLE swcs_axis_original ADD name text;
#插入数据并设置TTL
INSERT INTO swcs_axis_original (device_code, date_point, time_point, user_id, route_id, acc_x, acc_y, acc_z, ang_x, ang_y, ang_z, create_time, create_user,deleted,device_type,id,update_time)
VALUES
('MY112013233',20220520,'2022-06-20 19:00:00', 22222, 111111, '11.0,2.0', '1.0,2.0', '1.0,2.0', '1.0,2.0', '1.1,2.0', '1.0,2.0','2022-07-20 18:00:00',11111,1,1,11111,'2022-07-20 18:00:00') USING TTL 600;
#删除列数据---必须按顺序指定所有主键
DELETE deleted from swcs_axis_original where device_code ='MY11400' and date_point = 20220723 and time_point ='2022-07-23 11:00:00' and user_id =54 and route_id =11200;
#删除行数据
DELETE from swcs_axis_original where device_code ='MY11400' and date_point = 20220723 and user_id =54;
三、Cassandra查询语言
1、数据模型
Cassandra使用一种称为复合键的特殊类型的主键,来表示相关的行的组,也称为分区。复合键由一个分区键和一组可选的集群列组成。分区键用于确定存储行的节点,并且它本身可以由多重列组成,集群列用于控制分区中的存储排序,Cassandra还支持一个称为静态列的附加构造,它用于存储不是主键的一部分,而是由分区中的每一行共享的数据。

2、Insert/Update/Upsert
如果插入一个与现有行具有相同主键的行,则将替换该行。如果您更新了一个行,而主键不存在,Cassandra将创建它。
3、TTL生存时间
查看数据过期时间:
select ttl(acc_x) from swcs_axis_original ;
修改数据过期时间:
UPDATE swcs_axis_original USING TTL 1536043 set acc_x='2222' where device_code = 'MY11400' and date_point = 20220723 and time_point = '2022-07-23 11:00:00' and user_id= 54 and route_id = 11200;
插入数据设置过期时间:
INSERT INTO swcs_axis_original (device_code, date_point, time_point, user_id, route_id, acc_x, acc_y, acc_z, ang_x, ang_y, ang_z, create_time, create_user,deleted,device_type,id,update_time)
VALUES
('MY112013233',20220520,'2022-06-20 19:00:00', 22222, 111111, '11.0,2.0', '1.0,2.0', '1.0,2.0', '1.0,2.0', '1.1,2.0', '1.0,2.0','2022-07-20 18:00:00',11111,1,1,11111,'2022-07-20 18:00:00') USING TTL 600;
4、数据类型
数字类型:int ,bigint,smallint,tinyint,varint,float,double,decimal
字符类型:text,varchar,ascii
时间类型:timestamp,date,time,uuid,timeuuid
其他类型:boolean,blob,inet,counter
集合:set,list,map,tuples
自定义类型:create type
四、数据模型
1、概念数据模型
与关系型数据库的差异:没有关联join,没有外键,基于查询的数据模型设计,基于存储的数据模型设计(分区键),基于排序的数据模型设计(聚类键)
小结:通过业务流的方式,层层设计主键的因果查询,最终完成一个业务功能
2、计算分区大小
Cassandra限制每个分区最大单元格20亿,否则会影响性能,建议不超过10万,
分区单元格数计算方式:
3、计算磁盘空间
五、Cassandra架构
1、数据中心和机架:查询中尽量路由到本地数据,最大限度提高性能
2、Gossip故障检测:通过Gossip协议,维护live 和dead 节点列表,进而实现故障检测
3、Snitches:有效的路由请求,确定那些节点进行读写
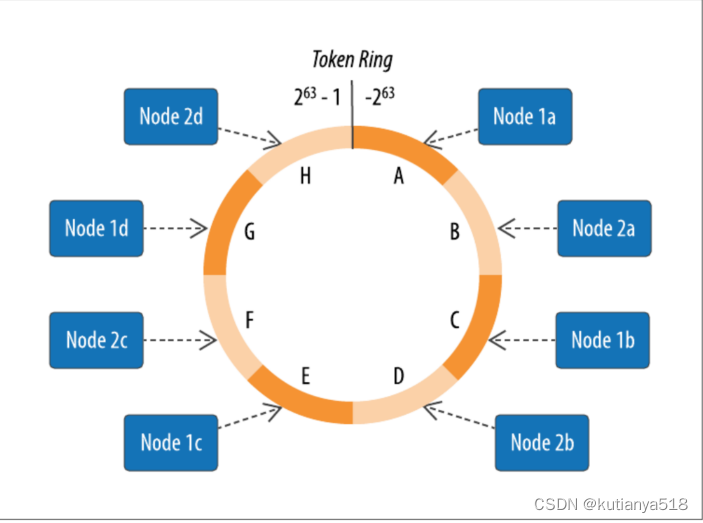
4、Rings and Tokens: cassandra将由一个集群管理的数据表示为一个环。环中的每个节点都被分配了一个或多个由token标记描述的数据范围,这决定了数据在环中的位置。
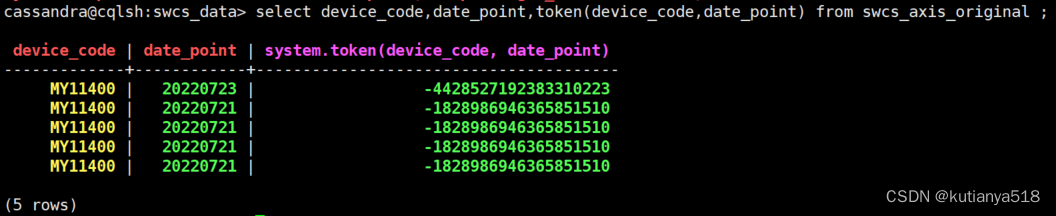
token()函数可查看分区键的hash值:
5、Virtual Nodes虚拟节点
虚拟节点就是一个由token标识的更小的数据范围,每个机器根据num_tokens的配置,决定在整个集群中所把持的比例
num_tokens:每个节点通过该值的比例,分配存储数据,对于性能配置好的机器,调大该值,性能配置欠佳的机器,调小该值。
6、Partitioners分区器
决定数据落在集群中的那个数据节点上,Murmur3Partitioner从1.2开始,作为默认的分区器,生成的hash值是64为的
7、Replication Strategies复制策略
节点作为不同数据范围的副本。如果一个节点关闭,其他副本可以响应对该数据范围的查询。Cassandra以一种对用户透明的方式跨节点复制数据,复制因子是集群中将接收相同数据的副本的节点数量。如果你的复制因子是3,那么环中的三个节点将有每一行的副本。
实现类:SimpleStrategy(副本存放在环周围的连续节点) and NetworkTopologyStrategy(副本存放在数据中心和机架上--生产使用),创建keyspace时需要指定
8、 Consistency Levels一致性级别
Cassandra提供了可调和的一致性级别,允许您在一个细粒度的级别上进行这些权衡。您在每个读或写查询上指定一致性级别,指示需要多少一致性。更高的一致性级别意味着需要更多的节点响应读或写查询,这使您更加保证每个副本上出现的值是相同的。
复制因子与一致性的区别:每个keyspace设置复制因子。一致性级别由客户端为每个查询指定。复制因子表示在每次写操作期间要使用的存储值的节点数。一致性级别指定客户端决定必须响应多少节点,以便确信成功的读写操作。
9、Memtables, SSTables, and Commit Logs
Commit Logs:当节点收到操作请求时,会先记录到commit log中,是Cassandra故障恢复的机制
Memtables:当操作请求写入到commit log后,会立马把值写入到被称为memtables的数据结构中
SSTables:当存储在memtables表中的对象的数量达到一个阈值时,memtables内存表中的内容将被刷新到一个称为SSTable的文件中的磁盘上。
10、Bloom filters
Cassandra为每个SSTable,维护一个布隆过滤器,提高Read的性能
11、Caching---默认启用了key cache 和counter cache
- key cache 分区键到行索引的map
- row cache
- chunk cache
- counter cache
12、 Compaction
在Compaction期间,对合并的数据进行排序,在已排序的数据上创建一个新的索引,并将新合并、排序和索引的数据写入一个新的SSTable(每个SSTable由多个文件组成,包括数据、索引和过滤器),压缩包括sstable、data、keys、columns的合并,删除废弃的值(标记为墓碑)等。
13、Deletion and Tombstones
墓碑是一个标记,用来指示已被删除的数据。在执行删除操作时,不会立即删除该数据。相反,它被视为一个更新操作,在值上放置一个墓碑,在执行compaction过程中,被彻底删除,释放空间,每个表gc_grace_seconds默认保存的时间是10天
六、Cassandra的应用设计
1、 Secondary Indexes
#创建索引CREATE INDEX ON hotels ( address );默认索引名称--<table name>_<column name>_idxCREATE INDEX hotels_address_idx ON hotels ( address );#删除索引DROP INDEX hotels_address_idx;
一般情况下,在进行数据模型设计的时候是根据查询进行设计的,二级索引一般用在,在初始数据模型设计中没有考虑到的查询的一种有用方法
2、Materialized Views 视图
#创建实体化视图样例CREATE MATERIALIZED VIEW reservation.reservations_by_confirmationAS SELECT * FROM reservation.reservations_by_hotel_dateWHERE confirm_number IS NOT NULL and hotel_id IS NOT NULL andstart_date IS NOT NULL and room_number IS NOT NULLPRIMARY KEY (confirm_number, hotel_id, start_date, room_number);
七、Cassandra应用开发驱动
1、 DataStax Java Driver
引入依赖:
<dependency>
<groupId>com.datastax.oss</groupId>
<artifactId>java-driver-core</artifactId>
</dependency>
1、 Connecting to a Cluster
CqlSession cqlSession = CqlSession.builder()
.addContactPoint(new InetSocketAddress("<some IP address>", 9042)) .addContactPoint(new InetSocketAddress("<another IP address>", 9042)) .withLocalDatacenter("<data center name>")
.withKeyspace("reservation") .build()
CqlSession自带连接池

2、 Statements
2.1 Simple Statements
#入库操作
SimpleStatement reservationInsert = SimpleStatement.builder("INSERT INTO reservations_by_confirmation (confirm_number, hotel_id,start_date, end_date, room_number, guest_id) VALUES (?, ?, ?, ?, ?, ?)").addPositionalValue("RS2G0Z").addPositionalValue("NY456").addPositionalValue("2020-06-08").addPositionalValue("2020-06-10").addPositionalValue(111).addPositionalValue("1b4d86f4-ccff-4256-a63d-45c905df2677").build();cqlSession.execute(reservationInsert);#查询操作SimpleStatement reservationSelect = SimpleStatement.builder("SELECT * FROM reservations_by_confirmation WHERE confirm_number=?").addPositionalValue("RS2G0Z").build();ResultSet reservationSelectResult = cqlSession.execute(reservationSelect);
2.2 Prepared Statements
一次提交,多次使用,每次只发送参数,提高执行效率
PreparedStatement reservationInsertPrepared = cqlSession.prepare("INSERT INTO reservations_by_confirmation (confirm_number, hotel_id,start_date, end_date, room_number, guest_id) VALUES (?, ?, ?, ?, ?, ?)");BoundStatement reservationInsertBound = reservationInsertPrepared.bind().setString("confirm_number", "RS2G0Z").setString("hotel_id", "NY456").setLocalDate("start_date", "2020-06-08").setLocalDate("end_date", "2020-06-10").setShort(111).setUuid("1b4d86f4-ccff-4256-a63d-45c905df2677")
2.3 QueryBuilder
DataStaxJava驱动程序提供了一个独特的特性,其他驱动程序不支持它,它使用一个流畅风格的API以按程序创建查询
#入库操作
Insert reservationInsert =insertInto("reservation", "reservations_by_confirmation").value("confirm_number", "RS2G0Z").value("hotel_id", "NY456").value("start_date", "2020-06-08").value("end_date", "2020-06-10").value("room_number", 111).value("guest_id", "1b4d86f4-ccff-4256-a63d-45c905df2677");SimpleStatement reservationInsertStatement = reservationInsert.build();#查询操作selectFrom("reservation", "reservations_by_confirmation").all().whereColumn("confirm_number").isEqualTo("RS2G0Z");SimpleStatement reseravationSelectStatement = reservationSelect.build();
2.4 Object Mapper
一种对象映射的方式,通过注解、实体类、mapper的类似mybatis的开发方式
2.5 Driver logging
#logback中配置驱动日志----在springboot中未起效果
<configuration><logger name="com.datastax.oss.driver" level="INFO"/></configuration>
八、Cassandra读写数据
1、Writing
1.1Write Consistency Levels 写一致性

如下所示,在CQL中可设置会话级别的一致性
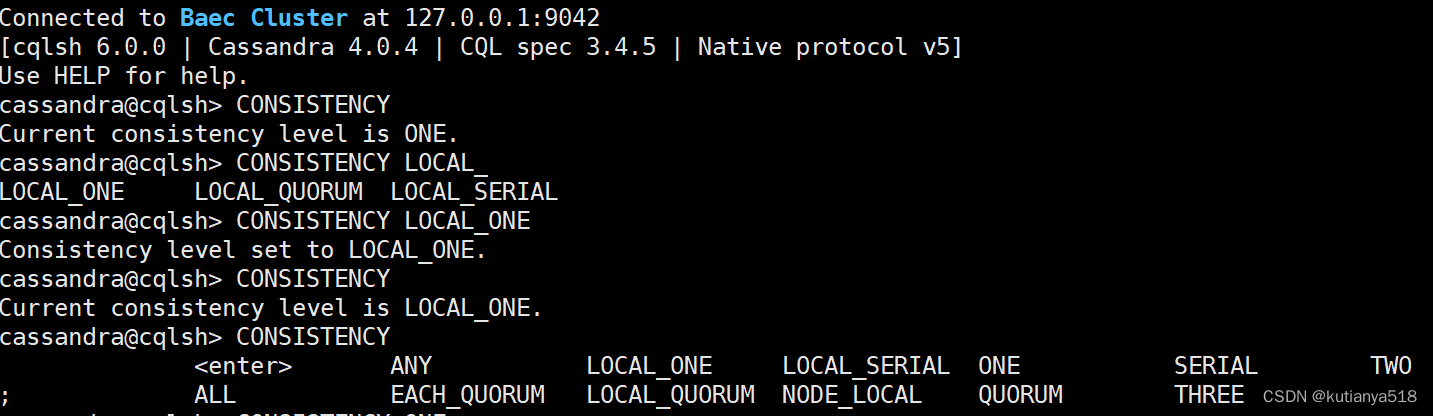
小结:根据需要可配置一致性级别,Cassandra默认的一致性是ONE,也可以通过驱动配置或者通过在执行statement时设置一致性
如下官网所述:

1.2 Lightweight Transactions 轻量级事务
对于Insert操作:通过添加if not exist 语句,判断是否入库,不存在则入库,否则不入库

对于update操作:通过添加if 条件 语句,判断是否更新,满足则更新,否则不更新

2、Reading
2.1 Read consistency levels

小结:根据配置的读一致性策略,会在数据返回前或返回后修复不一致的数据
2.2 Range Queries, Ordering and Filtering
where查询包含两个规则:
- 必须指定分区键
- 聚集键必须顺序指定,不可跳跃
ALLOW FILTERING:
一个全表扫描的附加语句,官方不建议附加ALLOW FILTERING去满足查询,否则就要重新审视一下表设计了。
更多样化的查询样例请参考:
CQL WHERE Clause: A Deep Look | Datastax
2.3Deleting
Cassandra的删除不是立即删除,对于删除的数据通过tombstone标记,当达到gc_grace_seconds的配置时间,就会立即进行compaction,进行垃圾回收,并释放磁盘空间。
避免产生大量tombstone的方式:
- 避免将null值写入表,因为这些值被解释为删除
- 以整个分区的方式删除数据
- 更新集合数据时,避免使用替换而是更改其中的某个元素
- 对于时间序列的表,采用 TimeWindow CompactionStrategy,便于一次性删除SSTable
九 Configuring and Deploying Cassandra
1、集群管理
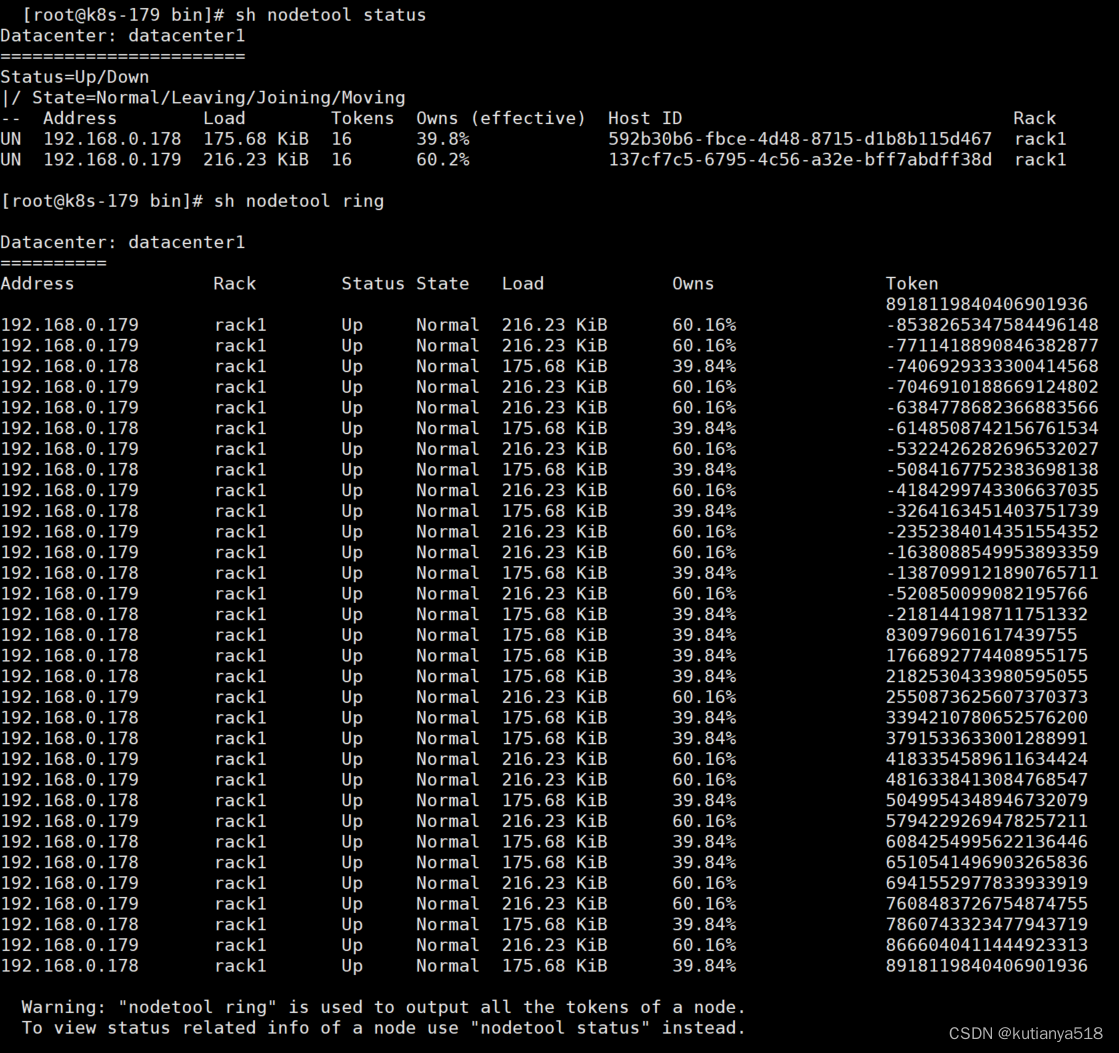
查看节点状态:nodetool status ,nodetool ring
2、节点配置
2.1集群名称

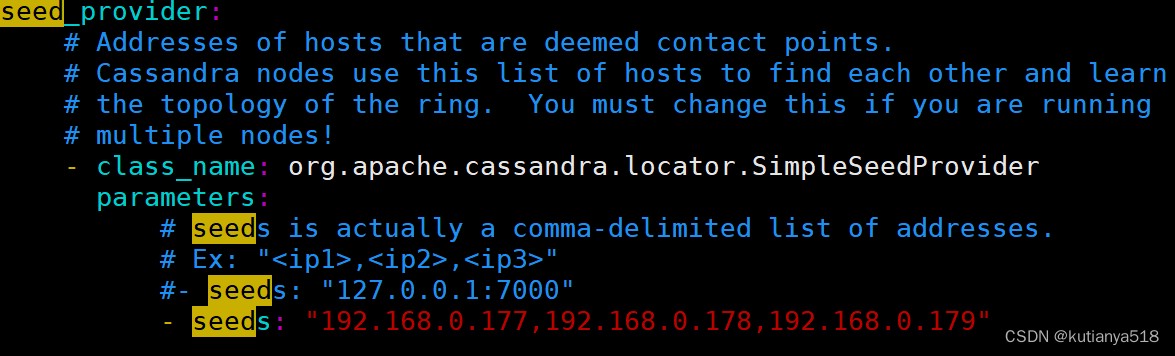
2.2配置集群的种子节点
2.3Snitches配置:snitches通过获取其他节点得拓扑信息,从而高效路由请求,
默认是SimpleSnitch,官方要求创建keyspace时

2.4分区器:默认使用Murmur3Partitioner,通过分区器把分区键映射成token值

2.5Tokens and Virtual Nodes
对于机器配置好的节点调大num_tokens,否则调小
官方文档说明:每个节点拥有更少的令牌可以在令牌范围之间提供足够的平衡,最初每个节点256个token,目前默认16个

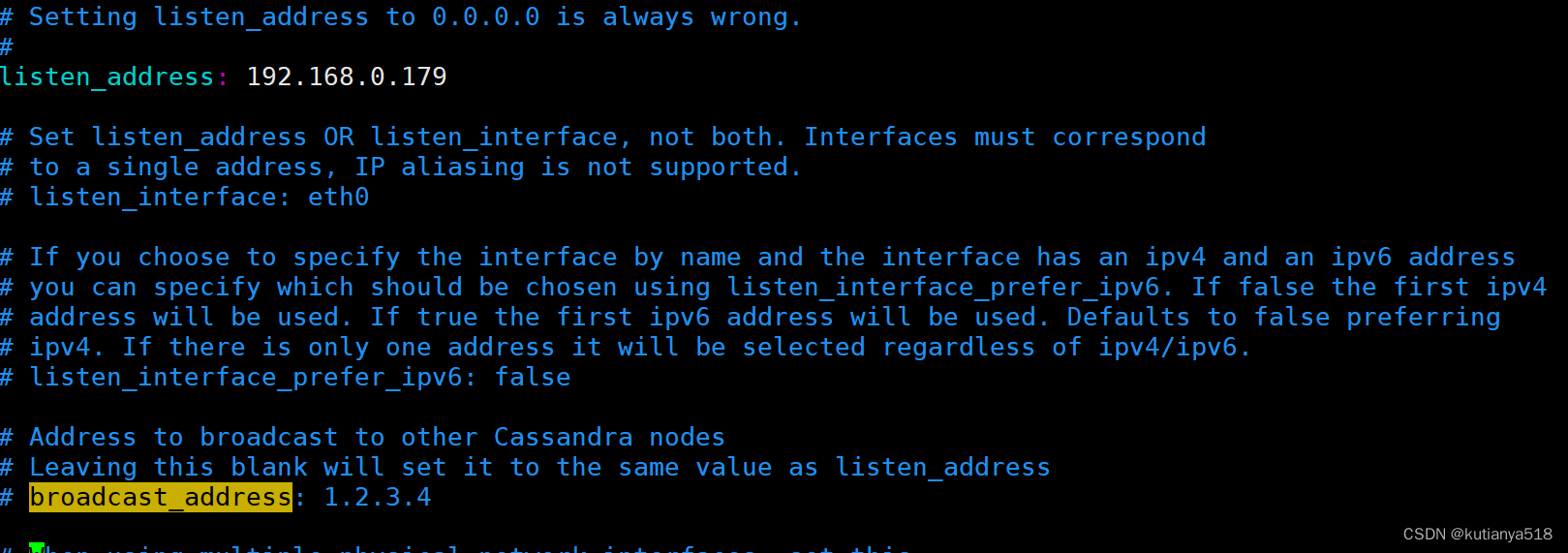
2.6监听地址:每个节点配置本机ip,用于与其他节点通信连接
listen_address

broadcast_address:默认同listen_address
十 Monitoring
1、nodetool的使用
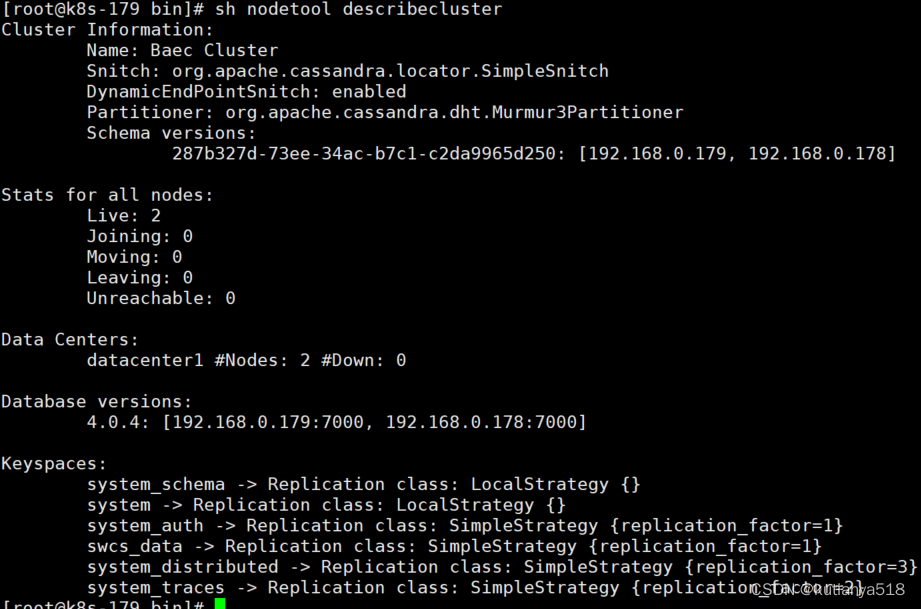

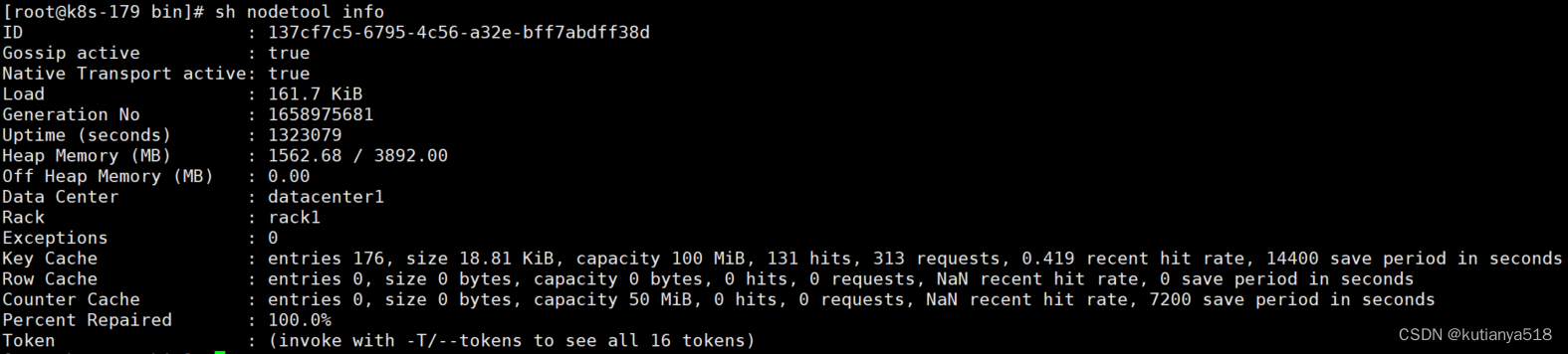
查看节点状态:nodetool status ,nodetool ring
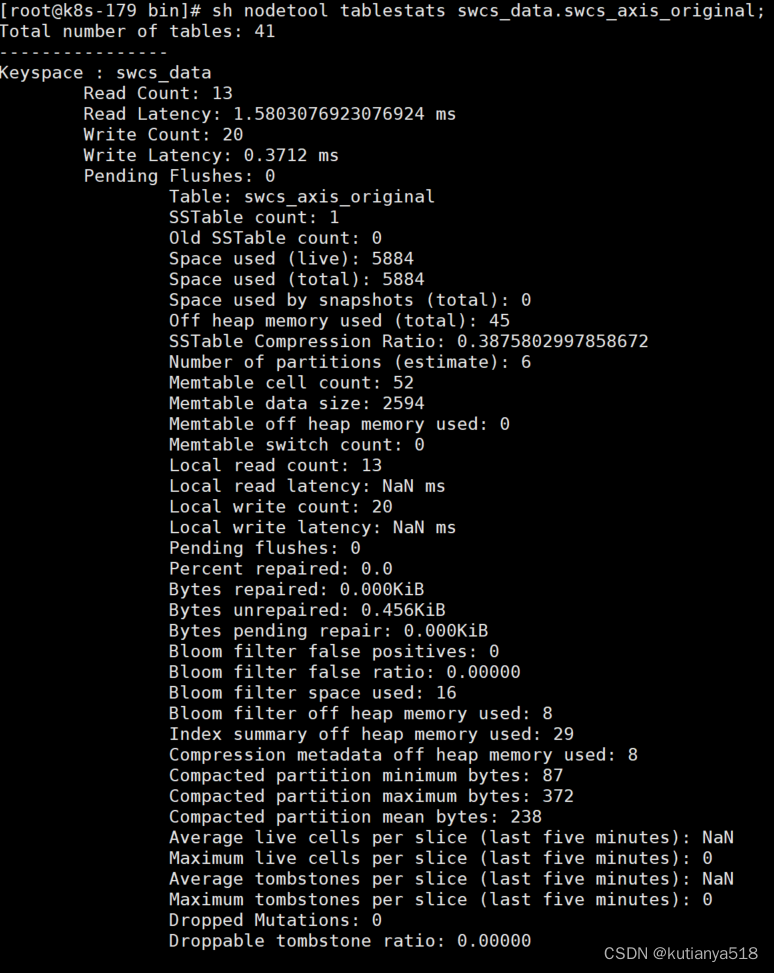
查看表空间:nodetool tablestats keyspace.tablename
十一 Maintenance
1、常见维护任务
1.1 Flush
#刷新键空间或键空间下的某个表
nodetool flush keyspace/keyspace.table
强制把数据从memtable,刷新到磁盘SSTable,同时清除commitlog
1.2 Cleanup
#compaction节点的数据
nodetool cleanup keyspace/keyspace.table
快速释放磁盘空间,清除旧的数据,使用场景是,添加节点,或更改复制因子或者复制策略
1.3 Repair
#修复键空间或表
nodetool repair keyspace/keyspace.table
根据复制因子,修复节点的上数据不一致情况,达到所有节点副本都是最新数据
2、处理节点故障 Handling Node Failure
2.1 Repairing Failed Nodes
如果发现节点宕机了,首先查看节点挂了多久,然后做如下判断操作:
- 如果节点宕机低于 max_hint_window_in_ms(3小时),重启节点,然后观察日志,通过nodetool status 查看是否启动成功。此种场景是对于死亡不久的节点通过Hinted Handoff mechanism进行恢复的。
- 如果节点宕机时间大于max_hint_window_in_ms(3小时),而小于gc_grace_seconds ( 864000即10天),假设重启成功,则运行修复指令 nodetool repair。
- 如果几点宕机超过gc_grace_seconds ( 864000即10天),则需要考虑重建或替换该节点,避免 tombstone复活。
2.2 Replacing Nodes
如果需要替换现有的节点:
- 参考官方在现有数据中心添加节点的方式,进行添加
- 在新节点上找到jvm.options文件,
- 并编辑输入 JVM_OPTS="$JVM_OPTS -Dcassandra.replace_address_first_boot=ip(被替换节点的地址)"
- 通过在该节点上执行命令 nodetool netstats,可监控到信息
2.3 Removing Nodes
- Decommissioning a node 停用一个现有节点,命令是: nodetool decommission
- Removing a node 删除一个现有节点,nodetool removenode host ID
- Assassinating a node 强制删除一个现有节点,如果removenode删除失败,可通过 nodetool assassinate IP 进行删除
十二 Performance Tuning
1、压力测试工具
#cassandra的tools/bin目录下的一个压力测试工具,会自动创建keyspacecassandra-stress write n=1000000#读测试cassandra-stress read n=200000
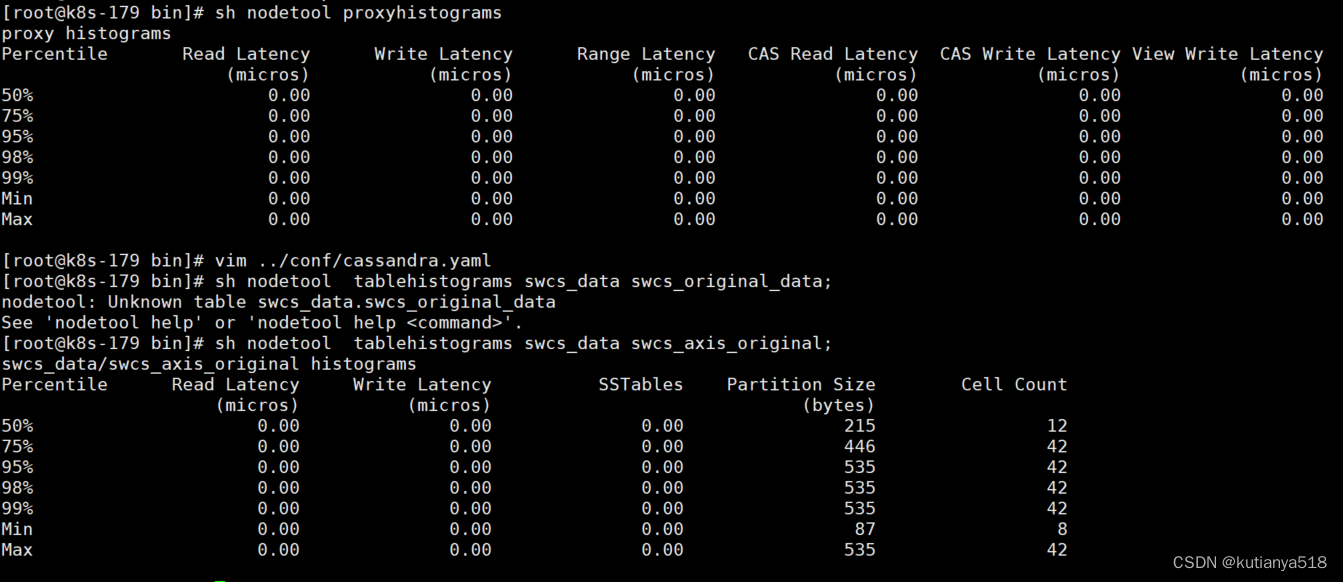
#展示出节点作为协调器的读、写、范围读的延迟nodetool proxyhistograms#对于表的延迟情况nodetool tablehistograms kespace tablename
3、追踪
#开启追踪
Trancing on;
#执行cql,即可看到执行计划,以及数据的节点分布等信息
#关闭追踪
Trancing off;
十三、 Security
1、默认账号
#cassandra默认的账号密码是cassandra
sh cqlsh -ucassandra -pcassandra
2、添加账号
#创建账号
create user swcs with password 'swcs';
#修改密码
alter user username with password 'new password';
#查看用户
list users;
3、切换用户
#在一个cql会话期间切换其他用户
login cassandra 'cassandra';
由swcs用户切换到cassandra,在切换回swcs;

Spring Data Cassandra批量写数据记录 - 简书
Cassandra主键查询的一些限制_duqk1982的博客-CSDN博客

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









