







程序跑完之后,往往需要将结果保存为txt格式,有的时候保存完成后,会出现乱码问题。一般能想到的原因就是txt编辑器编码不合适的问题,除此之外还有一种常常被忽略的原因是我们保存时数据处理不正确。字符型数据按照但字节数据进行保存时,如果字符型数据保存的是不能被正常显示的ASCII值,读该文件时便会出现乱码现象。下面是数据处理不正确导致乱码的例子。要解决这个问题,只要将字符型数据强制转换为整型数据即可。
例子代码如下:
#include <fstream>
using namespace std;
int main(int argc, char** argv)
{
uchar ch=1,ch0=48;
ofstream files("files.txt");
files<<"char is"<<" "<<ch0<<endl;
files<<"ASCII is"<<" "<<(int)ch0<<endl;
files<<"used as number"<<" "<<(int)ch<<endl;
files<<"encode problem"<<" "<<ch<<endl;
return 1;
}运行完成后,得到的txt文件内容如下, 可以看到最后一行最后一个字符ASCII码为1,不能正常显示,所以出现乱码现象。
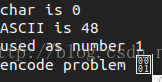
下面实在vim中显示的情况。
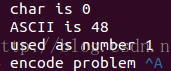
上面的代码中,有两个ASCII码值:1和48;
在代码的第8行由于ch0是字符类型的数据,所以保存到文本文件时直接保存其ASCII值48,显示的时候为0。
在第9行ch0被强制转换为整型,保存时会按照十进制数48进行进行保存,所以下次读出是会显示48,这个与原数据相同。
在第10行ch被转换为整型进行保存,编码时会按照转换后的数字49进行保存,所以读出时数值显示仍为1。
在第11行中ch按照uchar类型保存,保存的便是其ASCII码值1,在读的时候仍得到ASCII 1,此时会出现乱码现象,因为ASCII 1是不能显示的。















 9635
9635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









