






20220315

starrocks连接hadoop源数据位置
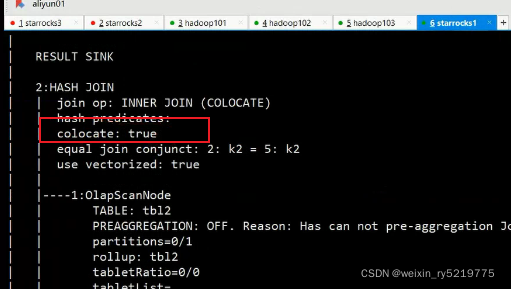
colocate join 执行成功
20220314

集群是HA的情况下需要填
ui监控:域名:8030

 聚合模型
聚合模型
rollup表索引,稀疏索引
 数据模型
数据模型
明细模型相当于数据的ods,dwd

冷热数据
冷数据不会再被更改,不会被加载进内存
宽表都是些聚合指标不是明细数据,列可能很多,但是行很少
主键模型费内存,全部加载到内存
CREATE TABLE `tb_onekey_goods_info_manual_match_test` (
`id` bigint(20) NOT NULL COMMENT "业务主键 自增id",
`goods_id` varchar(200) NULL COMMENT "商品id",
`hz_goods_id` varchar(200) NULL COMMENT "合纵商品id",
`remarks_status` int(11) NULL COMMENT "对码方法,0:算法规则"
) ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "手动对码结果-商品信息表(商品粒度)"
DISTRIBUTED BY HASH(`id`) BUCKETS 4
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
创建非外部表
import pymysql
self.config_starrocks_onekey = {
"host": "192.168.1.112",
"port": 9030,
"user": "doris",
"password": "hezong2022",
"database": "onekey_bi",
"charset": "utf8",
}
self.conn = pymysql.connect(**self.config_starrocks_onekey)
starrock如果是建立在mysql的基础之上的话,大部分关于mysql的操作都可以直接使用
可以直接使用pymysql,好像没有自增功能?没有replace into?
starrocks有按主键模型的(id进行更新,覆盖)
https://mp.weixin.qq.com/s/C7UzjdAQL9PTNXeSsVRjQA
基于StarRocks的极速实时数据分析实践















 3335
3335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









