










经过一番艰辛的过程,搭建好hadoop2.5.2的完全分布式集群环境,本文描述环境的搭建,后续文章将描述开发环境及HDFS API 及MapReduce例程编写及运行过程,转载请注明出处(http://blog.csdn.net/kylindai/article/details/46584637)
上一篇文章描述了 zookeeper 集群的安装,本文描述 hadoop 服务器的安装过程
1. 安装 hadoop
回顾集群规划
hadoop01: NameNode
hadoop02: NameNode
hadoop03: ResourceManager
hadoop04: DataNode, JournalNode, NodeManager
hadoop05: DataNode, JournalNode, NodeManager
hadoop06: DataNode, JournalNode, NodeManager
1.1 安装软件
在hadoop01上解压hadoop,并做 /usr/local/hadoop 链接
# tar xvfz hadoop-2.5.2.tar.gz -C /opt
# ln -s /opt/hadoop-2.5.2 /usr/local/hadoop1.2 修改配置文件
修改hadoop配置文件,配置文件都位于 /usr/local/hadoop/etc/hadoop 目录下,一共要修改6个配置文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slave
(1) hadoop-env.sh
这是 hadoop 命令脚本需要用到的环境变量脚本
需要修改里面的 JAVA_HOME 环境变量(奇怪的是为啥不直接取已经设置好的环境变量)
用 vi 打开 hadoop-env.sh 文件,在第25行,将 JAVA_HOME 设置为正的值:
export JAVA_HOME = /usr/local/java如下图:
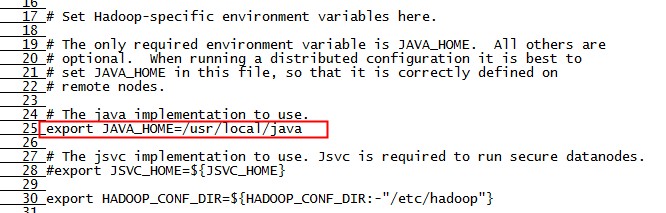
(2) core-site.xml
说明:
a. 指定 hdfs 默认的 url,其中 nameservice id 在 hdfs-site.xml 中定义
b. 指定 hdfs 元数据及edits文件的目录,这个目录需要在 namenode 上创建,也就是在 hadoop01 和 hadoop02 上都要创建,这里创建的目录为: /data/hadoop.data
c. 指定 zookeeper 服务器地址及端口,namenode ha 需要使用
最终内容如下:
<configuration>
<!-- 指定hdfs的默认url, cluster1 为集群的 nameservice id -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<!-- 指定hadoop临时目录,存放hdfs元数据及edits文件的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop.data</value>
</property>
<!-- 指定zookeeper地址,NameNode HA 需要用到 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop03:2181,hadoop04:2181,hadoop05:2181</value>
</property>
</configuration>(3) hdfs-site.xml
说明:
a. 指定 nameservices,一个集群有一个id,这里定义为 cluster1
b. 指定 cluster1 的 namenode 节点,namenode1, namenode2
c. 两个 namenode 的 rpc 及 http 访问地址及端口
d. 指定 cluster1 的 journalnode 的地址和端口
e. 指定 journalnode 本地同步文件路径
f. 设置 namenode failover 自动切换
g. 设置 namenode failover 自动切换的 provider 程序
h. 设置 namenode failover 自动切换时需要用到的 ssh key 的目录位置
最终内容如下:
<configuration>
<!-- nameservices id -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<!-- cluster1 namenod: namenode1, namenode2 -->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>namenode1,namenode2</value>
</property>
<!-- cluster1 namenode1 rpc-address -->
<property>
<name>dfs.namenode.rpc-address.cluster1.namenode1</name>
<value>hadoop01:9000</value>
</property>
<!-- cluster1 namenode1 http-address -->
<property>
<name>dfs.namenode.http-address.cluster1.namenode1</name>
<value>hadoop01:50070</value>
</property>
<!-- cluster1 namenode2 rpc-address -->
<property>
<name>dfs.namenode.rpc-address.cluster1.namenode2</name>
<value>hadoop02:9000</value>
</property>
<!-- cluster1 namenode2 http-address -->
<property>
<name>dfs.namenode.http-address.cluster1.namenode2</name>
<value>hadoop02:50070</value>
</property>
<!-- cluster1 journalnode 的地址和端口 - namenode1 & namenode2 元数据实时同步 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop04:8485;hadoop05:8485;hadoop06:8485/cluster1</value>
</property>
<!-- cluster1 journalnode log 文件存放目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop.journal</value>
</property>
<!-- namenode ha -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- failover proxy -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>(4) mapred-site.xml
说明:
a. 指定 mapreduce 的运行框架为 yarn
最终内容如下:
<configuration>
<!-- 指定 mapreduce 的运行框架为 yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(5) yarn-site.xml
说明:
a. 指定 resourcemanager 的地址(还是有单点隐患)
最终内容如下:
<configuration>
<!-- 指定 resourcemanager 地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
<!-- nodemanager 启动时加载 services 的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>(6) slaves
说明:
a. 指定 cluster1 的 datanode 的机器名,我们规划在 hadoop04, hadoop05, hadoop06 上
最终内容如下:
hadoop04
hadoop05
hadoop061.3 复制hadoop到其他节点
# scp -r /opt/hadoop-2.5.2 hadoop02:/opt
# scp -r /opt/hadoop-2.5.2 hadoop03:/opt
# scp -r /opt/hadoop-2.5.2 hadoop04:/opt
# scp -r /opt/hadoop-2.5.2 hadoop05:/opt
# scp -r /opt/hadoop-2.5.2 hadoop06:/opt复制好后,在 namenode (hadoop01, hadoop02) 和 datanode (hadoop04, hadoop05, hadoop06) 上创建目录
# mkdir /data
# mkdir /data/hadoop.data接下来,在 journode (hadoop04, hadoop05, hadoop06) 上创建目录
# mkdir /data
# mkdir /data/hadoop.journal2. 启动 hadoop
hadoop安装配置完毕后,接下来就可以准备启动了
2.1 启动 zookeeper
上一篇文章中我们已经安装并启动了 zookeeper,这里就略过。
2.2 在 zookeeper 中创建 hadoop_ha 节点
严格按下述步骤:
在 hadoop01 上执行下面的命令:
# hdfs zkfc –formatZK执行结果如下:

可以看到 Successfully created /hadoop-ha/cluster1,创建成功。
到 hadoop03 上看一下 zookeeper znode 的情况:
# zkCli.sh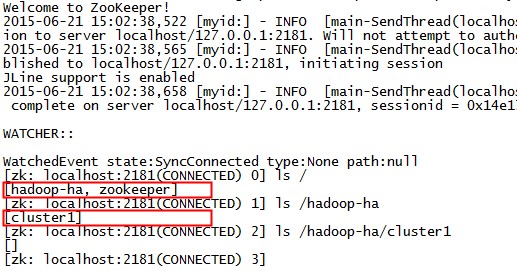
看到 /hadoop-ha/cluster1 节点创建成功
2.3 启动 journalnode
在 hadoop01 上,执行下述命令:
# hadoop-daemons.sh start journalnode看到输出:

journalnode 分别在 hadoop04, hadoop05, hadoop06 上启动了。
到 hadoop04 上看一下进程:
# jps 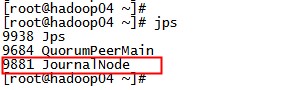
可以看到 JournalNode 进程如期启动。
2.4 格式化 namenode
在 hadoop01 上执行:
# hdfs namenode -format -clusterid cluster1看到输出:
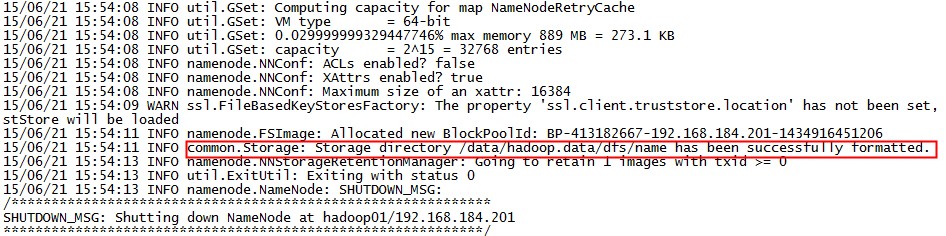
说明格式化成功,接下来将 /data/hadoop.data 目录复制到 namenode2 上
# scp -r /data/hadoop.data hadoop02:/data可以看到刚刚格式化后生成的 fsimage 文件被复制到 namenode2 上

2.5 启动 namenode 和 datanode
在 hadoop01 上运行:
# start-dfs.sh 输出如下:
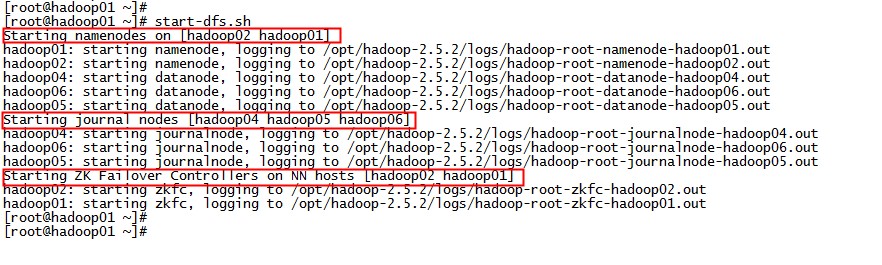
可以看到 namenode, datanode, journalnode, zkfc 都如期启动了。
2.6 启动 yarn
在 hadoop03 上运行:
# start-yarn.sh输出如下:

可以看到 resourcemanager, nodemanager 都如期启动了
下一篇文章,我们来操作 hdfs, 并搭建 hadoop 开发环境,编写 hdfs api 及 mapreduce 的例子。















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









