







导读:
·云原生数据库起源于Amazon,随之受到国内厂商的广泛关注。以华为云、阿里云、腾讯云等为代表的头部厂商投入大量资源进行研发。仅三年左右的时间,市场已经形成较为成熟的云原生数据库应用模式并应用在不同的场景中。

云原生数据库架构特点
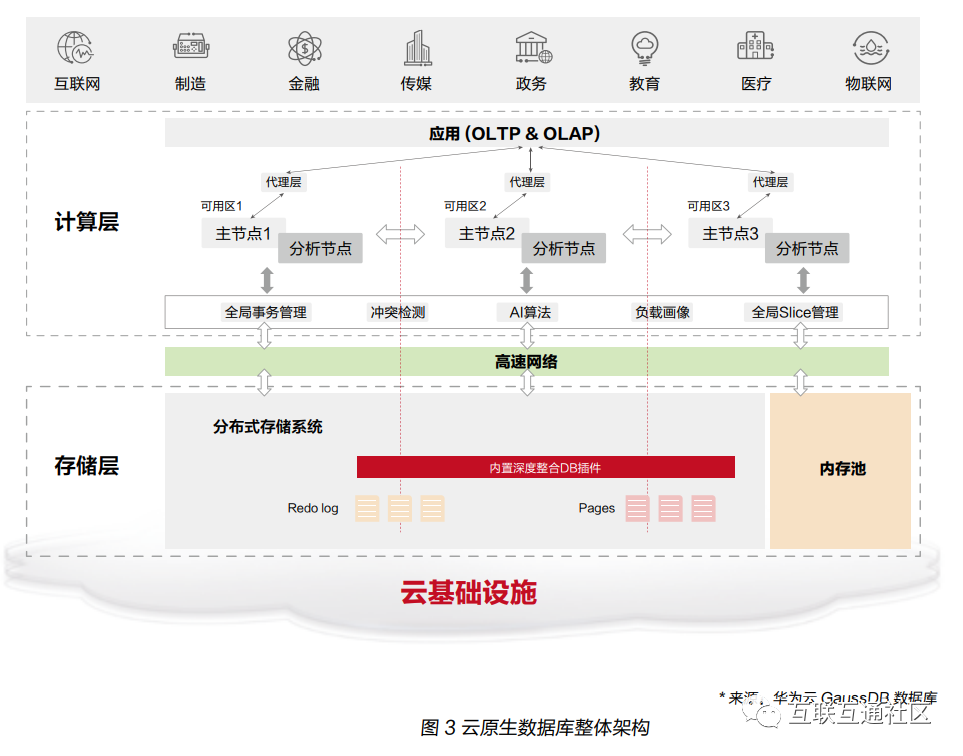
云原生数据库在架构上实现:资源池化存算分离,并且与云基础设施深度结合和优化;以应用为中心,统一数据入口及数据管理,应用透明无感知,多模兼容全开放。
1.资源池化存算
分离云原生数据库的主要架构特征是“存算分离”,即采用计算资源层与存储资源层解耦的技术架构,让所有节点都共享一份存储,从而实现增加计算节点无需调整存储资源或拷贝数据文件的目的。在这种架构下,云原生数据库能充分发挥各种资源的弹性能力,从1U到数百U都可以充分利用CPU计算能力,支持百TB以上的存储容量无感弹性伸缩。在云原生2.0时代,计算资源层中CPU算力与内存也会解耦,从1G到上T的内存也都可以在线热伸缩。
2.与云深度结合和优化
云原生2.0时代,云原生数据库不仅要基于云端硬件资源池化来实现数据库的计算存储弹性伸缩和分布式部署能力,还需要能够利用云基础设施本身的特性。云原生数据库会越来越紧密地和云基础设施结合,充分利用云基础设施内在的能力来完善数据库的功能,提供更优的性能。比如利用云基础设施本身的跨可用区部署能力,实现数据库的跨可用区部署访问;利用云基础设施跨地域布局的特点,实现数据库的全球就近接入和异地灾备能力;利用存储层的近存储并行处理能力,计算层下推数据库要处理的语义到存储层,进而在存储层预处理数据库的算子,避免计算层和存储层不必要的数据交互;利用存储层的日志回放能力,节省计算层和存储层的高速网络带宽。
3.统一入口应用透明
以应用为中心的云原生数据库,在架构设计上应充分考虑应用使用数据库的无感知,如用水用电一样方便地使用云原生数据库。首先是事务型数据库和分析型数据库的融合。随着现阶段数据业务分类越来越模糊,即分析业务事务化、事务业务分析化,云原生数据库只有支持HTAP混合负载处理的能力,才能让应用在开发设计时不再需要考虑哪些逻辑放到事务型数据库里处理,哪些逻辑放到分析型数据库里处理,从而都交由云原生数据库一个入口来统一处理,使得数据库内部转换逻辑对应用透明无感知。
其次是在运行过程中的透明性。云原生数据库应支持在数据库系统切换与故障转移时提供无损的应用连续性,让正在运行的应用无感知。同时,在多个只读节点的架构下,云原生数据库应支持多个只读节点的全局一致性,应用在使用时可以访问任意一个节点查询数据,不用担心数据的不一致性。为避免应用单点写入可靠性不足的问题,云原生数据库还应具备多主的能力,自动均衡业务请求,高效处理写冲突,让应用使用无感知。
4.多模兼容全开放
云原生数据库应该具备兼容多种生态接口的统一架构,利用同样的云基础设施资源,既可以使用MySQL、PostgreSQL这样的SQL接口访问数据库,也可以使用Redis、MongoDB等NoSQL接口访问。除了支持关系型数据存储模型,也应该支持多种模型的兼容访问,比如支持KV模型、时序模型、文档存储模型等。
云原生数据库通过多层次解耦完成数据融合。底层StorageLayer通过统一的智能化分布式存储架构,提供脱离语义的数据能力和基础分布式一致性可扩展存储能力;不同引擎的数据格式不同、存储模式不同,需要不同的插件,中间层IndexLayer通过插件化的方式处理不同引擎所需要的不同数据组织和存储语义;上层的SQLInterfaceLayer则主要负责生态的兼容,每个数据引擎的实现代表各自独特的生态,如MySQL、openGauss及非关系型数据库MongoDB(文档型)、Redis(KV型)、InfluxDB(时序型)、Cassandra(宽列型)等生态,提供高性能、高可靠、高安全、低成本的同时,还提供多模型一致的运维体验。
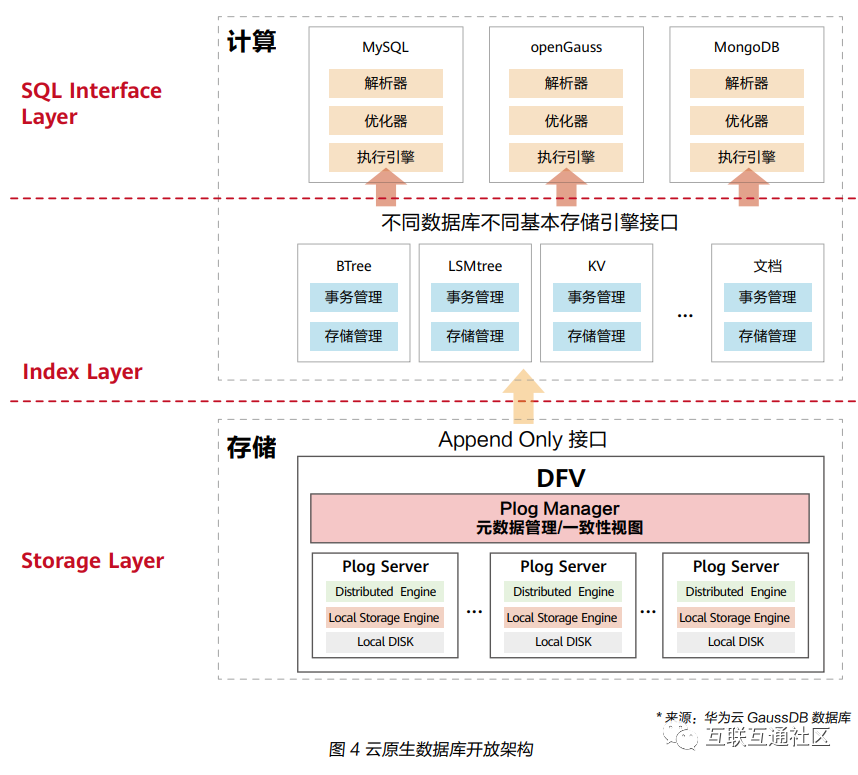
云原生时代数据库的生态一定是开放的,用户可以自由地在不同的云数据库之间迁移,用户不会再选择封闭的生态,无论自研生态还是开源生态均完全开放。因此云原生数据库应支持用户在不同的数据库之间迁移数据,而不应绑定用户。要么兼容开源生态,可以使用开源生态的工具进行迁移;要么开放核心引擎的源码,社区可以自研迁移工具自由切换到其他生态。开放生态的数据库将成为世界数据库的主流。
云原生数据库典型架构示例
以华为云GaussDB(forMySQL)云原生数据库为例,它的架构构建在多租户共享的分布式存储系统之上。它的SQL引擎是一个经过深度修改的MySQL8.0版本,因此在语法和语义方面与MySQL100%兼容,计算节点和存储之间使用RDMA网络。
GaussDB(forMySQL)使用的存储系统是一种高可靠的跨可用区云存储。在公有云上,存储系统可以是一个有几十或数百个节点的大型集群,横向扩展能力比单租户线下方案高很多倍。SQL节点将REDO日志写到存储层,页面在存储层物化,此设计显著减少了更新密集型工作负载的网络通信。属于单个数据库的页面以Slice形式组织,Slices分布在多个存储节点上,这个数据分布就是分布式查询的基础。
GaussDB(forMySQL)自上向下分为3大部分:SQL节点、存储抽象层SAL(StorageAbstractLayer)以及存储层(StorageNodes)。
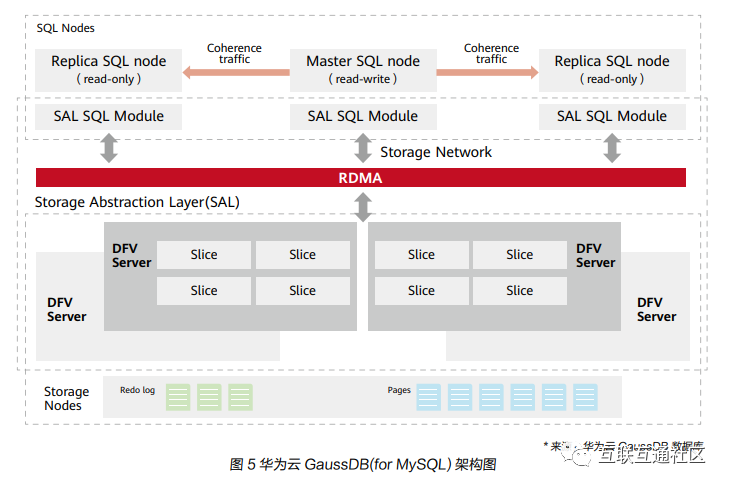
首先,SQL节点形成一个集群,可以是一个主节点和多个只读副本。每个集群属于一个云租户,一个租户可以具有多个集群。SQL节点能够管理客户端连接、解析SQL请求、生成查询执行计划、执行查询以及管理事务隔离。
其次是SAL(存储抽象层),它是SQL节点和存储层之间的桥接器。SAL包括两个主要组件,SALSQL模块和DFV(DataFunctionVirtualization,是一款与数据库垂直整合的高性能、高可靠的分布式存储系统)存储节点内部的Slice存储。SALSQL模块为SQL节点提供了SALAPI,用以与底层存储系统进行交互。SliceStore是在DFV存储节点内部运行的插件模块,它需要与DFV存储框架一起使用,用以在相同DFV节点上管理多个数据库分片,支持多租户资源共享,并将页面的多个版本提供给SQL节点。对于每个分片,SliceStore使用日志目录作为中心组件来管理REDO日志和页面数据。SliceStore的主要职责是接收分片REDO日志,将其持久化并注册到日志目录中;接收页面阅读请求并构建特定版本的页面以及垃圾回收和合并日志。
最后,GaussDB(forMySQL)存储层建立在DFV持久层之上,DFV持久层为上层SQL节点存储提供读写接口,提供跨3个可用区之间的数据强一致性和可靠性保证。存储层里包含日志存储节点LogStore和页面存储节点PageStore,日志存储主要是持久化由SQL节点生成的日志记录,日志存储的底层存储对象称为PLog,PLog是一种大小有限的、追加型的存储对象,可以在多个日志存储节点之间同步复制。页面存储节点的主要功能是处理来自数据库主节点和只读节点的页面读取请求。页面存储必须能够提供数据库前端请求页面的任何版本,因此页面存储必须能够访问其负责的页面的所有日志记录。
在这种体系架构下,整个数据库集群只需一份足够可靠的数据库副本集,极大节约成本。同时,所有只读副本共享云存储中的数据,去除数据库层的复制逻辑。没有独立的备用实例,当主节点发生故障,集群进行切换操作时,只读副本可以切换为主节点,接管集群服务。而且由于只有数据库日志通过网络从数据库计算节点写入DFV存储层,没有脏页、逻辑日志和双写的流量,极大节省了网络资源。
互联互通社区
互联互通社区-IT智库,是互联互通社区IT架构、前沿技术平台。包含科技趋势、总体架构、产业架构、技术架构、系统架构、业务架构等内容,内容简练,皆属干货,合作请+微信:hulianhutongshequ.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









