









知道文法规则后,我们就要分析出其中的所有的符号、操作符、标示符(id)、字面值(nb)、以及关键字。其中符号、操作符、关键字都是一符一类,我们需要写程序分析每一个字符,最终得到一个token序列,标示符表及字面值表。闲话少说,看代码(下面程序使用vs2013编译)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//token结构体
struct Token
{
Token(string str, int pos)
{
this->type = str;
this->pos = pos;
}
string type;
int pos;
};
vector<string> IdTable; //全局变量,词法分析得到的标示符表
vector<int> NbTable; //全局变量,词法分析得到的INTC值表
#define ERROR_INVALID_SYMBOL 1 //宏定义错误:非法符号
#define NO_ERROR 0 //宏定义 :没有错误
int error = NO_ERROR; //全局变量,记录词法分析中的错误类型
/*
*判断字符是不是其他字符
*/
bool IsOther(char ch)
{
if (ch >= 'A'&&ch <= 'Z')
return false;
if (ch >= 'a'&&ch <= 'z')
return false;
if (ch >= '0'&&ch <= '9')
return false;
return true;
}
/*
*判断字符串是不是关键字
*/
bool IsKeyWord(string str)
{
if (str == "integer")
return true;
if (str == "char")
return true;
if (str == "program")
return true;
if (str == "array")
return true;
if (str == "of")
return true;
if (str == "record")
return true;
if (str == "end")
return true;
if (str == "var")
return true;
if (str == "procedure")
return true;
if (str == "begin")
return true;
if (str == "if")
return true;
if (str == "then")
return true;
if (str == "else")
return true;
if (str == "fi")
return true;
if (str == "while")
return true;
if (str == "do")
return true;
if (str == "endwh")
return true;
if (str == "read")
return true;
if (str == "write")
return true;
if (str == "return")
return true;
if (str == "type")
return true;
return false;
}
/*
*返回字符串在表中的位置,没有就加到最后,并返回下标
*/
int AddIdTable(string str)
{
for (int i = 0; i < IdTable.size(); i++)
{
if (str == IdTable[i])
return i;
}
IdTable.push_back(str);
return IdTable.size()-1;
}
/*
*返回数字在表中的位置,没有就加到最后,并返回下标
*/
int AddNbTable(string str)
{
int num = atoi(str.c_str());
for (int i = 0; i < NbTable.size(); i++)
{
if (num == NbTable[i])
return i;
}
NbTable.push_back(num);
return NbTable.size() - 1;
}
/*
*词法分析扫描程序,每次调用返回一个Token指针
*/
Token *Scanner(FILE *pf)
{
char ch = 0;
string tmpStr = "";
Token * pToken = NULL;
LS0://根据第一个字符确定程序走向
ch = fgetc(pf);
if (ch != EOF)
{
if ((ch >= 'A' &&ch <= 'Z') || (ch >= 'a' && ch <= 'z'))
goto LS1;
if (ch >= '0' &&ch <= '9')
goto LS2;
if (ch == '+')
goto LS3;
if (ch == '-')
goto LS4;
if (ch == '*')
goto LS5;
if (ch == '/')
goto LS6;
if (ch == '<')
goto LS7;
if (ch == ';')
goto LS8;
if (ch == ':')
goto LS9;
if (ch == ',')
goto LS10;
if (ch == '.')
goto LS11;
if (ch == '=')
goto LS12;
if (ch == '[')
goto LS13;
if (ch == ']')
goto LS14;
if (ch == '(')
goto LS15;
if (ch == ')')
goto LS16;
if (ch == ' ' || ch == '\n' || ch == '\r' || ch == '\t')
goto LS17;
goto LS18;
}
else
{
return NULL;
}
LS1://标示符和关键字
{
tmpStr += ch;
ch = fgetc(pf);
if ((ch >= 'A' &&ch <= 'Z') || (ch >= 'a' && ch <= 'z') || (ch >= '0' &&ch <= '9'))
goto LS1;
if (IsOther(ch))
{
ungetc(ch, pf);//把读到的字符放回到文件流中
if (IsKeyWord(tmpStr))
{
//关键字
pToken = new Token("$"+tmpStr,-1);
return pToken;
}
else
{
//不是关键字,是标示符
int pos = AddIdTable(tmpStr);
pToken = new Token("$id", pos);
return pToken;
}
}
}
LS2://数字
{
tmpStr += ch;
ch = fgetc(pf);
if (ch >= '0' &&ch <= '9')
goto LS2;
if (IsOther(ch))
{
ungetc(ch, pf);
int pos = AddNbTable(tmpStr);
pToken = new Token("$INTC", pos);
return pToken;
}
}
LS3://'+'
{
pToken = new Token("$+", -1);
return pToken;
}
LS4://'-'
{
pToken = new Token("$-", -1);
return pToken;
}
LS5://'*'
{
pToken = new Token("$*", -1);
return pToken;
}
LS6://'/'
{
pToken = new Token("$/", -1);
return pToken;
}
LS7://'<'
{
pToken = new Token("$<", -1);
return pToken;
}
LS8://';'
{
pToken = new Token("$;", -1);
return pToken;
}
LS9://':'
{
ch = fgetc(pf);
if (ch == '=')
{
pToken = new Token("$:=", -1);
return pToken;
}
if (IsOther(ch))
{
error = ERROR_INVALID_SYMBOL;
printf("错误:“:”不是合法的符号\n");
return NULL;
}
}
LS10://','
{
pToken = new Token("$comma", -1);
return pToken;
}
LS11://'.'
{
pToken = new Token("$.", -1);
return pToken;
}
LS12://'='
{
pToken = new Token("$=", -1);
return pToken;
}
LS13://'['
{
pToken = new Token("$[", -1);
return pToken;
}
LS14://']'
{
pToken = new Token("$]", -1);
return pToken;
}
LS15://'('
{
pToken = new Token("$(", -1);
return pToken;
}
LS16://')'
{
pToken = new Token("$)", -1);
return pToken;
}
LS17://空白符
{
goto LS0;
}
LS18://other
{
error = ERROR_INVALID_SYMBOL;//设置全局变量error
printf("错误:含有非法符号( %c )\n", ch);//打印错误信息
return NULL;
}
}
/*
*主函数,如果argc大于等于2,argv[1]为源文件名,否则默认为snl.txt
*/
int main(int argc, char ** argv)
{
//设置源文件
string filename;
if (argc >= 2)
filename = argv[1];
else
filename = "snl.txt";
//打开源文件
FILE *pf = fopen(filename.c_str(),"r");
if (!pf)
{
printf("打开文件失败!\n");
return -1;
}
vector <Token> result;
Token * pToken = NULL;
while ((pToken = Scanner(pf)) != NULL)
{
result.push_back(*pToken);
delete pToken;
pToken = NULL;
}
fclose(pf);
if (error == NO_ERROR)
{
pf = fopen((filename + ".token").c_str(), "w+");
for (auto &iter : result)
{
if (iter.type == "$id" || iter.type == "$INTC")
{
printf("(%-10s, [%2d] )\n", iter.type.c_str(), iter.pos);
fprintf(pf, "(%s,[%d])\n", iter.type.c_str(), iter.pos);
}
else
{
printf("(%-10s, \" \" )\n", iter.type.c_str());
fprintf(pf, "(%s,\"\")\n", iter.type.c_str());
}
}
fclose(pf);
pf = fopen((filename + ".idtable").c_str(), "w+");
for (int i = 0; i < IdTable.size(); i++)
{
fprintf(pf, "%s\n", IdTable[i].c_str());
}
fclose(pf);
pf = fopen((filename + ".nbtable").c_str(), "w+");
for (int i = 0; i < NbTable.size(); i++)
{
fprintf(pf, "%d\n", NbTable[i]);
}
fclose(pf);
}
system("pause");
}程序输出的是token序列,以及标示符表和字面值表
token表文件名称为 *.token文件
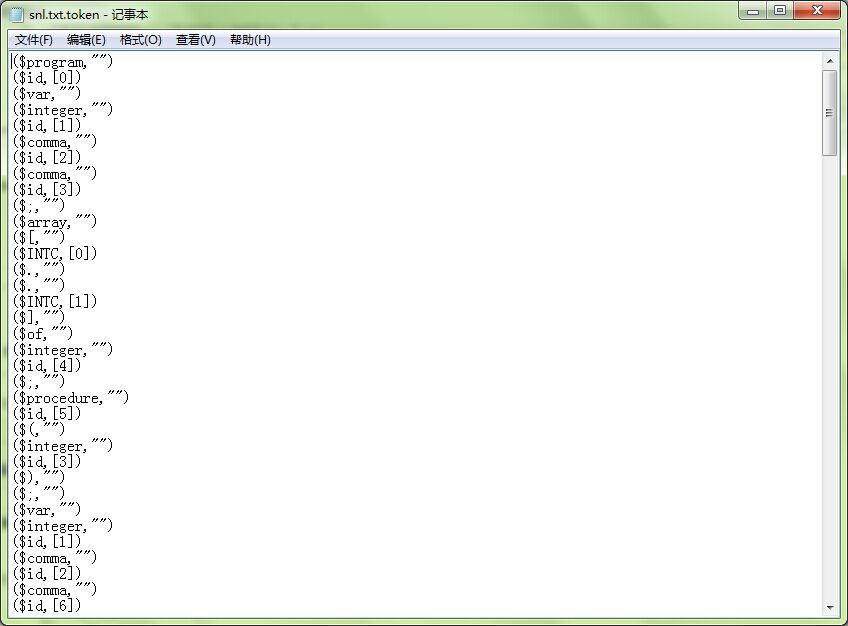
其他两个表在语法分析中用不到,生成文件名称分别为*.idtable和*.nbtable。















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









