






目录
5.3.3.3 find_parents() 和 find_parent()
5.3.3.4 find_next_siblings() 和 find_next_sibling()
5.3.3.5 find_previous_siblings() 和 find_previous_sibling()
5.3.3.6 find_all_next() 和 find_next()
5.3.3.7 find_all_previous() 和 find_previous()

一.什么是Python爬虫
Python爬虫是使用Python编程语言编写的程序,用于自动化地获取互联网上的数据。它通过模拟浏览器的行为,发送HTTP请求并获取网页的HTML内容,然后从HTML中提取所需信息,并进行数据处理和存储。
二.HTML文件格式
Python爬虫可以获取网页的HTML格式内容,并对其进行解析和处理。HTML(Hypertext Markup Language)是一种用于创建网页结构和内容的标记语言。接下来为大家简单的讲解一下HTML文件。
以下是一个简单的HTML文档示例:
<!DOCTYPE html>
<html>
<head>
<title>我的第一个网页</title>
</head>
<body>
<h1>欢迎来到我的网页</h1>
<p>这是一个示例段落。</p>
<img src="example.jpg" alt="示例图片">
<a href="https://www.example.com">点击这里访问示例网站</a>
</body>
</html>在上面的例子中:
<!DOCTYPE html>:这是文档类型声明,指定了HTML版本。<html>:这是HTML文档的根元素,它包含整个HTML内容。<head>:这个部分包含有关文档的元信息,例如标题、字符集设置和链接到外部资源等。<title>:这个标签定义了文档的标题,显示在浏览器的标题栏或标签页上。<body>:这个部分包含了网页的可见内容,例如文本、图像、链接等。<h1>:这是一个标题标签,用于表示一级标题。<p>:这是一个段落标签,用于表示文本段落。<img>:这是一个图像标签,用于插入图像到网页中。<a>:这是一个链接标签,用于创建超链接到其他网页或资源。
HTML是构建网页的基础,并且通常与CSS(层叠样式表)和JavaScript一起使用,用于实现更复杂和交互性的网页设计和功能。网页浏览器能够解析HTML并将其呈现给用户,使其成为互联网中最常见的内容呈现格式。
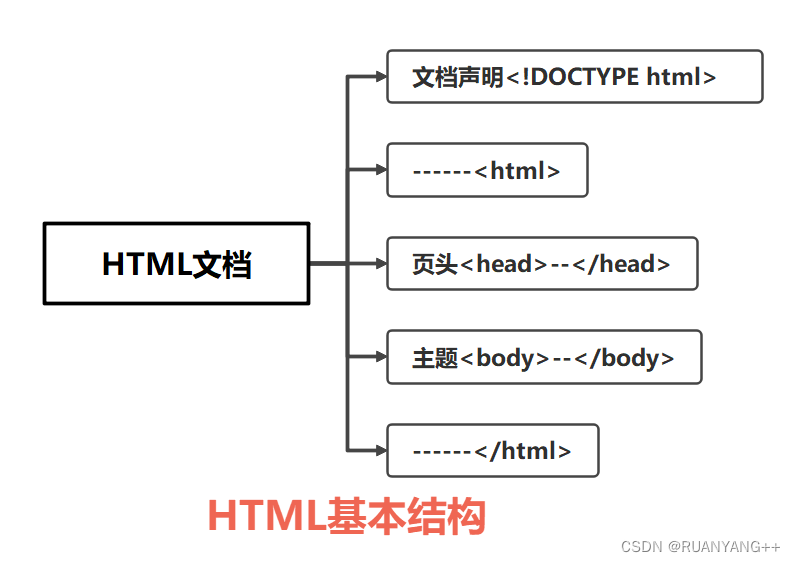
2.1 HTML格式的基本结构
HTML的基本结构由文档类型声明(DOCTYPE)、HTML根元素(<html>)、头部部分(<head>)和主体部分(<body>)组成。下面我将详细解释HTML的基本结构。
1. 文档类型声明(DOCTYPE):
在HTML文档的开头,应该始终包含文档类型声明,用于指定文档使用的HTML版本。它告诉浏览器使用何种规范来解析文档。
<!DOCTYPE html>2. HTML根元素(<html>):
HTML文档的根元素是`<html>`标签,它包含了整个HTML内容。
<html>
<!-- 在这里放置头部和主体内容 -->
</html> 3.头部部分(<head>):
<head>标签包含关于文档的元信息和引用的外部资源,例如标题、字符集设置、样式表、脚本等。
<head>
<!-- 在这里放置文档的元信息和外部资源链接 -->
</head>
4.主体部分(<body>):
<body>标签包含了网页的可见内容,如文本、图像、链接、表格等。用户将在浏览器中看到主体部分的内容。
<body>
<!-- 在这里放置网页的可见内容 -->
</body>
综合起来,一个完整的HTML文档如下所示
HTML结构示意图:
2.2 HTML标签
2.2.1 HTML基本标签
2.2.1.1 HTML标签
整个网页是从<html>这里开始的,然后到</html>结束。
2.2.1.2 head标签
head标签代表页面的“头”,定义一些特殊内容,这些内容往往都是“不可见内容”(在浏览器不可见)。
| <head>内部标签 | 说明 |
| <title> | 定义网页的标题 |
| <meta> | 定义网页的基本信息(供搜索引擎) |
| <style> | 定义CSS样式 |
| <link> | 链接外部CSS文件或脚本文件 |
| <script> | 定义脚本语言 |
| <base> | 定义页面所有链接的基础定位(用得很少) |
body标签代表页面的“身”,定义网页展示内容,这些内容往往都是“可见内容”(在浏览器可见)。
2.2.2 段落与文字
2.2.2.1 段落与文字标签
| 标签 | 语义 | 标签 |
| <h1>~<h6> | header | 标题 |
| <p> | paragraph | 段落 |
| <br> | break | 换行 |
| <hr> | horizontal rule | 水平线 |
| <div> | division | 分割(块元素) |
| <span> | span | 区域(行内元素) |
(1)标题
HTML 标题(Heading)是通过<h1> - <h6> 标签来定义的.
(2)段落
HTML 段落是通过标签 <p> 来定义的
2.2.2.2 文字格式化标签
| 标签 | 语义 | 说明 |
| <strong> | strong(加强) | 加粗 |
| <em> | emphasized(强调) | 斜体 |
| <cite> | cite(引用) | 斜体 |
| <sup> | superscripted(上标) | 上标 |
| <sub> | subscripted(下标) | 下标 |
2.2.3 列表
| 标签 | 语义 | 说明 |
| ol | ordered list | 有序列表 |
| ul | unordered list | 无序列表 |
| dl | definition list | 定义列表 |
HTML3种列表
列表有3种:有序列表、无序列表和定义列表。
有序列表和无序列表都比较常用,而定义列表比较少用。在实际应用中,最常用的是无序列表,请大家重点掌握。
目录列表和菜单列表已经被废除,大家可以直接忽略这两种列表。
(1)有序列表
语法:
<ol>
<li>有序列表项</li>
<li>有序列表项</li>
<li>有序列表项</li>
</ol>
| type属性值 | 列表项的序号类型 |
| 1 | 数字1、2、3…… |
| a | 小写英文字母a、b、c…… |
| A | 大写英文字母A、B、C…… |
| i | 小写罗马数字i、ii、iii…… |
| I | 大写罗马数字I、II、III…… |
(2)无序列表
无序列表是三个列表中最为重要的列表。
语法:
<ul type="列表项符号">
<li>无序列表项</li>
<li>无序列表项</li>
<li>无序列表项</li>
</ul>
| type属性值 | 列表项的序号类型 |
| disc | 默认值,实心圆“●” |
| circle | 空心圆“○” |
| square | 实心正方形“■” |
(3)定义列表
语法:
<dl>
<dt>定义名词</dt>
<dd>定义描述</dd>
……
</dl>
说明:
<dl>即“definition list(定义列表)”,<dt>即“definition term(定义名词)”,而<dd>即“definition description(定义描述)”。
在该语法中,<dl>标记和</dl>标记分别定义了定义列表的开始和结束,<dt>后面添加要解释的名词,而在<dd>后面则添加该名词的具体解释。
2.2.4 链接
HTML 链接是通过标签 <a> 来定义的
语法:
<a href="链接地址" target="目标窗口的打开方式">
| target属性值 | 说明 |
| _self | 默认方式,即在当前窗口打开链接 |
| _blank | 在一个全新的空白窗口中打开链接 |
| _top | 在顶层框架中打开链接 |
| _parent | 在当前框架的上一层里打开链 |
2.2.5 图片
HTML 图像是通过标签 <img> 来定义的
语法:
<img src="图片地址" alt="图片描述(给搜索引擎看)" title="图片描述(给用户看)">
| 属性 | 说明 |
| src | 图像的文件地址 |
| alt | 图片显示不出来时的提示文字 |
| title | 鼠标移到图片上的提示文字 |
2.2.6 表格
2.2.6.1 表格基本标签
| 标签 | 语义 | 说明 |
| table | table(表格) | 表格 |
| tr | table row(表格行) | 行 |
| td | table data cell(表格单元格) | 单元格 |
2.2.6.2 表格结构标签
| 标签 | 语义 | 说明 |
| thead | table head | 表头 |
| tbody | table body | 表身 |
| tfoot | table foot | 表脚 |
| th | table header | 表头单元格 |
2.2.6.3 表格基本结构
<table>、<tr>和<td>是HTML表格最基本的3个标签,其他标题标签<caption>、表头单元格<th>可以没有,但是这3者必须要有。
语法:
<table>
<tr>
<td>单元格1</td>
<td>单元格2</td>
</tr>
<tr>
<td>单元格1</td>
<td>单元格2</td>
</tr>
</table>
说明:
<table>和</table>标记着表格的开始和结束,<tr>和</tr>标记着行的开始和结束,在表格中包含几组<tr></tr>就表示该表格为几行。<td>和</td>标记着单元格的开始和结束。
2.2.6.4 表格的完整结构
表格完整结构应该包括表格标题(caption)、表头(thead)、表身(tbody)和表脚(tfoot)4部分。
语法:
<table>
<caption>表格标题</caption>
<!--表头-->
<thead>
<tr>
<th>表头单元格1</th>
<th>表头单元格2</th>
</tr>
</thead>
<!--表身-->
<tbody>
<tr>
<td>标准单元格1</td>
<td>标准单元格2</td>
</tr>
<tr>
<td>标准单元格1</td>
<td>标准单元格2</td>
</tr>
</tbody>
<!--表脚-->
<tfoot>
<tr>
<td>标准单元格1</td>
<td>标准单元格2</td>
</tr>
</tfoot>
</table>说明:
<thead>、<tbody>和<tfoot>这三个标签分别表示表头、表身、表脚。th表示表头单元格,th表示表身单元格。每一对“<tr></tr>”表示一行。
三.requests库
在Python中,requests库是一个常用的第三方库,用于发送HTTP请求和处理响应。它提供了简洁而直观的API,使得进行网络请求和数据获取变得非常容易。
3.1 request使用
3.1.1 requests安装
安装requests库可以按照以下步骤进行:
-
首先确保已经安装了Python。"requests"库兼容Python 2.7和Python 3.x版本。
-
使用pip命令进行安装。pip是Python的包管理工具,通常在安装Python时自动安装。
在命令行中输入以下命令来安装"requests"库:
pip install requests如果使用的是Python 3,并且同时安装了Python 2.x,请确保使用
pip3命令来安装:pip3 install requests -
等待安装完成。pip会自动下载并安装"requests"库及其依赖项。
-
安装完成后,你就可以在Python代码中导入并使用"requests"库了。
3.1.2 requests响应
在下载好request库后,我们要使用它,首先要进行引用,在代码中导入:
import request导入后就可以发送 HTTP 请求,使用 requests 提供的方法向指定 URL 发送 HTTP 请求,例如:
# 导入 requests 包
import requests
# 发送请求
x = requests.get('https://www.runoob.com/')
# 返回网页内容
print(x.text)每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等:
print(response.status_code) # 获取响应状态码
print(response.headers) # 获取响应头
print(response.content) # 获取响应内容| 属性/方法 | 说明 |
| apparent_encoding | 编码方式 |
| close() | 关闭与服务器的连接 |
| content | 返回响应的内容,以字节为单位 |
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
| elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
| encoding | 解码 r.text 的编码方式 |
| headers | 返回响应头,字典格式 |
| history | 返回包含请求历史的响应对象列表(url) |
| is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
| is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
| iter_content() | 迭代响应 |
| iter_lines() | 迭代响应的行 |
| json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| links | 返回响应的解析头链接 |
| next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
| ok | 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
| raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
| reason | 响应状态的描述,比如 "Not Found" 或 "OK" |
| request | 返回请求此响应的请求对象 |
| status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| text | 返回响应的内容,unicode 类型数据 |
| url | 返回响应的 URL |
3.1.3 requests请求
requests库中的方法:
| 方法 | 说明 |
| delete(url, args) | 发送 DELETE 请求到指定 url |
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
3.1.3.1 get方法
3.1.3.1.1 get方法使用
在"requests"库中,可以使用get()方法来发送GET请求。该方法接受一个URL作为参数,并返回一个Response对象,其中包含服务器的响应。
以下是使用get()方法发送GET请求的基本语法:
import requests
response = requests.get(url, params=None, **kwargs)参数说明:
url(必需):请求的URL地址。params(可选):一个字典或字节序列,用于设置查询字符串参数。例如,params={'key1': 'value1', 'key2': 'value2'}。**kwargs:可选的关键字参数,用于设置请求头、超时时间、代理等其他配置。常用的关键字参数有headers、timeout、proxies等。
3.1.3.1.2 get方法中常用参数
| 参数 | 类型 | 作用 |
| params | 字典 | url为基准的url地址,不包含查询参数;该方法会自动对params字典编码,然后和url拼接 |
| url | 字符串 | requests 发起请求的地址 |
| headers | 字典 | 请求头,发送请求的过程中请求的附加内容携带着一些必要的参数 |
| cookies | 字典 | 携带登录状态 |
| proxies | 字典 | 用来设置代理 ip 服务器 |
| timeout | 整型 | 用于设定超时时间, 单位为秒 |
3.1.3.2 post方法
3.1.3.2.1 post方法使用
在"requests"库中,可以使用`post()`方法来发送POST请求。该方法接受一个URL作为参数,并返回一个`Response`对象,其中包含服务器的响应。
以下是使用`post()`方法发送POST请求的基本语法:
import requests
response = requests.post(url, data=None, json=None, **kwargs)参数说明:
- url(必需):请求的URL地址。
- data(可选):一个字典、字节序列或文件对象,用于设置请求体中的数据。
- json(可选):一个Python对象,会被自动编码为JSON格式并设置为请求体中的数据。
- **kwargs:可选的关键字参数,用于设置请求头、超时时间、代理等其他配置。常用的关键字参数有`headers`、`timeout`、`proxies`等。
3.1.3.2.2 post方法中常用参数
| 参数 | 类型 | 作用 |
| data | 字典 | 作为向服务器提供或提交资源时提交,主要用于 post 请求 |
| json | 字典 | json格式的数据, json合适在相关的html |
3.1.3.3 request方法
在"requests"库中,可以使用requests()方法发送任意类型的HTTP请求。该方法接受一个HTTP请求方法(如GET、POST、PUT等)作为参数,并返回一个Response对象,其中包含服务器的响应。
使用requests()方法发送请求的基本语法:
import requests
response = requests.request(method, url, **kwargs)参数说明:
method(必需):请求的HTTP方法,可以是GET、POST、PUT、DELETE等。url(必需):请求的URL地址。**kwargs:可选的关键字参数,用于设置请求头、超时时间、代理等其他配置。常用的关键字参数有data、json、headers、timeout、proxies等,具体取决于请求的需要。
例如,下面是一个简单的例子,演示了如何使用requests()方法发送GET请求并处理响应:
import requests
url = 'https://api.example.com/songs'
response = requests.request('GET', url)
if response.status_code == 200: # 请求成功
data = response.json() # 解析响应的JSON数据
print(data)
else: # 请求失败
print('Request failed with status code:', response.status_code) 在这个例子中,我们使用requests()方法发送一个GET请求到'https://api.example.com/songs',并检查响应的状态码。如果状态码为200,表示请求成功,我们可以通过.json()方法解析响应内容并打印出来;否则,我们打印出请求失败的状态码。
需要注意的是,requests()方法可以发送任意类型的HTTP请求,只需要将对应的HTTP方法作为第一个参数传递给它即可。例如,要发送POST请求,可以使用requests.request('POST', url, data=data);要发送PUT请求,可以使用requests.request('PUT', url, data=data),依此类推。其他配置参数也可以通过**kwargs传递,根据具体需求设置。
3.1.3.4 headers方法
在"requests"库中,可以使用head()方法发送一个HEAD请求,并返回服务器响应的头部信息。HEAD请求类似于GET请求,但是服务器只会返回头部信息,而不会返回实际的响应内容。
使用head()方法发送HEAD请求的基本语法:
import requests
response = requests.head(url, **kwargs)参数说明:
url(必需):请求的URL地址。**kwargs:可选的关键字参数,用于设置请求头、超时时间、代理等其他配置,与request()方法的参数一样。
下面是一个简单的例子,演示了如何使用head()方法发送HEAD请求并处理响应:
import requests
url = 'https://www.example.com/'
response = requests.head(url)
if response.status_code == 200: # 请求成功
headers = response.headers # 获取响应头信息
print(headers)
else: # 请求失败
print('Request failed with status code:', response.status_code) 在这个例子中,我们使用head()方法发送一个HEAD请求到'Example Domain',然后通过response.headers属性获取服务器返回的响应头信息,并进行处理或打印。
需要注意的是,head()方法只返回服务器响应的头部信息,而不会返回实际的响应内容。这对于只关注头部信息而不需要实际内容的场景非常有用。
四.Re正则表达式
正则表达式(Regular Expression,简称 Regex 或 Regexp)是一种用于匹配和操作文本模式的工具。它可以被用于各种编程语言和文本处理工具中,用于在字符串中查找、匹配和操作特定的文本模式。正则表达式提供了一种强大的方式来描述字符串的模式,使用户能够更精确地进行文本处理和操作。
4.1 正则表达式的结构
正则表达式(Regular Expression)的结构由一系列字符和特殊字符组成,用于定义一个搜索模式。这个模式可以被用来检查字符串是否符合特定的格式要求,或者从文本中提取出特定的信息。
4.1.1 普通字符
正则表达式中的普通字符是指不具有特殊含义的普通文本字符。这些字符会直接按照字面意义进行匹配,而不会被解释为特殊的规则。在正则表达式中,普通字符包括所有字母、数字、标点符号和其他键盘上可见的字符,例如 `a`、`b`、`1`、`2`、`!`、`@` 等。
当需要匹配一个特定的字符时,可以直接将其写入正则表达式中,不需要对其进行转义或使用其他特殊符号。例如,正则表达式 `apple` 会匹配字符串中的 "apple",但不会匹配 "appl" 或 "aple"。
需要注意的是,普通字符在某些上下文中可能会成为特殊字符。例如,如果在正则表达式中使用 `.`(点)字符,它会被解释为通用字符,匹配任意字符(除了换行符)。如果要匹配字面意义上的点字符,需要使用转义符号 `\`,即 `\.`。
4.1.2 元字符
正则表达式中的元字符是指具有特殊含义的特殊字符,用于表示匹配规则的组成部分。这些元字符在正则表达式中具有特殊用途,可以用于构建复杂的模式来进行字符串匹配、查找、替换和提取操作。以下是一些常见的正则表达式元字符:
| 代码 | 说明 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始(在集合字符里[^a]表示非(不匹配)的意思 |
| $ | 匹配字符串的结束 |
4.1.3 反义字符
在正则表达式中,反义元字符用于匹配与某些元字符相反的内容。它们与普通元字符的匹配规则相反,表示不匹配某些特定字符或字符类。以下是一些常见的正则表达式反义元字符:
| 代码 | 说明 |
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
4.1.4 量词
正则表达式的量词用于指定前面的元素出现的次数。它们控制了匹配模式中的重复次数,可以让你更灵活地定义匹配的字符串模式。以下是常见的正则表达式量词:
| 代码 | 说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
4.1.5 转义字符
正则表达式的量词没有直接的转义字符,它们通常是由普通字符和特殊字符组合而成。前面提到的量词如 *、+、?、{n}、{n,}、{n,m} 都是直接使用的,不需要转义。当然,在一些编程语言或工具中,正则表达式的字符串可能需要进行转义处理,以确保正则表达式被正确解释和匹配。
例如,如果你想匹配一个文本中的连续星号(*),你可以使用 \* 来转义它,以避免被当作量词的一部分。类似地,其他特殊字符也可能需要转义,具体情况取决于你使用正则表达式的环境。
总之,正则表达式的量词本身并不需要转义,但在特定情况下,你可能需要转义包含在正则表达式中的特殊字符,以确保它们被正确处理。
4.1.6 字符分枝
当谈到正则表达式中的字符分支时,我们实际上是在讨论如何匹配多个可能的字符之一。字符分支可以通过使用垂直线 | 来实现,它表示“或”关系。这使得我们可以在一个正则表达式中指定多个备选字符,只要其中之一匹配,整个表达式就会匹配。
例如,如果你想匹配单词 "color" 或 "colour",你可以使用正则表达式 colou(r|ur)。在这个表达式中,(r|ur) 表示一个字符分支,它会匹配一个字符是 "r" 或 "ur" 的情况。
另一个示例是,如果你想匹配 "gray" 或 "grey",你可以使用正则表达式 gr(e|a)y。
字符分支在正则表达式中非常有用,因为它允许你灵活地匹配多个可能的模式,而不必编写多个不同的正则表达式。请注意,字符分支可以嵌套,以构建更复杂的匹配模式。
4.1.7 字符分组
正则表达式的字符数组(Character Classes)是一种用于匹配特定字符集合的机制。字符数组允许你指定一个字符范围或多个备选字符,以便在匹配文本时更加灵活和精确。在正则表达式中,字符数组使用方括号 [ ] 来表示。
以下是一些字符数组的示例和解释:
| 示例 | 解释 |
[aeiou] | 这个字符数组匹配任何一个元音字母(a、e、i、o 或 u) |
[0-9] | 这个字符数组匹配任何一个数字字符 |
[A-Za-z] | 这个字符数组匹配任何一个大写或小写字母 |
[a-zA-Z0-9] | 这个字符数组匹配任何一个大写或小写字母,或数字字符 |
[abc] | 这个字符数组匹配字符 "a"、"b" 或 "c" 中的任何一个 |
[^0-9] | 在字符数组的开头加上 ^ 符号,表示否定匹配,这个示例将匹配任何一个非数字字符 |
在字符数组内部,你可以使用连字符 - 来表示一个范围。例如,[a-z] 表示从小写字母 "a" 到 "z" 的范围,包括这两个字母在内的所有小写字母。
需要注意的是,在字符数组中,大多数正则表达式的特殊字符失去了它们的特殊含义。例如,点号 . 在字符数组内只表示普通的点号,不再表示匹配任意字符的通配符。
示例用法:
- 正则表达式
gr[ae]y可以匹配 "gray" 或 "grey"。 - 正则表达式
[0-9]+可以匹配一个或多个连续的数字字符。
4.1.8 贪婪匹配和懒惰匹配
贪婪匹配指的是正则表达式会尽可能多地匹配输入文本。例如,如果使用表达式 a+ 来匹配输入 "aaa",贪婪匹配将匹配整个 "aaa",因为它会尽可能多地匹配连续的 "a"。
懒惰匹配(也称为非贪婪匹配)则是指正则表达式会尽可能少地匹配输入文本。例如,如果使用表达式 a+? 来匹配输入 "aaa",懒惰匹配将只匹配一个 "a",因为它会寻求最短的匹配。
在正则表达式中,懒惰匹配通常使用 ? 来实现。例如,*? 表示懒惰匹配的零次或多次重复,+? 表示懒惰匹配的一次或多次重复,?? 表示懒惰匹配的零次或一次重复,等等。
示例用法:
- 贪婪匹配:表达式
a+会匹配 "aaa" 中的所有 "a"。 - 懒惰匹配:表达式
a+?只会匹配 "aaa" 中的第一个 "a"。
| 代码 | 说明 |
| .* | 贪婪匹配 |
| .*? | 惰性匹配 |
4.2 Python使用正则表达式
在Python中,re(正则表达式)模块是用于处理正则表达式的官方模块。它提供了一组功能,使得在Python中使用正则表达式变得简单和灵活。
4.2.1 导入正则表达式模块
import re4.2.2 常用re模块函数
导入re模块后,就可以使用其内部函数了,常用的函数如下:
1.re.search(pattern, string): 在整个字符串中搜索匹配正则表达式pattern的第一个位置,并返回一个match对象。如果找不到匹配,则返回None。
import re
# # search, 找到一个结果就返回, 返回的结果是match对象. 拿数据需要.group()
s = re.search(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
print(s.group()) #输出10086
2.re.match(pattern, string): 从字符串的开头开始匹配正则表达式pattern,如果从开头就没有匹配,则返回None。
import re
# # match是从头开始匹配
s = re.match(r"\d+", "10086, 我女朋友的电话是:10010")
print(s.group()) #输出10086
3.re.findall(pattern, string): 在字符串中找到所有匹配正则表达式pattern的非重叠出现,并返回一个列表。
import re
# # findall: 匹配字符串中所有的符合正则的内容
lst = re.findall(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
print(lst) #输出['10086', '10010'] 4.re.finditer(pattern, string): 返回一个迭代器,该迭代器生成所有匹配正则表达式pattern的match对象。
import re
# # finditer: 匹配字符串中所有的内容[返回的是迭代器], 从迭代器中拿到内容需要.group()
it = re.finditer(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
for i in it:
print(i.group())#输出10086
# 10010 5.re.compile(pattern): 将正则表达式pattern编译为一个正则表达式对象,以便在后续操作中重复使用。
import re
# # 预加载正则表达式
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话号是:10086, 我女朋友的电话是:10010")
for it in ret:
print(it.group()) #输出10086
# 10010
(?P<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
import re
s = """
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思哲</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
"""
# (?P<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
obj = re.compile(r"<div class='.*?'><span id='(?P<id>\d+)'>(?P<wahaha>.*?)</span></div>", re.S) # re.S: 让.能匹配换行符
result = obj.finditer(s)
for it in result:
print(it.group("wahaha"))
print(it.group("id"))
#输出:
#郭麒麟
#1
#宋铁
#2
#大聪明
#3
#范思哲
#4
#胡说八道
#5
6.re.sub(pattern, repl, string): 将字符串中所有匹配正则表达式pattern的部分替换为repl。
7.re.split(pattern, string): 使用正则表达式pattern将字符串分割,并返回分割后的列表。
五.Beautifulsoup
Beautifulsoup同样可以解析HTML或XML格式的文档。这些文档由标签、属性和内容组成,它们描述了网页的结构和信息。
Beautiful Soup库可以帮助我们解析和处理这些文档。它将HTML或XML文档转换为一个树形结构,也就是一个层次化的对象结构。这个树形结构使得我们可以通过各种方法和属性来遍历、搜索和修改文档。
5.1 Beautiful Soup安装
5.1.1 软件包管理安装
如果你用的是新版的Debain或ubuntu,那么可以通过系统的软件包管理来安装。
$ apt-get install Python-bs4
5.1.2 pip或easy_install命令安装
Beautiful Soup 4 通过PyPi发布,可以通过 easy_install 或 pip命令进行安装。包的名称是beautifulsoup4 。
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
注意:(在PyPi中还有一个名字是 BeautifulSoup 的包,那是 Beautiful Soup3 的发布版本,因为很多项目还在使用BS3, 所以 BeautifulSoup 包依然有效,如果现在开发新的项目,还是下载beautifulsoup4 的包 )
5.1.3 安装包安装
可以通过下载BS4的源码 ,然后通过setup.py来安装.
$ Python setup.py install
5.2 解析器安装
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml ,另一个是html5lib。
5.2.1 lxml解析器安装
根据操作系统不同,可以选择下列方法来安装lxml。
$ apt-get install Python-lxml
$ easy_install lxml
$ pip install lxml
5.2.2 html5lib8解析器安装
html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib。
$ apt-get install Python-html5lib
$ easy_install html5lib
$ pip install html5lib
5.2.3 主要解析器分析
| 解析器 | 使用方法 | 优势 | 劣势 |
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库 执行速度适中 文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快 文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”]) BeautifulSoup(markup, “xml”) | 速度快 唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性 以浏览器的方式解析文档 生成HTML5格式的文档 | 速度慢 不依 |
5.3 Beautiful Soup使用
5.3.1 创建Beautiful Soup对象
首先导入bs4、lxml、request包
#encoding:UTF-8
from bs4 import BeautifulSoup
import lxml
import requestsHTML文档示例:
html_doc = """
<html>
<head>
<title>Beautiful Soup示例</title>
</head>
<body>
<div class="container">
<h1>欢迎使用Beautiful Soup!</h1>
<p class="message">这是一个示例页面。</p>
<ul>
<li>列表项1</li>
<li>列表项2</li>
<li>列表项3</li>
</ul>
</div>
</body>
</html>
"""
创建beautiful soup对象
方式一:在程序中有html格式的字符串,可在程序中进行创建对象。
soup = BeautifulSoup(html_doc,'lxml') #创建 beautifulsoup 对象方式二:可用本地文件创建对象。
soup = BeautifulSoup(open('index.html')) #用本地 HTML 文件来创建对象方法三:利用python内置模块进行创建对象。
soup = BeautifulSoup(html_doc, 'html.parser')5.3.2 对象的种类
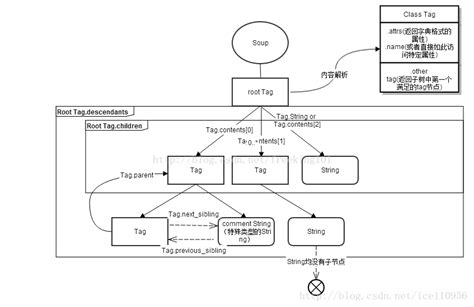
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment 。
5.3.2.1 tag
Tag 对象与XML或HTML原生文档中的tag相同:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>Tag有很多方法和属性,在 遍历文档树 和 搜索文档树 中有详细解释.现在介绍一下tag中最重要的属性: name和attributes
name属性:
每个tag都有自己的名字,通过 .name 来获取:
tag.name
# u'b'如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档:
tag.name = "blockquote"
tag
# <blockquote class="boldest">Extremely bold</blockquote>attributes属性:
一个tag可能有很多个属性. tag <b class="boldest"> 有一个 “class” 的属性,值为 “boldest” . tag的属性的操作方法与字典相同:
tag['class']
# u'boldest'也可以直接”点”取属性, 比如: .attrs :
tag.attrs
# {u'class': u'boldest'}tag的属性可以被添加,删除或修改. 再说一次, tag的属性操作方法与字典一样
tag['class'] = 'verybold'
tag['id'] = 1
tag
# <blockquote class="verybold" id="1">Extremely bold</blockquote>
del tag['class']
del tag['id']
tag
# <blockquote>Extremely bold</blockquote>
tag['class']
# KeyError: 'class'
print(tag.get('class'))
# None5.3.2.2 NavigableString
获得了标签可用xx.string方法来获取标签内的字符串,得到的类型是NavigableString类型。
tag.string
# u'Extremely bold'
type(tag.string)
# <class 'bs4.element.NavigableString'>一个 NavigableString 字符串与Python中的Unicode字符串相同,并且还支持包含在 遍历文档树 和 搜索文档树 中的一些特性. 通过 unicode() 方法可以直接将 NavigableString 对象转换成Unicode字符串:
unicode_string = unicode(tag.string)
unicode_string
# u'Extremely bold'
type(unicode_string)
# <type 'unicode'>tag中包含的字符串不能编辑,但是可以被替换成其它的字符串,用 replace_with() 方法:
tag.string.replace_with("No longer bold")
tag
# <blockquote>No longer bold</blockquote>NavigableString 对象支持 遍历文档树 和 搜索文档树 中定义的大部分属性, 并非全部.尤其是,一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法.
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址.这样会浪费内存.
5.3.2.3 BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
因为 BeautifulSoup 对象并不是真正的HTML或XML的tag,所以它没有name和attribute属性.但有时查看它的 .name 属性是很方便的,所以 BeautifulSoup 对象包含了一个值为 “[document]” 的特殊属性 .name
soup.name
# u'[document]'5.3.2.4 Comment
Tag , NavigableString , BeautifulSoup 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象.容易让人担心的内容是文档的注释部分:
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
type(comment)
# <class 'bs4.element.Comment'>Comment 对象是一个特殊类型的 NavigableString 对象:
comment
# u'Hey, buddy. Want to buy a used parser'但是当它出现在HTML文档中时, Comment 对象会使用特殊的格式输出:
print(soup.b.prettify())
# <b>
# <!--Hey, buddy. Want to buy a used parser?-->
# </b>5.3.3 搜索文档树
5.3.3.1 find_all()
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件.这里有几个例子:
soup.find_all("title")
# [<title>The Dormouse's story</title>]
soup.find_all("p", "title")
# [<p class="title"><b>The Dormouse's story</b></p>]
soup.find_all("a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find_all(id="link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
import re
soup.find(text=re.compile("sisters"))
# u'Once upon a time there were three little sisters; and their names were\n'有几个方法很相似,还有几个方法是新的,参数中的 text 和 id 是什么含义? 为什么 find_all("p", "title") 返回的是CSS Class为”title”的<p>标签? 我们来仔细看一下 find_all() 的参数
- name参数
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉.
简单的用法如下:
soup.find_all("title")
# [<title>The Dormouse's story</title>]重申: 搜索 name 参数的值可以使任一类型的 过滤器 ,字符窜,正则表达式,列表,方法或是 True .
- keyword参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性.
soup.find_all(id='link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]如果传入 href 参数,Beautiful Soup会搜索每个tag的”href”属性:
soup.find_all(href=re.compile("elsie"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
下面的例子在文档树中查找所有包含 id 属性的tag,无论 id 的值是什么:
soup.find_all(id=True)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]使用多个指定名字的参数可以同时过滤tag的多个属性:
soup.find_all(href=re.compile("elsie"), id='link1')
# [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')
data_soup.find_all(data-foo="value")
# SyntaxError: keyword can't be an expression但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
data_soup.find_all(attrs={"data-foo": "value"})
# [<div data-foo="value">foo!</div>]- 按CSS搜索
按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字 class 在Python中是保留字,使用 class 做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过 class_ 参数搜索有指定CSS类名的tag:
soup.find_all("a", class_="sister")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]class_ 参数同样接受不同类型的 过滤器 ,字符串,正则表达式,方法或 True :
soup.find_all(class_=re.compile("itl"))
# [<p class="title"><b>The Dormouse's story</b></p>]
def has_six_characters(css_class):
return css_class is not None and len(css_class) == 6
soup.find_all(class_=has_six_characters)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]tag的 class 属性是 多值属性 .按照CSS类名搜索tag时,可以分别搜索tag中的每个CSS类名:
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
css_soup.find_all("p", class_="strikeout")
# [<p class="body strikeout"></p>]
css_soup.find_all("p", class_="body")
# [<p class="body strikeout"></p>]搜索 class 属性时也可以通过CSS值完全匹配:
css_soup.find_all("p", class_="body strikeout")
# [<p class="body strikeout"></p>]完全匹配 class 的值时,如果CSS类名的顺序与实际不符,将搜索不到结果:
soup.find_all("a", attrs={"class": "sister"})
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]- text参数
通过 text 参数可以搜搜文档中的字符串内容.与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True . 看例子:
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
[u"The Dormouse's story", u"The Dormouse's story"]
def is_the_only_string_within_a_tag(s):
""Return True if this string is the only child of its parent tag.""
return (s == s.parent.string)
soup.find_all(text=is_the_only_string_within_a_tag)
# [u"The Dormouse's story", u"The Dormouse's story", u'Elsie', u'Lacie', u'Tillie', u'...']虽然 text 参数用于搜索字符串,还可以与其它参数混合使用来过滤tag.Beautiful Soup会找到 .string 方法与 text 参数值相符的tag.下面代码用来搜索内容里面包含“Elsie”的<a>标签:
soup.find_all("a", text="Elsie")
# [<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>]- limit参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果.
文档树中有3个tag符合搜索条件,但结果只返回了2个,因为我们限制了返回数量:
soup.find_all("a", limit=2)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]- recursive 参数
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
一段简单的文档:
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
...是否使用 recursive 参数的搜索结果:
soup.html.find_all("title")
# [<title>The Dormouse's story</title>]
soup.html.find_all("title", recursive=False)
# []像调用 find_all() 一样调用tag
find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的:
soup.find_all("a")
soup("a")这两行代码也是等价的:
soup.title.find_all(text=True)
soup.title(text=True)5.3.3.2 find
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的:
soup.find_all('title', limit=1)
# [<title>The Dormouse's story</title>]
soup.find('title')
# <title>The Dormouse's story</title>唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果.
find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
print(soup.find("nosuchtag"))
# Nonesoup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>5.3.3.3 find_parents() 和 find_parent()
我们已经用了很大篇幅来介绍 find_all() 和 find() 方法,Beautiful Soup中还有10个用于搜索的API.它们中的五个用的是与 find_all() 相同的搜索参数,另外5个与 find() 方法的搜索参数类似.区别仅是它们搜索文档的不同部分.
记住: find_all() 和 find() 只搜索当前节点的所有子节点,子孙节点等. find_parents() 和 find_parent() 用来搜索当前节点的父辈节点,搜索方法与普通tag的搜索方法相同,搜索文档搜索文档包含的内容. 我们从一个文档中的一个叶子节点开始:
a_string = soup.find(text="Lacie")
a_string
# u'Lacie'
a_string.find_parents("a")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
a_string.find_parent("p")
# <p class="story">Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
# and they lived at the bottom of a well.</p>
a_string.find_parents("p", class_="title")
# []文档中的一个<a>标签是是当前叶子节点的直接父节点,所以可以被找到.还有一个<p>标签,是目标叶子节点的间接父辈节点,所以也可以被找到.包含class值为”title”的<p>标签不是不是目标叶子节点的父辈节点,所以通过 find_parents() 方法搜索不到.
find_parent() 和 find_parents() 方法会让人联想到 .parent 和 .parents 属性.它们之间的联系非常紧密.搜索父辈节点的方法实际上就是对 .parents 属性的迭代搜索.
5.3.3.4 find_next_siblings() 和 find_next_sibling()
find_next_siblings( name , attrs , recursive , text , **kwargs )
find_next_sibling( name , attrs , recursive , text , **kwargs )
这2个方法通过 .next_siblings 属性对当tag的所有后面解析 [5] 的兄弟tag节点进行迭代, find_next_siblings() 方法返回所有符合条件的后面的兄弟节点, find_next_sibling() 只返回符合条件的后面的第一个tag节点.
first_link = soup.a
first_link
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
first_link.find_next_siblings("a")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
first_story_paragraph = soup.find("p", "story")
first_story_paragraph.find_next_sibling("p")
# <p class="story">...</p>5.3.3.5 find_previous_siblings() 和 find_previous_sibling()
find_previous_siblings( name , attrs , recursive , text , **kwargs )
find_previous_sibling( name , attrs , recursive , text , **kwargs )
这2个方法通过 .previous_siblings 属性对当前tag的前面解析 [5] 的兄弟tag节点进行迭代, find_previous_siblings() 方法返回所有符合条件的前面的兄弟节点, find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点:
last_link = soup.find("a", id="link3")
last_link
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
last_link.find_previous_siblings("a")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
first_story_paragraph = soup.find("p", "story")
first_story_paragraph.find_previous_sibling("p")
# <p class="title"><b>The Dormouse's story</b></p>5.3.3.6 find_all_next() 和 find_next()
这2个方法通过 .next_elements 属性对当前tag的之后的 [5] tag和字符串进行迭代, find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点:
first_link = soup.a
first_link
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
first_link.find_all_next(text=True)
# [u'Elsie', u',\n', u'Lacie', u' and\n', u'Tillie',
# u';\nand they lived at the bottom of a well.', u'\n\n', u'...', u'\n']
first_link.find_next("p")
# <p class="story">...</p>第一个例子中,字符串 “Elsie”也被显示出来,尽管它被包含在我们开始查找的<a>标签的里面.第二个例子中,最后一个<p>标签也被显示出来,尽管它与我们开始查找位置的<a>标签不属于同一部分.例子中,搜索的重点是要匹配过滤器的条件,并且在文档中出现的顺序而不是开始查找的元素的位置.
5.3.3.7 find_all_previous() 和 find_previous()
find_all_previous( name , attrs , recursive , text , **kwargs )
这2个方法通过 .previous_elements 属性对当前节点前面 [5] 的tag和字符串进行迭代, find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点.
first_link = soup.a
first_link
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
first_link.find_all_previous("p")
# [<p class="story">Once upon a time there were three little sisters; ...</p>,
# <p class="title"><b>The Dormouse's story</b></p>]
first_link.find_previous("title")
# <title>The Dormouse's story</title>find_all_previous("p") 返回了文档中的第一段(class=”title”的那段),但还返回了第二段,<p>标签包含了我们开始查找的<a>标签.不要惊讶,这段代码的功能是查找所有出现在指定<a>标签之前的<p>标签,因为这个<p>标签包含了开始的<a>标签,所以<p>标签一定是在<a>之前出现的.
六.Xpath
XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的查询语言。它是一种非常强大的工具,用于在XML文档中进行导航和提取信息。XPath可以用于在XML文档中选择节点、属性和文本,以及根据特定的条件进行过滤和定位。
XPath使用一种路径表达式来描述节点的位置,类似于文件系统中的路径。路径表达式可以从根节点开始,通过节点名称、属性、层级关系等来定位目标节点。XPath还支持使用逻辑运算符、比较运算符和函数来创建更复杂的查询。
6.1 XPath解析原理
- 实现标签的定位:实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
- 调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
6.2 实例化etree的对象
要在Python中实例化一个etree对象,通常需要使用第三方库,如lxml。lxml是一个功能强大且高性能的XML和HTML处理库,它提供了etree模块来操作和处理XML文档。以下是在Python中实例化一个etree对象的步骤:
-
安装lxml库:
首先,你需要确保已经安装了lxml库。你可以使用以下命令通过pip安装它:pip install lxml -
导入模块:
在Python代码中,你需要导入etree模块:from lxml import etree -
实例化etree对象
分为两种方式去实例化etree对象,一种是通过文件路径去找到html文件去实例化,另一种是通过源码数据去实例化。
- 将本地的html文档中的源码数据加载到etree对象中:
etree. parse(filePath)#你的文件路径
- 可以将从互联网上获取的源码数据加载到该对象中
etree.HtML('page_ text')#page_ text互联网中响应的数据6.3 节点
6.3.1 父节点
在XPath中,父节点(Parent Node)指的是一个元素节点的直接包含它的上层元素节点。换句话说,父节点是包含当前节点的那个元素节点。在XML文档的层级结构中,每个元素节点都可以有一个父节点,除了根节点(顶层节点),它没有父节点。
使用之前的XML片段作为例子:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book>
<title>The Hobbit</title>
<author>J.R.R. Tolkien</author>
</book>
</bookstore>
在这个示例中:
<book>元素节点的父节点是<bookstore>元素节点。<title>和<author>元素节点的父节点是各自的<book>元素节点。<bookstore>元素节点没有父节点,因为它是根节点。
在XPath中,如果要选择某个元素节点的父节点,可以使用 parent:: 轴,例如 /bookstore/book/title/parent::book 会选择 <title> 元素节点的父节点 <book> 元素节点。
XPath中的父节点是指直接包含当前节点的元素节点,而子节点是指直接嵌套在当前节点内部的其他元素节点。
6.3.2 子节点
在XPath中,子节点(Child Nodes)指的是一个元素节点下直接嵌套的其他元素节点。换句话说,子节点是位于父节点内部的那些元素节点。在XML文档的层级结构中,一个元素节点可以包含多个子节点,这些子节点可以是其他元素节点、文本节点、注释节点等。
例如,考虑以下XML片段:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book>
<title>The Hobbit</title>
<author>J.R.R. Tolkien</author>
</book>
</bookstore>
在这个示例中,<bookstore> 元素节点有两个子节点 <book>。每个 <book> 元素节点又有两个子节点 <title> 和 <author>。因此,在这个上下文中,<book> 元素节点就是 <bookstore> 元素节点的子节点,而 <title> 和 <author> 元素节点是 <book> 元素节点的子节点。
在XPath中,如果要选择某个元素节点的所有子节点,可以使用 child:: 轴,例如 /bookstore/child::book 会选择 <bookstore> 元素节点的所有子节点中的 <book> 元素节点。
6.3.3 兄弟节点
在XPath中,兄弟节点(Sibling Nodes)指的是与当前元素节点处于同一层级的其他元素节点。换句话说,兄弟节点是与当前节点在同一个父节点下的其他元素节点。在XML文档的层级结构中,如果两个元素节点具有相同的父节点,则它们被认为是兄弟节点。
使用之前的XML片段作为例子:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book>
<title>The Hobbit</title>
<author>J.R.R. Tolkien</author>
</book>
</bookstore>
在这个示例中:
<book>元素节点之间互为兄弟节点,因为它们都是<bookstore>元素节点的子节点。<title>元素节点和<author>元素节点也互为兄弟节点,因为它们都是同一个<book>元素节点的子节点。
在XPath中,如果要选择当前元素节点的兄弟节点,可以使用 following-sibling:: 轴或 preceding-sibling:: 轴。例如,假设我们想选择第一个 <book> 元素节点的兄弟节点(第二个 <book> 元素节点),可以使用 /bookstore/book[1]/following-sibling::book[1]。
在XPath中,兄弟节点是指与当前元素节点在同一父节点下的其他元素节点。
6.4 XPath的规则
6.4.1 选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
示例:
| 路径表达式 | 结果 |
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
6.4.2 谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
示例 :
| 路径表达式 | 解释 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
6.4.3 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
示例 :
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
6.4.4 选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
示例:
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
七.异步爬虫

7.1 多线程
def func():
for i in range(1000):
print("func", i)
if __name__ == '__main__':
func()
for i in range(1000):
print("main", i)运行结果:

from threading import Thread
def func():
for i in range(1000):
print("func", i)
if __name__ == '__main__':
t = Thread(target=func)
t.start()
for i in range(1000):
print("main", i)运行结果:
7.2 多进程
多进程爬虫可以提高爬取网页数据的效率,特别是在面对大量链接或需要处理耗时的请求时。在Python中,可以使用多进程库(如`multiprocessing`)结合爬虫框架(如`requests`和`BeautifulSoup`)来实现多进程爬虫。
多进程示例:
from multiprocessing import Process
def func():
for i in range(1000):
print("func", i)
if __name__ == '__main__':
p = Process(target=func)
p.start()
for i in range(1000):
print("main", i)7.3 协程
import time
def func():
print("我爱黎明")
time.sleep(3)
print("我真的爱黎明")
func()
import time
# await: 当该任务被挂起后,CPU会⾃动切换到其他任务中
async def func1():
print("func1, start")
await asyncio.sleep(3)
print("func1, end")
async def func2():
print("func2, start")
await asyncio.sleep(4)
print("func2, end")
async def func3():
print("func3, start")
await asyncio.sleep(2)
if __name__ == '__main__':
start = time.time()
tasks = [ # 协程任务列表
func1(), # 创建协程任务
func2(),
func3()
]
lop = asyncio.get_event_loop()
# 我要执⾏这个协程任务列表中的所有任务
lop.run_until_complete(asyncio.wait(tasks))
# 我要执⾏这个协程任务列表中的所有任务
print(time.time() - start)
7.3.1 aiohttp多任务异步协程
aiohttp是python的⼀个⾮常优秀的第三⽅异步http请求库. 我们可以⽤aiohttp来编写异步爬⾍(协程)。
1 pip install aiohttp实例代码
import aiohttp
import asyncio
import time
import requests
# 异步下载
async def aiodownload(url, session):
name = url.split("/")[-1]
# 发送请求, 这⾥和requests.get()⼏乎没区别, 除了代
理换成了proxy
async with session.get(url) as resp:
# 读取数据. 如果想要读取源代码. 直接
resp.text()即可. ⽐原来多了个()
content = await resp.content.read()
# 写⼊⽂件, 有兴趣可以参考aiofiles, 我这⾥根本
不需要.
with open(name, mode="wb") as f:
f.write(content)
async def main():
# 创建session对象 -> 相当于requsts对象
async with aiohttp.ClientSession() as
session:
# 添加下载任务
tasks =
[asyncio.create_task(aiodownload(url, session))
for url in urls]
# 等待所有任务下载完成
await asyncio.wait(tasks)
# 同步⽅式下载图⽚
def download(url):29 name = url.split("/")[-1]
resp = requests.get(url)
content = resp.content
with open(name, mode="wb") as f:
f.write(content)八.selenium
Selenium 是一种自动化测试工具和框架,用于模拟用户在 Web 浏览器中的行为。它提供了一组用于控制浏览器、操作网页元素和执行测试脚本的 API。Selenium 可以与各种编程语言(如Python、Java、C# 等)结合使用,使开发人员能够自动化测试网页应用程序的功能和交互。
Selenium 具有以下主要特点:
-
浏览器兼容性:Selenium 支持多种浏览器,包括 Chrome、Firefox、Safari、Edge 等,可在不同的浏览器上进行测试,确保应用程序在各种环境中的兼容性。
-
元素定位:Selenium 提供了丰富的方法来定位和操作网页元素,可以通过 ID、类名、XPath、CSS 选择器等方式快速准确地定位到要操作的元素。
-
模拟用户行为:Selenium 可以模拟用户在浏览器中的各种操作,如点击、输入文本、提交表单、拖拽等,以及处理 JavaScript 弹窗、切换窗口、处理框架等操作。
-
多平台支持:Selenium 可以在不同的操作系统上运行,包括 Windows、Mac 和 Linux 等。
-
集成框架:Selenium 可以与各种测试框架(如JUnit、TestNG)和持续集成工具(如Jenkins)结合使用,实现自动化测试的流程和报告生成。
Selenium 提供了多种编程语言的客户端库,开发人员可以根据自己的偏好和需求选择最适合的语言进行测试脚本开发。通过使用 Selenium,开发人员可以自动执行各种测试任务,包括功能测试、回归测试、性能测试等,提高测试效率和准确性。
8.1 搭建环境
8.1.1 selenium安装
打开 cmd,输入下面命令进行安装。
pip install -i https://pypi.douban.com/simple selenium
8.1.2 浏览器驱动安装
针对不同的浏览器,需要安装不同的驱动。
注意:安装的驱动版本应该与本电脑浏览器版本相对应。
这里以chrome浏览器进行举例
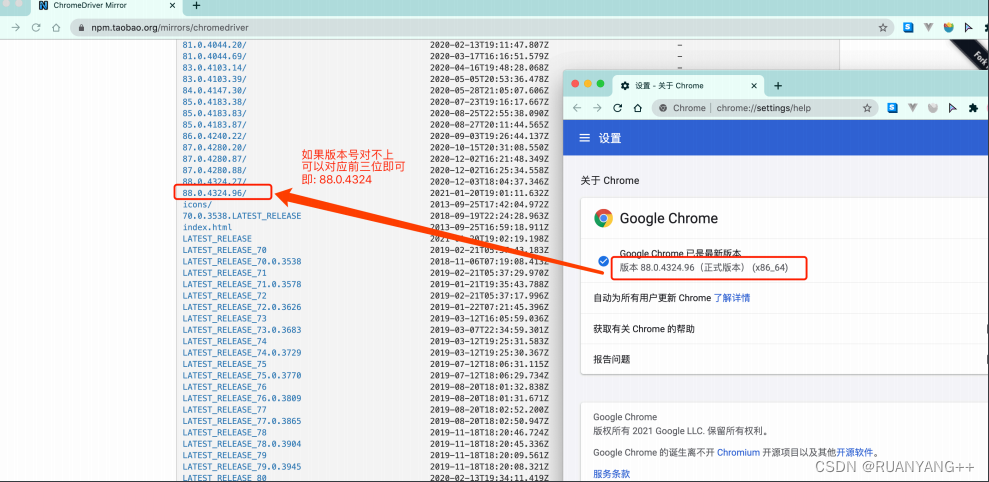

根据你电脑的不同⾃⾏选择. win64选win32即可.
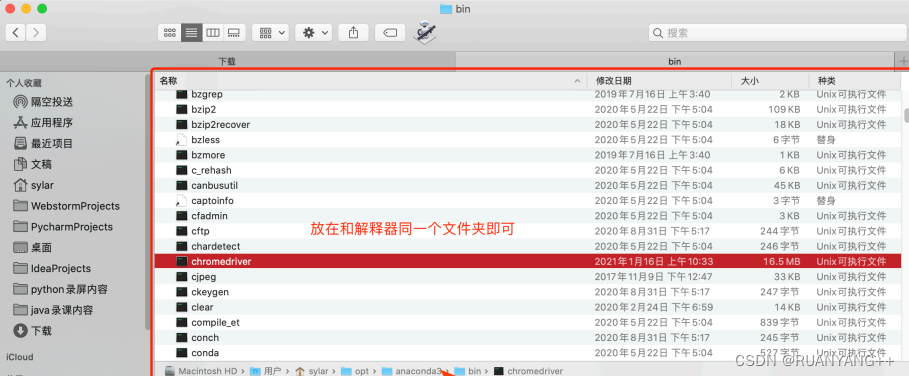
然后关键的来了. 把你下载的浏览器驱动放在程序所在的⽂件夹。或者放到python解释器所在的⽂件夹.。两种⼆选其⼀。

或者
8.2 selenium 使用
基本使用
from selenium.webdriver import Chrome # 导⼊⾕歌浏
览器的类
# 创建浏览器对象
drive= Chrome(executable_path="chromedriver") # 如果你的浏览器驱动放在了项⽬⾥.
# drive= Chrome() # 如果你的浏览器驱动放在了解释器⽂件夹
drive.get("http://www.baidu.com") # 输⼊⽹址
print(web.title) # 打印title8.2.1 元素定位
在 Selenium 中,我们可以使用多种方式进行元素定位,以便在自动化测试中找到和操作特定的网页元素。以下是几种常用的元素定位方法:
1.通过 ID 定位元素:
element = driver.find_element_by_id("element_id")2.通过 class 名称定位元素:
element = driver.find_element_by_class_name("class_name")3.通过标签名称定位元素:
element = driver.find_element_by_tag_name("tag_name")4.通过链接文本定位元素(用于定位链接):
element = driver.find_element_by_link_text("link_text")5.通过部分链接文本定位元素(用于定位链接):
element = driver.find_element_by_partial_link_text("partial_link_text")6.通过 CSS 选择器定位元素:
element = driver.find_element_by_css_selector("css_selector")7.通过 XPath 定位元素:
element = driver.find_element_by_xpath("xpath_expression") 以上代码示例中,driver 是 WebDriver 对象,用于控制浏览器。find_element_by_XXX() 方法用于定位单个元素,如果需要定位多个元素,可以使用 find_elements_by_XXX() 方法,并返回一个元素列表。
另外,还有一些辅助方法可以与上述定位方法组合使用,例如:
find_element()和find_elements():接受两个参数,第一个参数为定位方法,第二个参数为定位值。find_element_by_*()和find_elements_by_*():一些特殊的定位方式,例如find_element_by_name(),find_elements_by_xpath()等。
根据页面结构和元素属性的不同,选择合适的定位方法进行元素定位。如果出现多个匹配的元素,可以使用索引或其他属性进一步缩小范围,确保找到正确的元素。
8.2.2 元素操作
.send_keys() # 输入方法
.click() # 点击方法
.clear() # 清空方法
8.2.3 浏览器操作方法
driver.maximize_window() # 最大化浏览器
driver.set_window_size(w,h) # 设置浏览器大小 单位像素 【了解】
driver.set_window_position(x,y) # 设置浏览器位置 【了解】
driver.back() # 后退操作
driver.forward() # 前进操作
driver.refrensh() # 刷新操作
driver.close() # 关闭当前主窗口(主窗口:默认启动那个界面,就是主窗口)
driver.quit() # 关闭driver对象启动的全部页面
driver.title # 获取当前页面title信息
driver.current_url # 获取当前页面url信息
8.2.4 获取元素信息操作
text 获取元素的文本; 如:driver.text
size 获取元素的大小: 如:driver.size
get_attribute 获取元素属性值;如:driver.get_attribute("id") ,传递的参数是元素的属性名
is_displayed 判断元素是否可见 如:element.is_displayed()
is_enabled 判断元素是否可用 如:element.is_enabled()
is_selected 判断元素是否被选中 如:element.is_selected()
8.2.5 鼠标操作
导包:
from selenium.webdriver.common.action_chains import ActionChains
鼠标的常用事件:
context_click(element) # 右击
double_click(element) #双击
double_and_drop(source, target) # 拖拽
move_to_element(element) # 悬停 【重点】
perform() # 执行以上事件的方法 【重点】8.2.5.1 鼠标右键及双击
#鼠标操作:
context_click() 右键
double_click() 鼠标双击
8.2.5.2 鼠标拖拽
# 鼠标拖拽
action.drag_and_drop(source, target)
8.2.5.3 鼠标悬停
# 鼠标悬停 【重点】
action.move_to_element(element)
8.2.6 键盘操作
导包:
from selenium.webdriver.common.keys import Keys
# 单键
element.send_keys(Keys.XXX)
# 组合键
element.send_keys(Keys.XXX, 'a') # 注意这里的组合键都是小写8.2.7 窗口切换
driver.current_window_handle (获取当前的句柄值)
driver.window_handles ( 获取当前由driver启动所有窗口句柄)
driver.switch_to.window(handle) —> 切换窗口
8.2.8 截图操作
在 Selenium 中,你可以使用 screenshot() 方法对网页进行截图操作。以下是一些常见的截图操作示例:
1.对整个网页进行截图:
driver.save_screenshot("screenshot.png")2.对指定元素进行截图:
element = driver.find_element_by_id("element_id") element.screenshot("element_screenshot.png")3.对指定区域进行截图:
element = driver.find_element_by_id("element_id") location = element.location size = element.size driver.save_screenshot("screenshot.png") left = location['x'] top = location['y'] right = location['x'] + size['width'] bottom = location['y'] + size['height'] image = Image.open("screenshot.png") image = image.crop((left, top, right, bottom)) image.save("element_screenshot.png")在第三个示例中,我们首先对整个网页进行了截图,然后使用元素的位置和大小信息,通过裁剪整个截图来获取指定元素的截图。
需要注意的是,为了进行截图操作,你需要确保你的环境中安装了 Pillow 或者其他图像处理库,例如 opencv-python。
截图操作可以帮助你在自动化测试过程中进行调试和验证,也可以用于生成测试报告或记录页面的状态。根据实际需求,你可以选择合适的截图操作方式。
8.3 超级鹰搞定验证码
8.3.1 简介
超级鹰是一个基于人工智能的验证码识别平台。它可以帮助用户自动破解网站上的验证码,以应对需要进行验证码验证的场景。超级鹰主要用于爬虫开发、自动化测试和数据采集等领域。
使用超级鹰进行验证码识别的流程通常如下:
- 用户将需要识别的验证码图片上传到超级鹰服务器。
- 超级鹰的人工智能算法会对验证码图片进行分析和处理。
- 超级鹰返回识别结果给用户,通常是验证码的文本或数字。
- 用户可以将返回的识别结果用于后续的自动化操作,例如自动填写验证码表单、进行爬虫访问等。
超级鹰支持识别多种类型的验证码,包括普通图片验证码、滑动验证码、点击验证码、语音验证码等。
使用超级鹰进行验证码识别时,要确保遵守相关的法律法规和网站的使用规定,不进行违法犯罪活动或侵犯他人隐私。此外,有些网站可能会采取反爬虫措施来阻止使用验证码识别技术的行为,因此在实际使用中需要谨慎并遵守相关规定。
8.3.2 使用
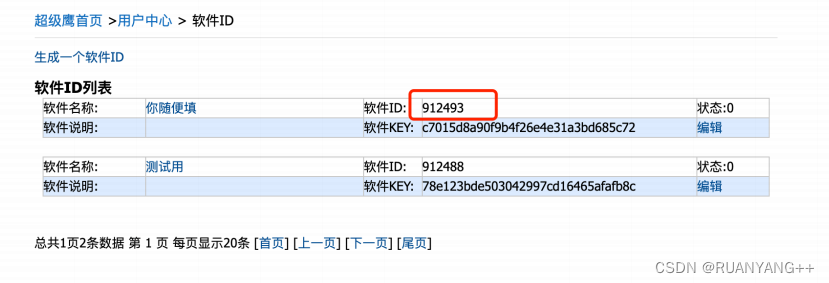
⾸先, 登录超级鹰的官⽹. 然后需要注册。注册后, 需要我们进⼊⽤户中⼼。 ⽣成⼀个新的软件ID就可以⽤了。

注意这个号, 后⾯会⽤到。
然后我们回到超级鹰的官⽹. 找到测试代码. 找到python的测试代码, 下载. 丢到pycharm⾥。

下载好的内容解压. 丢到pycharm中

进行测试

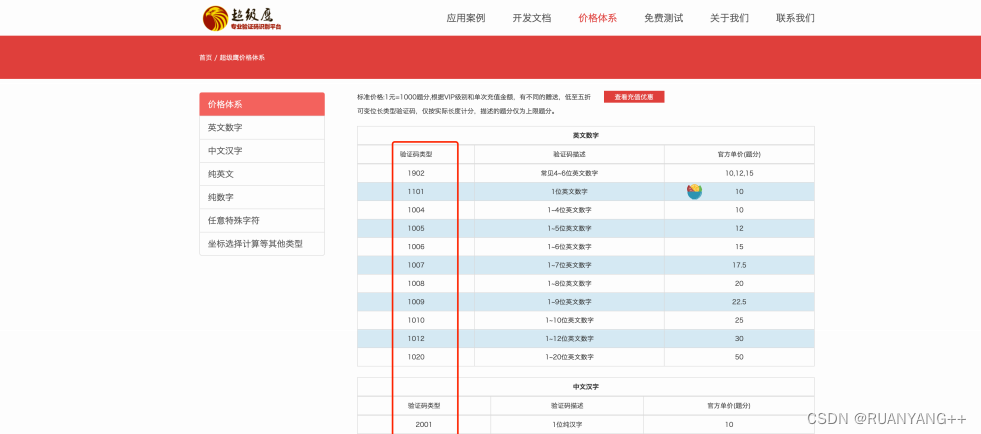
如果遇到的验证码⽐较特殊. 可以更换代码中的1902位置的参数值。具体情况可以参考官⽹上给出的参数列表。
九.scrapy
Scrapy 是一个用于爬取网站数据的开源Python框架。它提供了一套简单而强大的工具,使你能够定义爬取规则和处理爬取数据的流程,从而快速高效地实现数据采集任务。
Scrapy 的主要特点包括:
-
基于异步处理:Scrapy 是基于异步处理的框架,可以同时发送多个请求并处理响应,提高了爬取效率。
-
爬取规则定义:通过定义爬取规则,你可以指定要爬取的网页链接、提取数据的方式以及处理数据的方法。
-
可扩展性:Scrapy 提供了一系列的插件和扩展机制,你可以根据自己的需求添加功能或定制化操作。
-
数据流管理:Scrapy 使用管道(Pipeline)来处理爬取到的数据,可以对数据进行清洗、验证、存储等操作。
-
全面的特性支持:Scrapy 支持处理 cookies、代理、用户代理头、重试、延迟下载等常见的爬虫需求。
使用 Scrapy 进行网页爬取时,你需要编写爬虫程序,在程序中定义需要爬取的网页链接、提取数据的方式以及如何处理数据。Scrapy 提供了丰富的命令行工具和 API,使得编写和运行爬虫变得更加便捷。
9.1 Scrapy基本模块
9.1.1 调度器(Scheduler)
Scrapy 框架中的调度器(Scheduler)是负责管理待爬取的请求队列的组件。它接收起始请求(start_requests)或从 Spider 组件返回的新的请求,并按照一定的调度策略将这些请求添加到队列中,然后逐个发送给下载器进行处理。
调度器的主要功能包括:
-
接收起始请求:根据配置文件中的起始请求(start_urls)或 Spider 中定义的 start_requests() 方法,调度器接收并加入请求队列。
-
管理请求队列:调度器维护一个请求队列,使用合适的数据结构(如队列、栈、优先队列等)来管理请求。可以根据需求选择不同的请求队列数据结构。
-
选择下一个请求:根据设定的调度策略,调度器从请求队列中选择下一个待处理的请求,并将其发送给下载器。
-
过滤重复请求:调度器可以使用过滤器(dupefilter)来检测和过滤重复的请求,避免重复爬取相同的页面。
-
处理请求优先级:根据请求的优先级设置,调度器可以对请求队列进行排序,确保高优先级的请求优先处理。
-
动态调整请求队列:在运行过程中,Spider 可能会生成新的请求,调度器需要及时处理并添加到请求队列中。
Scrapy 提供了默认实现的调度器,默认使用优先级队列来管理请求队列,并使用布隆过滤器(Bloom Filter)进行请求去重。同时,Scrapy 也支持用户自定义调度器实现,可以根据需求选择合适的调度策略和数据结构。
通过调度器的灵活管理,Scrapy 框架能够高效地处理爬取流程,保证请求的有序发送和数据的正确处理。
9.1.2 下载器(Downloader)
Scrapy 框架的下载器(Downloader)是用来发送网络请求并接收响应的组件。它负责从调度器接收请求,并将请求发送到互联网上的服务器,然后接收服务器返回的响应数据。
下载器的主要功能包括:
-
发送请求:下载器根据接收到的请求,使用合适的网络库(如Requests、Twisted等)发送HTTP请求到指定的URL地址。
-
处理请求头部:下载器可以处理请求的头部信息,包括添加自定义的User-Agent、Cookies、Referer等,以便模拟不同的浏览器行为。
-
下载响应内容:一旦下载器发送请求并接收到服务器的响应,它会将响应内容以原始形式或经过解压、解密等处理后返回给引擎。
-
处理重定向:如果服务器返回了重定向响应(如HTTP 301、302等状态码),下载器会根据配置的重定向规则进行处理,可以自动跟随重定向或者根据需求自定义处理方式。
-
处理代理:在某些场景下,需要通过代理服务器发送请求,下载器可以支持配置代理服务器,实现匿名性和IP切换等功能。
-
设置超时和重试:下载器可以设置超时时间,当请求超过指定时间没有得到响应时,可以进行超时处理。同时,下载器还支持自定义的重试机制,以处理临时的网络错误或连接问题。
-
处理请求中间件:下载器可以与请求中间件(Downloader Middleware)协同工作,对请求进行预处理、加密、签名等操作,并在响应返回前进行后处理。
Scrapy 框架的下载器是一个可扩展的组件,用户可以根据需要自定义实现一些功能,并结合中间件进行更高级的请求处理和管理。下载器的灵活性和高效性使得 Scrapy 能够有效地处理大规模的爬取任务。
9.1.3 爬虫(Spider)
Scrapy的Spider是一个用于定义和控制爬取行为的核心组件。Spider负责从起始URL开始递归地爬取网页,并根据预定义的规则提取数据、跟踪链接、处理页面等操作。
Scrapy的Spider类是一个基础类,你可以创建自己的Spider类继承它,并在子类中编写具体的爬取逻辑。下面是创建Spider的一般步骤:
1. 创建一个新的Spider类:
在Scrapy项目的spiders目录下创建一个新的Python文件,比如`my_spider.py`。在这个文件中定义一个类,继承自scrapy.Spider类,并给它一个名字。
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider" 2. 设置Spider的属性:
在Spider类中,你需要设置一些属性来配置爬取行为。其中最重要的属性是`start_urls`,它是一个包含起始URL的列表,Spider将从这些URL开始爬取。
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = [
'http://www.example.com/page1',
'http://www.example.com/page2',
] 3. 编写解析方法:
在Spider类中,你需要编写一个或多个解析方法,用于处理每个页面的响应数据。解析方法的名称可以任意指定,但通常使用`parse`作为默认的解析方法。
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = [
'http://www.example.com/page1',
'http://www.example.com/page2',
]
def parse(self, response):
# 在这里编写解析响应的逻辑
pass 4. 解析数据和跟踪链接:
在解析方法中,你可以使用XPath或CSS选择器来提取页面中的数据,并通过yield语句生成Item对象或新的请求。
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = [
'http://www.example.com/page1',
'http://www.example.com/page2',
]
def parse(self, response):
# 提取数据
title = response.xpath('//h1/text()').get()
content = response.css('div.content::text').get()
# 生成Item对象
item = {
'title': title,
'content': content
}
yield item
# 跟踪链接并发送新的请求
for url in response.css('a::attr(href)').getall():
yield response.follow(url, self.parse) 5. 运行Spider:
在命令行中进入到Scrapy项目的根目录,然后执行`scrapy crawl spider_name`命令,其中`spider_name`是你之前给Spider起的名字。Scrapy将自动启动Spider,并开始抓取网页和处理数据。
以上是创建和运行Scrapy Spider的基本步骤,你可以根据具体需求编写更复杂的逻辑和规则,使用Scrapy提供的丰富功能来处理数据、控制爬取过程等。详细的Spider类属性和方法可以参考Scrapy官方文档。
9.1.4 实体管道(Item Pipeline)
在Scrapy中,实体管道(Item Pipeline)用于处理从Spider中获取的Item对象。实体管道负责对Item进行处理、清洗、持久化等操作,以及在需要时将Item发送到下一个管道。
下面是使用Scrapy实体管道的一般步骤:
1. 启用实体管道:
打开Scrapy项目的settings.py文件,并找到`ITEM_PIPELINES`配置项。将它设置为一个字典,其中键表示管道的优先级,值是管道的类路径。你可以定义多个管道,并按照优先级顺序执行。
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
'myproject.pipelines.AnotherPipeline': 400,
}
2. 编写管道类:
在Scrapy项目中创建一个pipelines.py文件,并编写一个继承自`scrapy.ItemPipeline`的类。在这个类中,你可以实现处理Item的各种方法,如`process_item()`等。
class MyPipeline:
def process_item(self, item, spider):
# 处理Item的逻辑
return item
3. 实现Item处理逻辑:
在`process_item()`方法中,你可以对Item进行各种处理,包括数据清洗、验证、转换等。你还可以将Item保存到数据库、写入文件、发送API请求等操作。
class MyPipeline:
def process_item(self, item, spider):
# 数据清洗
item['content'] = item['content'].strip()
# 保存到数据库
db.save(item)
return item
4. 执行多个管道操作:
如果你在settings.py中定义了多个管道,Scrapy会按照优先级顺序依次调用它们的`process_item()`方法。管道可以对Item进行连续的处理,每个管道可以修改Item并将其传递给下一个管道。
class MyPipeline1:
def process_item(self, item, spider):
# 管道1的处理逻辑
return item
class MyPipeline2:
def process_item(self, item, spider):
# 管道2的处理逻辑
return item 5. 配置其他设置:
除了管道优先级,你还可以在settings.py中配置其他参数,如并发数、延迟等。这些设置可以影响Scrapy爬取过程和实体管道的行为。
CONCURRENT_REQUESTS = 16
DOWNLOAD_DELAY = 0.5
以上是使用Scrapy实体管道的基本步骤,你可以根据实际需求编写自己的管道类,并在其中实现各种数据处理和持久化操作。请参考Scrapy官方文档以获取更详细的信息和进一步的指导。
9.1.5 Scrapy引擎(Scrapy Engine)
Scrapy的引擎(Engine)是Scrapy框架的核心组件之一,负责控制整个爬取流程的执行。引擎协调各个组件的工作,包括调度器(Scheduler)、下载器(Downloader)和Spider等,以及处理请求和响应数据的流转。
引擎的一般工作流程如下:
1. Spider生成初始请求:当引擎启动时,它会接收到一个或多个Spider对象,并从这些Spider对象中获取起始URL。然后,引擎将根据这些起始URL构造初始的请求对象,并将这些请求交给调度器。
2. 调度器调度请求:调度器接收到请求后,会根据调度算法决定当前要执行的请求,并将其发送给下载器。
3. 下载器下载页面:下载器接收到请求后,会根据请求的URL下载对应的页面,并将下载结果封装成响应对象。
4. 引擎将响应传给Spider:引擎接收到响应后,将响应交给Spider进行解析。Spider会根据预定义的规则提取数据、跟踪链接等操作,并生成新的请求或者爬取项(Item)。
5. 引擎处理新的请求或爬取项:如果Spider生成了新的请求,引擎会将这些请求交给调度器继续调度;如果Spider生成了爬取项,引擎会将这些项交给实体管道(Pipelines)进行处理。
6. 循环执行以上步骤:引擎会不断循环执行上述步骤,直到没有新的请求并且Spider也没有新的爬取项生成。
Scrapy引擎通过协调各个组件的工作,实现了高效的异步处理和并发控制,并提供了丰富的中间件(Middleware)扩展点,使用户可以根据自己的需求进行定制和扩展。引擎的工作流程是Scrapy框架能够高效运行的关键所在。
引擎的具体实现是Scrapy框架内部的细节,一般情况下,我们不需要直接与引擎进行交互,而是通过编写Spider、中间件和管道等组件来实现具体的功能。
9.1.6 中间件
Scrapy框架提供了多个中间件,用于扩展和定制爬虫功能。以下是Scrapy中常用的几种中间件:
1. 下载中间件(Downloader Middleware):
- RetryMiddleware:处理请求重试,可配置最大重试次数和重试策略。
- UserAgentMiddleware:设置请求的User-Agent头,用于伪装爬虫身份。
- ProxyMiddleware:设置代理服务器,实现IP代理轮换或匿名访问。
2. 爬虫中间件(Spider Middleware):
- DepthMiddleware:控制请求的深度,限制爬取的层级。
- OffsiteMiddleware:过滤非法域名的请求,保证爬虫只爬取指定域名下的页面。
- RobotsTxtMiddleware:处理Robots协议,实现爬虫的合规性。
3. 信号中间件(Signal Middleware):
- StatsMiddleware:收集爬取状态数据,并在完成时输出统计信息。
- SpiderOpenCloseMiddleware:处理爬虫的启动和关闭事件。
- SpiderMiddleware:处理其他自定义信号事件,比如爬虫创建、请求处理等。
4. 自定义中间件:
开发者可以根据需求编写自定义的中间件来处理请求和响应,以实现更灵活和个性化的功能,例如:
- 解析请求和响应前后的预处理和后处理逻辑。
- 添加自定义的请求头、代理、Cookie等信息。
- 处理异常情况和错误重试。
- 对响应数据进行加工或过滤。
配置中间件:
在Scrapy的settings.py配置文件中,使用`DOWNLOADER_MIDDLEWARES`和`SPIDER_MIDDLEWARES`配置项分别来启用和配置下载中间件和爬虫中间件。例如:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.MyDownloaderMiddleware': 543,
}
SPIDER_MIDDLEWARES = {
'myproject.middlewares.MySpiderMiddleware': 543,
}
注意:数字`543`是中间件的优先级,数值越小,优先级越高。根据需求和顺序调整中间件的优先级。
编写中间件:为了编写自己的中间件,可以创建一个Python类并实现预定义的方法,如`process_request`、`process_response`等。在方法中编写对应的处理逻辑,可以拦截请求和响应,并在其中进行自定义操作。
9.2 Scrapy工作流程
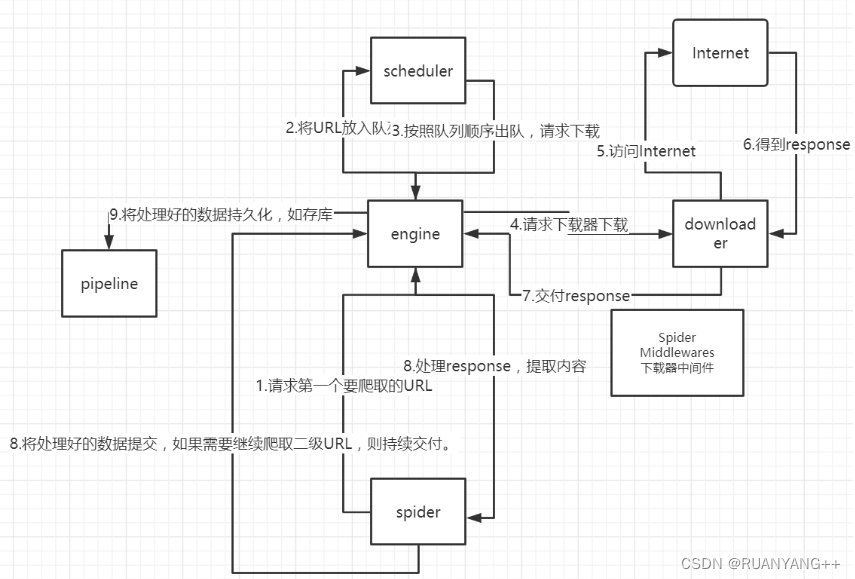
Scrapy爬虫工作流程:
1.spider(爬虫)中起始的 URL 构造成 Requests 对象 ⇒ 爬虫中间件 ⇒ engine (引擎) ⇒ scheduler(调度器);
2.scheduler(调度器)把 Requests ⇒engine (引擎) ⇒ 下载中间件 ⇒ download(下载器);
3.download(下载器)发送请求,获取 Responses 响应 ⇒ 下载中间件 ⇒ engine (引擎) ⇒ 爬虫中间件 ⇒ spider(爬虫);
4.spider(爬虫)提取 URL 地址,组装成 Requests 对象 ⇒ 爬虫中间件 ⇒ engine (引擎) ⇒ scheduler(调度器),重复步骤2;
5.spider(爬虫)提取数据 ⇒ engine (引擎) ⇒ 管道处理和保存数据;
9.3 Scrapy框架安装
第一种:在命令行模式下使用pip命令即可安装:
$ pip install scrapy第二种:首先下载,然后再安装:
$ pip download scrapy -d ./
# 通过指定国内镜像源下载
$pip download -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy -d ./进入下载目录后执行下面命令安装:
$ pip install Scrapy-1.5.0-py2.py3-none-any.whl
9.4 Scrapy的使用
9.4.1 基本步骤
1.创建新的Scrapy项目:在命令行中,使用scrapy startproject命令创建一个新的Scrapy项目
scrapy startproject mySpider 2.定义Spider:进入项目文件夹,使用scrapy genspider命令创建一个Spider。
scrapy genspider demo "demo.cn" 3.编写Spider代码:打开生成的Spider文件(位于myproject/myproject/spiders目录下),根据网站的结构和需求,编写爬取和解析页面的代码逻辑。在Spider中,可以定义爬取的起始URL、如何提取数据和生成新的请求等。
4.配置Spider:在Scrapy项目文件夹中的settings.py配置文件中,可以对Spider进行相关配置,例如设置User-Agent、设置下载中间件等。根据需求进行相应的配置。
9.4.2 程序运行
在命令中运行爬虫
scrapy crawl qb # qb爬虫的名字9.4.3 Scrapy文件
当我们创建了一个scrapy项目后,继续创建了一个spider,scrapy项目后目录结构如下图:
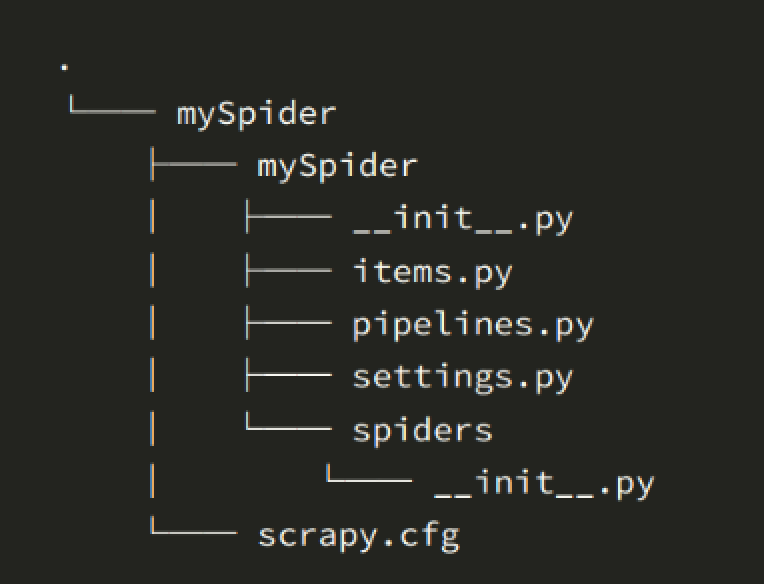
在Scrapy项目中,各个文件的作用如下:
1. scrapy.cfg: `scrapy.cfg` 是 Scrapy 项目的配置文件,它是一个 INI 格式的文件。在该文件中可以配置项目的全局设置,如爬虫模块位置、日志设置等。
2. items.py: `items.py` 文件定义了数据模型(Item),用于定义要提取的数据结构。开发者可以根据需求定义自己的 Item 类,用于存储从网页中提取的数据。
3. middlewares.py: `middlewares.py` 文件是 Scrapy 中间件的定义和配置文件。中间件用于拦截和处理 Scrapy 引擎与下载器之间的请求和响应数据。通过编写自定义的中间件,可以对请求和响应进行预处理或后处理,例如添加请求头、处理异常等。
4. pipelines.py:`pipelines.py` 文件用于定义数据处理管道(Pipeline)。Pipeline 负责处理从 Spider 提取到的 Item,包括数据清洗、验证、存储等操作。开发者可以在该文件中定义多个 Pipeline,并按顺序对 Item 进行处理。
5. settings.py:`settings.py` 文件是 Scrapy 项目的设置文件。通过配置该文件,可以进行一些全局设置,如指定使用的 Spider、配置爬取延时、设置 User-Agent、启用中间件等。
6. spiders: `spiders/` 目录是存放 Spider 的目录。在该目录下,可以创建多个 Spider 文件。Spider 是定义网页爬取和数据提取逻辑的核心组件,开发者可以根据需求编写自己的 Spider。
7. scrapy命令行工具:Scrapy 提供了一系列的命令行工具,用于管理和操作 Scrapy 项目,例如创建项目、生成 Spider、运行 Spider 等。通过命令行工具,可以方便地进行项目的管理和操作。
















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









