






一、 SVM概念
支持向量机是一种二分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。支持向量机的学习算法是求解凸二次规划的最优化算法。
基础的SVM算法是一个二分类算法,至于多分类任务,可以通过多次使用SVM进行解决。
1.线性可分支持向量机
对于一个数据集合可以画一条直线将两组数据点分开,这样的数据成为线性可分(linearly separable),如下图所示:

分割超平面:将上述数据集分隔开来的直线成为分隔超平面。对于二维平面来说,分隔超平面就是一条直线。对于三维及三维以上的数据来说,分隔数据的是个平面,称为超平面,也就是分类的决策边界。
间隔:点到分割面的距离,称为点相对于分割面的间隔。数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。论文中提到的间隔多指这个间隔。SVM分类器就是要找最大的数据集间隔。
支持向量:离分隔超平面最近的那些点。
2.最大间隔
对于线性可分的数据集D = ( x i , y i ) ,分类正确的超平面 
在SVM中,上式被称为样本点到超平面的函数间隔,同时等价于


在数据集中众多的样本点中,距离超平面最近的这几个训练样本点使等号成立,即支持向量会使等号成立,那么两个异类支持向量到超平面的距离之和为 ![]()
最大化间隔也就是寻找参数w ww和b bb , 使得γ \gammaγ最大,即: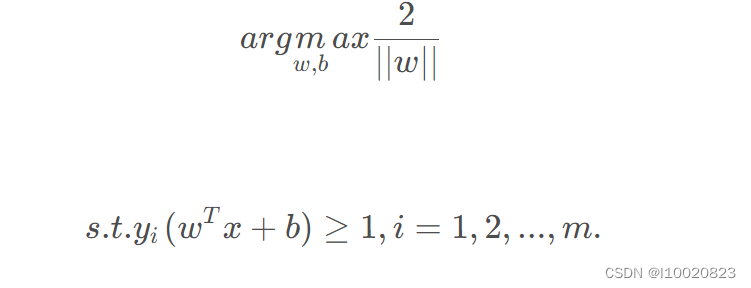
显然,我们可以转化为
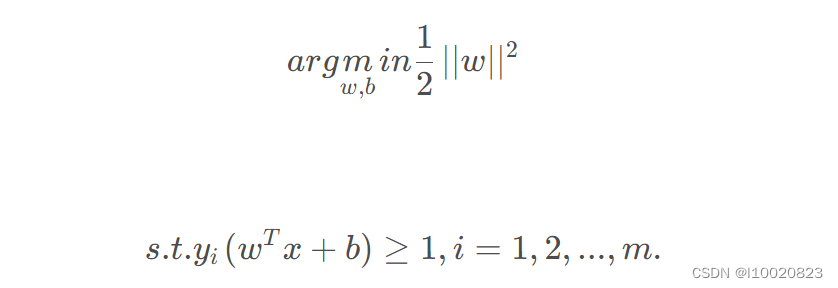
上式就是求解最大间隔超平面的最终表达式。
3.核函数
(1)在前面的讨论中,我们假设样本是线性可分的,即存在一个划分的超平面将样本正确划分,然而在实际生活中,原始的样本空间可能并不存在一个能划分正确的超平面,例如“异或问题”,如下图左图所示。

对于这样的问题,一般的,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间中线性可分,如上图右图所示,将二位空间合理的映射到一个三维空间,就能找到一个合适的划分超平面。如果原始空间是有限维,南无那么一定存在一个高维特征空间使样本可分。
令ϕ ( x )表示将x 映射后的特征向量,那么,在特征空间中划分超平面的模型可以表示为
其中w 和 b 是模型参数。
那么目标函数就转化为:
其对偶问题就变为:

求解得到:

(2)几种常见的核函数:

4.向量机对偶算法
第一步:引入拉格朗日乘子≥ 0得到拉格朗日函数
![]()
第二步:令对w和b的偏导为零:

第三步:w, b回代到第一步:

二、实现(鸢尾花分类预测)
1.数据集介绍
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)三种中的哪一品种。
数据:
sepal_len sepal_wid petal_len petal_wid label
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 22.代码实现
基于sklearn的代码实现:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
for i in range(len(data)):
if data[i,-1] == 0:
data[i,-1] = -1
return data[:,:2], data[:,-1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
plt.scatter(X[:50,0],X[:50,1], label='0')
plt.scatter(X[50:,0],X[50:,1], label='1')
plt.show()
model = SVC()
model.fit(X_train, y_train)
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
print('train accuracy: ' + str(model.score(X_train, y_train)))
print('test accuracy: ' + str(model.score(X_test, y_test)))3.运行结果
(1)数据分布展示:

(2)训练集和测试集上的准确性
train accuracy: 1.0
test accuracy: 0.96三、总结
1.SVM的优缺点
(1)优点
高效的处理高维特征空间:SVM通过将数据映射到高维空间中,可以处理高维特征,并在低维空间中进行计算,从而有效地处理高维数据。
适用于小样本数据集:SVM是一种基于边界的算法,它依赖于少数支持向量,因此对于小样本数据集具有较好的泛化能力。
可以处理非线性问题:SVM使用核函数将输入数据映射到高维空间,从而可以解决非线性问题。常用的核函数包括线性核、多项式核和径向基函数(RBF)核。
避免局部最优解:SVM的优化目标是最大化间隔,而不是仅仅最小化误分类点。这使得SVM在解决复杂问题时能够避免陷入局部最优解。
对于噪声数据的鲁棒性:SVM通过使用支持向量来定义决策边界,这使得它对于噪声数据具有一定的鲁棒性。
(2)缺点
对大规模数据集的计算开销较大:SVM的计算复杂度随着样本数量的增加而增加,特别是在大规模数据集上的训练时间较长。
对于非线性问题选择合适的核函数和参数较为困难:在处理非线性问题时,选择适当的核函数和相应的参数需要一定的经验和领域知识。
对缺失数据敏感:SVM在处理含有缺失数据的情况下表现不佳,因为它依赖于支持向量的定义。
难以解释模型结果:SVM生成的模型通常是黑盒模型,难以直观地解释模型的决策过程和结果。
2.SVM的应用场景
SVM在许多其他领域也有广泛的应用,特别是在分类和回归问题中。它的灵活性和强大的泛化能力使其成为机器学习中的重要工具之一。主要应用场景有文本分类如垃圾邮件分类、情感分析和文档分类、图像识别、信用评分、风险评估和股票市场预测等金融任务、医学诊断、视频分类等














 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









