









基础
熵
如果X是一个离散型随机变量,取值空间为R,其概率分布为
p(x)=P(X=x),x∈R
。那么,X的熵定义为:
H(X)=−∑x∈Rp(x)log2p(x)
其中,约定
0log20=0
。由于公式中对数以2为底,所以该公式定义的熵的单位为二进制(比特)。
熵用于描述一个一个随机变量的不确定性的数量。一个随机变量的熵越大,它的不确定性就越大。用通俗的话来来讲,一个随机变量的熵越大,它的各个取值的情况就越混乱,你越难猜中这个随机变量的取值。实际上,熵就是表示一个体系的混乱程度。反之,如果熵越小,这个体系就越纯,这正是本文要用到的性质。
直观上
有下表表示的数据集D:
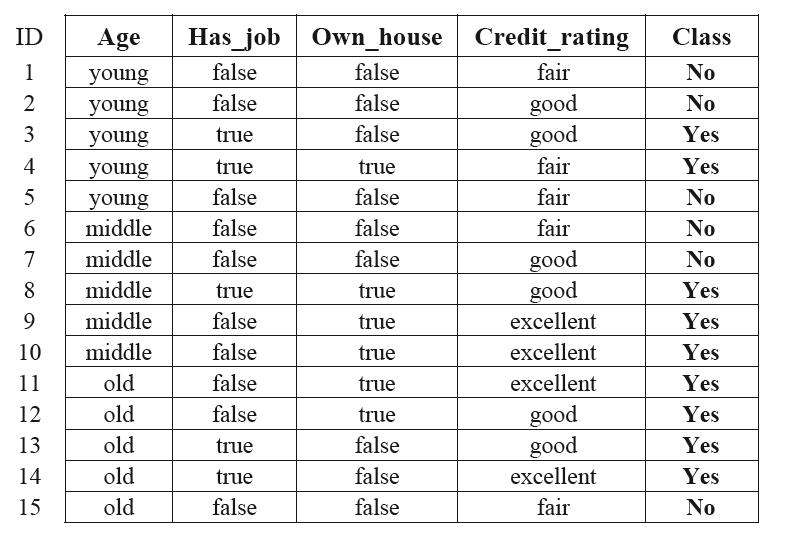
表中的每一行是D中的一个对象,具体意思是,一个人的条件以及是否发给了这个人信用卡。可以利用这个表生成决策树:
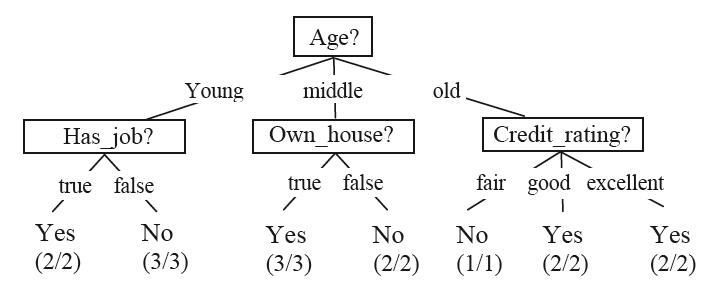
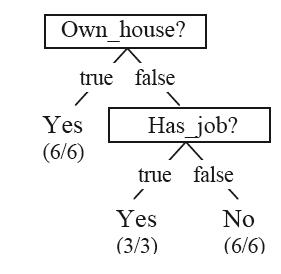
……
这些决策树就可以用来对一个新的对象进行分类了。
可以看到,通过这个表可以生成很多决策树,我们希望得到最好的那个决策树,比如,针对上面生成的决策树,我们更喜欢第二个。决策树算法可以帮我们得到数据集D对应的最好的那棵决策树。
决策树算法
决策树算法的伪代码如下:

其中,D表示数据集,A表示属性集,T表示一个树节点。
伪代码把算法描述得很清晰,但其中提到的两个函数impurityEval-1和impurityEval-2以及两个函数计算结果的差值需要延伸一下。
impurityEval-1用于计算数据集D纯度,impurityEval-2用于计算数据集D通过属性Ai划分子集之后的纯度。通过前面“基础”部分,我们知道,一个系统的纯度(也就是混乱度)可以用熵来表示,于是有:
impurityEval−1(D)=H(D)=−∑|C|j=1p(cj)log2p(cj)
其中,
|C|
是类别总数,
p(cj)
表示数据集D中类别
cj
占的比例。
数据集D通过属性Ai划分子集之后的纯度可表示为:
impurityEval−2(D)=HAi(D)=−∑vk=1|Dk||D|H(Dk)
其中,v是数据集D通过属性Ai分割后的子数据集的数目,
|D|
表示数据集D中对象的数目。
伪代码中12行和13行说,当impurityEval-1和impurityEval-2的差值小于个阈值时,递归停止,意思是说,用属性Ai划分数据集D让数据集变纯的效果不明显,继续分下去没有必要。impurityEval-1和impurityEval-2的差值还有个专门的名字,叫做信息增益,用公式表示就是:
gain(D,Ai)=impurityEval−2(D)−impurityEval−1(D)
本文首先介绍算法的核心基础,熵的概率,然后直观上展示了怎么从数据集生成决策树,最后介绍决策树算法本身。任何一个部分的介绍都是简略的,如果读者感兴趣,可以阅读文末的参考书籍。
参考资料:
《Web数据挖掘》第2版,Bing Liu 著, 俞勇 译
《统计自然语言处理》第2版,宗成庆 著















 2199
2199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









