






目录
一.神经网络概述:
神经网络是一种强大的机器学习算法,通过模拟人脑神经元之间的连接和信号传递过程,实现了对复杂数据模式的学习和预测。现代的“人工神经网络”是受生物神经的启发才逐步发展而来,生物神经网络中最基本的组织是神经元,以脊椎动物神经细胞为例:
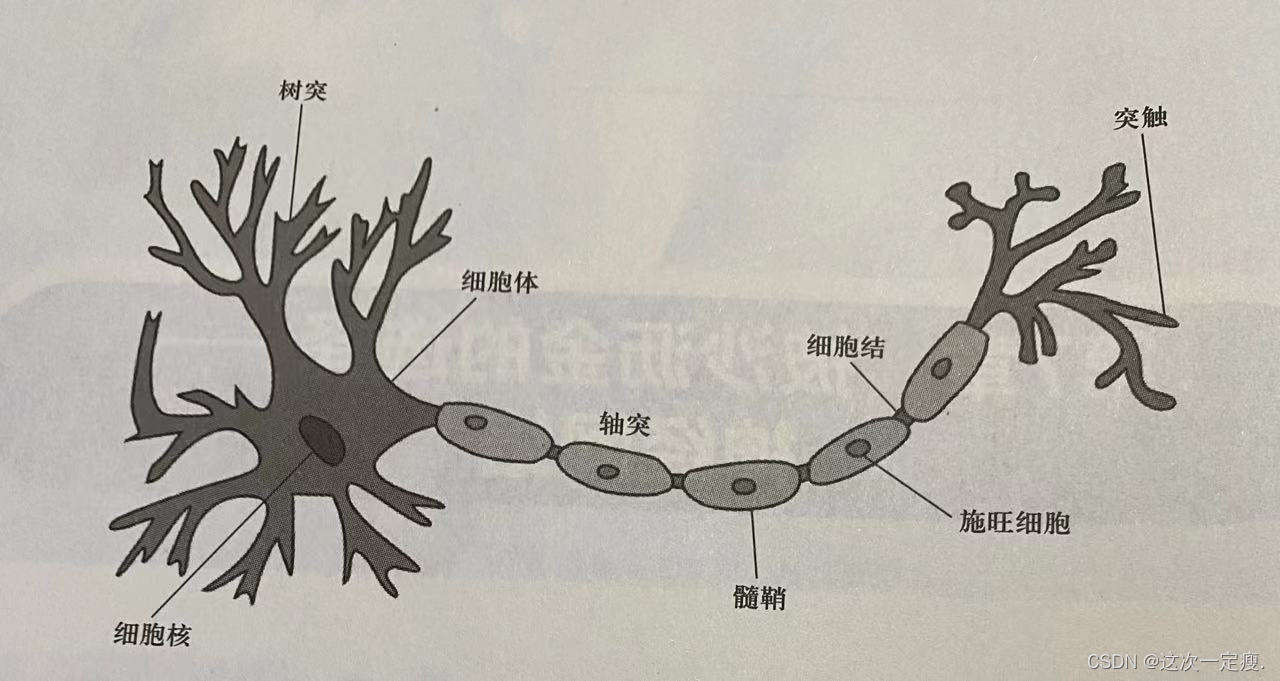
组织虽然复杂,但是功能却比较简单,当“突触”接收的信号(能够引发电位变化的化学物质)传导到细胞体中并积累到一定程度,它就被“激发”,激发的结果是这个神经元会向其他神经元发送化学物质。1943年McCulloch将上述过程描述成简单的模型,这就是沿用至今的M-P神经元模型:
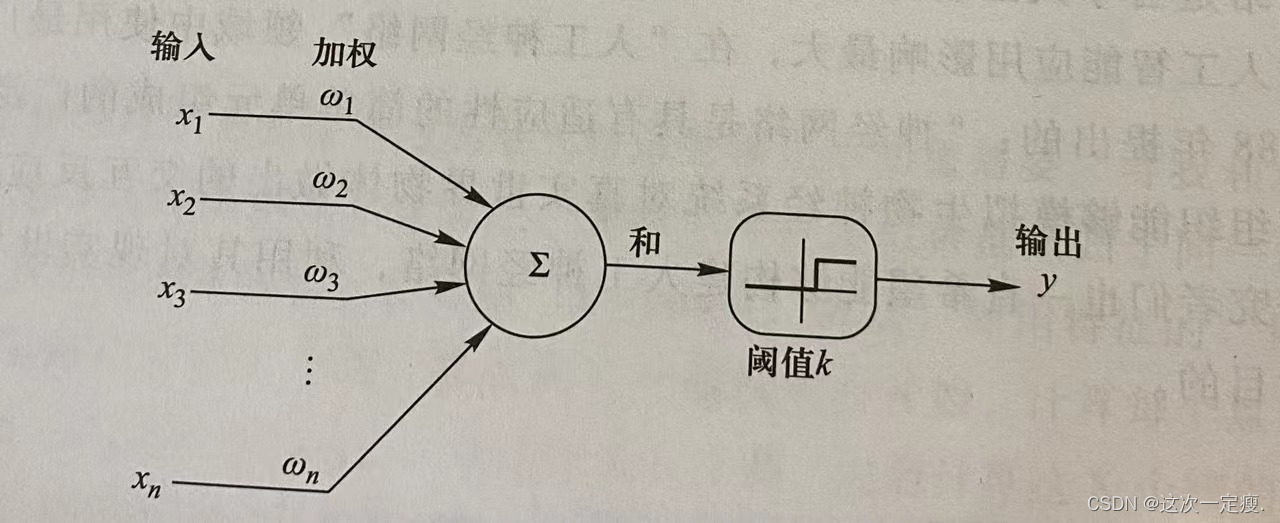
二.神经网络优化过程:
1.准备数据:首先需要准备用于训练神经网络的数据集,包括输入数据和对应的输出数据。
2.构建神经网络模型:根据任务需求和数据特点,构建合适的神经网络模型,包括确定网络结构、每层的神经元数量、连接权重等参数。
3.初始化参数:将神经网络的参数初始化为合适的值,常用的初始化方法包括随机初始化、零初始化等。
4.训练神经网络:使用训练数据对神经网络进行训练,通过反向传播算法不断调整神经网络的权重和偏置,使得模型的预测结果更加接近于真实结果。
5.验证和调整:在训练过程中,可以通过验证集来评估模型的性能,并根据验证结果调整模型的参数和结构,以进一步提高模型的性能。
6.测试和评估:使用测试集对训练好的模型进行测试和评估,以确定模型的泛化能力。
7.调整学习率和学习策略:根据训练过程中出现的不同情况,适时调整学习率和学习策略,以获得更好的训练效果。
总之,神经网络的优化过程是一个不断迭代和调整的过程,需要综合考虑多个方面,包括数据集、模型结构、参数初始化、学习率、验证和测试。
三.sklearn datasets产生数据集
1.了解sklearn:
Scikit-learn(简称sklearn)是一个用于机器学习的Python库,它建立在NumPy、SciPy和Matplotlib之上,提供了简单而高效的数据挖掘和数据分析工具。该库包含各种用于监督学习和无监督学习的算法,包括分类、回归、聚类、降维等。
以下是Scikit-learn的一些主要特点和功能:
-
简单而一致的API: Scikit-learn提供了统一的、简洁的API,使得使用不同的算法非常方便,并且易于学习和使用。
-
丰富的算法库: Scikit-learn包含了大量的机器学习算法,涵盖了各种任务,如分类、回归、聚类、降维等。
-
特征工程: 提供了丰富的特征提取、转换和选择方法,帮助用户准备和处理数据。
-
模型评估: 提供了多种评估指标和交叉验证方法,帮助用户评估模型的性能,并选择最佳的超参数。
-
内置数据集: Scikit-learn内置了一些常用的数据集,可以用于快速的实验和学习。
-
可扩展性: 由于Scikit-learn建立在NumPy、SciPy等Python科学计算库之上,因此具有很高的可扩展性,用户可以自由地扩展功能。
总的来说,Scikit-learn是一个功能强大、易于使用的机器学习库,适用于各种规模和复杂度的任务,是Python机器学习领域的重要工具之一。
2.安装sklearn:
- 要安装Scikit-learn,你可以使用pip(Python包管理器)。在命令行中执行以下命令:
-
pip install scikit-learn这将会下载并安装最新版本的Scikit-learn库及其所有依赖项。如果你使用的是Anaconda发行版,你也可以使用conda进行安装:
-
conda install scikit-learn根据自己的喜好选择其中一种。
3.datasets产生数据集
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
# 生成分类数据集
X, y = make_classification(n_samples=100, n_features=2, n_classes=2, n_clusters_per_class=1, random_state=42)
# 可视化生成的数据集
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, s=100, edgecolors='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Generated Classification Dataset')
plt.show()
在这个示例中,我们使用make_classification函数生成了一个简单的分类数据集。参数n_samples指定了样本数量,n_features指定了特征数量,n_classes指定了类别数量,n_clusters_per_class指定了每个类别内的簇数量。我们还指定了一个随机种子random_state以确保结果的可重复性。
然后,我们使用matplotlib将生成的数据集可视化。每个样本都用散点表示,颜色由标签y确定,即不同颜色代表不同的类别。
4.Logistic回归进行分类
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 生成分类数据集
X, y = make_classification(n_samples=100, n_features=2, n_classes=2, n_clusters_per_class=1, random_state=42)
# 将数据集分割成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 对测试集进行预测
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制决策边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, s=20, edgecolors='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Logistic Regression Classifier')
plt.show()
# 打印混淆矩阵和分类报告
print("\nConfusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
在这个示例中,我们首先生成了一个分类数据集,然后将其分割成训练集和测试集。接下来,我们初始化了一个逻辑回归模型并使用训练集对其进行训练。然后,我们对测试集进行预测,并计算了模型的准确率。
最后,我们绘制了决策边界和样本点的散点图,以可视化分类结果。同时,我们还打印了混淆矩阵和分类报告,用于评估模型的性能。
四.Keras:
1.了解Keras:
Keras是一个高级封装器,封装了面向Python的API。API接口可以与3个不同的后端库相兼容:Theano、谷歌的TensorFlow和微软的CNTK。这几个库都在底层实现了基本的神经网络单元和高度优化的线性代数库,可以用于处理点积,以支持高效的神经网络矩阵乘法运算,也是用 python 编写的高级神经网络 API ,它的核心思想在于实现快速实验,它能够在 TensorFlow , CNTK或Theano 之上运行,因此为了使用 Keras 首先需要安装 TensorFlow,CNTK 或 Theano 库作为后端。
2.安装Keras:
使用Tensorflow,因此需要首先使用如下命令安装Tensorflow:
$ pip install tensorflow-gpu
3.Keras实现神经网络:
# 导入所需的库
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 生成一些随机的训练数据
X_train = np.random.rand(1000, 10) # 1000个样本,每个样本有10个特征
y_train = np.random.randint(2, size=(1000, 1)) # 1000个样本的二分类标签
# 构建神经网络模型
model = Sequential()
# 添加输入层和隐藏层
model.add(Dense(units=64, input_dim=10, activation='relu'))
# 添加输出层
model.add(Dense(units=1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 使用模型进行预测
X_test = np.random.rand(10, 10) # 10个样本用于测试
predictions = model.predict(X_test)
# 打印预测结果
print(predictions)
在这个示例中,我们首先导入了所需的库。然后,我们生成了一些随机的训练数据,包括特征(X_train)和对应的标签(y_train)。接下来,我们使用Sequential模型构建了一个简单的神经网络,包括一个具有64个神经元的隐藏层和一个输出层。我们使用ReLU作为隐藏层的激活函数,使用sigmoid作为输出层的激活函数。
然后,我们编译模型,指定损失函数为二分类交叉熵(binary_crossentropy),优化器为Adam,评估指标为准确率(accuracy)。
接着,我们使用训练数据训练模型,指定训练轮数为10轮,批量大小为32。训练完成后,我们可以使用模型进行预测,并打印预测结果。
总结:
1.库和框架:
1.Python中有许多用于构建和训练神经网络的库和框架,其中最流行的包括TensorFlow、Keras、PyTorch等。
2.TensorFlow是一个功能强大的深度学习库,提供了灵活的工具来构建和训练各种类型的神经网络。
3.Keras是一个高级神经网络API,它可以在TensorFlow、Theano和CNTK等后端上运行,使得构建神经网络变得简单而直观。
2.模型构建:
1.在Python中,可以使用Keras或TensorFlow等库来构建神经网络模型。通过定义层和连接它们来创建模型,可以选择不同类型的层,如全连接层、卷积层、循环层等。
2.使用Keras的Sequential模型可以轻松地构建简单的线性堆叠模型,而使用函数式API可以构建更复杂的模型结构。
3.训练和优化:
1.神经网络的训练通常涉及到损失函数的定义、优化器的选择以及评估指标的设置。
2.通过在训练数据上反复迭代,并利用反向传播和梯度下降等优化算法来调整网络参数,以最小化损失函数,实现模型的训练。
4.应用领域:
1,。神经网络在各种领域都有广泛的应用,包括计算机视觉、自然语言处理、语音识别、推荐系统等。
2.在Python中,可以利用各种神经网络库和框架来构建和训练针对不同任务的神经网络模型,并且可以根据具体需求进行调整和优化。
5.部署和应用:
1.训练好的神经网络模型可以部署到各种环境中进行应用,包括嵌入式系统、移动设备、云服务器等。
2.在Python中,可以使用TensorFlow Serving、TensorFlow Lite等工具来部署和使用训练好的神经网络模型。
文章链接:https://blog.csdn.net/l3308487908/article/details/138032665?spm=1001.2014.3001.5502















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









