






目录
一、深度学习概念
1.神经网络的组成:
人工神经网络(Artificial Neural Networks,简写为ANNs)是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的,并具有自学习和自适应的能力。神经网络类型众多,其中最为重要的是多层感知机。
2.深度学习的定义
深度学习定义:一般是指通过训练多层网络结构对未知数据进行分类或回归
深度学习分类:有监督学习方法——深度前馈网络、卷积神经网络、循环神经网络等;
无监督学习方法——深度信念网、深度玻尔兹曼机,深度自编码器等。
深度学习的思想:深度神经网络的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。
3.深度学习应用:
(1)图像处理领域主要应用
图像分类(物体识别): 整幅图像的分类或识别
物体检测: 检测图像中物体的位置进而识别物体
图像分割: 对图像中的特定物体按边缘进行分割
图像回归: 预测图像中物体组成部分的坐标
(2)语音识别领域主要应用
语言模型:根据之前词预测下一个单词。
情感分析:分析文本体现的情感(正负向、正负中或多态度类型)。
神经机器翻译:基于统计语言模型的多语种互译。
神经自动摘要:根据文本自动生成摘要。
机器阅读理解:通过阅读文本回答问题、完成选择题或完型填空。
自然语言推理:根据一句话(前提)推理出另一句话(结论)。
(3)综合应用:
图像描述:根据图像给出图像的描述句子
可视问答:根据图像或视频回答问题
图像生成:根据文本描述生成图像
视频生成:根据故事自动生成视频
二、PyTorch安装步骤:
安装命令:
pip3 install torch torchvision torchaudioconda install pytorch torchvision cpuonly -c pytorch1.安装Anaconda:
从Anaconda官网下载并安装Anaconda。安装过程中注意选择“为所有用户安装”和“添加到环境变量”选项,并选择合适的安装位置。安装完成后,可以通过打开Anaconda Navigator或命令行窗口,并输入conda version来验证安装是否成功。
2.创建虚拟环境:
打开Anaconda Prompt(或者命令行窗口),输入以下命令创建一个新的虚拟环境(以环境名为pytorch,Python版本为3.8为例):
conda create -n pytorch python=3.8可以根据需要选择不同的Python版本。创建完成后,使用conda env list命令查看已创建的虚拟环境列表,确认pytorch环境已成功创建。
3.安装PyTorch:
激活刚刚创建的pytorch虚拟环境:conda activate pytorch,接着,进入PyTorch官网,根据自己的需求(如是否需要CUDA支持)选择合适的安装命令。将提供的安装命令复制到激活的pytorch虚拟环境的命令行中运行,开始安装PyTorch。安装完成后,可以通过输入python进入Python环境,然后尝试import torch来验证PyTorch是否安装成功。
4.配置镜像源(可选):
由于PyTorch的官方下载源位于国外,下载速度可能较慢。为了提高下载速度,可以选择配置国内的镜像源,如清华源或中科大源等。具体配置方法可以参考相关镜像源的官方文档。
三、神经元模型:
神经网络的概念最初来源于生物学家对大脑神经网络的研究,从中发现其神经元的工作原理,并且从数学角度提出感知器模型,并对其进行抽象化。
神经元接受来自n个其他神经元传递过来的输入信号,神经元将接受到的输入值按照某种权重加起来,叠加起来的刺激强度S可用公式表示:
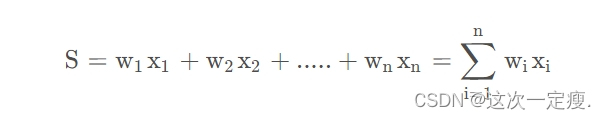
而这种输出,并非赤裸裸地直接输出,而是与当前神经元的阈值进行比较,然后通过激活函数(Activation Function)向外表达输出,在概念上这叫做感知机(Perceptron),其模型可用公式表示:
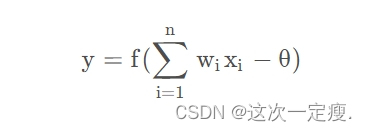
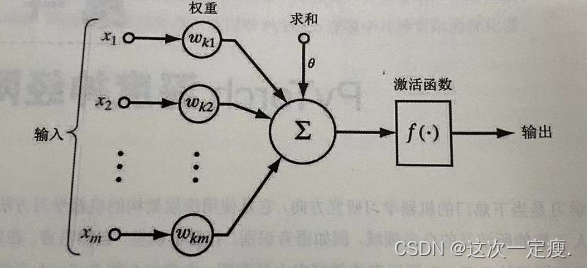
1. 每个神经元都是一个 多输入单输出的信息处理单元;
2. 神经元输入分兴奋性输入和 抑制性输入两种类型;
3. 神经元具有 空间整合特性和 阈值特性;
4. 神经元输入与输出间有固定的 时滞,主要取决于突触延搁。
四、多层感知器:
(1)导入必要的python模块
主要是numpy、theano,以及python自带的os、sys、time模块,这些模块的使用在下面的程序中会看到。
import os
import sysimport time
import numpy
import theano
import theano.tensor as T
(2)定义MLP模型
这一部分定义MLP的基本“构件”,LogisticRegression
逻辑回归(softmax回归),代码详解如下:
"""
定义分类层,Softmax回归
在deeplearning tutorial中,直接将LogisticRegression视为Softmax,
而我们所认识的二类别的逻辑回归就是当n_out=2时的LogisticRegression
"""
#参数说明:
#input,大小就是(n_example,n_in),其中n_example是一个batch的大小,
#因为我们训练时用的是Minibatch SGD,因此input这样定义
#n_in,即上一层(隐含层)的输出
#n_out,输出的类别数
class LogisticRegression(object):
def __init__(self, input, n_in, n_out):
#W大小是n_in行n_out列,b为n_out维向量。即:每个输出对应W的一列以及b的一个元素。
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
self.b = theano.shared(
value=numpy.zeros(
(n_out,),
dtype=theano.config.floatX
),
name='b',
borrow=True
)
#input是(n_example,n_in),W是(n_in,n_out),点乘得到(n_example,n_out),加上偏置b,
#再作为T.nnet.softmax的输入,得到p_y_given_x
#故p_y_given_x每一行代表每一个样本被估计为各类别的概率
#PS:b是n_out维向量,与(n_example,n_out)矩阵相加,内部其实是先复制n_example个b,
#然后(n_example,n_out)矩阵的每一行都加b
self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b)
#argmax返回最大值下标,因为本例数据集是MNIST,下标刚好就是类别。axis=1表示按行操作。
self.y_pred = T.argmax(self.p_y_given_x, axis=1)
#params,LogisticRegression的参数
self.params = [self.W, self.b](1)多层感知器是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以认为是一个有向图,由多个节点层组成,每一层全连接到下一层。除了输入节点外,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。
(2)一种被称为反向传播算法的监督学习方法常被用来训练MLP,MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。若每个神经元的激活函数都是线性函数,则任意层数的 MLP 都可以被简化成一个等价的单层感知器。

五、总结:
PyTorch是一个开源的机器学习框架,特别适用于深度学习任务。
关键点总结:
(1)动态计算图:
PyTorch使用动态计算图,与静态计算图相比更灵活,因为它可以根据需要随时更改计算图结构。这使得调试和模型构建更加直观。
(2)张量:
PyTorch中的核心数据结构是张量,它们类似于NumPy数组,但能够在GPU上进行加速计算。
(3)模型构建:
PyTorch提供了简单而灵活的API,使得构建神经网络模型变得轻松。你可以通过继承nn.Module类来定义自己的模型,并且可以使用预先定义的层(如全连接层、卷积层等)来构建模型。
(4)自动求导:
PyTorch的自动求导功能使得反向传播算法变得简单。通过设置requires_grad=True来跟踪张量的操作历史,并且可以调用.backward()方法来计算梯度。
(5)优化器:
PyTorch提供了各种优化器,如SGD、Adam等,用于更新模型参数以最小化损失函数。
(6)数据加载和处理:
PyTorch提供了torch.utils.data模块来处理数据加载和预处理。你可以使用Dataset和DataLoader类来加载和迭代数据集,并且可以轻松地应用各种数据转换和增强操作。
(7)模型训练和评估:
在PyTorch中,模型的训练和评估通常通过编写自定义的训练循环来完成。在训练循环中,你会迭代数据批次,计算模型输出和损失,然后更新模型参数。
(8)迁移学习:
PyTorch提供了许多预训练的模型,如ImageNet上训练的ResNet、VGG等。你可以利用这些预训练模型进行迁移学习,通过微调模型来解决自己的特定任务。
(9)分布式训练:
PyTorch支持分布式训练,可以在多个GPU或多台机器上并行地训练模型。
(10)部署和生产环境:
一旦训练完成,你可以使用PyTorch提供的工具将模型部署到生产环境中,例如TorchScript、ONNX等。
文章链接:https://blog.csdn.net/l3308487908/article/details/139185026?spm=1001.2014.3001.5502















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









