







源码地址
https://github.com/QwenLM/Qwen
说明文档
https://github.com/QwenLM/Qwen/blob/main/README_CN.md
Qwen本地部署
- 项目介绍:Qwen 是一个全能的语言模型系列,包含各种参数量的模型,如 Qwen(基础预训练语言模型,即基座模型)和 Qwen-Chat(聊天模型,该模型采用人类对齐技术进行微调)。项目地址:QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud. (github.com)
- 项目环境要求:
python 3.8 and above
pytorch 1.12 and above, 2.0 and above are recommended
transformers 4.32 and above
CUDA 11.4 and above are recommended (this is for GPU users, flash-attention users, etc.)
- 准备环境与工具(本机):python3.10、 CUDA12.2、 pycharm(可能需要)
- 本地部署
打开Anaconda prompt
- 虚拟环境创建:conda create -n qwen python=3.10
- 激活虚拟环境:conda activate qwen
- 进入项目所在文件夹,如:
D:
D:\liu\Project\Qwen-main(进入上述网址将项目下载到本地)
- 安装对应版本的pytorch:pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu121(与cuda对应)
- 安装依赖包:pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com(阿里源加速下载)
- 输入pip install modelscope安装魔塔依赖包
- 在本地创建一个python文件,如main.py

- 在文件中输入以下代码将模型下载至本地(默认下载于C盘.Cache文件夹中)
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# Downloading model checkpoint to a local dir model_dir
# model_dir = snapshot_download('qwen/Qwen-7B')
# model_dir = snapshot_download('qwen/Qwen-7B-Chat')
# model_dir = snapshot_download('qwen/Qwen-14B')
model_dir = snapshot_download('qwen/Qwen-14B-Chat')
# Loading local checkpoints
# trust_remote_code is still set as True since we still load codes from local dir instead of transformers
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
trust_remote_code=True
).eval()
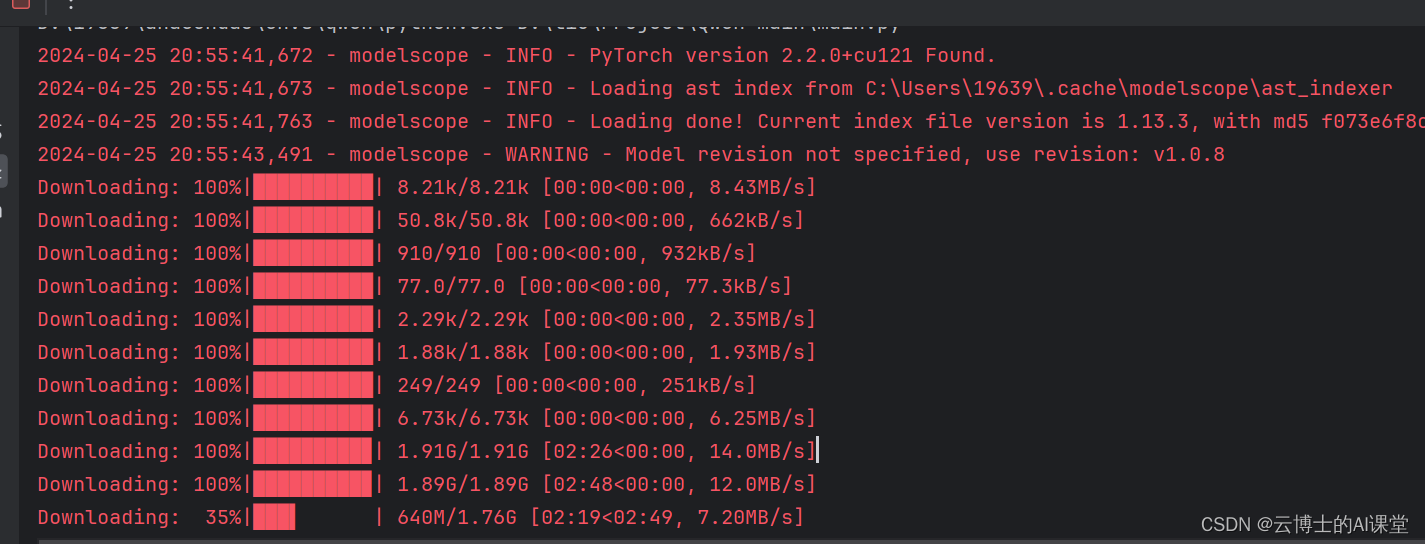
模型下载过程如下:
- 在上述代码后加入以下代码进行对话
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history)
print(response)
response, history = model.chat(tokenizer, "它有什么好玩的景点", history=history)
print(response)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









