







存在错误的程序是sample中的scanLargeArray,在指出具体错误之前,让我们先看一下这个程序的运行结果吧.
我的本本是130M,运行结果如下:
Running parallel prefix sum (prescan) of 1000000 elements
This version is work efficient (O(n) adds)
and has very few shared memory bank conflicts
Test PASSED
Average GPU execution time: 0.082135 ms
CPU execution time: 8.225319 ms
Check out the CUDA Data Parallel Primitives Library for more on scan.
http://www.gpgpu.org/developer/cudpp
Press ENTER to exit...
哇,GPU比CPU快100倍!GPU真有前途....拍手!
等会,记得好像prefix sum也是一个受带宽限制的任务吧,我的本本上的GPU有那么强壮吗?
怀着好奇心,计算了一下,就算至少扫描一遍数据:
一个float是4字节,4*1000000/0.082135*1000=48.7GB/s !!!
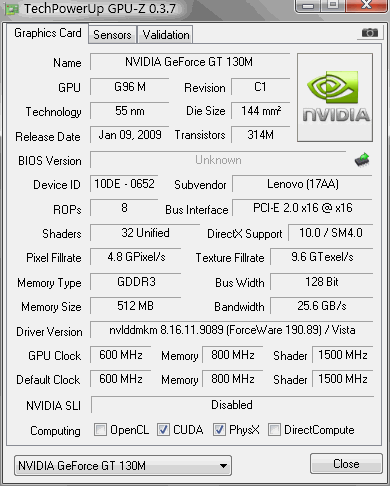
记得130M只有128bit的带宽啊,有那么厉害吗?
用GPU-Z一查,晕了,才25.6GB/s。(见下图)
肯定有问题!还好,有source可查,看了好几遍source,还是一下看不出问题。
最后,在测量时间的地方发现了问题所在。
请看scanLargeArray.cu中的下面一段程序:
preallocBlockSums(num_elements);
// run once to remove startup overhead
prescanArray(d_odata, d_idata, num_elements);
// Run the prescan
cutStartTimer(timerGPU);
for (unsigned int i = 0; i < num_test_iterations; i++)
{
//printf("prescanArray/n");
prescanArray(d_odata, d_idata, num_elements);
}
cutStopTimer(timerGPU);
deallocBlockSums();
// copy result from device to host
cutilSafeCall(cudaMemcpy( h_data, d_odata, sizeof(float) * num_elements,
cudaMemcpyDeviceToHost));
看出问题吗?哈哈,其实bug很低级,就是测试的都是内核的启动时间而非执行时间!
整个source中没有任何cudaThreadSynchronize!最后的同步是在
cutilSafeCall(cudaMemcpy( h_data, d_odata, sizeof(float) * num_elements,
cudaMemcpyDeviceToHost));
这里,而这时,计时已经结束了。
为证实这点,小小改了一下程序,在计时结束前,加上一句cudaThreadSynchronize调用。如下:
// Run the prescan
cutStartTimer(timerGPU);
for (unsigned int i = 0; i < num_test_iterations; i++)
{
//printf("prescanArray/n");
prescanArray(d_odata, d_idata, num_elements);
}
cudaThreadSynchronize();// add by l7331014
cutStopTimer(timerGPU);
这下运行结果变成了如下数据:
Running parallel prefix sum (prescan) of 1000000 elements
This version is work efficient (O(n) adds)
and has very few shared memory bank conflicts
Test PASSED
Average GPU execution time: 3.330053 ms
CPU execution time: 9.927999 ms
Check out the CUDA Data Parallel Primitives Library for more on scan.
http://www.gpgpu.org/developer/cudpp
Press ENTER to exit...
再计算一次带宽:
4*1000000/3.330053*1000=1.2GB/s !
这个才是真正的性能数据。真是天上地下啊,呵呵。
又运行了自己写的一个测试内核启动时间的小程序,结果如下:
Start time test .....
Processing time: 0.088433 (ms)
Finished !
这下算证实了。
最后说一下,sdk sample中的scan算法不是好的算法,在这里就不多提了,我会在以后的文章中分析为何不好。呵呵。















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









