







版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、 http://spark.apache.org/sql/
Spark Streaming 介绍
在很多实时数据处理的场景中,都需要用到流式处理(Stream Process) 框架, Spark也包含了两个完整的流式处理框架Spark Streaming和Structured Streaming(Spark 2.0出现)。
在传统的数据处理过程中,我们往往先将数据存入数据库中,当需要的时候再去数据库中进行检索查询,将处理的结果返回给请求的用户;另外, MapReduce 这类大数据处理框架,更多应用在离线计算场景中。而对于一些实时性要求较高的场景,我们期望延迟在秒甚至毫秒级别,就需要引出一种新的数据计算结构——流式计算,对无边界的数据进行连续不断的处理、聚合和分析。
Streaming 应用场景
如下的场景需求, 仅仅通过传统的批处理/离线处理/离线计算/处理历史数据是无法完成的:
电商实时大屏
1)、 电商实时大屏:每年双十一时,淘宝和京东实时订单销售额和产品数量大屏展示,要求:
- 数据量大,可能每秒钟上万甚至几十万订单量
- 快速的处理,统计出不同维度销售订单额,以供前端大屏展示

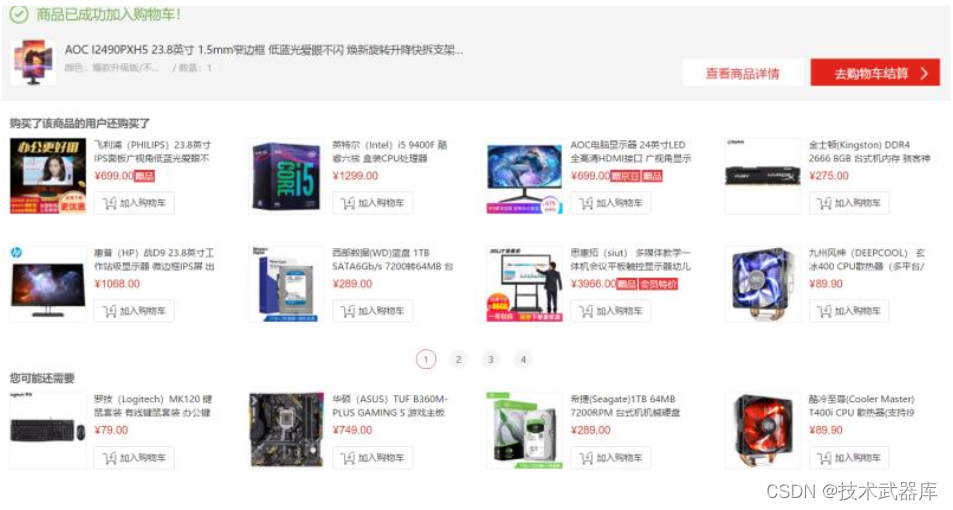
商品推荐
2)、商品推荐: 京东和淘宝的商城在购物车、商品详情等地方都有商品推荐的模块,商品推荐的要求:
- 快速的处理, 加入购物车以后就需要迅速的进行推荐
- 数据量大
- 需要使用一些推荐算法
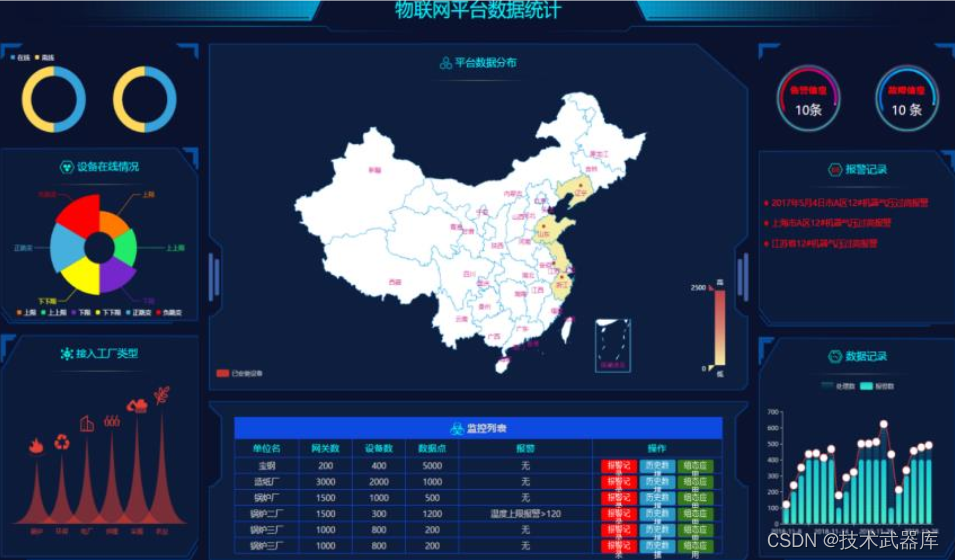
工业大数据
3)、工业大数据:现在的工场中, 设备是可以联网的, 汇报自己的运行状态, 在应用层可以针对这些数据来分析运行状况和稳健程度, 展示工件完成情况, 运行情况等,工业大数据的需求:
- 快速响应, 及时预测问题
- 数据是以事件的形式动态的产品和汇报
- 因为是运行状态信息, 且一般都是几十上百台机器, 所以汇报的数据量很大
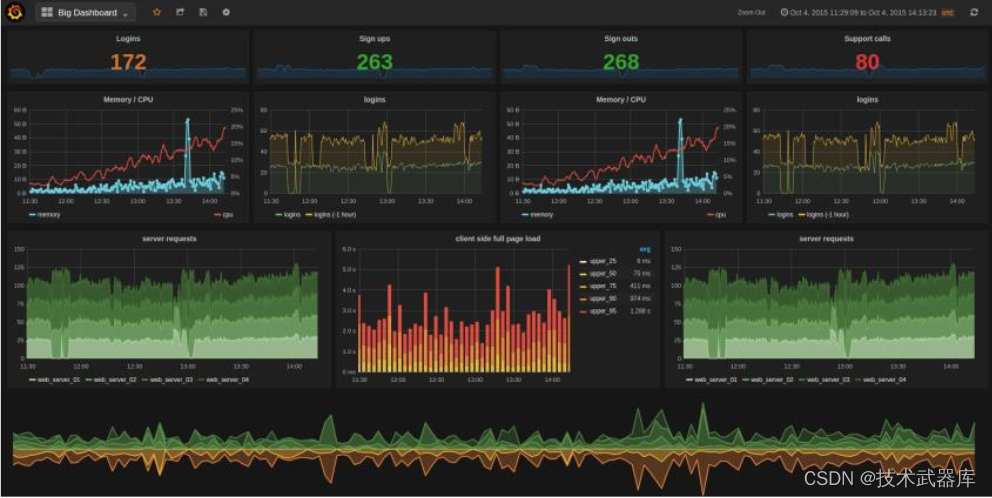
集群监控
4)、集群监控:一般的大型集群和平台, 都需要对其进行监控,监控的需求
- 要针对各种数据库, 包括 MySQL, HBase 等进行监控
- 要针对应用进行监控, 例如 Tomcat, Nginx, Node.js 等
- 要针对硬件的一些指标进行监控, 例如 CPU, 内存, 磁盘 等
- 工具的日志输出是非常多的, 往往一个用户的访问行为会带来几百条日志, 这些都要汇报,所以数据量比较大
- 要从这些日志中, 聚合系统运行状况
上述展示场景需要实时对数据进行分析处理,属于大数据中领域: 实时流式数据处理,概况应用场景如下几个大方面:
Lambda架构
Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架。 Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm, Lambda架构是其根据多年进行分布式大数据系统的经验总结提炼而成。
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有: 高容错、低延时和可扩展等。 Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop, Kafka, Storm, Spark, Hbase等各类大数据组件。
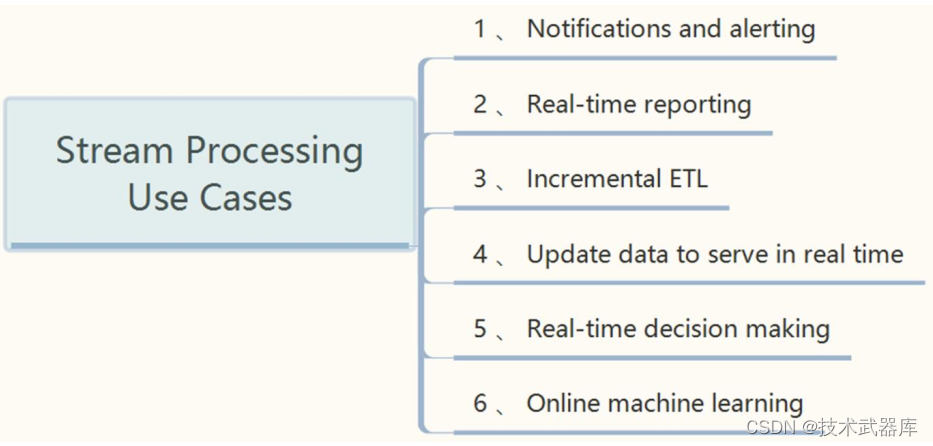
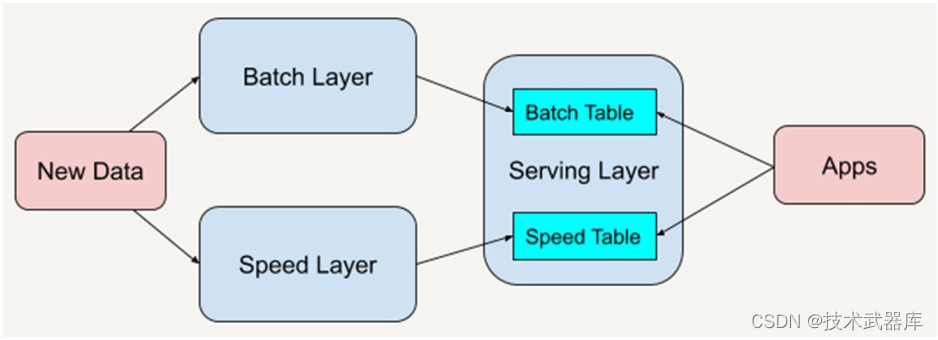
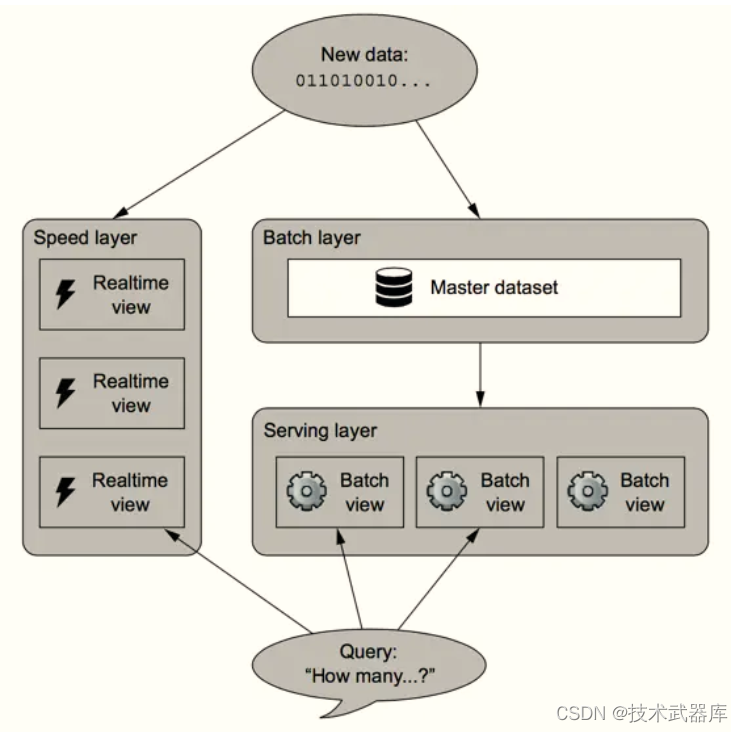
Lambda架构通过分解的三层架构来解决该问题: 批处理层(Batch Layer),速度层(SpeedLayer)和服务层(Serving Layer) 。
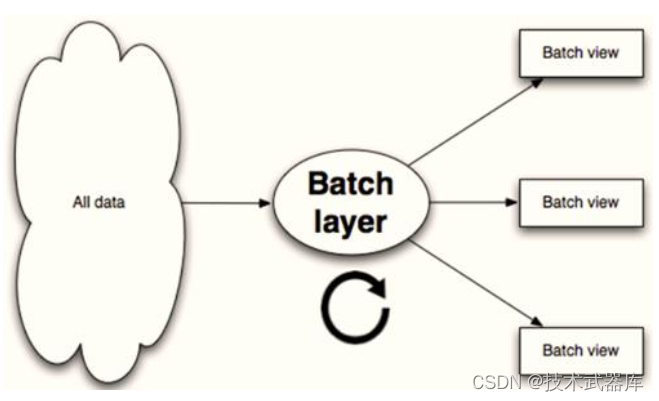
1)、批处理层(Batch Layer)
- 批处理层主用由Hadoop来实现,负责数据的存储和产生随意的视图数据;
- 承担了两个职责:存储Master Dataset,这是一个不变的持续增长的数据集;针对这个Master Dataset进行预运算;
- Batch Layer执行的是批量处理,例如Hadoop或者Spark支持的Map-Reduce方式;
2)、 速度层(Speed Layer)
- 从对数据的处理来看, speed layer与batch layer非常相似,它们之间最大的区别是前者只处理最近的数据,后者则要处理所有的数据;
- 为了满足最小的延迟, speed layer并不会在同一时间读取所有的新数据,相反,它会在接收到新数据时,更新realtime view,而不会像batch layer那样重新运算整个view;
- speed layer是一种增量的计算,而非重新运算(recomputation);
- Speed Layer的作用包括:对更新到serving layer带来的高延迟的一种补充、快速、增量的算法和最终Batch Layer会覆盖speed layer。
3)、 服务层(Serving Layer)
- 服务层负责建立索引和呈现视图, 以便于它们可以被非常好被查询到;
- Batch Layer通过对master dataset执行查询获得了batch view,而Serving Layer就要负责对batch view进行操作,从而为最终的实时查询提供支撑;
- 职责包含:对batch view的随机访问和更新batch view;
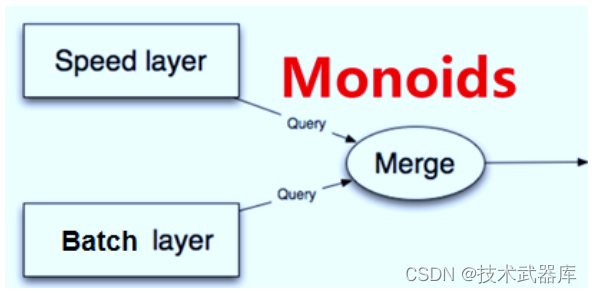
总结下来, Lambda架构就是如下的三个等式:

整个Lambda架构如下图所示:
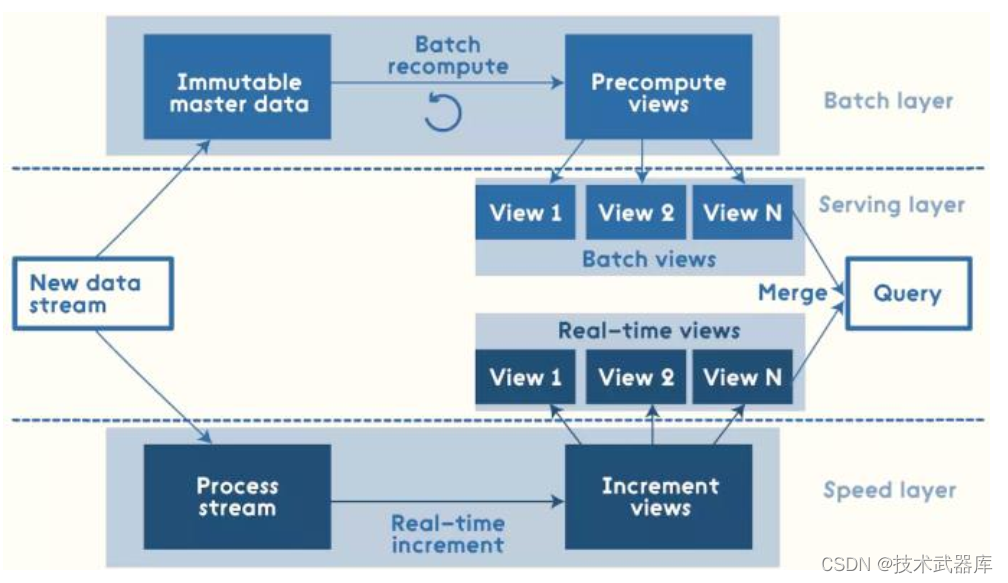
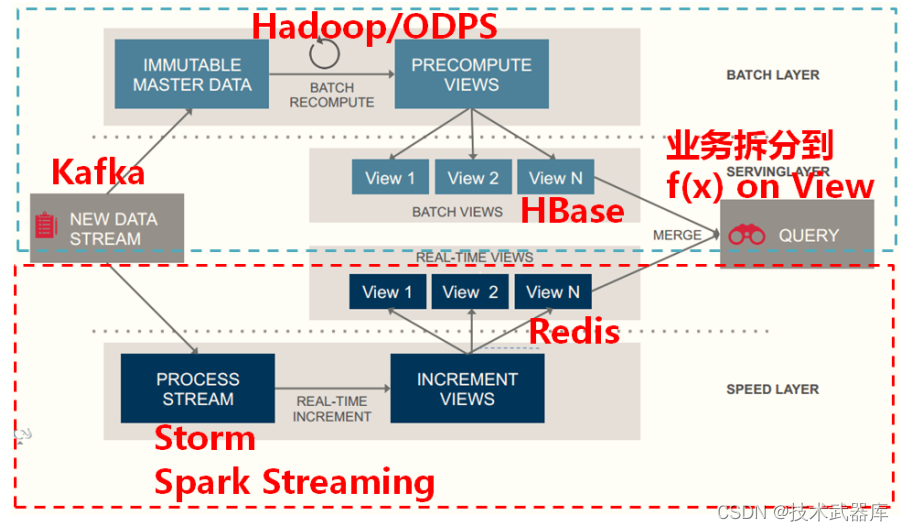
下图给出了Lambda架构中各个层常用的组件:
- 数据流存储可选用基于不可变日志的分布式消息系统Kafka;
- Batch Layer数据集的存储可选用Hadoop的HDFS,或者是阿里云的ODPS; Batch View的预计算可以选用MapReduce或Spark;
- Batch View自身结果数据的存储可使用MySQL(查询少量的最近结果数据),或HBase(查询大量的历史结果数据)。
- Speed Layer增量数据的处理可选用Storm或Spark Streaming或Flink或StructuredStreaming;
- Realtime View增量结果数据集为了满足实时更新的效率,可选用Redis等内存NoSQL。
Streaming 计算模式
流式处理任务是大数据处理中很重要的一个分支,关于流式计算的框架也有很多,如比较出名的Storm流式处理框架,是由Nathan Marz等人于 2010 年最先开发,之后将Storm开源,成为Apache 的顶级项目, Trident 对Storm进行了一个更高层次的抽象;另外由LinkedIn贡献给社区的Samza 也是一种流处理解决方案,不过其构建严重依赖于另一个开源项目 Kafka。 Spark
Streaming 构建在Spark的基础之上,随着Spark的发展, Spark Streaming和Structured Streaming也受到了越来越多的关注。
不同的流式处理框架有不同的特点,也适应不同的场景,主要有如下两种模式。
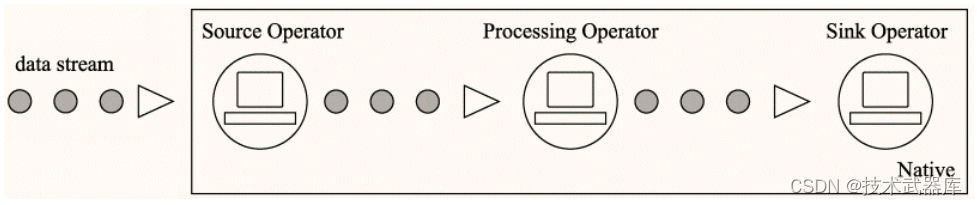
模式一: 原生流处理(Native)
- 所有输入记录会一条接一条地被处理,上面提到的 Storm 和 Flink都是采用这种方式;
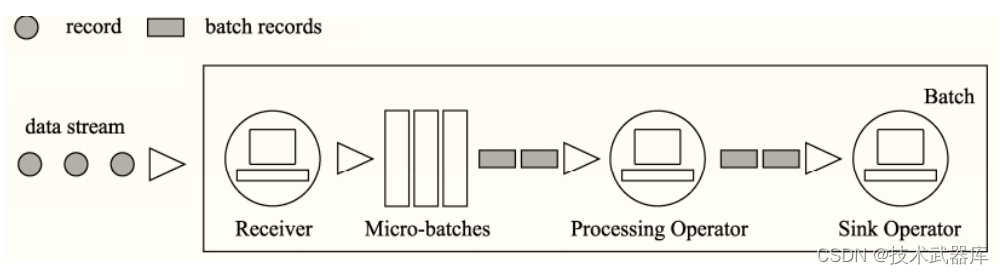
模式二: 微批处理(Batch)
- 将输入的数据以某一时间间隔 T,切分成多个微批量数据,然后对每个批量数据进行处理,Spark Streaming 和 StructuredStreaming采用的是这种方式;
SparkStreaming 计算思想
Spark Streaming是Spark生态系统当中一个重要的框架,它建立在Spark Core之上, 下图也可以看出Sparking Streaming在Spark生态系统中地位。

官方定义Spark Streaming模块:

SparkStreaming是一个基于SparkCore之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。

对于Spark Streaming来说, 将流式数据按照时间间隔BatchInterval划分为很多部分,每一部分Batch(批次),针对每批次数据Batch当做RDD进行快速分析和处理。
它的核心是DStream, DStream类似于RDD,它实质上一系列的RDD的集合, DStream可以按照秒、分等时间间隔将数据流进行批量的划分。首先从接收到流数据之后,将其划分为多个batch,然后提交给Spark集群进行计算,最后将结果批量输出到HDFS或者数据库以及前端页面展示等等。

如下图所示: 将流式数据按照【X seconds】划分很多批次Batch,每个Batch数据封装到RDD中进行处理分析,最后每批次数据进行输出。
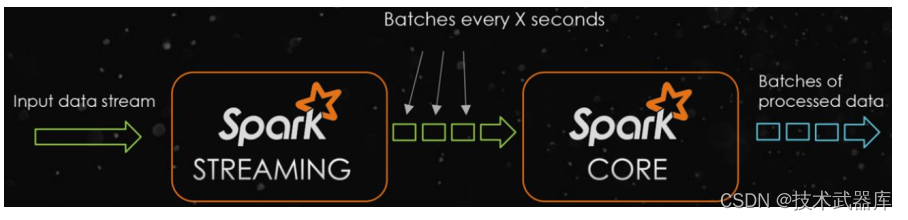
对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~5秒钟之间,所以Spark Streaming能够满足流式准实时计算场景,对实时性要求非常高的如高频实时交易场景则不太适合。

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











