







版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、 http://spark.apache.org/sql/
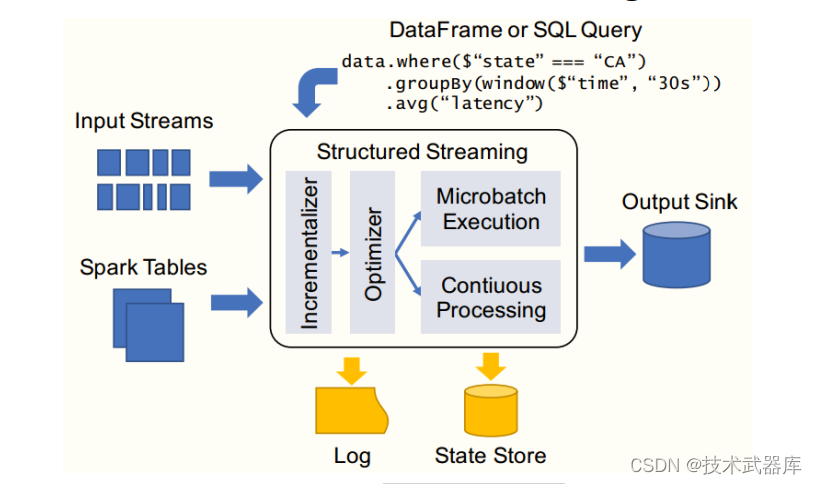
连续处理(Continuous Processing)是Spark 2.3中引入的一种新的实验性流执行模式,可实现低的(~1 ms)端到端延迟,并且至少具有一次容错保证。 将其与默认的微批处理(micro-batchprocessing)引擎相比较,该引擎可以实现一次性保证,但最多可实现~100ms的延迟。
连续处理概述
连续处理(Continuous Processing)是“真正”的流处理,之所以说“真正”是因为 continuousmode是传统的流处理模式,通过运行一个long-running的operator用来处理数据。之前SparkStreaming是基于 micro-batch 模式的,就被很多人诟病不是“真正的”流式处理。continuous mode处理模式只要一有数据可用就会进行处理,如下图所示:

epoch是input event stream中数据被发送给operator处理的最小单位,在处理过程中, epoch的offset会被记录到WAL中 。另外continuous模式下的snapshot存储使用的一致性算法是Chandy-Lamport算法。
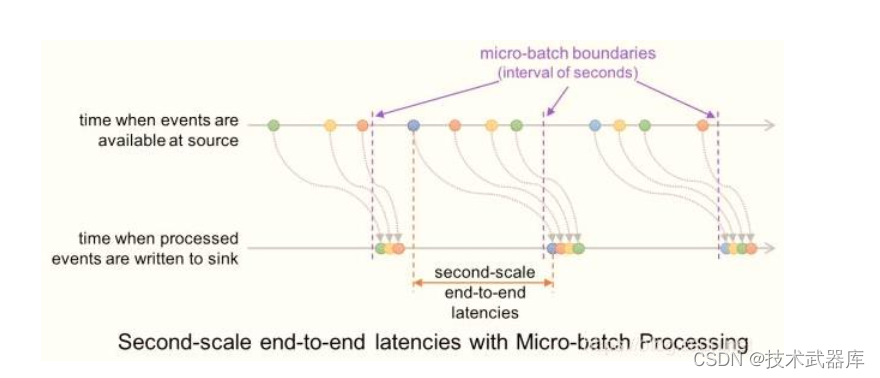
与micro-batch模式缺点和优点都很明显,缺点是不容易做扩展,优点是延迟更低。为什么延迟更低,下面两幅图目了然:
- 微批处理(Micro-batch Processing)
- 连续处理(Continue Processing)
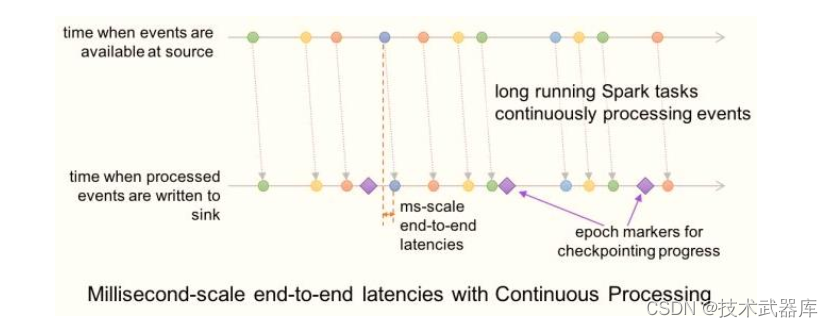
在一台4核服务器上对Structured Streaming的连续处理模式进行基准测试,该测试展示了延迟-吞吐量的权衡(因为分区是独立运行的,希望延迟与节点数量保持一致)。

上图展示了一个map任务的结果,这个map任务从Kafka中读取数据,虚线展示了微批模式能达到的最大吞吐量。可以看到,在连续模式下,吞吐量不会大幅下降,但是延迟会更低。(小于10毫秒的延迟,只有微批处理模式最大吞吐量的一半)。它的最大稳定吞吐量也略高,因为微批处理模式由于任务调度而导致延迟。
编程实现
要在连续处理模式下运行支持的查询,只需指定一个continuous trigger,并将所需的检查点间隔作为参数,示例代码:
// 从Kafka消费数据
val streamDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
// 数据ETL后保存Kafka
streamDF.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start()
检查点间隔为1秒意味着连续处理引擎将每秒记录查询的进度, 生成的检查点采用与微批处理引擎兼容的格式,因此可以使用任何触发器重新启动任何查询。 例如以微批处理模式启动的支持查询可以以连续模式(continuous mode)重新启动,反之亦然。
范例演示: 从Kafka实时消费数据,经过ETL处理后,将数据发送至Kafka Topic。
package continueprocess
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 从Spark 2.3版本开始,StructuredStreaming结构化流中添加新流式数据处理方式:Continuous processing
* 持续流数据处理:当数据一产生就立即处理,类似Storm、Flink框架,延迟性达到100ms以下,目前属于实验开发阶段
*/
object StructuredContinuous {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
spark.sparkContext.setLogLevel("WARN")
// 1. 从KAFKA读取数据
val kafkaStreamDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.10.10:9092")
.option("subscribe", "stationTopic")
.load()
// 2. 对基站日志数据进行ETL操作
// station_0,18600004405,18900009049,success,1589711564033,9000
val etlStreamDF: Dataset[String] = kafkaStreamDF
// 获取value字段的值,转换为String类型
.selectExpr("CAST(value AS STRING)")
// 转换为Dataset类型
.as[String]
// 过滤数据:通话状态为success
.filter{log =>
null != log && log.trim.split(",").length == 6 && "success".equals(log.trim.split(",")(3))
}
// 3. 针对流式应用来说,输出的是流
val query: StreamingQuery = etlStreamDF.writeStream
.outputMode(OutputMode.Append())
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.10.10:9092")
.option("topic", "etlTopic")
// 设置检查点目录
.option("checkpointLocation", s"datas/struct/chk4")
// TODO: 设置持续流处理 Continuous Processing, 指定CKPT时间间隔
/*
the continuous processing engine will records the progress of the query every second
持续流处理引擎,将每1秒中记录当前查询Query进度状态
*/
.trigger(Trigger.Continuous("1 second"))
.start() // 流式应用,需要启动start
// 查询器等待流式应用终止
query.awaitTermination()
query.stop() // 等待所有任务运行完成才停止运行
}
}
运行应用程序,观察数据生成与数据处理发送Kafka时间,实时性很快,延迟性在毫秒级别。
支持查询
从Spark 2.3开始,连续处理模式才出现,目前仅支持以下类型的查询:
- 第一、数据源Sources: Kafka source(支持所有选项)及Rate source(仅仅适合测试)。
- 第二、接收器Sinks: Kafka sink(支持所有选项)、 Console sink(适合调试)。
- 第三、 DataFrame Operations操作:在连续模式下仅支持类似 map 的 Dataset/DataFrame 操作,即仅投影(select, map, flatMap,mapPartitions等)和选择(where, filter等)。
连续处理引擎 启动多个长时间运行的任务,这些任务 不断从源中读取数据,处理数据并连续写入接收器 。 查询所需的任务数取决于查询可以并行从源读取的分区数。 因此,在开始连续处理查询之前,必须确保群集中有足够的核数并行执行所有任务。例如,如果正在读取具有10个分区的Kafka主题,则群集必须至少具有10个核数才能使查询取得进展。

















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











