







1. 什么是Model Head
- Model Head 是连接在模型后的层,通常为1个或多个全连接层
- Model Head 将模型的编码的表示结果进行映射,以解决不同类型的任务
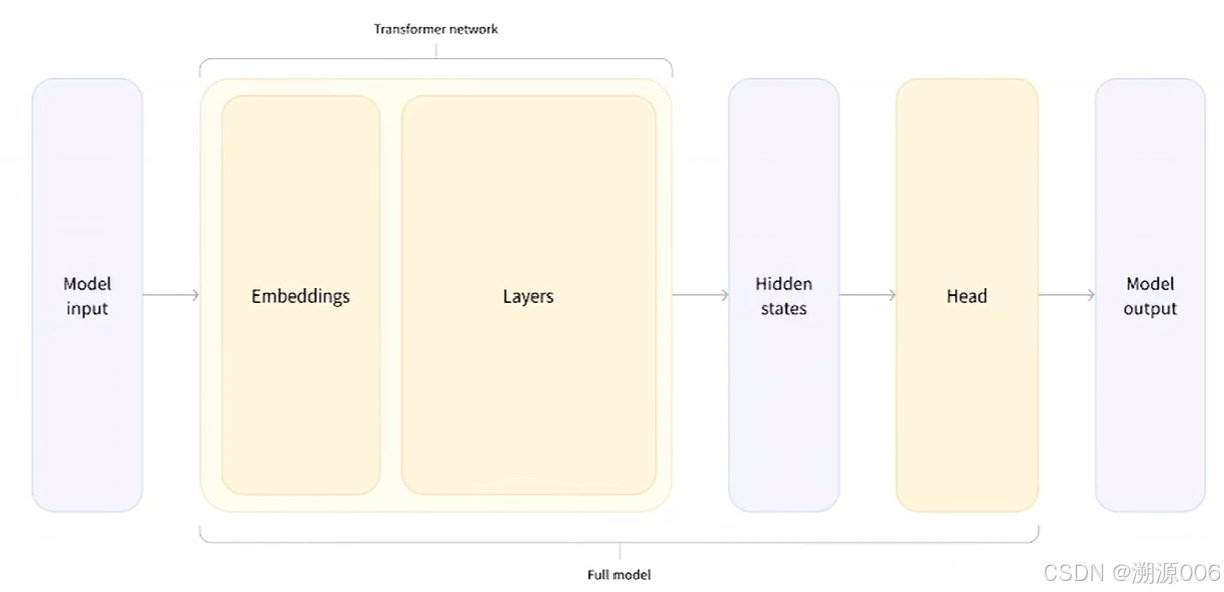
不同的任务会有不同的Model Head。
2. 模型加载
2.1 在线加载
预训练模型的加载与Tokenizer类似,我们只需要指定想要加载的模型名称即可。面对各种类型的模型,transformers也为我们提供了更加便捷的加载方式,我们无需指定具体的模型的类型,可以统一使用AutoModel进行加载。首次加载的时候会进行模型文件的下载,下载后的文件会保存在~/.cache/huggingface/transformers文件夹中。注意:可能会因为网络问题,下载失败。transformers的模型仓库中提供了丰富的模型,我们可以到模型仓库的网站中查看,直接搜索想要的模型。
from transformers import AutoConfig, AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("hfl/rbt3")
2.2 离线加载
如果在线下载失败,可以先手动从huggingface的网站下载模型文献到本地,然后再从本地加载模型。
(1)手动下载模型方式一:浏览器下载
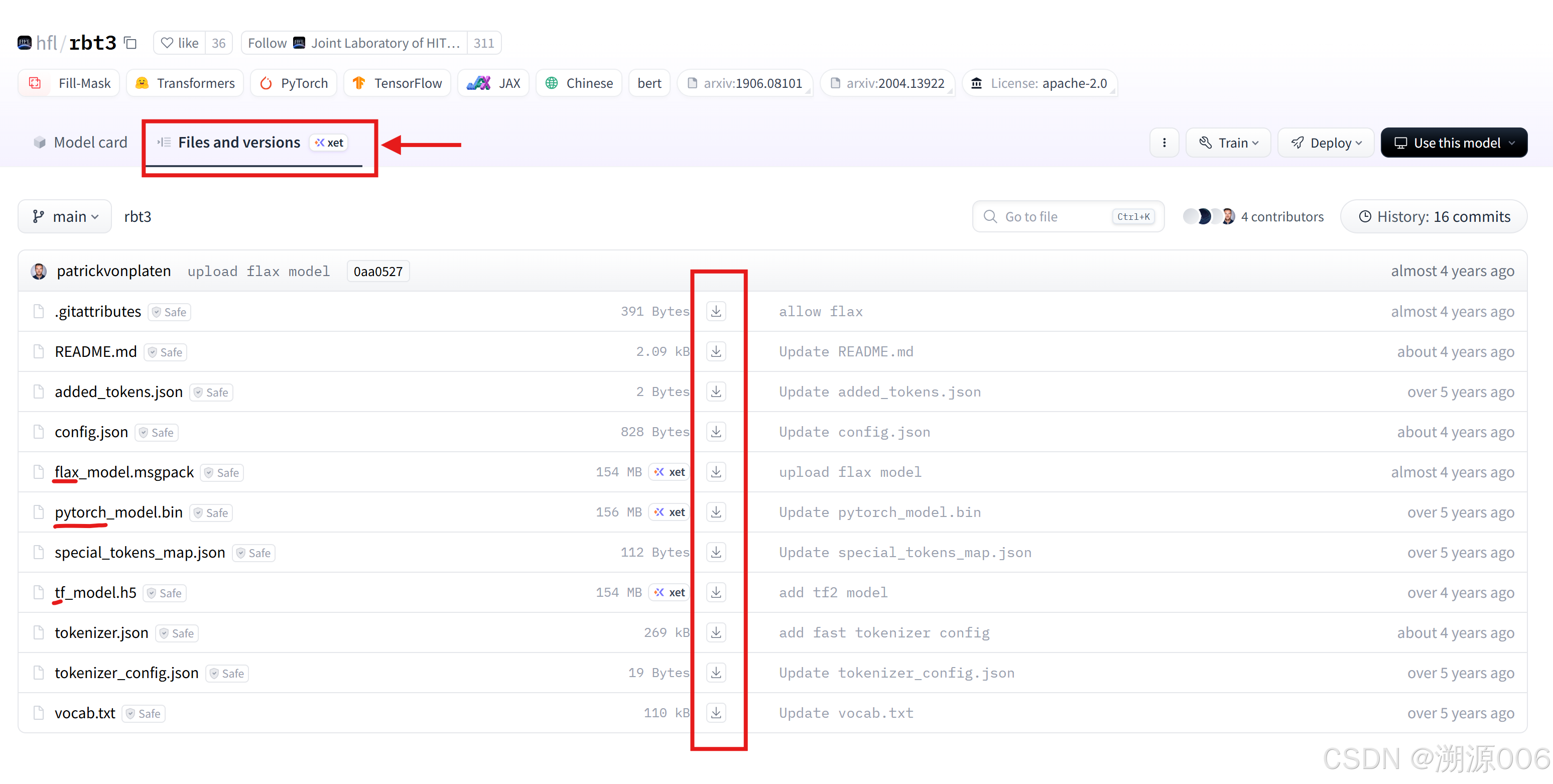
找到模型的files and versions标签页,可以点击下载按钮直接下载对应的文件。可以看到对于rbt3这个模型,三个比较大的文件,分别对应模型的不同版本,我们只需要pytorch版本。
(2)手动下载模型方式一:git clone
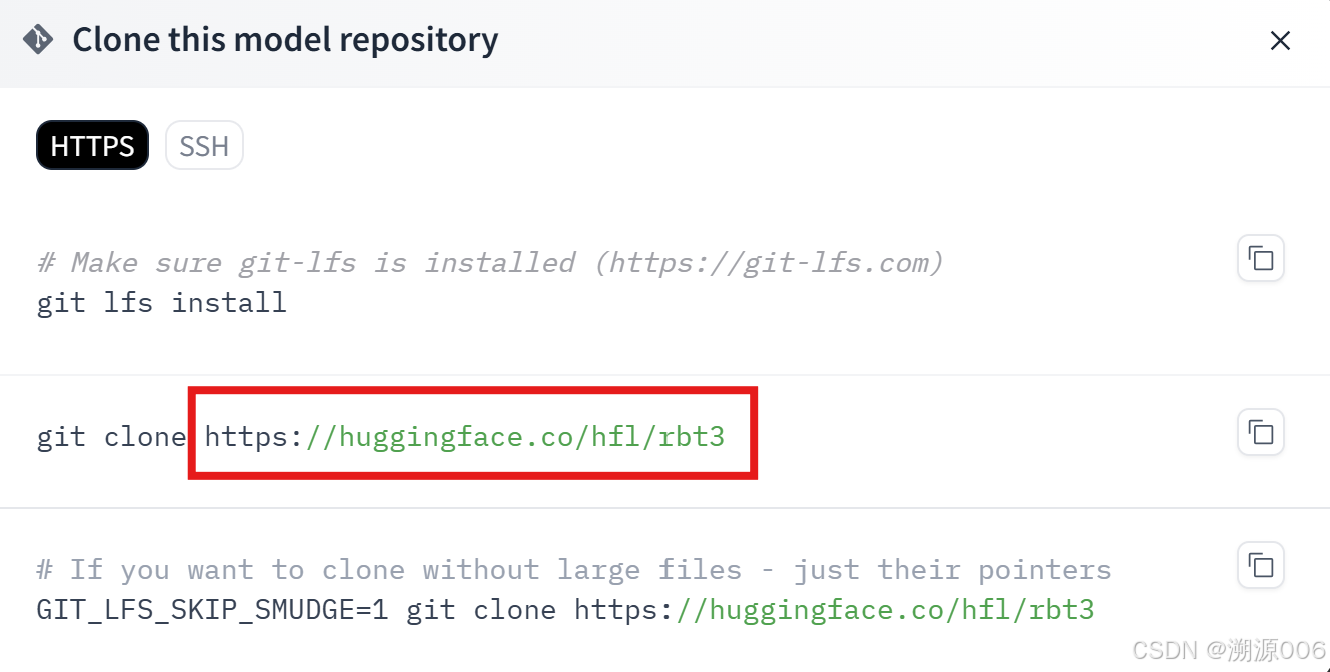
文件里可能包含其他版本的模型文件,如果只想下载pytorch版本的模型文件,如下:
# 可以使用下面命令进行下载 (只下载pytorch的权重文件)
!git lfs clone "https://huggingface.co/hfl/rbt3" --include="*.bin"
然后就可以从本地离线加载了:
# 如果在离线场景下,则需要将模型文件提前准备好,from_pretrained方法中指定本地模型存储的文件夹即可。
model = AutoModel.from_pretrained("../models/rbts")
2.3 加载模型的同时配置参数
加载的时候可以配置一些参数,有哪些参数可以加载呢?可以查看一下:
model.config
或者如下:
config = AutoConfig.from_pretrained("../models/rbts")
以上两种的结果是一样的,如下:
BertConfig {
"_attn_implementation_autoset": true,
"_name_or_path": "../models/rbts",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 3,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
...
"transformers_version": "4.49.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
可能还不是很全,可以通过如下方式选择参数:
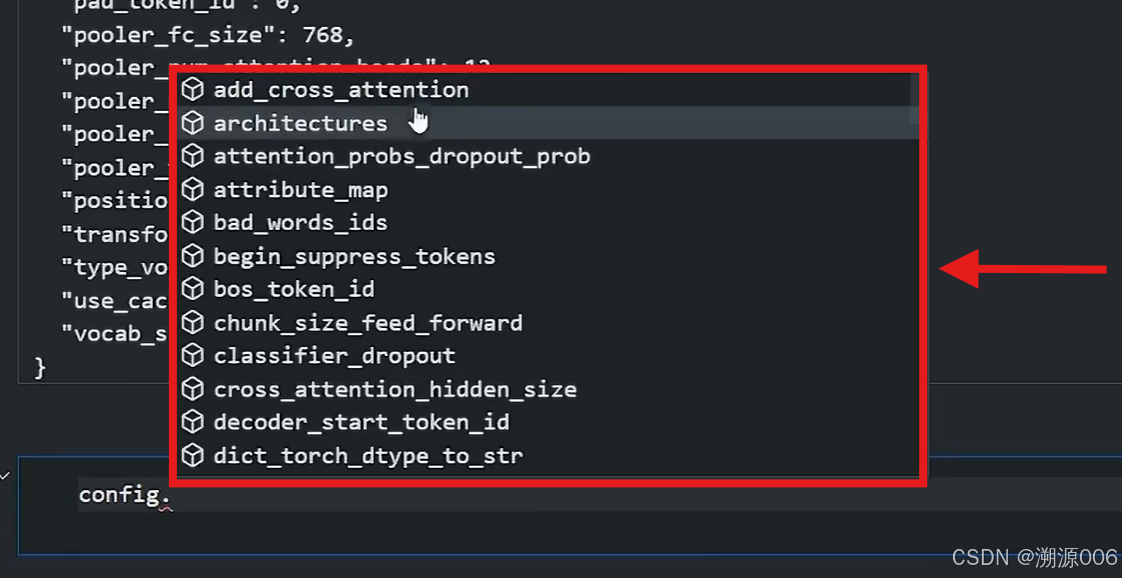
这些参数在哪里呢?首先可以查看config变量属于哪个类.上面的例子属于BertConfig类,进入这个类
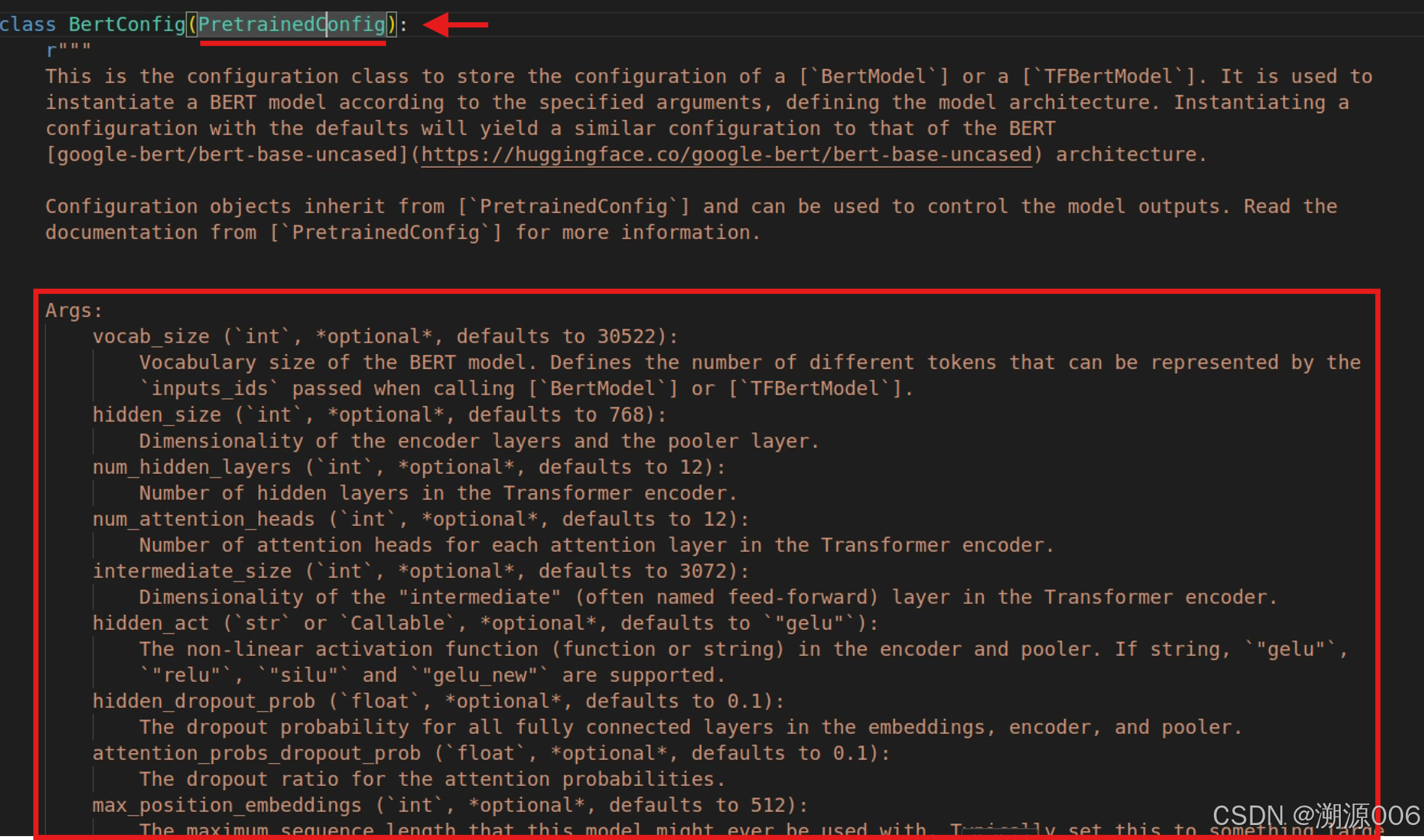
参数还不全,在进入他的父类:
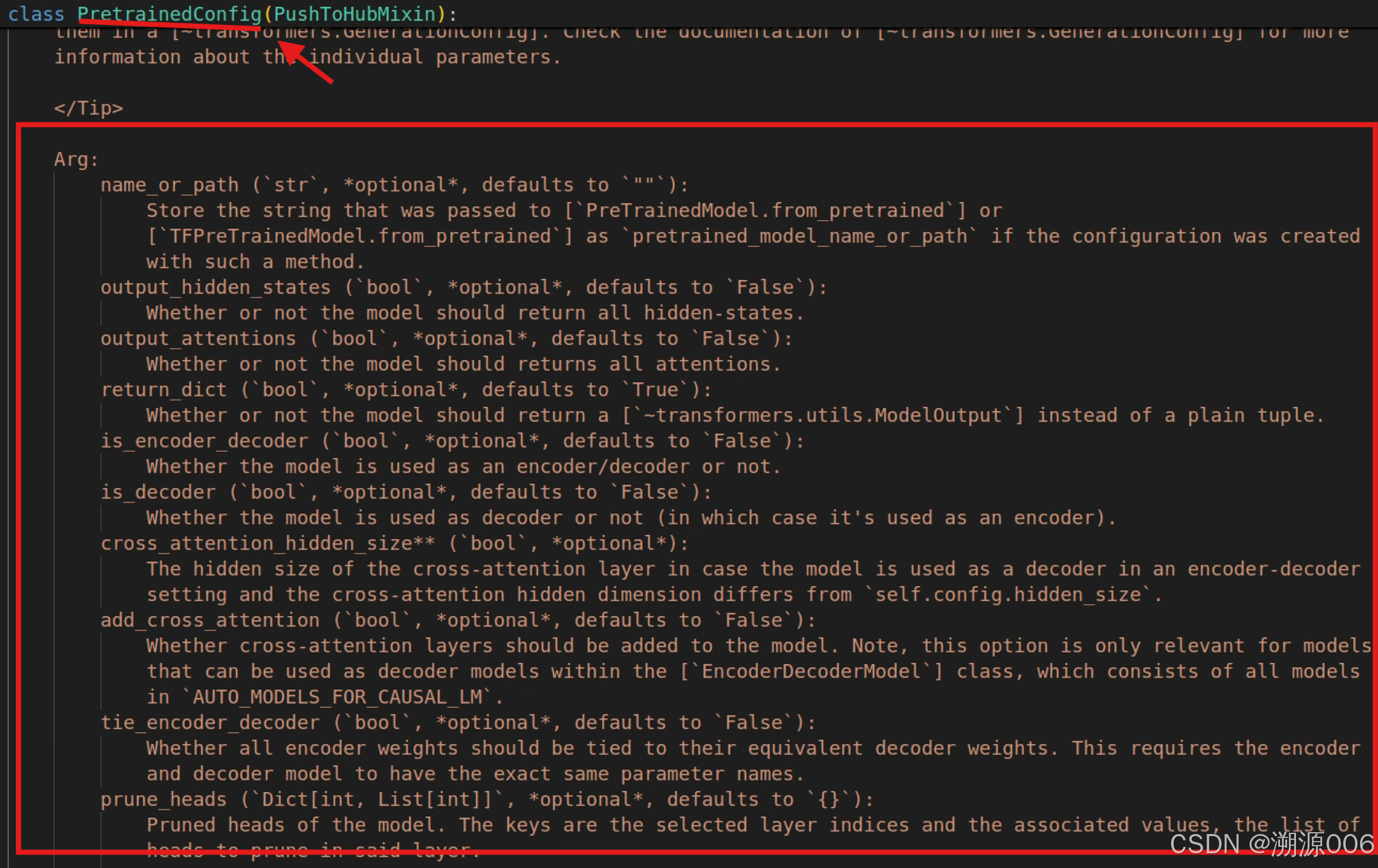
可以看到更多的参数。
3. 模型的调用
3.1 准备(tokenize)
sen = "弱小的我也有大梦想!"
tokenizer = AutoTokenizer.from_pretrained("../models/rbts")
inputs1 = tokenizer(sen)
输出如下:
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 8013, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
返回的每个值是lisst,如果是增加一个参数 return_tensors="pt",让返回pytorch tensors,如下
inputs = tokenizer(sen, return_tensors="pt")
则输出如下:
{'input_ids': tensor([[ 101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 8013, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
分词的时候加上return_tensors="pt"就把list变为pytorch tensor,可以直接输入模型。
3.2 不带Model Head的模型调用(只得到编码结果)
# 数据经过Tokenizer处理后可以便可以直接输入到模型中,得到模型编码
model = AutoModel.from_pretrained(model_path, output_attentions=True)
output = model(**inputs)
返回:
BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=tensor(
[[[ 0.6804, 0.6664, 0.7170, ..., -0.4102, 0.7839, -0.0262],
[-0.7378, -0.2748, 0.5034, ..., -0.1359, -0.4331, -0.5874],
[-0.0212, 0.5642, 0.1032, ..., -0.3617, 0.4646, -0.4747],
...,
[ 0.0853, 0.6679, -0.1757, ..., -0.0942, 0.4664, 0.2925],
[ 0.3336, 0.3224, -0.3355, ..., -0.3262, 0.2532, -0.2507],
[ 0.6761, 0.6688, 0.7154, ..., -0.4083, 0.7824, -0.0224]]],
grad_fn=<NativeLayerNormBackward0>),
pooler_output=tensor(
[[-1.2646e-01, -9.8619e-01, -1.0000e+00, -9.8325e-01, 8.0238e-01,
...,
6.7307e-03, 9.9942e-01, -1.8233e-01]], grad_fn=<TanhBackward0>), hidden_states=None,
past_key_values=None,
attentions=(tensor(
[[[[4.7840e-01, 3.7087e-04, 1.6194e-04, ..., 1.4241e-04,
4.1823e-04, 5.1813e-01],
...
[7.1003e-02, 1.5132e-03, 7.3035e-04, ..., 2.2069e-02,
3.9020e-01, 5.0058e-01]]]], grad_fn=<SoftmaxBackward0>), tensor([[[[4.3653e-01, 1.2017e-02, 5.9486e-03, ..., 6.0889e-03,
6.2510e-02, 4.1911e-01],
...,
[1.7047e-01, 3.6989e-02, 2.3646e-02, ..., 4.6833e-02,
2.5233e-01, 1.6721e-01]]]], grad_fn=<SoftmaxBackward0>)), cross_attentions=None)
因为设置了output_attentions=True,所以输出的attentions有具体数值,否则为None。
最后一层的输出就是:last_hidden_state,他的维度如下:
output.last_hidden_state.size() # (batch_size, sequence_length, hidden_size)
#torch.Size([1, 12, 768])
3.3 带Model Head的模型调用
- 仅仅使用预训练模型本身,是无法对下游任务进行训练的。
- 想要实现对下游任务的训练,我们需要加载transformers包中的扩展模型(预训练模型+任务头模块)。
- transformers包中提供了多种的任务头。
| NLP任务 | 任务头 |
|---|---|
| 文本分类 | SequenceClassification |
| 文本匹配 | SequenceClassification |
| 阅读理解(抽取式问答) | QuestionAnswering |
| 掩码语言模型 | MaskedLM |
| 文本生成 | CausalLM |
| 命名实体识别 | TokenClassification |
| 文本摘要 | Seq2SeqLM |
| 机器翻译 | Seq2SeqLM |
| 生成式问答 | Seq2SeqLM |
在代码上,就是我们不再导入AutoModel,而是导入AutoModelFor+任务头名称。 | |
| 假设我们要做文本分类任务,那么则应该导入AutoModelForSequenceClassification。 | |
| 这里需要注意,并不是每个模型都具备上述的全部任务头。预训练模型具体支持哪些任务头,需要到官网或者源码中进行查看。 |
from transformers import AutoModelForSequenceClassification
clz_model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=10)
clz_model(**inputs)
输出结果如下:
SequenceClassifierOutput(
loss=None,
logits=tensor([[-0.1776, 0.2208, -0.5060, -0.3938, -0.5837, 1.0171, -0.2616, 0.0495, 0.1728, 0.3047]],
grad_fn=<AddmmBackward0>),
hidden_states=None,
attentions=None
)
logits的元素个数与num_labels保持一致。
3.4 带model head 与不带model head的的对比
(1) 加载方式不同
不带model head的模型用AutoModel.from_pretrained加载模型
model = AutoModel.from_pretrained(model_path, output_attentions=True)
带model head的模型用 AutoModelForSequenceClassification.from_pretrained加载模型
clz_model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=10)
(2) 模型的不同
不带model head的模型:
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-2): 3 x BertLayer(
(attention): BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
带model head的模型:
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-2): 3 x BertLayer(
(attention): BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=10, bias=True)
)
可以看到带model head的模型就是在不带model head的模型加了最后的:
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=10, bias=True)
3.5 一个例子:基于pytorch和model进行情感分类训练
任务类型:文本分类
使用模型:hfl/rbt3
数据集地址:https://github.com/SophonPlus/ChineseNlpCorpus
数据集:
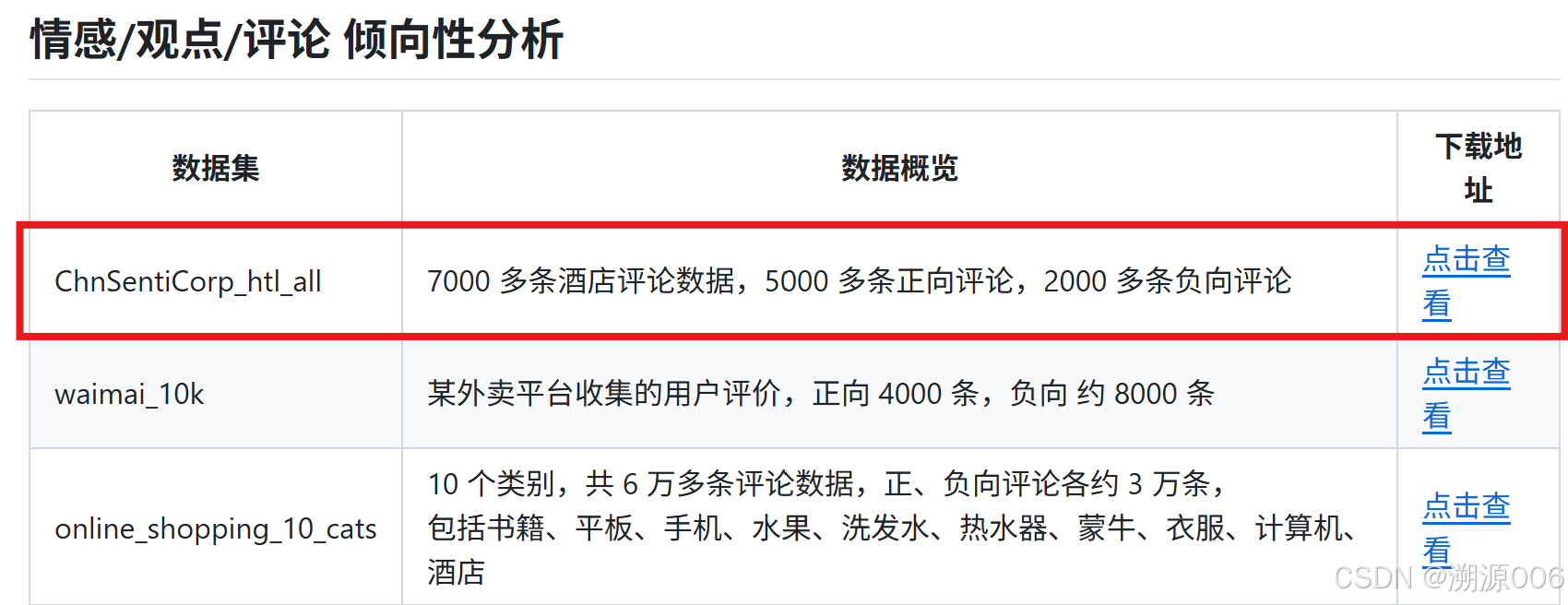
大概看一下数据集的样子:

包含两列:第一列是类别,好评是1,差评是0.
3.5.1 加载数据
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.utils.data import Dataset
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
class MyDataset(Dataset):
def __init__(self) -> None:
super().__init__()
self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv")
self.data = self.data.dropna()
def __getitem__(self, index):
return self.data.iloc[index]["review"], self.data.iloc[index]["label"]
def __len__(self):
return len(self.data)
读取数据,展示前5条:
dataset = MyDataset()
for i in range(5):
print(dataset[i])
打印如下:
('距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较为简单.', 1)
('商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!', 1)
('早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。', 1)
('宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小,但加上低价位因素,还是无超所值的;环境不错,就在小胡同内,安静整洁,暖气好足-_-||。。。呵还有一大优势就是从宾馆出发,步行不到十分钟就可以到梅兰芳故居等等,京味小胡同,北海距离好近呢。总之,不错。推荐给节约消费的自助游朋友~比较划算,附近特色小吃很多~', 1)
('CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风', 1)
3.5.2 创建Dataloader
from torch.utils.data import random_split
import torch
from torch.utils.data import DataLoader
# 划分训练集及验证集
trainset, validset = random_split(dataset, lengths=[0.9, 0.1])
# 离线加载模型
model_path = '/root/autodl-fs/models/rbt3'
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 对一批数据进行词元化,并且填充到相同的长度
def collate_func(batch):
texts, labels = [], []
for item in batch:
texts.append(item[0])
labels.append(item[1])
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")###所有样本对齐到128这个长度
inputs["labels"] = torch.tensor(labels)
return inputs
trainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)
next(enumerate(validloader))[1]
这里有一个重要的方法:collate_func,用于对数据进行处理。需要作为参数传入DataLoader。collate_func的输入是__getitem__方法的输出。
{'input_ids': tensor([[ 101, 2769, 812, ..., 0, 0, 0],
[ 101, 6983, 2421, ..., 0, 0, 0],
[ 101, 6392, 3177, ..., 0, 0, 0],
...,
[ 101, 3302, 1218, ..., 0, 0, 0],
[ 101, 2600, 860, ..., 752, 2141, 102],
[ 101, 1765, 4415, ..., 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 0, 0, 0]]),
'labels': tensor([1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1,
1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1])}
3.5.3 创建模型及优化器
from torch.optim import Adam
# 创建到Model Head的模型
model = AutoModelForSequenceClassification.from_pretrained(model_path)
if torch.cuda.is_available():
model = model.cuda() #把model放GPU上
# 创建优化器
optimizer = Adam(model.parameters(), lr=2e-5)
3.5.4 训练及评估
# 自定义评估 评估指标accuracy
def evaluate():
model.eval() ##开启评估模式
acc_num = 0
with torch.inference_mode():
for batch in validloader:
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}
output = model(**batch)
pred = torch.argmax(output.logits, dim=-1)
acc_num += (pred.long() == batch["labels"].long()).float().sum()
return acc_num / len(validset)
# 自定义训练
def train(epoch=3, log_step=100):
global_step = 0
for ep in range(epoch):
model.train() #开启model的trian模式
for batch in trainloader: #从trainloader取数据
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}##把数据放gpu上
optimizer.zero_grad() ##梯度归零
output = model(**batch) ##前向计算,输出是包含loss的
output.loss.backward() ##反向传播
optimizer.step() ##梯度更新
if global_step % log_step == 0: ##打印日志
print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}")
global_step += 1
acc = evaluate() ##评估性能
print(f"ep: {ep}, acc: {acc}")
3.5.5 模型训练
train()
ep: 0, global_step: 0, loss: 0.7741488814353943
ep: 0, global_step: 100, loss: 0.38942962884902954
ep: 0, global_step: 200, loss: 0.1997242420911789
ep: 0, acc: 0.8801546096801758
ep: 1, global_step: 300, loss: 0.16735711693763733
ep: 1, global_step: 400, loss: 0.39419108629226685
ep: 1, acc: 0.8969072103500366
ep: 2, global_step: 500, loss: 0.20464470982551575
ep: 2, global_step: 600, loss: 0.4124392569065094
ep: 2, acc: 0.8917525410652161
3.5.6 模型预测
(1)手动写所有过程:
sen = "我觉得这家酒店不错,饭很好吃!"
id2_label = {0: "差评!", 1: "好评!"}
model.eval()
with torch.inference_mode():
inputs = tokenizer(sen, return_tensors="pt")
inputs = {k: v.cuda() for k, v in inputs.items()}##数据放gpu上
logits = model(**inputs).logits##前向计算得到logits
pred = torch.argmax(logits, dim=-1)
print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")
输入:我觉得这家酒店不错,饭很好吃!
模型预测结果:好评!
(2)pipline的方法:
from transformers import pipeline
# 使用pipeline进行预测
model.config.id2label = id2_label###设置一下id2label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
pipe('我这家饭店饭很贵,菜很贵,不喜欢吃')
[{'label': '差评!', 'score': 0.5992199182510376}]
参考:
【1】【手把手带你实战HuggingFace Transformers-入门篇】基础组件之Model(上)基本使用_哔哩哔哩_bilibili
【2】Transformers基本组件(一)快速入门Pipeline、Tokenizer、Model_transformers.pipeline-CSDN博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









